Jetzt neu: der Elastic App Search-Web-Crawler
Es freut uns, dass wir mit der Veröffentlichung von Elastic Enterprise Search 7.11 auch den Start der Betaversion des Elastic App Search-Web-Crawlers bekanntgeben dürfen. Damit steht eine so einfache wie leistungsfähige Möglichkeit zur Verfügung, öffentlich verfügbare Webinhalte zu ingestieren, sodass sie sofort auf Ihrer Website durchsucht werden können.
Es gibt verschiedene Möglichkeiten, wie sich Inhalte auf Websites durchsuchbar machen lassen. Elastic App Search bietet bereits das Ingestieren von Inhalten durch Hochladen von JSON, durch Einfügen von JSON oder über API-Endpoints an. In der neuen Version kommt als zusätzliche bequeme Option für das Ingestieren von Inhalten der Web-Crawler (Beta) dazu.
Der Web-Crawler, der für selbstverwaltete und für Elastic Cloud-Deployments verfügbar ist, erfasst Informationen von öffentlich verfügbaren Websites und macht diese in Ihren App Search-Engines durchsuchbar. App Search kümmert sich im Hintergrund für Sie darum, die durchsuchbaren Inhalte relevant und einfach justierbar zu machen – ganz ohne Programmierkenntnisse.
Sehen wir uns einmal an, warum wir den Web-Crawler in App Search einführen.
Was macht diesen Web-Crawler so anders?
Die kurze Antwort lautet: [Trommelwirbel] Elastic Cloud.
Wenn Sie Elastic Enterprise Search in den letzten Jahren verfolgt haben (wir lieben unseren Fanclub), werden Sie wissen, dass es bereits einen Web-Crawler gibt, nämlich in Elastic Site Search. In der Elastic Cloud, die sich einer riesigen Popularität erfreut, sind aber nur Elastic App Search und Workplace Search verfügbar.
Höre ich da ein „na und“?
Nun, für den Umzug des komplett überarbeiteten und auf einer neuen Architektur aufbauenden Web-Crawlers zu App Search auf Elastic Cloud gibt es mehrere überzeugende Argumente:
- Ruhiger Schlaf mit Zusatzvorteilen: Als verwalteter Dienst für Elasticsearch und Kibana bietet Elastic Cloud die überragende Geschwindigkeit, Skalierbarkeit und Relevanz, die zum Markenzeichen von Elastic geworden ist. 1-Klick-Upgrades, einfaches Skalieren und Index-Lifecycle-Management (ILM) sind nur ein paar der Gründe, die Kunden in Scharen zu Elastic Cloud treiben. Und wenn Sie bereits Elastic Observability- oder Elastic Security-Kunde sind, können Sie Ihr gesamtes Deployment in einer leistungsfähigen zentralen Konsole verwalten.
- Ihre Daten, Ihre Wahl: Elastic Cloud ist in mehr als 40 Regionen weltweit bei den Top-Cloud-Anbietern dieser Erde verfügbar: Google Cloud (GCP), Microsoft Azure und Amazon Web Services (AWS). Ihre Daten, Ihre Cloud, Ihr Stil.
- Preisstruktur: Mit dem neuartigen ressourcenbasierten Preismodell von Elastic brauchen Sie sich keine Gedanken über obskure Metriken wie Nutzerzahl, Abfragenzahl, Dokumentengröße oder installierte Agents mehr zu machen. Ihre Kosten errechnen sich aus den Hardwareressourcen, die Sie für das Speichern, Durchsuchen und Analysieren Ihrer Daten nutzen – unabhängig von Ihrem Anwendungsfall.
Auch wenn es in diesem Blogpost vorrangig um Cloud-Deployments geht, möchten wir nicht versäumen, darauf hinzuweisen, dass der Web-Crawler jetzt auch für selbstverwaltete Deployments bereitsteht – eine Option, die bei Elastic Site Search (oder Swiftype) nicht angeboten wird.
Was tut der Web-Crawler nun eigentlich?
Bevor wir uns damit beschäftigen, wie wir den Web-Crawler einrichten können, sollten wir uns ansehen, wofür er verwendet werden kann, also was er sich von den öffentlichen Websites holt, die Sie angegeben haben.
Der Web-Crawler funktioniert wie folgt: Sie geben ihm eine URL vor, z. B. https://www.elastic.co, und der Web-Crawler besucht diese Webseite. Dort folgt er dann jedem neuen Link, den er auf dieser Seite findet, und extrahiert die Inhalte für das Ingestieren in Ihre App Search-Engine. Das nennt man „Content-Discovery“. Jeder so gefundene Link wird auf die gleiche Weise gecrawlt. Das Baumdiagramm zeigt, wie das ganz allgemein funktioniert.
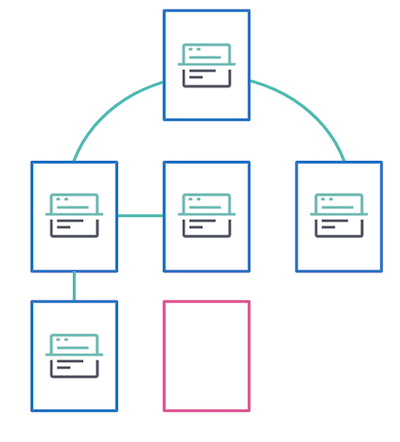
Die in der obigen Abbildung blau dargestellten Seiten, sind die, die bereits gecrawlt und indexiert worden sind. Allerdings hat keine der Seiten zur pinken Seite verlinkt, sodass diese nicht gecrawlt oder indexiert wird. Damit der Web-Crawler eine Seite besuchen kann, die nicht verknüpft ist, muss diese direkt als Eintrittspunkt bereitgestellt werden oder Teil einer Sitemap sein. Das Einrichten von Eintrittspunkten besprechen wir weiter unten.
Welche Inhaltsarten können extrahiert werden?
Mit der Beta-Version des Web-Crawlers können die folgenden Arten von Inhalten aus HTML-Seiten extrahiert werden:
- Titel der Seite
- Beschreibung (Metadaten)
- Keywords (Metadaten)
- Textkörper (normalisiert, ohne die HTML-Tags)
- kanonische URL
- zusätzliche URLs (für dasselbe Dokument)
- Links
Praktische Anleitung: Erste Schritte mit dem Web-Crawler

Beginnen wir am Anfang: Wir erstellen ein neues Elastic Enterprise Search-Deployment auf Elastic Cloud. Denjenigen unter Ihnen, die derzeit Elastic Site Search oder Swiftype verwenden oder die noch kein Elastic Cloud-Konto haben, lege ich das Angebot ans Herz, Elastic Cloud 14 Tage lang kostenlos auszuprobieren, um den Web-Crawler mit eigenen Augen zu erleben.
- Gehen Sie zu www.elastic.co und klicken Sie rechts oben auf „Anmelden“.
- Wählen Sie aus den angebotenen SSO-Methoden eine Methode aus oder erstellen Sie ein neues Konto.
- Klicken Sie nach dem Einloggen auf „Create deployment“.
- Wählen Sie die Elastic Enterprise Search-Deployment-Vorlage aus. Diese Vorlage ist für CPU-Ausgabe, Speicherung und Verfügbarkeitszonen optimiert. Alle Deployment-Vorlagen können im Anschluss an die Deployment-Erstellung an die jeweiligen konkreten Anforderungen angepasst werden.
- Wählen Sie aus der Liste Ihren Cloud-Anbieter aus. Sie können zwischen Google Cloud (GCP), Microsoft Azure oder Amazon Web Services (AWS) wählen.
- Geben Sie Ihrem Deployment einen Namen und klicken Sie dann auf „Create Deployment“.
- Sie erhalten eine Meldung, dass Ihr Deployment erstellt wurde.
Glückwunsch! Das war der erste Schritt zur Einrichtung Ihrer ersten App Search-Engine.
Die Lösung Elastic Enterprise Search besteht aus zwei Anwendungen: App Search und Workplace Search. Für die Zwecke dieses Tutorials klicken Sie bitte auf „Launch App Search“.
Bravo! Sie sind jetzt in App Search und können mit dem Erstellen eines Web-Crawlers beginnen.
Der Onboarding-Workflow hilft beim Erstellen Ihrer ersten Suchmaschine. Nachdem Sie einen Namen für Ihre Suchmaschine eingegeben haben (wir verwenden hier „my-elastic-search-engine“) erscheint ein Bildschirm, in dem Ihnen vier Möglichkeiten zum Ingestieren Ihrer Daten angeboten werden: JSON einfügen, JSON-Datei hochladen, nach API indexieren oder den Web-Crawler verwenden. Sie wissen inzwischen, welche Sie wählen sollten.
Jetzt können Sie Ihre eigene Website hinzufügen oder aus Spaß einmal Elastic.co als Domain-URL für den Web-Crawler festlegen. Nicht vergessen: Der Web-Crawler besucht die angegebene Webseite, wenn Sie die URL eingeben, und extrahiert auf seinem Weg alle Inhalte, die er findet. Von der angegebenen URL aus folgt er jedem neuen Link zu den gefundenen Seiten, bis er irgendwann einmal nicht mehr weiterkommt.
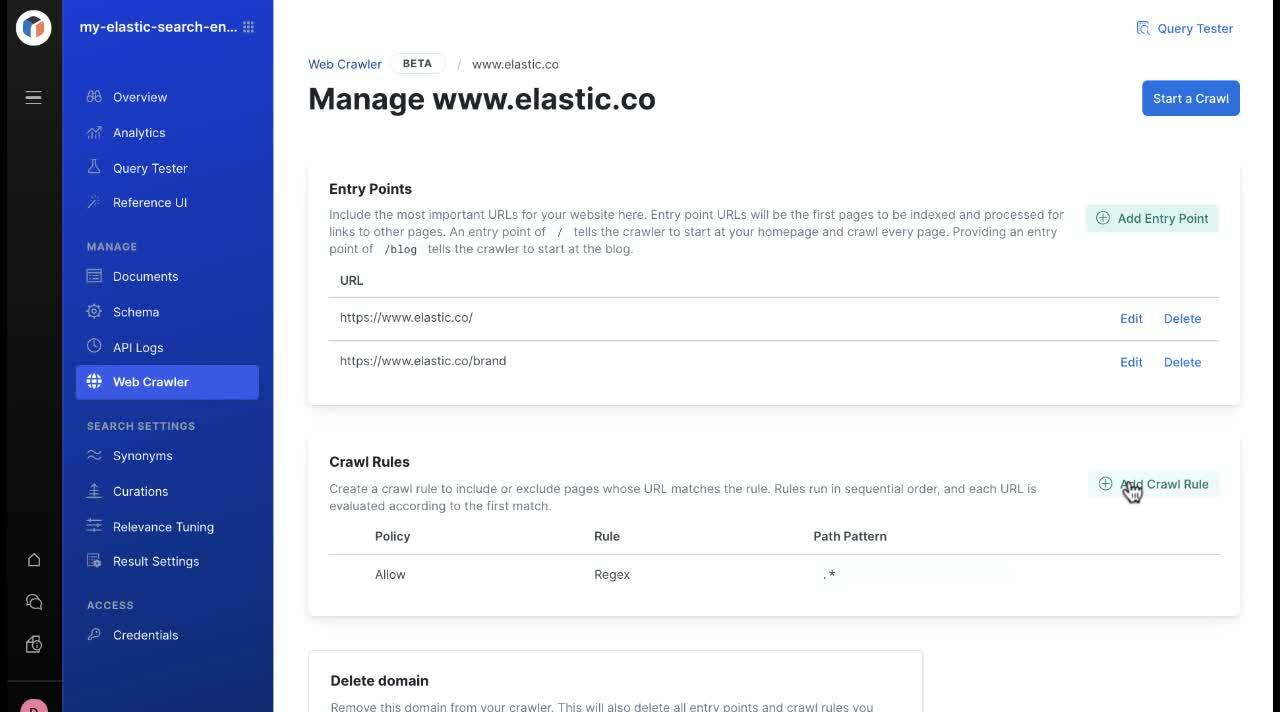
An dieser Stelle müssen wir noch einmal auf die Eintrittspunkt-Funktion („Entry Points“) zu sprechen kommen. Wenn es eine „Insel“-Seite gibt, auf die nicht von anderen Seiten verlinkt wird, fügen Sie einfach deren URL als Eintrittspunkt hinzu. Der Web-Crawler indexiert dann den Inhalt der Seite und folgt allen neuen Links, um die Inhalte zu extrahieren – bis er in eine Sackgasse gerät.
Auf derselben Konsolenseite können Sie Regeln für das Crawlen festlegen. Diese Regeln erlauben es Administratoren, bestimmte Seiten-URLs ein- oder auszuschließen. Nehmen wir beispielsweise einmal an, Ihre Marketing-Abteilung arbeitet mit Kampagnen-Landingpages und nutzt dafür das Pfadmuster „/lp“. Diese Landingpages eignen sich gut für die Akquise neuer Kunden über zielgenaue Inhalte, aber Sie möchten diese Inhalte nicht in Ihrer Suchmaschine haben.
In diesem Fall können Sie im Abschnitt zur Einrichtung von Crawl-Regeln eine neue Richtlinie festlegen, die das Indexieren von Inhalten mit URL-Pfaden untersagt, die „/lp“ enthalten.
Jetzt wird es spannend – es geht ans Crawlen! Klicken Sie, sobald Sie alle Eintrittspunkte und Crawling-Regeln festgelegt haben, auf die Schaltfläche Start a Crawl.
Klicken Sie auf den Tab „Documents“ und sehen Sie zu, wie Ihre Inhalte in die App Search-Suchmaschine ingestiert werden. Oder klicken Sie auf das „Query Tester“-Symbol rechts oben, um Ihre Suchmaschine von jedem Punkt der App Search-Benutzeroberfläche aus zu durchsuchen.
Wenn Sie Ihre Ergebnisse sofort in einem Suchfeld testen möchten, klicken Sie auf den Tab „Reference UI“. Hier finden Sie ein fertig vorkonfiguriertes Suchfeld auf React-Basis. Oder Sie nutzen die Elastic Search UI-JavaScript-Bibliotheken, um Ihre eigene Suchfunktion zu erstellen und anzupassen.
Jetzt sind Sie dran!
Wir glauben und hoffen, dass Ihnen das so leistungsfähige wie einfache Design des Web-Crawlers gefällt. Jetzt sind Sie dran, den Web-Crawler auszuprobieren!
Der Elastic App Search-Web-Crawler wird derzeit als Beta-Version bereitgestellt und steht in allen Abonnementstufen zur Verfügung, gleich, ob das Deployment selbstverwaltet ist oder Elastic Cloud genutzt wird. Wenn Sie bereits ein Elastic Cloud-Kunde sind, können Sie direkt von der Elastic Cloud-Konsole aus auf Enterprise Search zugreifen.
Elastic Cloud ist Neuland für Sie? Dann empfehlen wir Ihnen, sich unsere „Quick Starts“ anzusehen – kurze Schulungsvideos für einen schnellen Einstieg – und sich dann für das kostenlose 14-tägige Elastic Enterprise Search-Probeabo zu registrieren. Alternativ können Sie auch kostenlos die selbstverwalteten Versionen von App Search oder Workplace Search herunterladen.
Ressourcen:
Blog: Was gibts Neues in Elastic Enterprise Search?: Web-Crawler und Box als Inhaltsqellen
Dokumentation: App Search: Web-Crawler
Erste Schritte: Elastic Cloud: 14 Tage lang kostenlos ausprobieren