Sizing for Machine Learning with Elasticsearch
Editor's Note (August 3, 2021): This post uses deprecated features. Please reference the map custom regions with reverse geocoding documentation for current instructions.
Many organizations have started using Elastic's machine learning for their Security Analytics, Operational Analytics, and other projects that make use of anomaly detection for time series data. One of the first questions we get from someone setting up machine learning is how to size their hardware and cluster most effectively.
Sizing your environment for machine learning requires that you already have some idea of how to size Elasticsearch. To begin sizing for machine learning you should already have done your sizing calculations for data collection, mappings, and indexes. We will not cover Elasticsearch sizing in this article, but there is an excellent video from from 2016 Elastic{ON} that would be useful to review.
Like many sizing questions, the sizing of hardware and cluster for machine learning depends on the use-case. There are many variables to consider when configuring machine learning. We can guide you through some of the best practices, but ultimately sizing is something that needs to be customized for your unique situation.
Questions that should be considered when sizing an environment for machine learning are:
- How much data do you have and how many Elasticsearch nodes are you using today?
- How many jobs do you want to run? In machine learning the basic work unit is defined as a 'job' and it contains the configuration information and metadata necessary to perform an analytics task. For example, if you have 10 unique data sets, and plan to create 5 jobs per data set, you want to plan for 50 jobs.
- How complex are the machine learning jobs you intend to run? For example, do you want to monitor your application's aggregate error code counts (single-metric) or error code counts per unique server (multi-metric)?
- Are you looking only at anomalies in historical data or do you intend to run machine learning live against incoming data?
- What bucket span for anomaly detection granularity are you going to use? Review how machine learning jobs use the bucket span
- What is the cardinality of the metrics used for the machine learning jobs? How many metrics and how many individual values are there for those metrics?
When you initially start working with machine learning, most of the time you don't know all the answers to these questions. Testing configurations is usually an iterative process to get the answers you need for sizing the necessary resources. It is a good idea to set up a lab environment first to try different configurations before moving to production.
Sizing a lab to experiment with machine learning
Acquire a sample data set for testing
When setting up a lab environment you will need to start by collecting enough data to establish a model for machine learning. A good model for testing the subset should contain at least three weeks worth of data. When testing we recommend using actual data from one of your production systems rather than synthetic data. For machine learning testing, carve off a subset of data by a few devices over 3 or more weeks rather than pull an entire data set for a few days.
Hardware resources for lab testing
For lab configurations you don't have to run dedicated machine learning (ML) nodes; by default, any node with X-Pack installed will be able to run machine learning jobs. However, in production, we strongly recommend using dedicated ML nodes, as machine learning processing requires additional CPU and memory. Running a single job may use up to 4GB of memory with the default configuration in addition to what Elasticsearch utilizes for memory.
If utilizing existing Elasticsearch data nodes in the lab there needs to be enough headroom available in both RAM and CPU. The amount of headroom that is required is wholly dependent on the volume and complexity of the data you expect machine learning to analyze and the type(s) of analysis chosen for that data. In general, the more data volume, the more CPU is required. The greater the complexity of the data/analysis, the more RAM required.
There are many variables involved so it might be prudent to start "simple" with your machine learning configurations and move up in complexity as you watch your cluster performance along the way.
Types of machine learning jobs and how they affect system resources
Single metric machine learning jobs consume the least hardware resources of the different types of jobs. They can often consume less than 1mb of memory and a few seconds of compute time once per time bucket span because there are not many variables. The machine learning job only needs to pull the metrics per bucket span. If you are doing mostly single metric jobs, you will probably want to increase the job limit from the default limit of 10 (in the configuration settings).
Multivariate machine learning jobs can be configured through the multi-metric or advanced option within the Kibana interface. These jobs can consume significantly more memory than single metric jobs because of the number of variables they need to evaluate. The machine learning algorithms model each selected metric for each unique term in the selected "split data" field. Each individual model is very efficient, but the total number of models is the aggregate of metric counts multiplied by the cardinality of the split data field. As a result, these jobs can be highly variable in the amount of compute and memory they consume. We do not recommend using a split data field with more than 10k unique values. For fields with higher cardinality you should consider if it would be better to look into using an advanced machine learning job like population analysis.
If the split data field has a low cardinality (ie less than 100 unique values), these jobs consume a few megabytes of memory. If the split data field has high cardinality, these may consume gigabytes of memory and require using the advanced configuration editor to increase the max model size for the job (via model_size_limit configuration setting).
Moving machine learning jobs to production
Once you have prepared your test configuration and have some base line statistics on resources required to run your machine learning jobs, it is now time to scale out to your production cluster.
Production hardware recommendations
We recommend that ML nodes have at least 4 Cores and 64GB RAM. Assign 24GB of memory to the JVM Heap, reserving 40GB for ML processing. Machine learning jobs use memory outside of the JVM heap. Increasing the number of cores and RAM will let you run more jobs. Dedicated ML nodes do not require significant storage - the raw data and ML indexes are stored on data nodes.
Load added to the Elasticsearch cluster nodes
When moving to a production cluster it is important to understand the added search load on existing Elasticsearch data nodes. There are two ways that machine learning jobs will affect data nodes:
- 1. Retrieving data for analysis
Jobs pull in data periodically, based on the bucket span configured with the job. This is done by a data feed that searches the cluster for new data every bucket span interval. For real-time jobs, this is a very light load. However, when running on historic data, the ML jobs may be processing many buckets quickly, so the number of requests can be a high overhead on the cluster depending on the volume and historical time frame.
- 2. Retrieving and updating previous results for "re-normalization"
When an ML job finishes processing a bucket, it retrieves the previous results over the last 30 days and checks to see if historic anomaly scores should be updated based on the new data we have seen. This helps ensure look-back jobs have appropriate anomaly scores while the model is learning what anomalies look like in the dataset. This renormalization process can result in many queries and may be significant when running on historic data. When running in real-time, there should be relatively light overhead on the cluster.
Number of dedicated ML nodes for a production cluster
For high availability it is recommended to start with a minimum of two dedicated ML nodes in a production cluster. Continue to add another dedicated ML node for every 25 Elasticsearch data nodes under normal use. New ML nodes can be added to the cluster at any time, just like data nodes.
The default configuration for ML nodes is to allow a maximum of 10 concurrent ML jobs. The maximum number of jobs is a setting in the elasticsearch.yml configuration file that can be adjusted as indicated in configuration settings section below.
The maximum number of running jobs across the cluster goes up for every ML-capable node. For a cluster with 5 dedicated ML nodes, the maximum would be 50 concurrent ML jobs with the default settings. When configuring for high availability, you should not go over the maximum number minus one node, for example with the 5 dedicated ML nodes we would recommend configuring only 40 concurrent jobs for high availability.
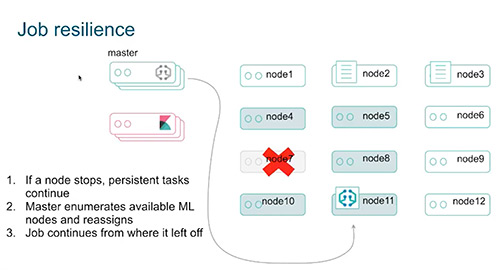
Machine learning has intelligence built in to acknowledge and reroute ML jobs in case of a failure. New ML jobs will be assigned to the ML-capable node with the least number of assigned jobs running on it unless that node already has hit its maximum limit. If a node goes down in the middle of running an ML job then another ML-capable node will find the job and start running it.
Configuration settings to manage ML nodes and jobs
The following settings are set in elasticsearch.yml for configuring ML resource usage:
node.ml: true
- If false, the node cannot open a job or start a data feed. No machine learning analytical processing will be performed on this node, but the node can respond to API requests.
- The default value is true (providing xpack.ml.enabled: true).
- This setting is per node and it requires node restart to take effect.
max_running_jobs: 10
- This setting controls the number of jobs in an open state. It limits the number of jobs that have been launched and the model state is held in memory. An open job is able to accept data and process it.
- This value can be increased 2-3X if the cluster has a lot of extra memory or if there are mostly single-metric ML jobs.
- The default value is 10 per Elasticsearch node that has enabled machine learning.
- This is a cluster wide setting, but requires nodes to be restarted to take effect.
xpack.ml.node_concurrent_job_allocations: 2
- Controls the number of jobs that are concurrently opening. For jobs that are being re-opened, if they have a large model state, then the act of opening a job and reading in this state takes up resources. Therefore we limit the concurrent number of opening jobs. For new jobs and small jobs this will take milliseconds to seconds.
- The default value is 2.
- This is a cluster-wide setting.
The following are set per job in job configuration:
model_size_limit: 4096
- Controls the approximate limit for the maximum required memory resources for the model state and persistence tasks.
- The size limit value is in MB, with the default being 4096 MB.
- This setting can be updated (increased) after job creation and requires job to be closed and reopened in order to take effect.
Resources
Machine Learning comes with an Elastic Platinum subscription, but you can download a free trial of X-Pack and try it out
Get a full machine learning product tour in the webinar
Try Elastic's machine learning video series:
Take the X-Pack online machine learning training (Free for a limited time)