Searching billions of documents
With Elastic, GitHub delivers search at scale, leveraging semantic search to provide efficient, fast discovery across more than 395 million code repositories and billions of documents.
Queries from humans and AI
GitHub uses semantic search to better understand search queries that use natural language for stronger communication with both human users and AI systems.
Reducing zero-hit searches
With Elastic, GitHub reduces the number of search results with zero hits and improves click-through rates, connecting users with the right information faster.
GitHub uses Elasticsearch to implement semantic search across billions of documents in its code platform, helping users quickly find the resources they need
GitHub is the world's largest host of code. Over 180 million developers worldwide at 4 million organizations, including 90% of the Fortune 100 companies, rely on GitHub to build, scale, and deliver software. The result is a massive platform hosting more than 395 million code repositories with billions of documents that include vital information like source code, patch notes, discussions, and wikis.
Search is a critical capability for GitHub. It's the primary way users find what they need, whether they're looking for specific open source packages, checking updates from a favorite user, or browsing for APIs to expand functionality of a project. "Search is essential for our users, both internal teams and our customers," says David Tippett, senior search engineer at GitHub. "We have vast resources available, but it means nothing if people can't find what they need."
GitHub traditionally relied heavily on keyword search, which worked well when developers knew exactly what they were looking for — such as specific function names or repository identifiers. However, search behavior has shifted significantly. Developers are increasingly asking longer, natural-language questions, and AI systems like developer assistants and agents now interact with GitHub data as first-class clients.
This shift has exposed the limitations of keyword-based search. Natural-language queries often return poor or even zero results, and AI-driven workflows struggle to generate precise keyword queries. As a result, these systems require more context-aware retrieval to be effective.
Recognizing this change, Tippett emphasized the importance of incorporating reliable semantic search. "People are changing how they search. They're asking questions in natural language, and they expect sites to understand how they talk," he says.
GitHub became an early adopter of Elastic for semantic search. Using Elasticsearch on Elastic Cloud, GitHub is helping to develop the next generation of search at scale.

Understanding humans and AI with natural language
Semantic search adds new capabilities to GitHub. Search results now elevate close matches, without engineers needing to spend hours upkeeping synonym databases for keyword search. As a result, GitHub dramatically reduced the number of searches that come back with zero hits. Users are less frustrated because they can find what they need faster.
Critically, semantic search also allows GitHub to handle natural language queries by understanding the context and intent behind what people ask. This is especially important in the growing age of AI where more people interact with GitHub through agents and other tools.
"Semantic search allows us to better understand people and the AI solutions they are working with," explains Tippett. "Elastic helps us support different types of queries while improving click-through rates, proving that we're helping people find the information they want to see."
"The fact that we can run a search platform used by hundreds of millions of users with a team of about five or six engineers is mind-blowing."
Scaling semantic search across GitHub
GitHub generates embeddings for its content in the issues system and stores them in Elasticsearch. When users search, their queries are compared against stored vectors, allowing Elasticsearch to return results based on semantic similarity rather than exact keyword matches.
Tippett praises Elastic for constantly updating its features with new functionality. GitHub adopted BBQ (Better Binary Quantization) as soon as it became production ready. By compressing high-dimensional vectors by 32x, BBQ dramatically reduces memory footprint, lowering infrastructure costs while improving query latency at scale. To maintain retrieval quality while benefiting from compression, GitHub pairs BBQ with oversampling and rescoring, allowing Elasticsearch to return highly relevant results while keeping latency and infrastructure requirements manageable at scale. For GitHub, this means much more affordable search operations even as the platform continues to scale.
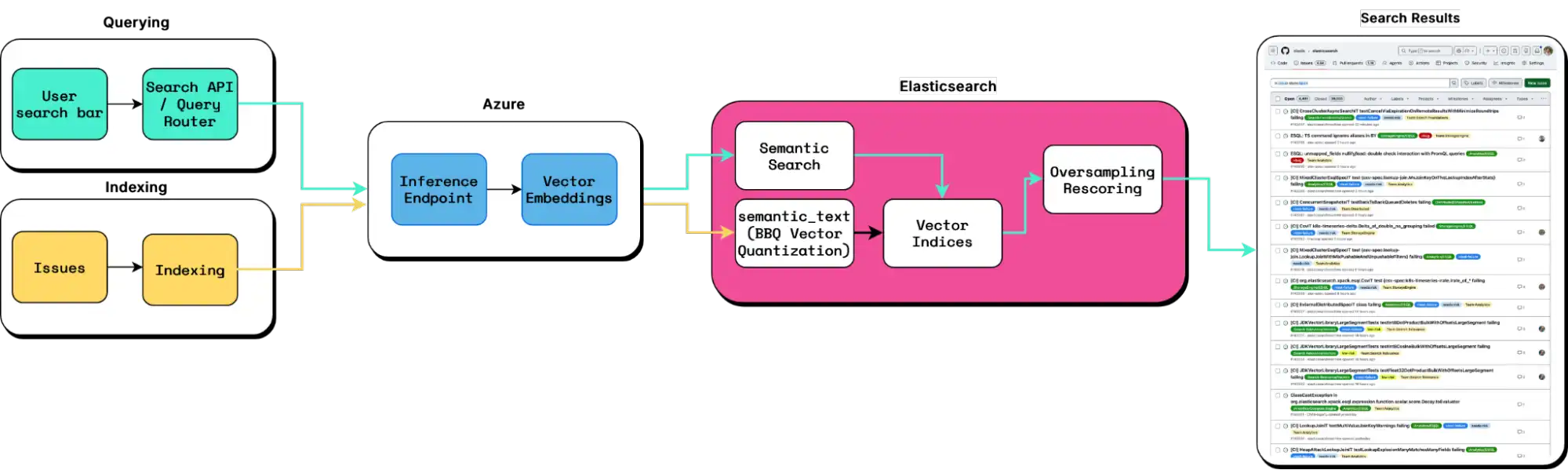
Elastic also makes development much easier with its wide range of built-in capabilities and development tools. GitHub teams especially like the Dev Tools Console in Kibana, which allows developers to easily run APIs, test queries, and debug responses to fine-tune custom search experiences before they ever hit production.
"Our software engineers aren't all search experts, and there can be a big learning curve with semantic search," says Tippett. "Kibana and features like autocomplete provide the freedom to explore and learn hands-on as users get up to speed on what Elastic and semantic search can do for them."
GitHub's platform team designed the rollout to make semantic search easy for internal teams to adopt. They started with Issues as the first production rollout, and then built a repeatable onboarding pipeline so other internal teams can adopt semantic search faster and more safely. "The fact that we can run a search platform used by hundreds of millions of users with a team of about five or six engineers is mind-blowing," says Tippett.
Tippett and his platform team developed an automated script that creates interference endpoints, deploys Kibana, loads indices, and prepares a development environment where teams can start testing semantic search almost immediately.
Now teams can onboard themselves with a click and start experimenting with semantic search in a controlled development environment, leading to even more innovation. "There's a lot of energy internally at GitHub. Everyone's very excited to see what Elastic and semantic search can do for internal workflows and product development, as well as for our customers."
"With Elastic and semantic search, our users can take full advantage of the largest code resource in the world to develop the future together."
Creating search for scale
Tippett also takes pride in how GitHub contributes to Elastic's development. As an early adopter operating on a very large scale, the company regularly pushes the limits of what search can do. The Elastic team is always there to work alongside developers, helping them overcome challenges and listening to feedback for what a massive enterprise operation really needs.
"It's been a very collaborative experience working with Elastic," says Tippett. "Whether we're talking to leadership or chatting with other members of the Elastic community, we get the expert advice we need to understand how Elastic works and find ways to do things better at scale."
Looking to the future, Tippett is particularly excited about using UBI (user behavior insights) standards with Elastic to provide developers clearer data about how adjustments improve search.
"One thing that I love about Elastic is that it always puts the user and their goals first," says Tippett. "For instance, search itself is never the goal. The goal is to help users find what they need. With Elastic and semantic search, our users can take full advantage of the largest code resource in the world to develop the future together."