Should I use Logstash or Elasticsearch ingest nodes?
Logstash was one of the original components of the Elastic Stack, and has long been the tool to use when needing to parse, enrich or process data. Over the years, a great number of input, output and filter plugins have been added, making it an extremely flexible and powerful tool that can be made to work in a variety of different architectures.
Ingest nodes were introduced in Elasticsearch 5.0 as a way to process documents in Elasticsearch prior to indexing. They allow simple architectures with minimum components, where applications send data directly to Elasticsearch for processing and indexing. This often simplifies getting started with the Elastic Stack, but will also scale out as data volumes grow.
The ingest node does however duplicate some of the functionality in Logstash, so a common question from our users have been which one they should use. In this blog post we discuss the architectural aspects you need to consider when choosing between the two with the aim to help you make a better informed decision.
This is the third installment in our series around common questions our users have. The previous were:
- How many shards should I have in my Elasticsearch cluster?
- Why am I seeing bulk rejections in my Elasticsearch cluster?
How do I get data in and out?
One of the major differences between Logstash and ingest node is how data gets in and out.
As ingest node runs within the indexing flow in Elasticsearch, data has to be pushed to it through bulk or indexing requests. There must therefore be a process actively writing data to Elasticsearch. An ingest node is not able to pull data from an external source, such as a message queue or a database.
A similar restriction exists after the data has been processed - the only option is to index data locally into Elasticsearch.
Logstash, on the other hand, has a wide variety of input and output plugins, and can be used to support a range of different architectures. It can act as a server and accept data pushed by clients over TCP, UDP and HTTP, as well as actively pull data from e.g. databases and message queues. When it comes to output there is a wide variety of options available, e.g. message queues like Kafka and RabbitMQ or long-term data archival on S3 or HDFS.
What about queueing and back-pressure?
When sending data to Elasticsearch, whether it is directly or via an ingest pipeline, every client needs to be able to handle the case when Elasticsearch is not able to keep up or accept more data. This is what we refer to as applying back-pressure. If the data nodes are not able to accept data, the ingest node will stop accepting data as well.
Architectures where there is no queueing mechanism built into the processing pipeline, either at the source or along the way, have the potential to suffer from data loss in the case Elasticsearch is not reachable or able to accept data for an extended period. This includes Beats that are not able to store and read data from file as well as other processes able to write directly to Elasticsearch, e.g. syslog-ng.
Logstash is able to queue data on disk using its persistent queues feature, allowing Logstash to provide at-least once delivery guarantees and buffer data locally through ingestion spikes. Logstash also supports integration with a number of different types of message queues, which allows a wide variety of deployment patterns to be supported.
How do I enrich and process my data?
Ingest node comes with over 20 different processors, covering the functionality of the most commonly used Logstash plugins. One limitation, however, is that the ingest node pipeline can only work in the context of a single event. Processors are also generally not able to call out to other systems or read data from disk, which somewhat limits the types of enrichment that can be performed.
Logstash has a significantly larger selection of plugins to choose from. This includes plugins to add or transform content based on lookups in configuration files, Elasticsearch or relational databases.
Beats and Logstash also support filtering out and dropping events based on configurable criteria, something that is not currently possible in ingest node.
Which one is easier to configure?
This is a very subjective topic, and depends on your background and what you are used to. Each ingest node pipeline is defined in a JSON document, which is stored in Elasticsearch. Large number of distinct pipelines can be defined, but each document can only be processed by a single pipeline when passing through the ingest node. This format might be a bit easier to work with than the Logstash configuration file format, at least for reasonably simple and well-defined pipelines. For more complex pipelines handling multiple data formats, the fact that Logstash allows the use of conditionals to control flow often make it easier to use. Logstash also has support for defining multiple logically separate pipelines, which can be managed through a Kibana-based user interface.
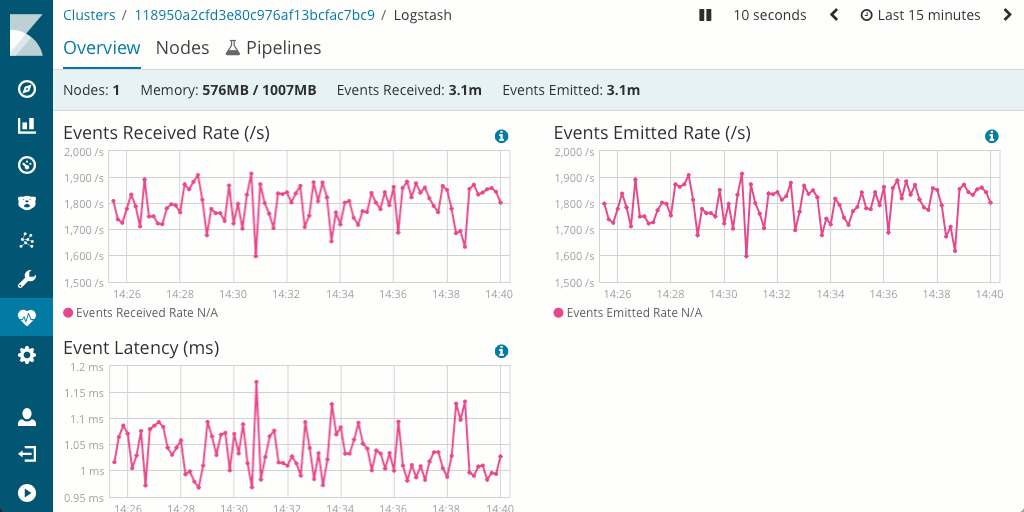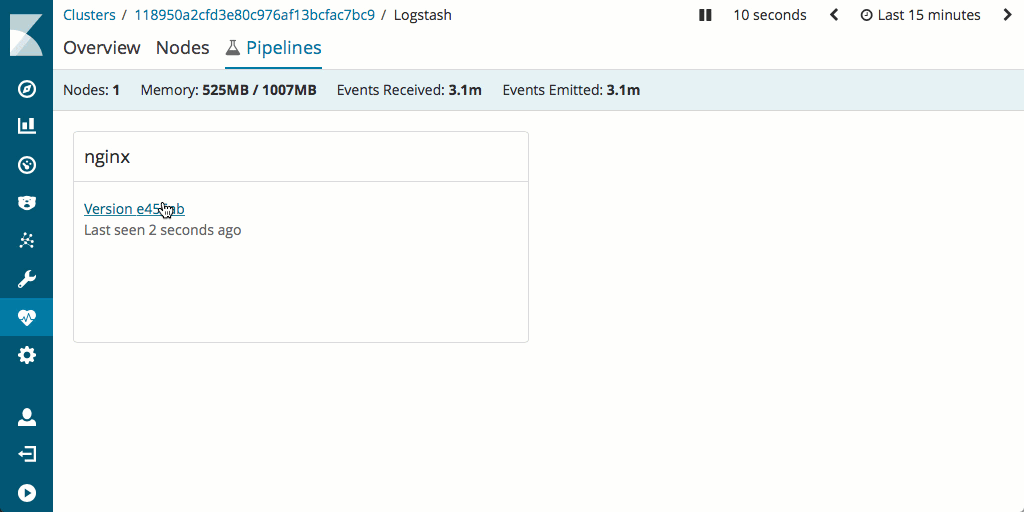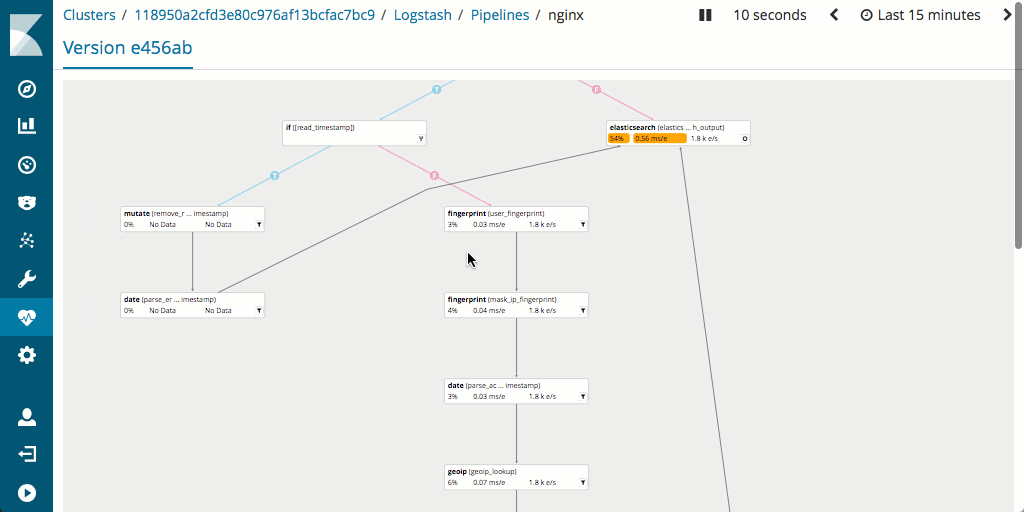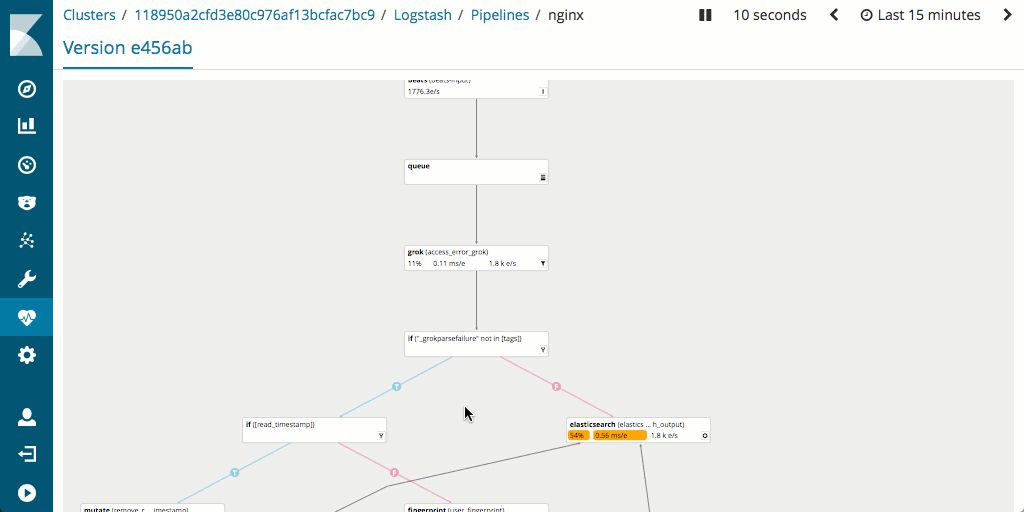
It is also worth noting that measuring and optimizing performance of the pipeline is generally easier in Logstash as it supports monitoring and has an excellent pipeline viewer UI that can be used to find bottlenecks and potential issues quickly.
How is the hardware footprint affected?
One of the great things about ingest node is that it allows very simple architectures, where Beats can write directly to an ingest node pipeline. Every node in an Elasticsearch cluster can act as an ingest node, which can keep the hardware footprint down and reduces the complexity of the architecture, at least for smaller use cases.
Once data volumes grows or processing gets more complex, resulting in higher CPU load in the cluster, it is generally recommended to switch to using dedicated ingest nodes. At this point additional hardware will be required either to host the dedicated ingest nodes or Logstash, and any difference in hardware footprint will depend a lot on the use case.
Can ingest node do anything Logstash can’t?
So far it seems like ingest node just offers a subset of the functionality that Logstash supports - this is, however, not entirely accurate.
The ingest node supports the ingest attachment processor plugin, which can be used to process and index attachments in common formats, e.g. PPT, XLS, and PDF. There is currently no equivalent plugin available for Logstash, so if you are planning on indexing various types of attachments, ingest node may be required.
As the ingest pipeline executes just before the data is indexed, it is also the most reliable method of adding a timestamp indicating when the event was indexed, e.g. in order to accurately measure and analyse ingest delays. Setting this before the data has successfully reached Elasticsearch could be misleading as there could be a delay between the timestamp being set and the data being indexed into Elasticsearch, e.g. if back-pressure is being applied or the client is forced to retry indexing the data multiple times. This type of timestamp can be used to measure the ingest delay per document.
Can I use Logstash and Ingest node together?
Even though the choice is often one over the other, it is naturally possible to also use them both together as Logstash supports sending data to an ingest pipeline. For more complex architectures there may also be multiple logical flows which may have very different requirements. Some may go through Logstash while others are sent directly to Elasticsearch ingest nodes. Using the one that makes most sense for each data stream will generally make the architecture easier to maintain.
Conclusions
There is overlap in functionality between Logstash and the Elasticsearch ingest node. This means that some architectures can be implemented with either technology. Both options however come with different sets of strengths and weaknesses, so it is important to analyse the requirements and architecture of your entire processing pipeline and select the most appropriate based on the criteria discussed in this blog post. The choice is not always one over the other, as they may be used together or in parallel for different parts of the processing pipeline.