Überwachen von Google Cloud mit dem Elastic Stack und Google Cloud Operations
Google Cloud Operations, früher unter dem Namen Stackdriver bekannt, ist ein zentrales Repository zur Speicherung von Logdaten, Metriken und Anwendungs-Traces aus Google Cloud-Ressourcen, wie Compute Engine, App Engine, Dataflow und Dataproc sowie deren SaaS-Angeboten, z. B. BigQuery. Durch das Senden dieser Daten an Elastic können Sie sich ein Bild von der Performance all dieser Ressourcen in Ihrer gesamten Infrastruktur machen, gleich ob On-Premise oder in der Cloud.
In diesem Blogpost richten wir eine Pipeline zum Streamen von Daten von Google Cloud Operations in den Elastic Stack ein, damit Sie parallel zu Ihren anderen Observability-Daten auch Ihre Google Cloud-Logdaten analysieren können. Für diese Demonstration verwenden wir das Google Cloud-Modul von Filebeat, mit dem wir Daten aus Google Cloud zu Analysezwecken an ein zu Probezwecken aufgesetztes Elastic Cloud-Deployment senden. Am besten, Sie vollziehen meine Schritte einfach bei sich nach.
Überblick über den Datenfluss
Im Rahmen dieser Demonstration senden wir Audit-, Firewall- und VPC-Flusslogs von Google Cloud-Ressourcen an Google Cloud Operations. Anschließend erstellen wir Senken und Pub/Sub-Themen, abonnieren das Ganze als Filebeat und senden unsere Daten dann zur weiteren Analyse mit Elasticsearch und Kibana an Elastic Cloud. Die folgende Grafik zeigt, welchen Weg die Daten nehmen, um in unser Cluster zu gelangen:
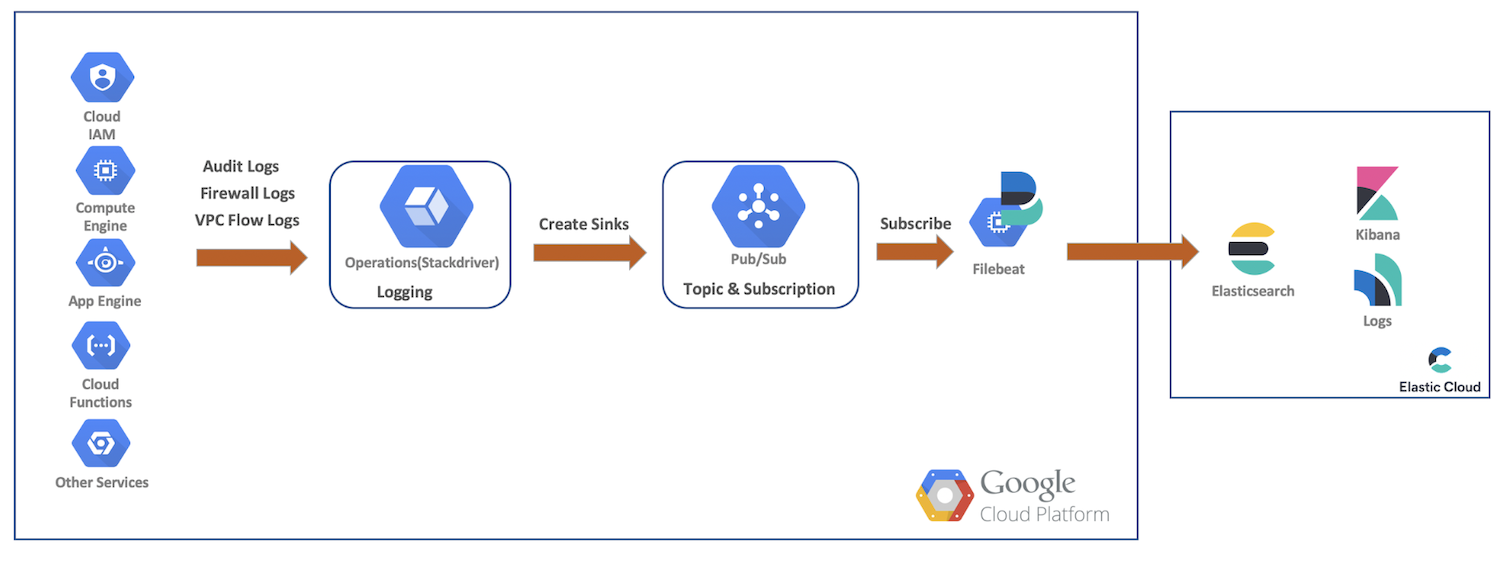
Einrichten und Konfigurieren des Google Cloud-Loggings
Google Cloud bietet in seiner umfangreichen Benutzeroberfläche auch Optionen zum Logging für Dienste, wobei die Logs in ihren entsprechenden Konsolen konfiguriert werden. In den folgenden Schritten aktivieren wir verschiedene Logs, erstellen unsere Senken und Themen und richten dann unser Dienstkonto und unsere Anmeldedaten ein.
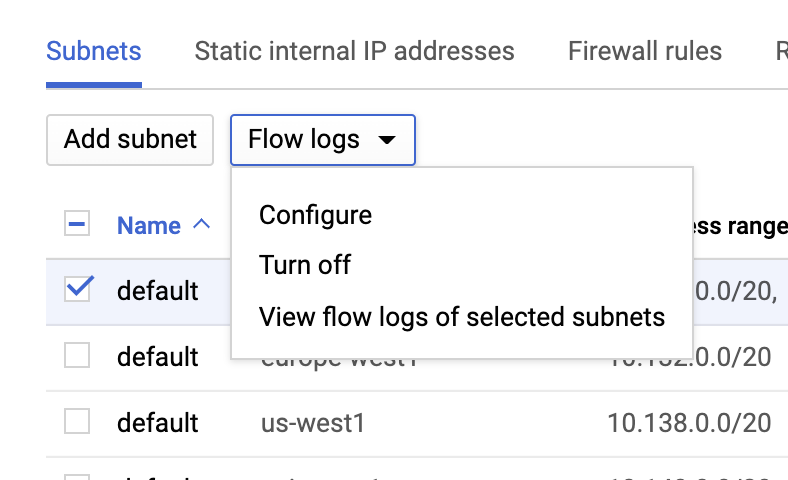
VPC-Flusslogs
VPC-Flusslogs können wir aktivieren, indem wir zur Seite VPC-Netzwerk gehen, eine VPC auswählen und im Dropdown Flusslogs auf Konfigurieren klicken:
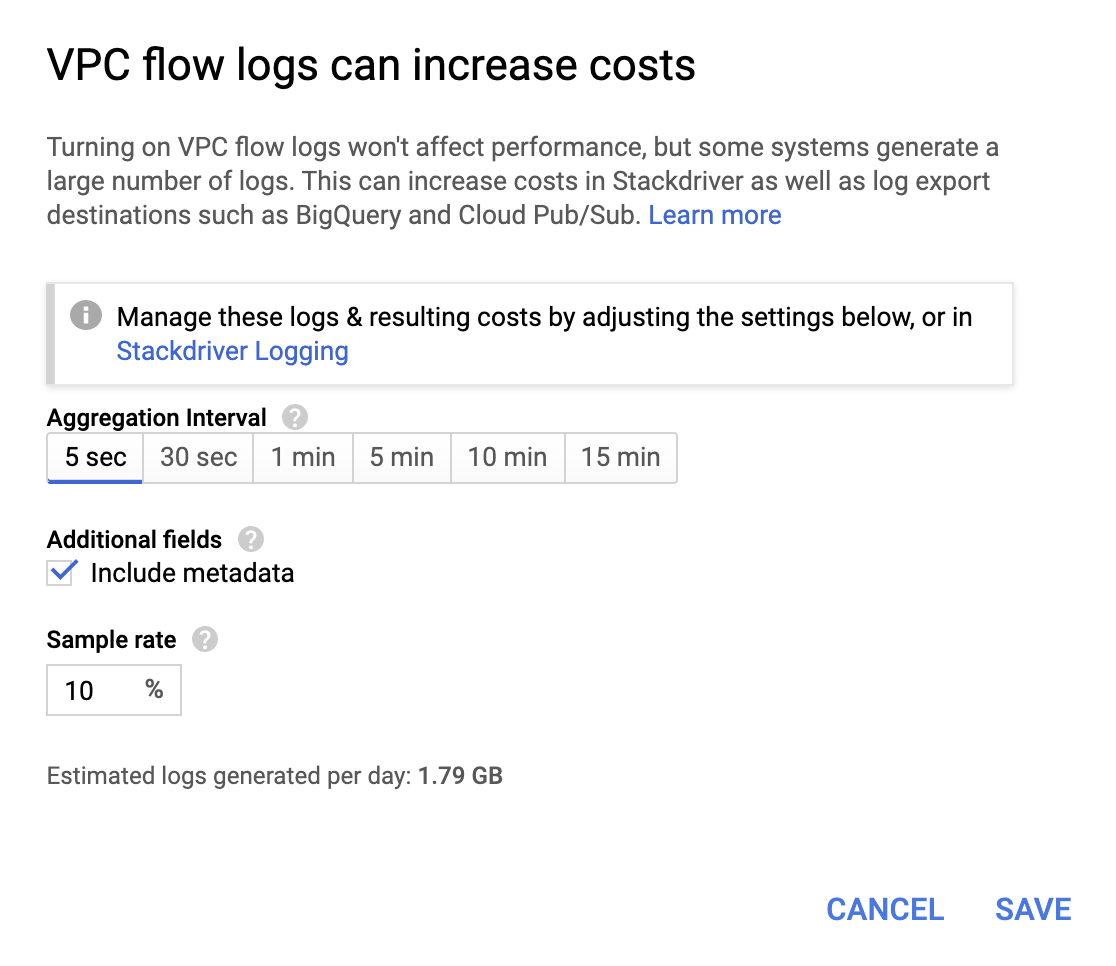
Für sich genommen sind diese Vorgänge jeweils nicht sehr teuer, aber da Kleinvieh bekanntlich auch Mist macht, lohnt es sich, ein für Ihre konkreten Anforderungen geeignetes Aggregationsintervall mit einer entsprechenden Abtastrate auszuwählen.
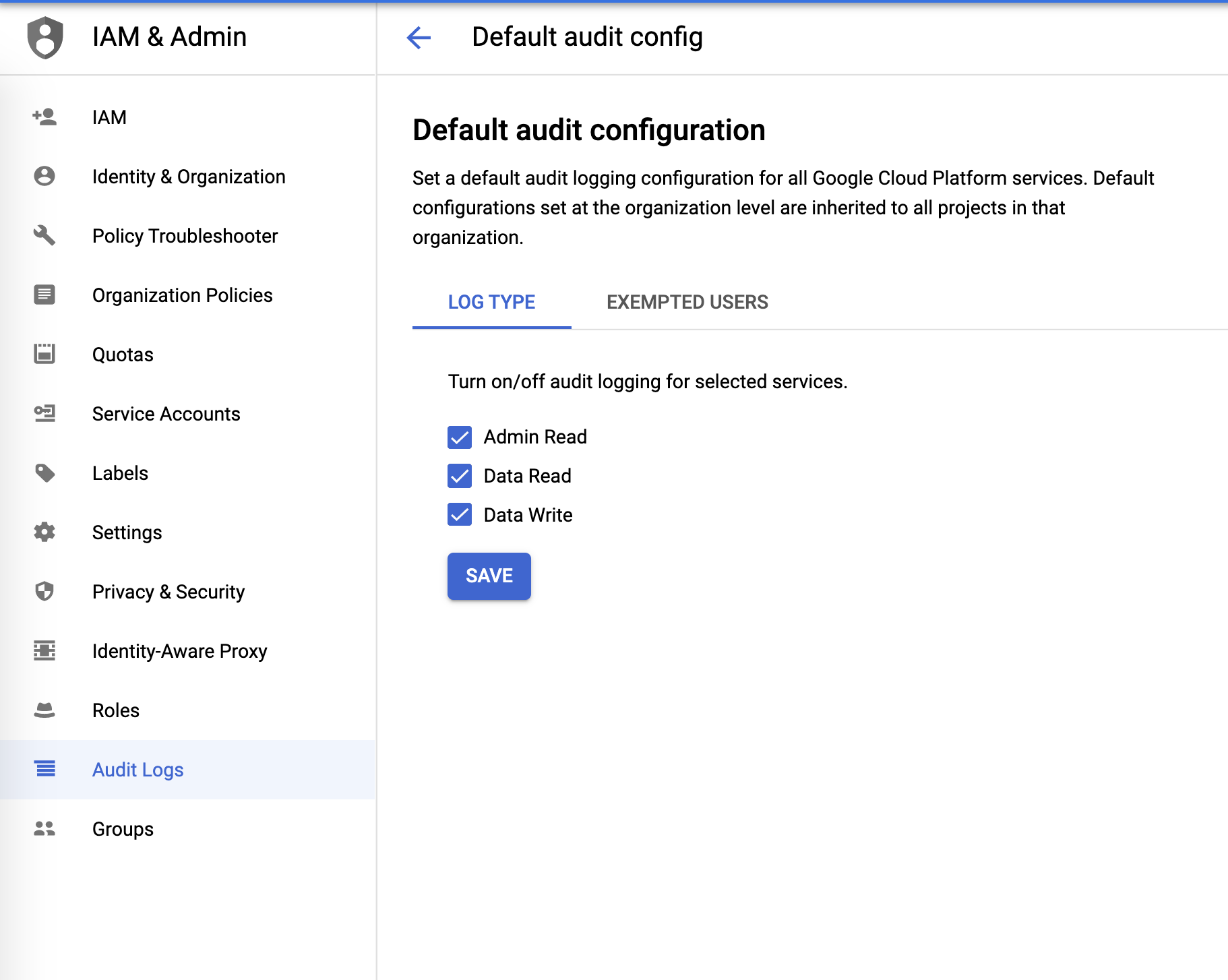
Audit-Logs
Audit-Logs können über das Menü IAM & Verwaltung konfiguriert werden:
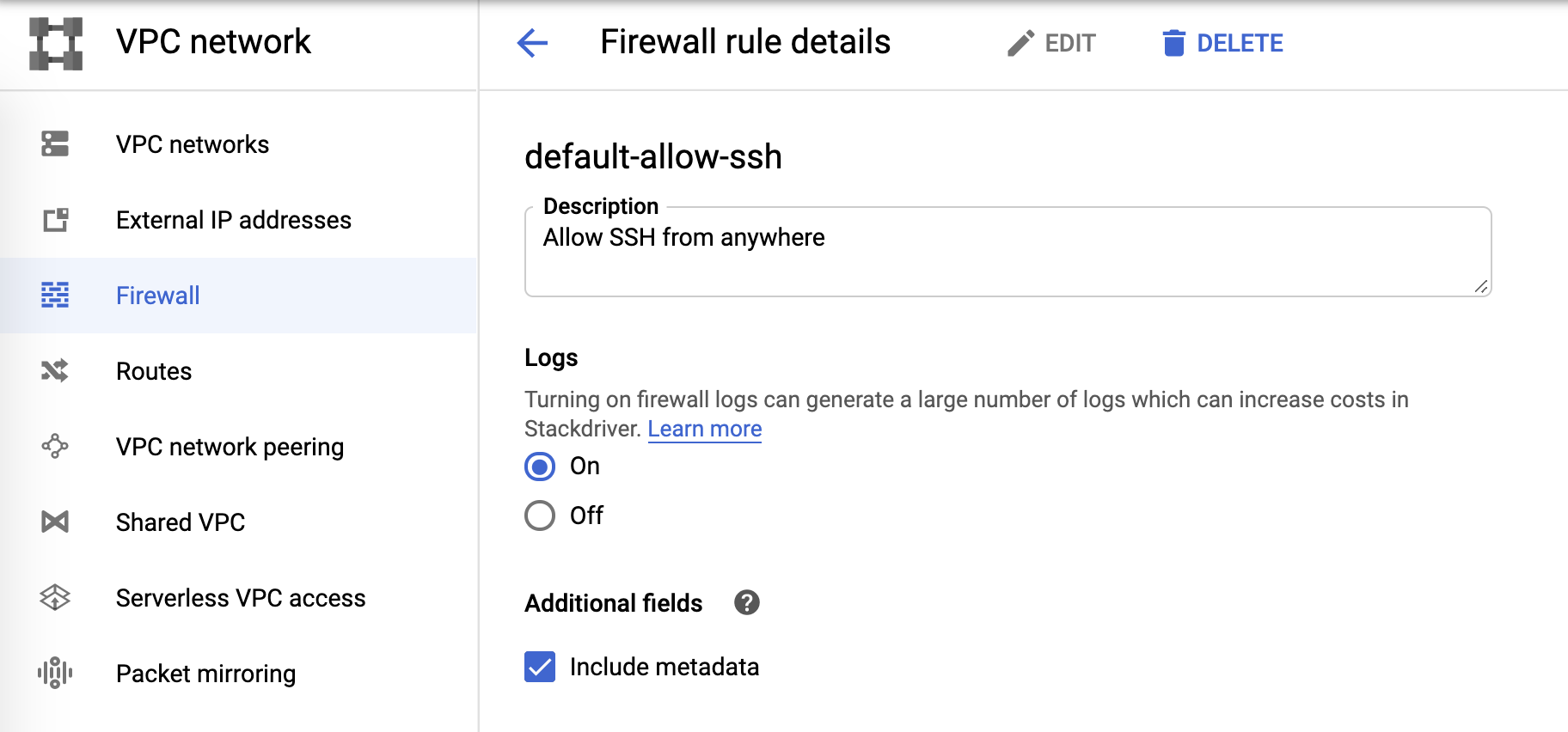
Firewall-Logs
Und zum Schluss die Firewall-Logs. Diese können über die Firewall-Regeln gesteuert werden:
Log-Senke und Pub/Sub
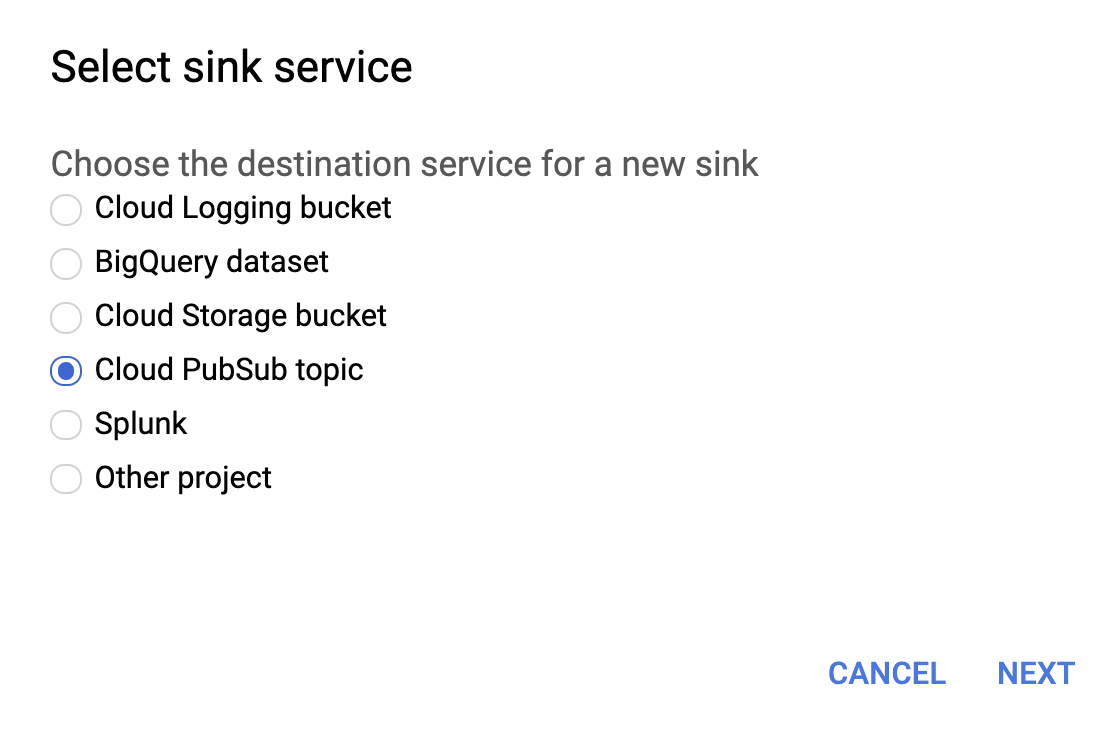
Nachdem wir die einzelnen Logging-Bereiche konfiguriert haben, können wir von der Loganzeige aus für jedes einzelne Log eine Senke erstellen:

Als Senkendienst wählen wir, wie unten zu sehen, die Option Cloud Pub/Sub-Thema aus.
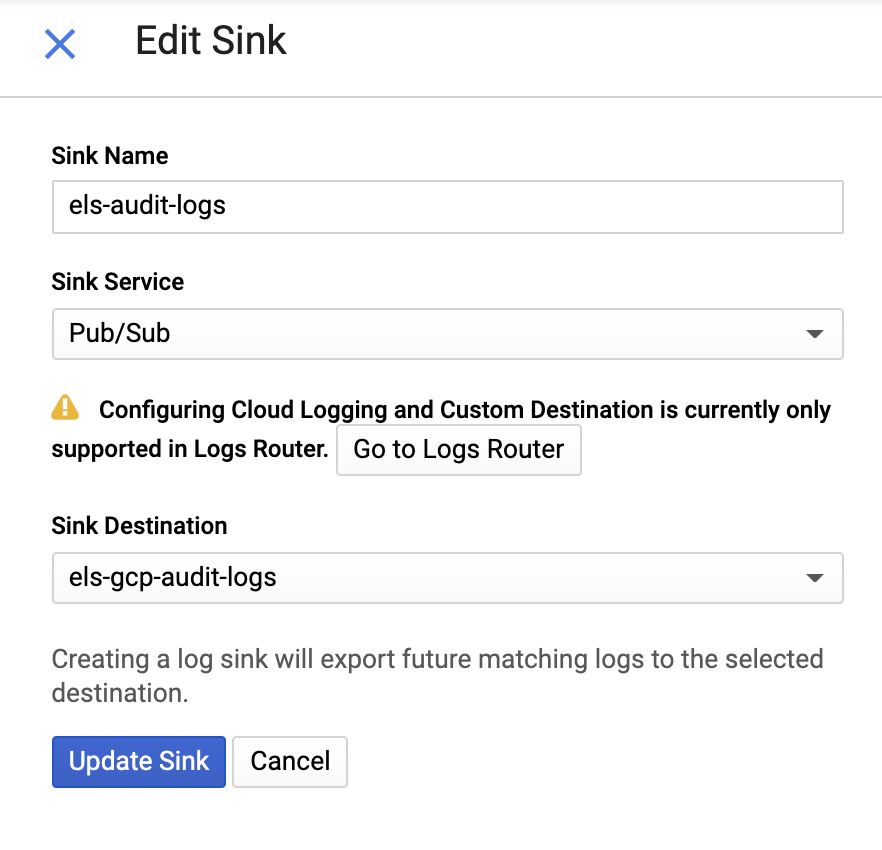
Anschließend geben wir einen Namen für die Senke und ein Pub/Sub-Thema ein. Dabei können wir wählen, ob ein vorhandenes Thema verwendet oder ein neues Thema erstellt werden soll:
Nachdem wir unsere Senke und unsere Themen erstellt haben, müssen wir jetzt das Pub/Sub-Thema Abos erstellen:
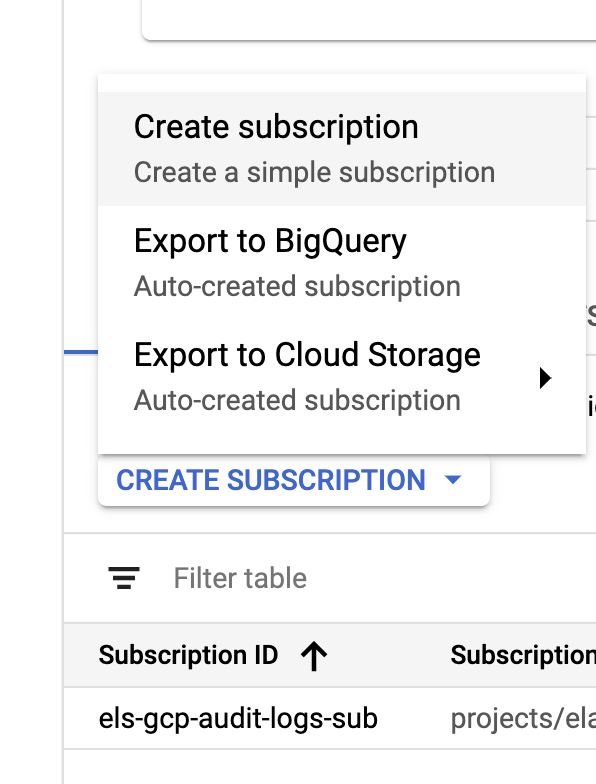 | 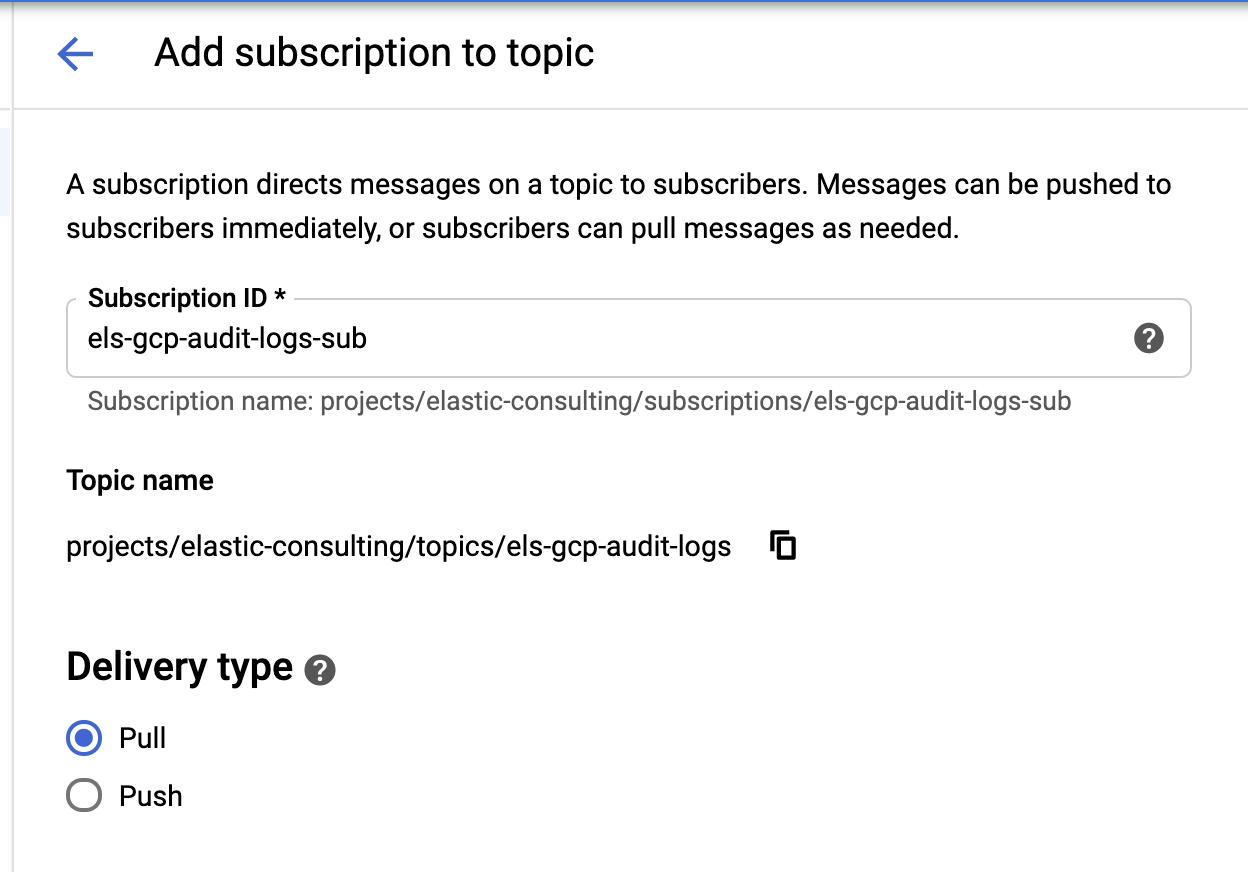 |
Konfigurieren Sie das Abo Ihren Anforderungen entsprechend.
Dienstkonto und Anmeldedaten
Zu guter Letzt erstellen wir ein Dienstkonto und eine Anmeldedatendatei.
Wir wählen die Rolle Pub/Sub-Bearbeiter; die Bedingung ist optional und kann zum Filtern der Themen verwendet werden.
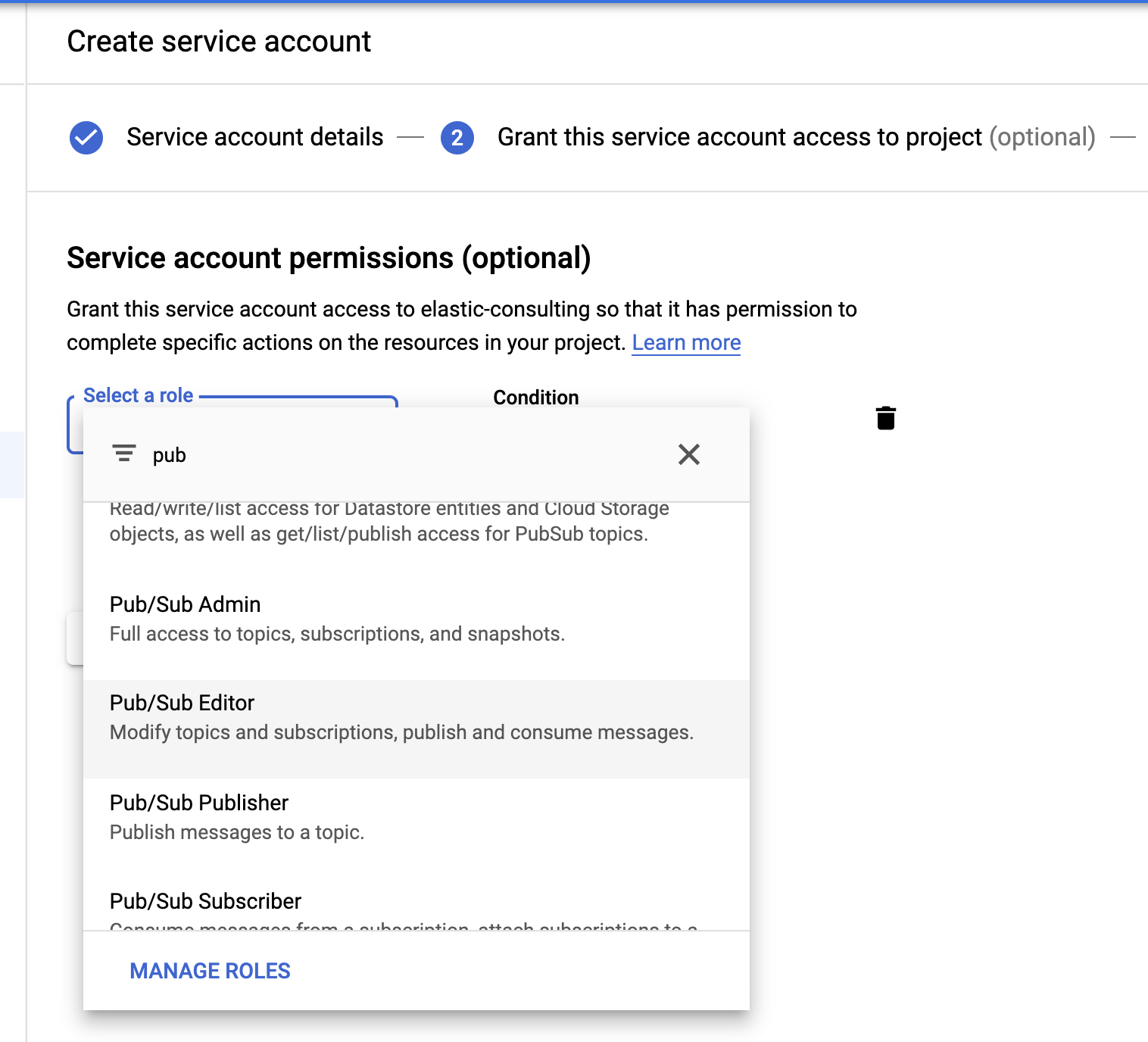
Nachdem wir das Dienstkonto erstellt haben, generieren wir einen JSON-Schlüssel, der auf den Filebeat-Host hochgeladen und im Filebeat-Konfigurationsverzeichnis /etc/filebeat gespeichert wird. Diesen Schlüssel verwendet Filebeat zum Authentifizieren als Dienstkonto.

Damit ist unsere Google Cloud-Konfiguration abgeschlossen.
Installieren und Konfigurieren von Filebeat
Filebeat dient dazu, die Logs zu erfassen und an unseren Elasticsearch-Cluster zu senden. In diesem Blogpost verwenden wir CentOS. Wie Sie Filebeat mit ein paar einfachen Schritten auf Ihrem Betriebssystem installieren können, erfahren Sie in unserer Filebeat-Dokumentation.
Aktivieren des Google Cloud-Moduls
Nach dem Installieren von Filebeat müssen wir das Google Cloud-Modul (googlecloud) aktivieren:
filebeat modules enable googlecloud
Dafür kopieren wir die JSON-Anmeldedaten, die wir vorhin erstellt haben, in /etc/filebeat/ und bearbeiten die Datei /etc/filebeat/modules.d/googlecloud.yml, um sie an unsere Google Cloud-Einrichtung anzupassen.
Einige der Konfigurationsschritte werden uns dankenswerterweise abgenommen. So werden beispielsweise alle drei Module aufgelistet und alle erforderlichen Konfigurationen sind bereits eingegeben. Sie müssen die Werte lediglich durch passende Werte für Ihre Konfiguration ersetzen.
# Modul: googlecloud
# Dokumentation: https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# Google Cloud-Projekt-ID.
var.project_id: els-dummy
# Google-Pub/Sub-Thema mit VPC-Flusslogs. Stackdriver muss
# so konfiguriert sein, dass dieses Thema als Senke für VPC-Flusslogs verwendet wird.
var.topic: els-gcp-vpc-flow-logs
# Google-Pub/Sub-Abo für das Thema. Wenn das Abo nicht existiert,
# wird es von Filebeat erstellt.
var.subscription_name: els-gcp-vpc-flow-logs-sub
# Anmeldedatendatei für das Dienstkonto mit Autorisierung für
# das Lesen aus dem Abo.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# Google Cloud-Projekt-ID
var.project_id: els-dummy
# Google-Pub/Sub-Thema mit Firewall-Logs. Stackdriver muss
# so konfiguriert sein, dass dieses Thema als Senke für Firewall-Logs verwendet wird.
var.topic: els-gcp-firewall-logs
# Google-Pub/Sub-Abo für das Thema. Wenn das Abo nicht existiert,
# wird es von Filebeat erstellt.
var.subscription_name: els-gcp-firewall-logs-sub
# Anmeldedatendatei für das Dienstkonto mit Autorisierung für
# das Lesen aus dem Abo.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# Google Cloud-Projekt-ID
var.project_id: els-dummy
# Google-Pub/Sub-Thema mit Audit-Logs. Stackdriver muss
# so konfiguriert sein, dass dieses Thema als Senke für Firewall-Logs verwendet wird.
var.topic: els-gcp-audit-logs
# Google-Pub/Sub-Abo für das Thema. Wenn das Abo nicht existiert,
# wird es von Filebeat erstellt.
var.subscription_name: els-gcp-audit-logs-sub
# Anmeldedatendatei für das Dienstkonto mit Autorisierung für
# das Lesen aus dem Abo.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
Zum Schluss konfigurieren wir Filebeat so, dass es auf unsere Kibana- und Elasticsearch-Endpoints verweist.
Wie in den Endpoint-Dokumentationen für Kibana und Elasticsearch beschrieben, können wir in unserer Datei filebeat.yml die Einstellung setup.dashboards.enabled: true festlegen, damit ein vorkonfiguriertes Dashboard für Google Cloud geladen wird.
Nur nebenbei: Filebeat bietet eine breite Palette an Modulen mit vorkonfigurierten Dashboards. Wir betrachten in diesem Beitrag nur das Modul für Google Cloud, ich empfehle Ihnen aber, sich auch einmal die anderen verfügbaren Filebeat-Module anzusehen.
Filebeat starten
Zum Schluss können wir Filebeat starten und das Flag -e hinzufügen, damit die Ausgabe als Logdaten an die Konsole gesendet wird:
sudo service filebeat start -e
Erkunden Ihrer Daten in Kibana
Nachdem wir eingerichtet haben, dass Filebeat Daten an unser Cluster sendet, können wir jetzt in der seitlichen Navigationsleiste von Kibana zu „Dashboard“ gehen. Falls Sie auch Dashboards für andere Module haben, empfiehlt sich möglicherweise eine Suche nach google, um die Dashboards für unser neu aktiviertes Modul zu finden. In unserem Fall sehen wir das Google Cloud-Dashboard „Audit“.
Dieses Dashboard enthält verschiedene Visualisierungen, darunter eine dynamische Karte der Ausgangsorte, eine Visualisierung der Ereignisergebnisse im Zeitverlauf und eine Aufschlüsselung der Ereignisaktionen. Mit diesen vorkonfigurierten interaktiven Visualisierungen lassen sich Logdaten ganz intuitiv erkunden. Wenn Sie Filebeat zum ersten Mal einrichten oder eine ältere Version des Elastic Stack ausführen (das Google Cloud-Modul wurde mit Version 7.7 allgemein verfügbar gemacht), gelten für das Laden von Dashboards diese Anweisungen.
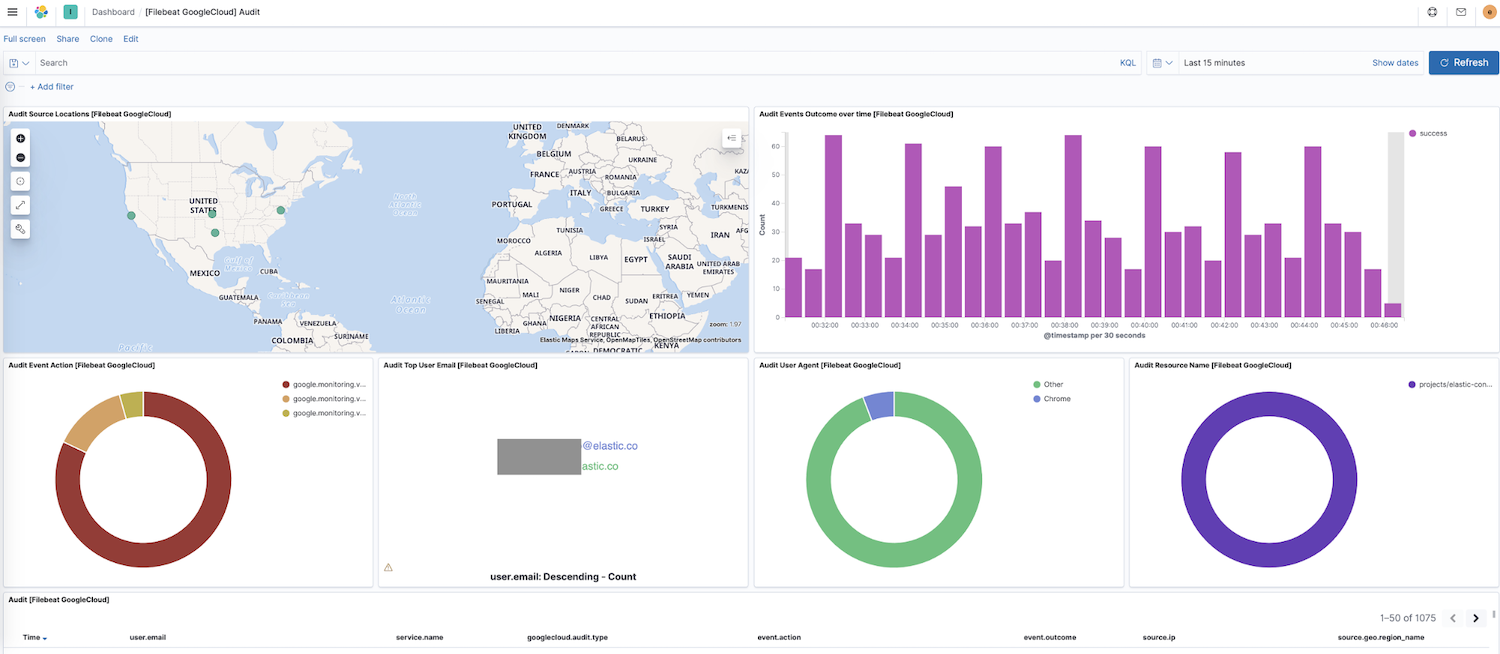
Darüber hinaus bietet Elastic eine Observability-Lösung mit einer Log-Monitoring-App. Die Standardwerte für die Logindizes sind filebeat-* und logs-*, aber diese Indizes können frei konfiguriert werden.
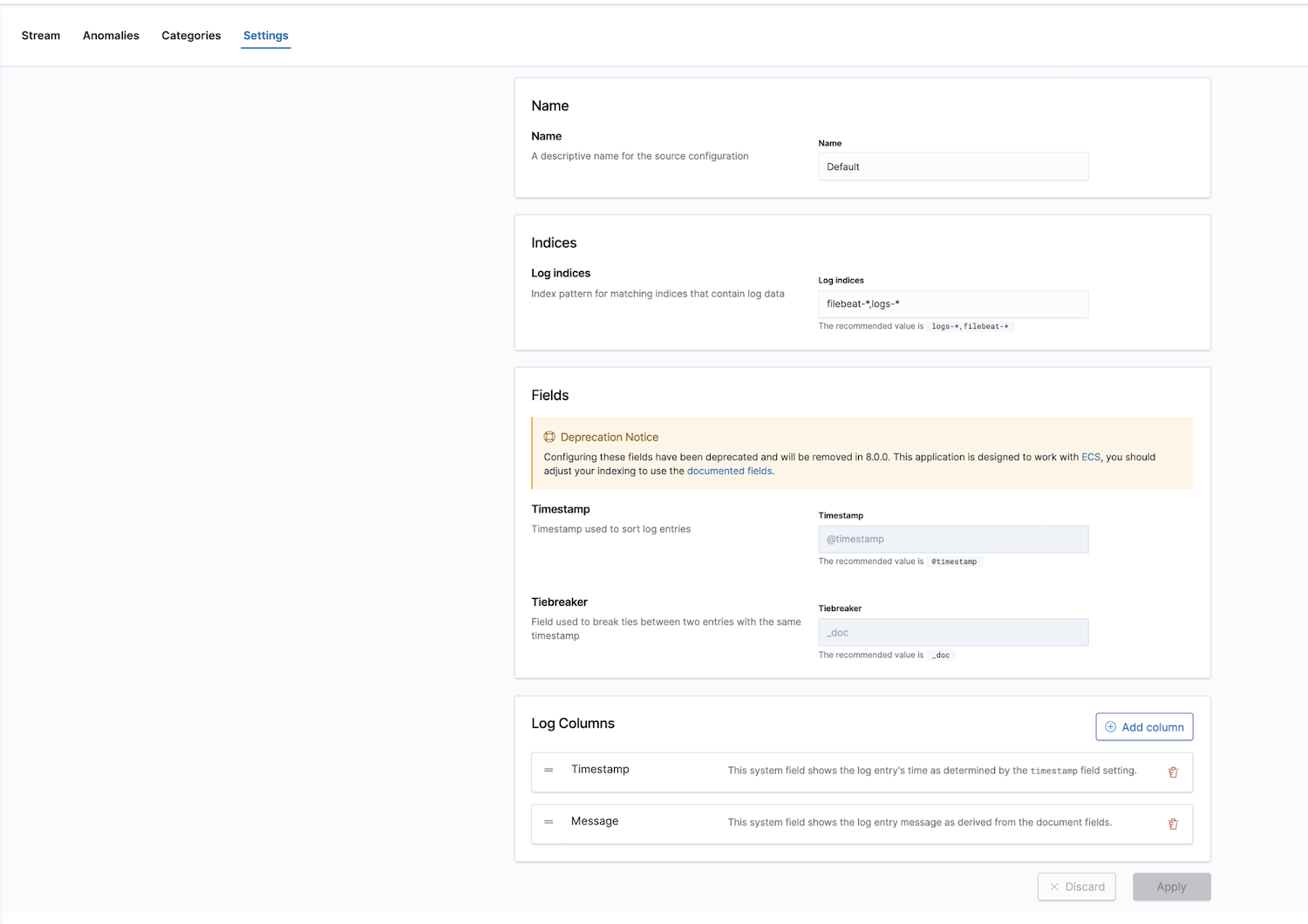
Nach dem Konfigurieren der richtigen Indexmuster in den Einstellungen können wir unsere Logdaten in der App Logs erkunden. So können wir uns Details zu den Logdaten ansehen und, wichtiger noch, Machine-Learning-Jobs für anormales Verhalten definieren, die Daten kategorisieren und einen Alert erstellen.
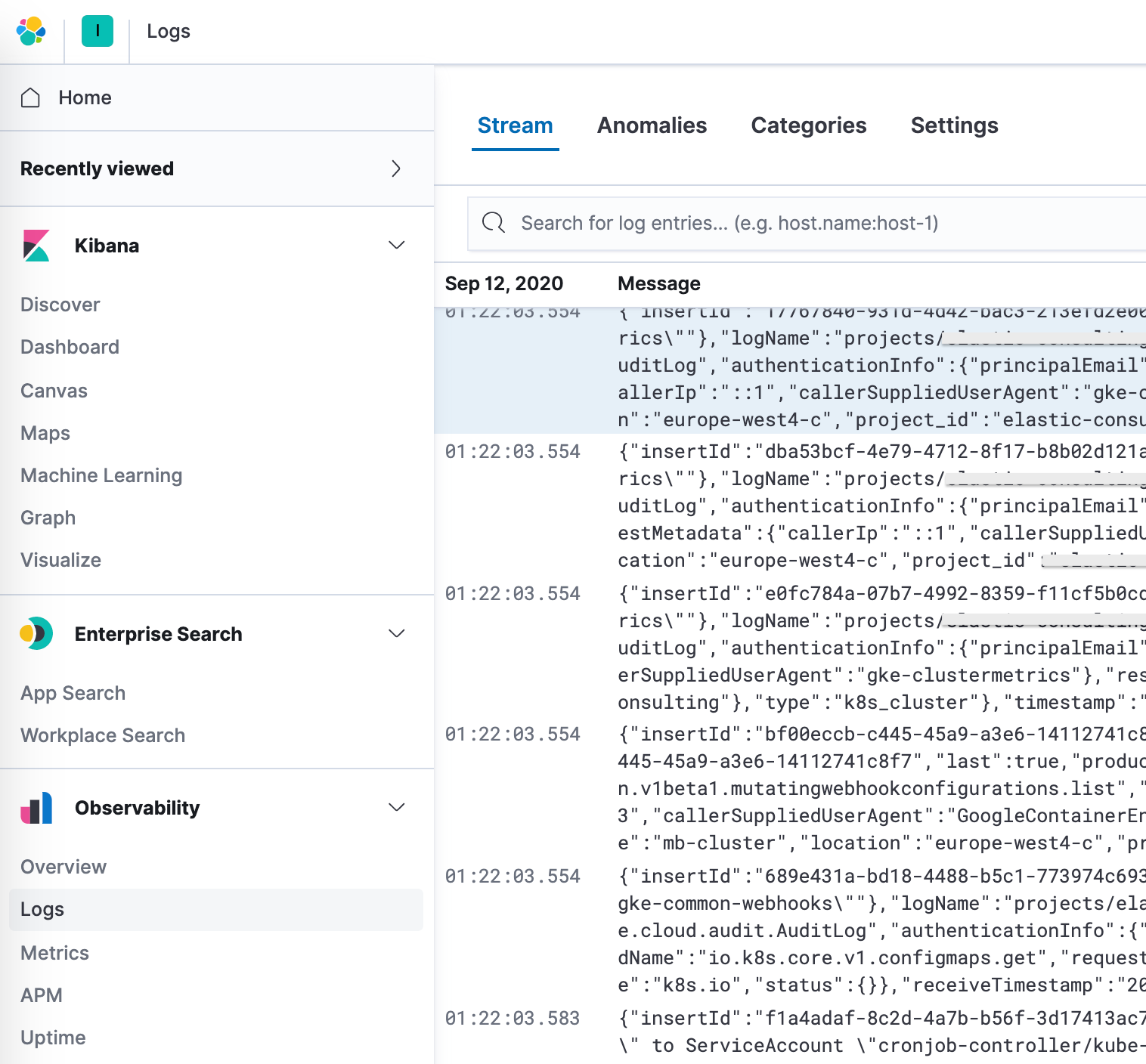
Erweitertes Google Cloud Operations(Stackdriver)-Logging
Oben haben wir besprochen, wie Vorgangslogs für diejenigen Logs gesendet werden können, die Filebeat-Module haben. Wie aber funktioniert das für andere Logs ohne dediziertes Filebeat-Modul? Im Folgenden beschäftigen wir uns daher damit, wie Sie auch diese Logs an Elastic senden können, damit wir sie parallel zu unseren anderen Logdaten ansehen können.
Was die Einrichtung und Konfiguration von Google Cloud anbelangt, bleibt alles, auch der Datenfluss, gleich. Wir erstellen eine Senke, ein Thema, ein Abo, einen sa und einen JSON-Schlüssel. Anders ist lediglich die Filebeat-Konfiguration.
Im Hintergrund werden auf Inputs, auf vorkonfiguriertes Parsing auf Quellebene und, in manchen Fällen, auf Ingestionspipelines bestimmte Module angewendet. Filebeat-Module vereinfachen zwar das Sammeln, Parsen und Visualisieren gängiger Logdatenformate, aber für Filebeat-Inputs ist mitunter zusätzliches Parsing erforderlich.
Das Modul googlecloud nutzt im Hintergrund den Input google-pubsub und liefert einige modulspezifische Ingestionspipelines. Es unterstützt standardmäßig vpcflow-, audit- und firewall-Logs.
Konfiguration
Statt extra ein Filebeat-Modul zu verwenden, abonnieren wir diese Themen aus einem Filebeat-Input.
Wir fügen der Datei filebeat.yml Folgendes hinzu:
filebeat.inputs:
- type: google-pubsub
enabled: true
pipeline: gcp-pubsub-parse-message-field
tags: ["gcp-pubsub"]
project_id: elastic-consulting
topic: gcp-gke-container-logs
subscription.name: gcp-gke-container-logs-sub
credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
In diesem Input geben wir das Thema, aus dem Daten bezogen werden sollen, und das zu verwendende Abo an. Außerdem geben wir die Anmeldedatendatei und eine Ingestionspipeline an. Letztere definieren wir als Nächstes.
Ingestionspipelines
Eine Ingestionspipeline gibt vor, in welcher Reihenfolge bestimmte Prozessoren ausgeführt werden müssen.
Google Cloud Operations speichert Logdaten und Meldungstext im JSON-Format. Das bedeutet, dass wir lediglich einen JSON-Prozessor in der Pipeline hinzufügen müssen, damit Daten im Meldungsfeld in einzelne Felder in Elasticsearch extrahiert werden.
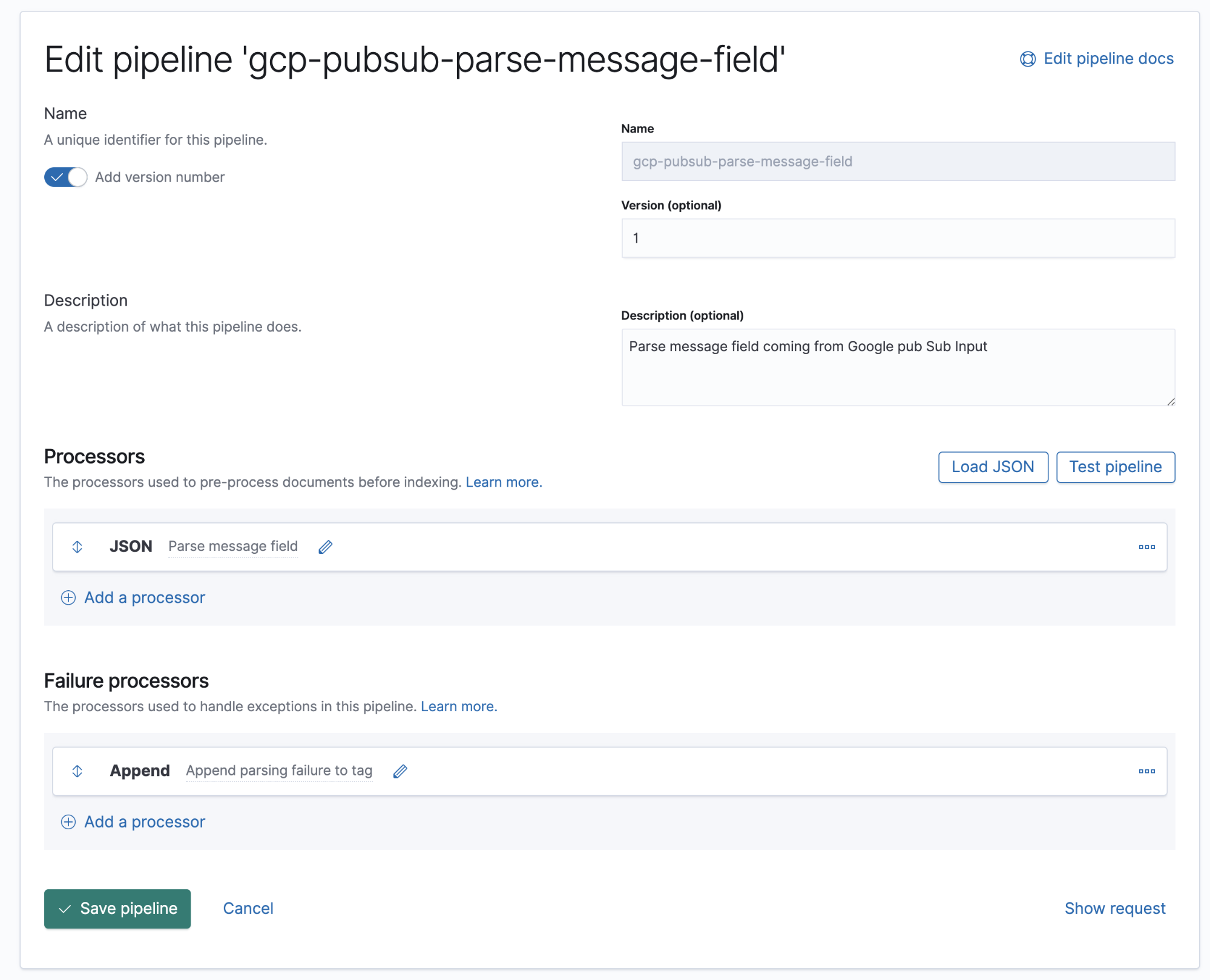
In dieser Pipeline haben wir einen (1) JSON-Prozessor, der Daten aus dem Feld message im Dokument abruft und sie in ein Feld mit der Bezeichnung log extrahiert.
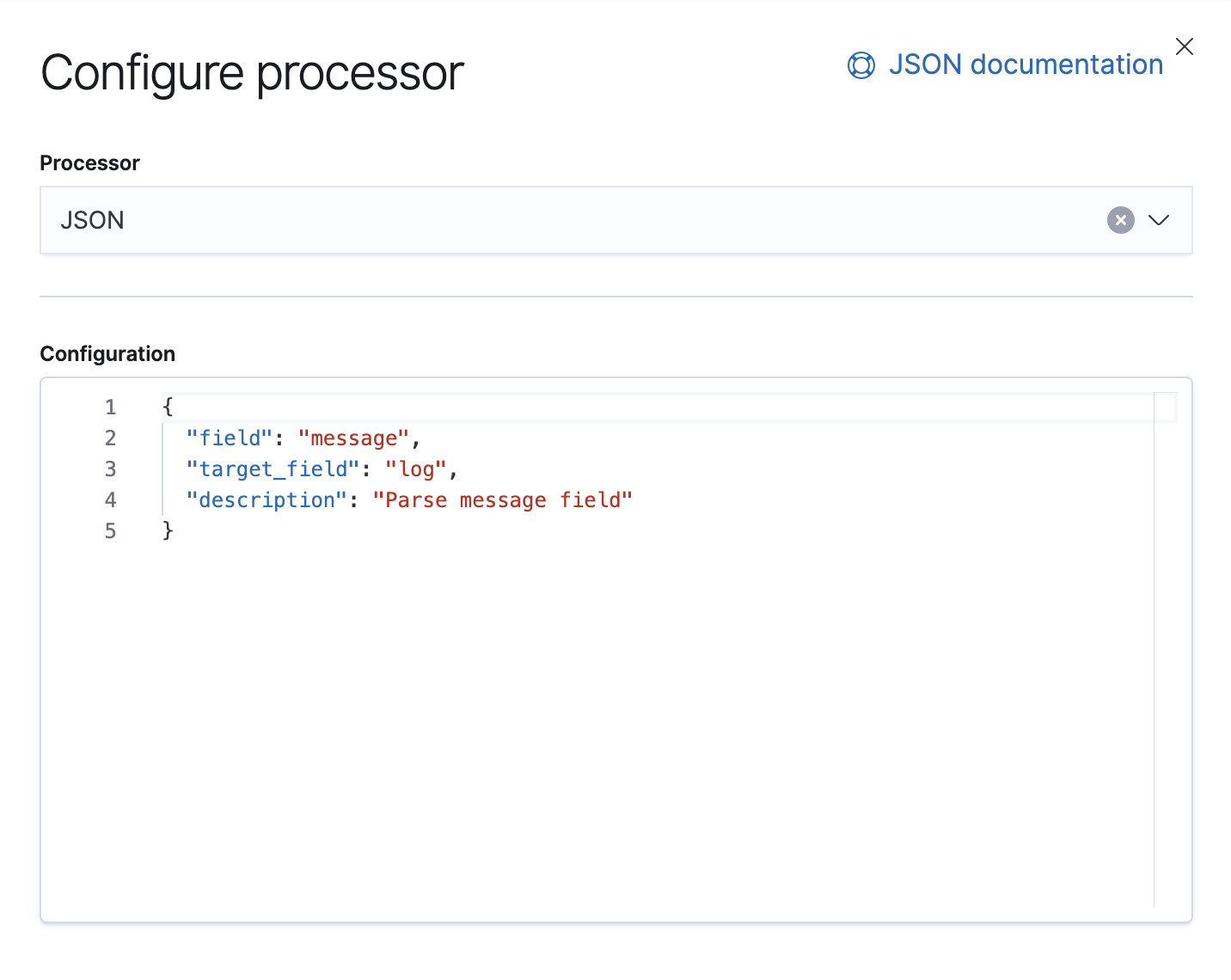
Außerdem haben wir einen Fehlerprozessor. Dessen Aufgabe ist es, Ausnahmen in dieser Pipeline zu behandeln. Für diesen Fall hängen wir einfach ein Tag an.
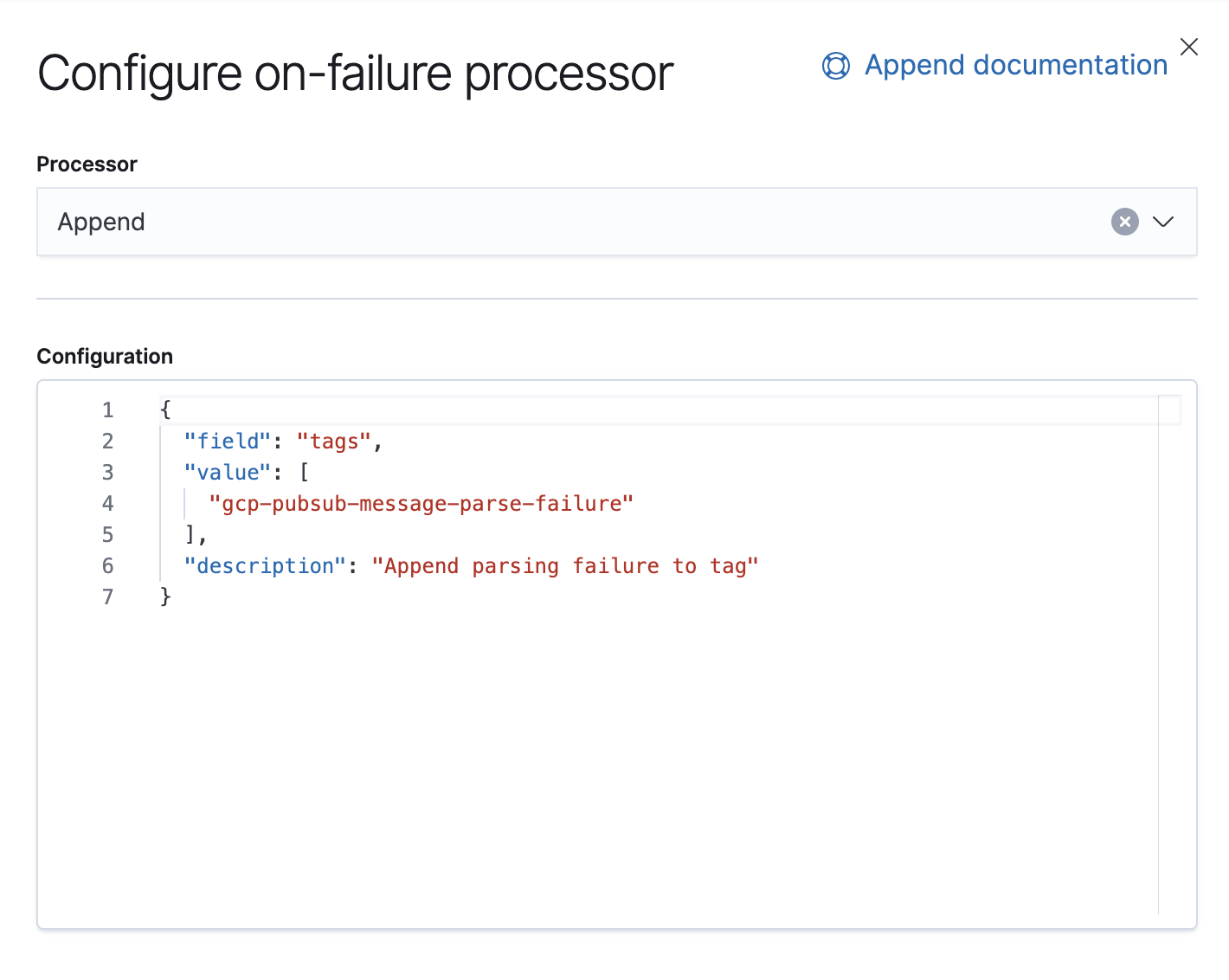
Seit 7.8 gibt es in Kibana die Möglichkeit, Ingestionspipelines über die Benutzeroberfläche zu erstellen: Stack Management → Ingest Node Pipelines. Wenn Sie eine ältere Version verwenden, können Sie APIs dafür verwenden. Für diese Pipeline ist dies die passende API:
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version": 1,
"description": "Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description": "Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description": "Append parsing failure to tag"
}
}
]
}
Wir speichern diese Pipeline und sofern wir dieselbe Pipeline auch im „google-pubsub“-Input konfiguriert haben, müssten wir nun in Kibana geparste Logdaten sehen.
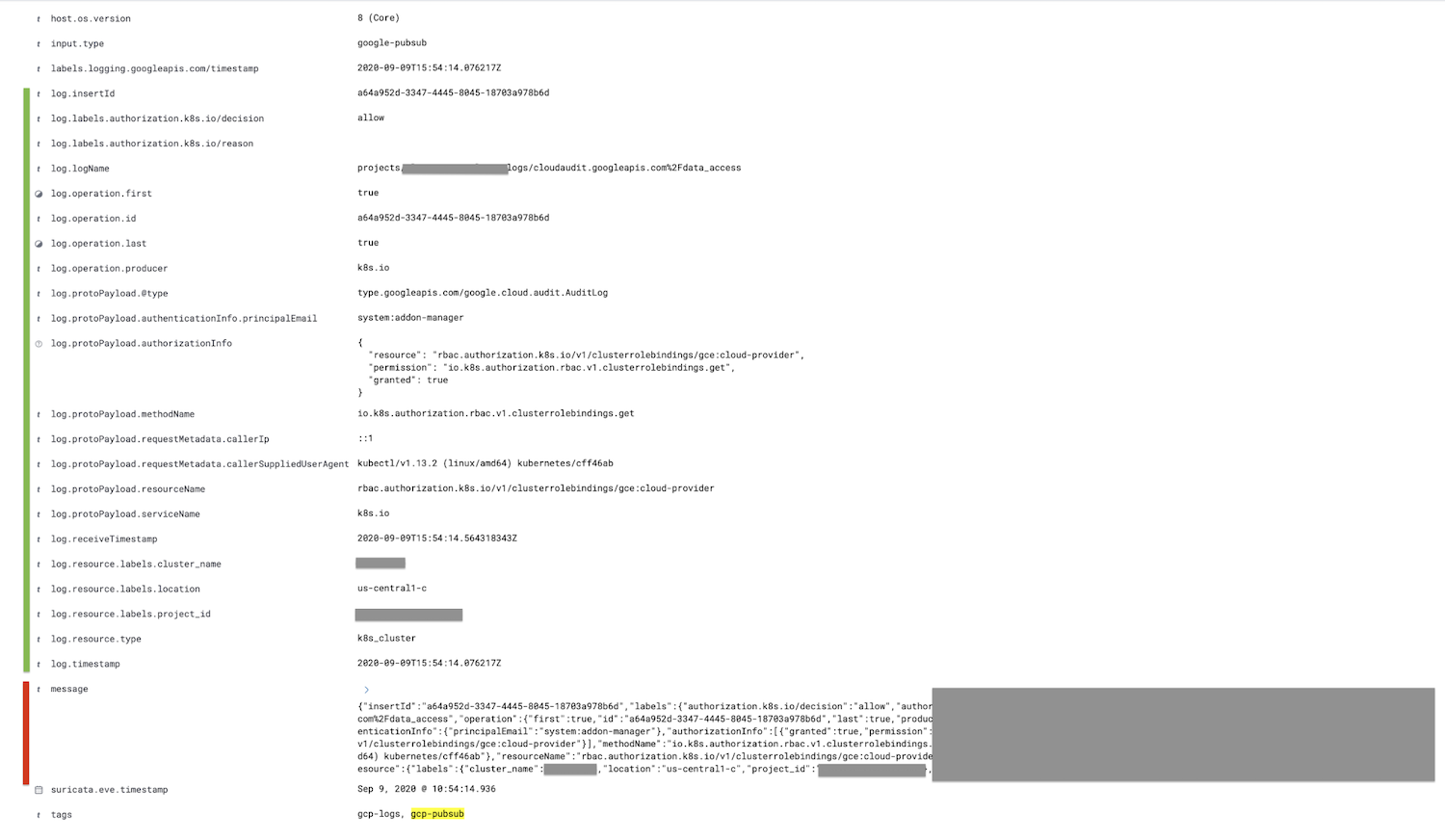
Das rot markierte Feld, das Feld „message“, wird in das Feld „log“ mit entsprechenden untergeordneten Feldern (hier grün markiert) geparst.
Sofern gewünscht, kann das Feld „message“ nach dem JSON-Prozessor in der Ingestionspipeline mit dem Entfernen-Prozessor entfernt werden, um das Dokument zu verkleinern.
Fazit
Damit sind wir in diesem Blogpost am Ende angelangt – vielen Dank fürs Nachstellen! Wenn Sie Fragen haben, stellen Sie diese in unseren Discuss-Foren. Wir würden uns freuen, von Ihnen zu hören. Oder Sie sehen sich unser On-Demand-Webinar zu Logging und Observability mit Elastic an.
Wenn Sie diese Demo gern selbst ausprobieren möchten, können Sie kostenlos Elasticsearch Service auf Elastic Cloud ausprobieren oder für ein selbst verwaltetes Deployment die neueste Version herunterladen.