De la conception à la concrétisation : lancement du langage de requête canalisé d'Elastic, ES|QL


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Nous avons le plaisir d'annoncer aujourd'hui la préversion technique du nouveau langage de requête canalisé d'Elastic®, ES|QL (langage de requête d'Elasticsearch), qui transforme, enrichit et simplifie l'examen des données. Adossé à un nouveau moteur de requête, ES|QL fournit des capacités de recherche avancées avec traitement simultané, qui améliorent la vitesse et l'efficacité quelles que soient la source de données et la structure. Résolvez rapidement les problèmes auxquels vous êtes confronté en créant des agrégations et des visualisations à partir d'un seul et même écran. Vous bénéficierez ainsi d'un workflow itératif et fluide.

Évolution dans Elasticsearch
Au cours des 13 dernières années, Elasticsearch® a évolué de manière significative, en s'adaptant aux besoins des utilisateurs et aux changements du paysage numérique. À l'origine conçu pour la recherche full-text, Elasticsearch a pris de l'ampleur pour prendre en charge un éventail plus vaste de cas d'utilisation, en se basant sur les retours des utilisateurs. Query DSL a été le premier langage de recherche que nous avons adopté au tout début dans Elasticsearch. Il fournissait un riche ensemble de requêtes pour les filtres, les agrégations et d'autres opérations. Ce langage dédié basé sur JSON est finalement devenu le socle de notre point de terminaison API _search.
Au fil des ans, face à la diversification des besoins, il est apparu évident que les utilisateurs voulaient plus que ce que pouvait offrir Query DSL. Nous avons donc adopté d'autres langages dédiés, que nous avons associés à Query DSL pour la création de scripts ou pour les événements lors des examens de sécurité et bien plus encore. Pourtant, même si ces ajouts favorisaient une meilleure polyvalence, ils ne couvraient pas entièrement certaines des exigences de nos utilisateurs.
Ce qu'attendaient les utilisateurs, c'était un langage de requête qui puisse :
- simplifier les examens des menaces et de la sécurité tout en observant et en résolvant les problèmes de production via une simple requête qui offre une approche exhaustive et itérative ;
- rationaliser les examens des données en favorisant la recherche, l'enrichissement, l'agrégation, la visualisation et bien plus encore, le tout à partir d'une interface unique ;
- utiliser des capacités de recherche avancées, comme le référencement avec traitement simultané, qui améliorent la vitesse et l'efficacité pour interroger de vastes volumes de données, quelles qu'en soient la source et la structure.
De la conception à la concrétisation : présentation d'ES|QL
Vous nous avez interpelés. Nous vous avons écoutés. Nous sommes fiers de vous présenter notre nouveau langage de requête canalisé innovant, ES|QL, qui offre une méthode unifiée pour interagir avec les données dans Elasticsearch, sans qu'il soit nécessaire de les transférer vers des systèmes externes pour leur appliquer un traitement spécialisé. À la différence d'autres langages qu'Elastic a adoptés au fil des ans comme Query DSL, ES|QL a été conçu dès le départ pour simplifier de façon drastique les examens de données et pour être accessible pour les novices et puissant pour les utilisateurs chevronnés.
Exemple de commande ES|QL :
from logstash-*
| stats avg_bytes = avg(bytes) by geo.src
| eval avg_bytes_kb = round(avg_bytes/1024, 2)
| enrich geo-data on geo.src with country, continent
| keep avg_bytes_kb, geo.src, country, continent
| limit 4Exemple de sortie ES|QL :
| avg_bytes_kb | geo.src | country | continent |
| 8.84 | BD | Bangladesh | Asia |
| 6.92 | BR | Brazil | Americas |
| 2.75 | CI | Côte d'Ivoire | Africa |
| 4.55 | CL | Chile | Americas |
Vers une simplicité ultime : une interface utilisateur sur mesure pour des workflows améliorés et itératifs
Pour comprendre une attaque en cours ou pour vous repérer dans les données d'observabilité, vous devez être capable de filtrer, rechercher, transformer et agréger les données se trouvant dans des volumes colossaux. Avec ES|QL, une seule requête suffit pour y parvenir.
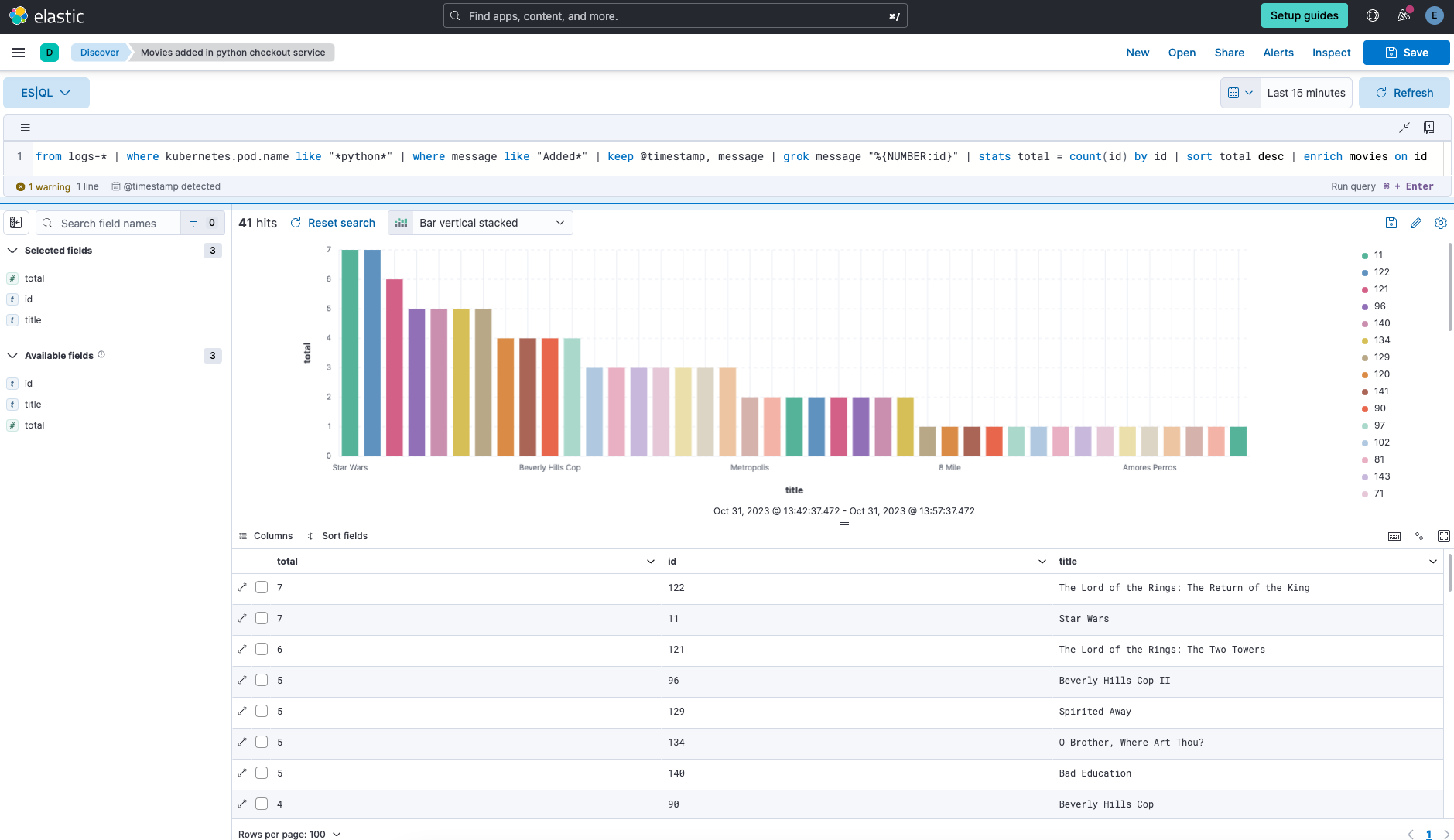
Lorsque vous recherchez un élément précis et que vous devez passer d'une fenêtre à une autre ou parcourir plusieurs écrans pour le trouver, vous pouvez être vite frustré, d'autant plus que vous perdez du temps. À partir d'une interface unifiée, ES|QL propose la saisie semi-automatique des syntaxes, intègre la documentation du produit et visualise les résultats de recherche. Vous bénéficiez ainsi d'un workflow ininterrompu et efficace pour toutes les recherches impliquant des données. Que votre cas d'utilisation porte sur la sécurité, l'observabilité ou la recherche, ES|QL booste l'efficacité, la vitesse et la profondeur de l'exploration de données.
Simultanéité d'ES|QL : deux threads valent mieux qu'un
Adossé à un solide moteur de requête, ES|QL propose des capacités de recherche avancées avec le traitement simultané. Les utilisateurs peuvent ainsi interroger les données quelles qu'en soient la source et la structure.
Il n'y a ni conversion, ni transpilation en Query DSL. À la place, chaque requête dans ES|QL est initialement décomposée, interprétée selon son sens, validée quant à son exactitude, puis améliorée pour garantir des performances optimales. Par la suite, un processus est mis en place pour exécuter la requête sur plusieurs nœuds dans le cluster. Les nœuds cible gèrent la requête et procèdent à des ajustements à la volée conformément au plan d'exécution à l'aide du framework fourni par ES|QL. Résultat : vous disposez de requêtes ultra-rapides directement prêtes à l'emploi. Par exemple, consultez les nightly benchmarks aux fins de comparaison.
Qui dit innovation de la plateforme, dit avantages pour les solutions Elastic
Les solutions d'Elastic, à savoir Elastic Search, Elastic Observability et Elastic Security, bénéficient toutes des fonctionnalités et des innovations mises en place dans Elasticsearch et Kibana®. ES|QL révolutionne l'utilisation de ces solutions et fournit un workflow d'examen des données qui est simple, mais puissant.
Amélioration d'Elastic Security avec ES|QL
ES|QL modifie radicalement la façon dont les analystes traquent les menaces et renforce la détection. Conçu en réponse à la demande de la communauté, ce langage tire parti de la puissance des requêtes canalisées à la vitesse d'Elasticsearch. Il renforce donc les capacités de SIEM, de sécurité aux points de terminaison et de sécurité du cloud d'Elastic Security.
- Une recherche rapide et itérative : pour suivre les traces infimes laissées par une menace émergente, il faut pouvoir agir vite et avoir un langage capable de fournir un workflow itératif.
- Un enrichissement des résultats avec le contexte : ES|QL permet aux analystes d'établir des corrélations entre des adresses IP suspectes et des bases de données de Threat Intelligence. Les utilisateurs bénéficient ainsi d'une vue claire sur les menaces potentielles.
- Une transformation des données : ES|QL permet aux utilisateurs de manipuler leurs données en définissant de nouveaux champs ou en analysant des données non normalisées. Le but : qu'ils aient des données claires et pertinentes.
- Une agrégation des données : grâce à la consolidation et à l'agrégation des résultats, les utilisateurs peuvent procéder à une analyse plus approfondie et en extraire des informations exploitables.
Elastic est la seule plateforme de recherche à associer l'efficacité d'une architecture de schéma d'écriture et l'expérience de recherche itérative d'un langage de requête canalisé de schéma de lecture. La recherche est ultra-rapide, tandis que la sortie de la requête est affinée à chaque passage successif, ce qui signifie que les analystes peuvent se rapprocher un peu plus de leur objectif.
ES|QL améliore également le moteur de détection puissant d'Elastic Security. Pour réduire les fausses alarmes, améliorer la pertinence des alertes et ouvrir les possibilités de la détection des comportements, les organisations peuvent incorporer des valeurs agrégées au sein des règles de détection. Avec l'évaluation directe, les professionnels peuvent élaborer de manière itérative des règles basées sur ES|QL et les perfectionner. Les requêtes sont présentées de façon claire, ce qui simplifie la collaboration et facilite la détection en tant que code.
L'influence d'ES|QL sur Elastic Observability
Les SRE qui se servent d'Elastic Observability peuvent tirer parti d'ES|QL pour analyser des logs, des indicateurs, des traces et des données de profilage. Ils peuvent ainsi repérer les goulots d'étranglement dans les performances, ainsi que les problèmes système, à partir d'une seule et même requête. Lorsque les SRE gèrent des données à haute dimensionnalité et à cardinalité élevée avec ES|QL dans Elastic Observability, ils bénéficient des avantages suivants :
- Suppression du bruit dans les signaux : l'alerting d'ES|QL améliore la précision de la détection en se concentrant sur les grandes tendances plutôt que sur des incidents isolés, en limitant le nombre de fausses alarmes et en délivrant des notifications exploitables. Les SRE peuvent gérer ces alertes via l'API Elastic et les intégrer dans les processus DevOps.
- Analyse optimale avec informations exploitables : ES|QL peut traiter différentes données d'observabilité, y compris des données relatives aux applications, à l'infrastructure, aux opérations, etc., et ce, quelles qu'en soient la source et la structure. ES|QL peut facilement enrichir les données avec des champs et du contexte supplémentaires, ce qui favorise la création de visualisations pour des tableaux de bord ou des analyses de problèmes avec une seule et même requête.
- Réduction du temps moyen de résolution : lorsqu'ES|QL est combiné avec l'AIOps d'Elastic Observability et Elastic AI Assistant, il améliore la précision de la détection en identifiant les grandes tendances, en isolant les incidents et en réduisant le nombre de faux positifs. Cette amélioration du contexte facilite le dépannage en permettant de repérer et de résoudre rapidement les problèmes.
Dans Elastic Observability, ES|QL permet non seulement d'améliorer la capacité d'un SRE à gérer l'expérience client, le chiffre d'affaires d'une entreprise et les objectifs de niveau de service avec plus d'efficacité, mais aussi de fluidifier la collaboration avec les développeurs et les DevOps en fournissant des données agrégées contextualisées.
L'influence d'ES|QL sur Elastic Search
Avec ES|QL, vous pouvez récupérer, agréger, calculer et transformer les données avec une seule et même requête. Ce langage possède des fonctionnalités très intéressantes, comme la possibilité de définir des champs au moment de la requête, d'effectuer des référencements pour enrichir les données et de traiter plusieurs requêtes simultanément. Avec ES|QL, explorez vos données de différentes façons pour mieux les comprendre. Ce langage utilise des clients pour réaliser différentes tâches, comme l'intégration d'API/de code ou la visualisation de résultats directement depuis un écran. Résultat : l'examen des données se fait en toute simplicité, ce qui vous permet d'en tirer le meilleur parti .
La conception d'ES|QL a un objectif bien affirmé : celui de réduire la complexité du code, afin d'économiser du temps et de l'argent. En permettant de réutiliser facilement les résultats des requêtes dans d'autres recherches, ES|QL limite la surcharge informatique et élimine la nécessité de recourir à des scripts alambiqués et des requêtes redondantes. ES|QL n'est pas une simple API, c'est un moyen puissant de transformer votre approche de la recherche.
Faites vos premiers pas avec ES|QL
L'avenir de l'exploration et de la manipulation des données est en marche. Elastic invite les analystes en sécurité, les SRE et les développeurs à tester ce langage révolutionnaire en avant-première et à décupler leurs possibilités lorsqu'ils utilisent les données. Envie d'en savoir plus sur les avantages d'ES|QL ? Cliquez ici ou lancez-vous avec un essai gratuit dès maintenant avec la préversion technique.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer