NLP For Security: Malicious Language Processing
Editor’s Note: Elastic joined forces with Endgame in October 2019, and has migrated some of the Endgame blog content to elastic.co. See Elastic Security to learn more about our integrated security solutions.
Natural Language Processing (NLP) is a diverse field in computer science dedicated to automatically parsing and processing human language. NLP has been used to perform authorship attribution and sentiment analysis, as well as being a core function of IBM’s Watson and Apple’s Siri. NLP research is thriving due to the massive amounts of diverse text sources (e.g., Twitter and Wikipedia) and multiple disciplines using text analytics to derive insights. However, NLP can be used for more than human language processing and can be applied to any written text. Data scientists at Endgame apply NLP to security by building upon advanced NLP techniques to better identify and understand malicious code, moving toward an NLP methodology specifically designed for malware analysis—a Malicious Language Processing framework. The goal of this Malicious Language Processing framework is to operationalize NLP to address one of the security domain’s most challenging big data problems by automating and expediting the identification of malicious code hidden within benign code.
How is NLP used in InfoSec?
Before we delve into how Endgame leverages NLP, let’s explore a few different ways others have used it to tackle information security problems:
- Domain Generation Algorithm classification – Using NLP to identify malicious domains (e.g., blbwpvcyztrepfue.ru) from benign domains (e.g., cnn.com)
- Source Code Vulnerability Analysis – Determining function patterns associated with known vulnerabilities, then using NLP to identify other potentially vulnerable code segments.
- Phishing Identification – A bag-of-words model determines the probability an email message contains a phishing attempt or not.
- Malware Family Analysis –Topic modeling techniques assign samples of malware to families, as discussed in my colleague Phil Roth’s previous blog.
Over the rest of this post, I’ll discuss how Endgame data scientists are using Malicious Language Processing to discover malicious language hidden within benign code.
Data Acquisition/Corpus Building
In order to perform NLP you must have a corpus, or collection of documents. While this is relatively straightforward in traditional NLP (e.g., APIs and web scraping) it is not necessarily the same in malware analysis. There are two primary techniques used to get data from malicious binaries: static and dynamic analysis.
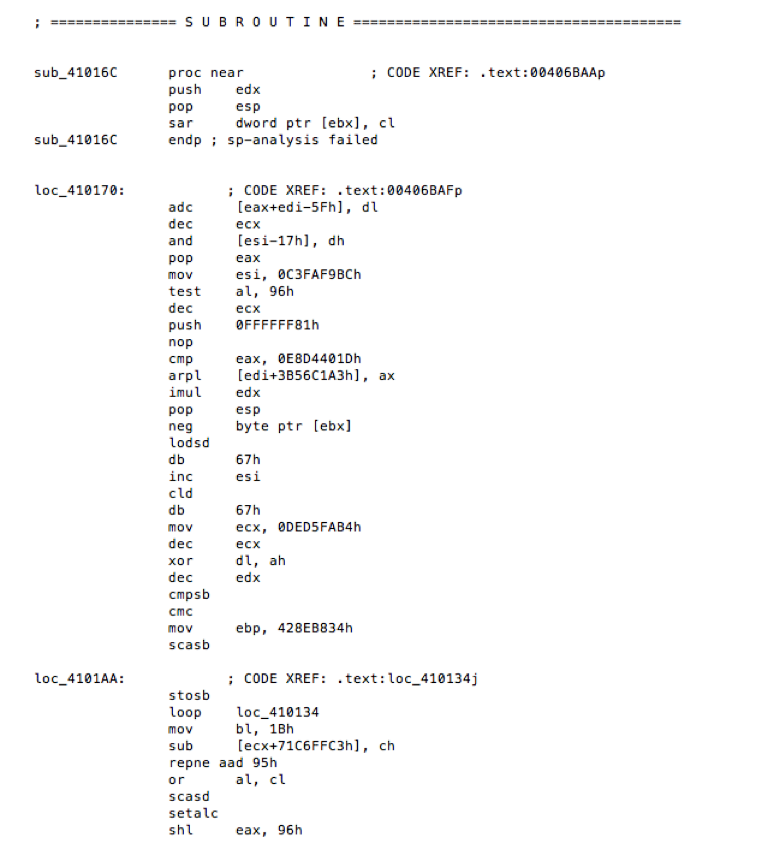
Fig 1. Disassembled source code
Static analysis, also called source code analysis, is performed using adisassembler providing output similar to the above (Fig 1). The disassembler presents a flat view of a binary, however structurally we lose important contextual information by not clearly delineating the logical order of instructions. In disassembly, jmp or call instructions should lead to different blocks of code that a standard flat file misrepresents. Luckily, static analysis tools exist that can provide call graphs that provide logical flow of instructions via a directed graph, like this and this.
Dynamic analysis, often called behavioral analysis, is the collection of metadata from an executed binary in a sandbox environment. Dynamic analysis can provide data such as network access, registry/file activity, and API function monitoring. While dynamic analysis is often more informative, it is also more resource intensive, requiring a suite of collection tools and a sandboxed virtual environment. Alternatively, static analysis can be automated to generate disassembly over a large set of binaries generating a corpus ready for the NLP pipeline. At Endgame we have engineered a hybrid approach that automates the analysis of malicious binaries providing data scientists with metadata from both static and dynamic analysis.
Lexical Parsing
Lexical parsing is paramount to the NLP process as it provides the ability to turn large bodies of text into individual tokens. The goal of Malicious Language Processing is to parse a binary the same way an NLP researcher would parse a document:

To generate the “words” in this process we must perform a few traditional NLP techniques. First is tokenization, the process of breaking down a string of text into meaningful segments called tokens.Segmenting on whitespace, new line characters, punctuation or regular expressions can generate tokens. (Fig 2)
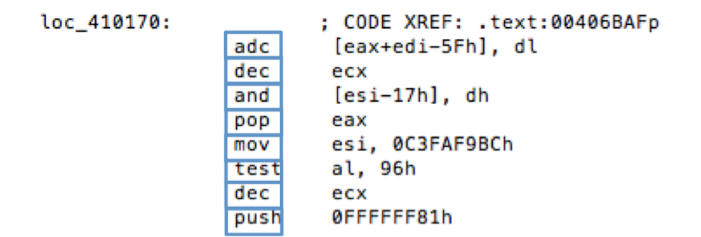
Fig 2. Tokenized disassembly
The next step in the lexical parsing process is to merge families of derivationally related words with similar meaning or text normalization. The two forms of this process are called stemming and lemmatization.
Stemming seeks to reduce a word to its functional stem. For example, in malware analysis this could reduce SetWindowTextA or SetWindowTextW to SetWindowText (Windows API), or JE, JLE, JNZ to JMP (x86 instructions) accounting for multiple variations of the essentially the same function.
Lemmatization is more difficult in general because it requires context or the part-of-speech tag of a word (e.g., noun, verb, etc.). In English, the word “better” has “good” as its lemma. In malware we do not yet have the luxury of parts-of-speech tagging, so lemmatization is not yet applicable. However, a rules-based dictionary that associates Windows API equivalents of C runtime functions may provide a step towards lemmatization, such as mapping _fread to ReadFile or _popen to CreateProcess.
Semantic Networks
Semantic or associative networks represent the co-occurrence of words within a body of text to gain an understanding of the semantic relationship between words. For each unique word in a corpus, a node is created on a directed graph. Links between words are generated with an associated weight based on the frequency that the two words co-occurred. The resulting graph can then be clustered to derive cliques or communities of functions that have similar behavior.
A malicious language semantic network could aid in the generation of a lexical database capability for malware similar to WordNet. WordNet is a lexical database of English nouns, verbs, and adjectives grouped into sets of cognitive synonyms. Endgame data scientists are in the incipient stages of exploring ways to search and identify synonyms or synsets of malicious functions. Additionally, we hope to leverage our version of WordNet in the development of lemmatization and the Parts-of-Speech tagging within the Malicious Language Processing framework.
Parts-of-Speech Tagging
Parts-of-Speech (POS) tagging is a piece of software capable of tagging a list of tokens in a string of text with the correct language annotation, such as noun, verb, etc. POS Tagging is crucial for gaining a better understanding of text and establishing semantic relationship within a corpus. Above I mentioned that there is currently no representation of POS tagging for malware. Source code may be too abstract to break down into nouns, prepositions or adjectives. However, it is possible to treat subroutines as “sentences” and gain an understanding of functions used as subjects, verb and predicates. Using pseudo code for a process injection in Windows, for example, would yield the following from a Malicious Language Processing POS-Tagger:

Closing Thoughts
While the majority of the concepts mentioned in this post are being leveraged by Endgame today to better understand malware behavior, there is still plenty of work to be done. The concept of Malicious Language Processing is still in its infancy. We are currently working hard to expand the Malicious Language Processing framework by developing a malicious stop word list (a list of the most common words/functions in a corpus of binaries) and creating an anomaly detector capable of determining which function(s) do not belong in a benign block of code. With more research and larger, more diverse corpuses, we will be able to understand the behavior and basic capabilities of a suspicious binary without executing or having a human reverse engineer it. We view NLP as an additional tool in a data scientist’s toolkit, and a powerful means by which we can apply data science to security problems, quickly parsing the malicious from the benign.