Machine learning for cybersecurity: only as effective as your implementation
We recently launched Elastic Security, combining the threat hunting and analytics tools from Elastic SIEM with the prevention and response features of Elastic Endpoint Security. This combined solution focuses on detecting and flexibly responding to security threats, with machine learning providing core capabilities for real-time protections, detections, and interactive hunting. But why are machine learning tools so important in information security? How is machine learning being applied? In this first of a two-part blog series, we’ll motivate the "why" and explore the "how," highlighting malware prevention via supervised machine learning in Elastic Endpoint Security. In a follow-up, we’ll highlight where machine learning plays a role in detecting anomalous behavior from the global view of Elastic SIEM.
Malicious activity: a case study
Even as the United States prepares for the 2020 election cycle, a three-year anniversary of an infamous cyber attack is still top of mind.
On Tuesday, March 15, 2016, threat actors allegedly from the advanced persistent threat (APT) Group 28 (aka “Fancy Bear”) began port scanning servers at the Democratic National Committee. This was part of a broader reconnaissance effort that adversaries commonly perform against a target. By Saturday, the adversary had delivered a spear-phishing email to the campaign chairman to gain access to his email account. Although recipients noted it as suspicious, the attack worked: by Monday, the threat group had compromised the chairman’s email account and stolen more than 50 thousand emails. Then, from a new email account created by attackers within the DNC domain (with a name similar to the account of a recognized DNC staffer), a spreadsheet named “candidate favorability ratings” was delivered to 30 DNC staffers. At least one recipient opened the spreadsheet and enabled a macro, which resulted in a local user account being hacked.
In the weeks that followed, a common playbook of tactics unfolded in what is now eponymously known as the DNC hack. Like other APT groups, while the specific techniques deployed are circumstantially tailored, the broader tactics are repeated in attack after attack (and thus codified by MITRE). The attack process typically follows some variation of the following steps:
- Human exploitation leads to account theft.
- Attackers establish persistence, use existing tools or install command-and-control malware (in the case of the DNC hack, X-Agent) that allow them to log keystrokes, take screenshots, and otherwise “land and expand” into other servers on the network.
- Attackers collect, compress, and consume a surfeit of data.
- Logs are scrubbed and digital footprints are delicately swept away.
- The threat group goes dormant, becoming difficult to fully root out, even if their presence is detected on a single device (in the case of the DNC hack, although X-Agent was disabled on June 20 — 97 days after the initial reconnaissance — a Linux version of the malware remained through October).
It’s not difficult to understand why unified protections and comprehensive event management are important in a case like this. Unfortunately, being compromised has become a fact of life, and security organizations aim to stop an attacker early in the execution of their plan. Thus, most of the energy traditionally spent in security has been toward detection mechanisms that reduce the dwell time of an attacker post-compromise. Since attacker tools and techniques vary, rules crafted for specific adversary techniques and machine learning trained to catch more general behaviors have been used to detect almost every point along the attacker’s natural progression from reconnaissance to delivery; exploitation to exfiltration.
The MITRE Corporation began developing a globally accessible knowledge base of adversary tactics and techniques (ATT&CK) based on real-world observations in 2014, which has now grown to codify 266 specific techniques, including many created or enhanced by community contributions of information. The MITRE ATT&CK matrix is now the most comprehensive adversary model and framework for describing the actions an adversary may take to compromise and operate within an enterprise network.

Why machine learning?
Machine learning offers an attractive paradigm for scaling the detection of adversarial behaviors and their tools, largely owing to the following:
- Automation — Coarsely, security has historically been tackled by throwing experts at data to produce rules, heuristics, and analytics in a repetitive process of cat-and-mouse. One natural outcome of machine learning is the repurposing of security experts to engineer automation processes — including machine learning training infrastructures — rather than spending cycles on the most repetitive tasks of detection creation. In this way, it’s the algorithms, not valued experts, that are tackling the mundane tasks, occasionally overseen, curated, and refined by security experts where appropriate.
- Discovery of sophisticated relationships — Human experts are still best positioned to pinpoint causal indicators of threat behavior. For example, a reverse engineer may disassemble and isolate a particular code block encapsulating nefarious behavior. However, machine learning is exceedingly good at finding useful correlations from data that can’t easily be discovered manually. For example, some combination of file size, imported functions, resource table usage, and properties of the .text section might isolate a 99.99% pure set of malicious files in the training data. While this isn’t a smoking gun for malicious behavior, it may offer enough evidence to convict a file, process, or user of malintent.
- Generalization with less brittleness — The discovered patterns tend to generalize toward new malware strains, similar tactics, or sketchy user behavior in a way that is less brittle than hand-crafted rules. Machine learning models are often shaped in a way that a file, process, or behavior is not convicted as a binary “good” or “bad,” but instead produces a score that smoothly transitions between areas convicted as “good” and areas convicted as “bad.” Importantly, a model is generated from the data. All real-world machine learning models are in some sense “wrong,” in that they do not perfectly summarize their training data. However, they are “useful” in their very specific task of rendering judgements on samples that are similar to those in their training set. They have “learned” to generalize.
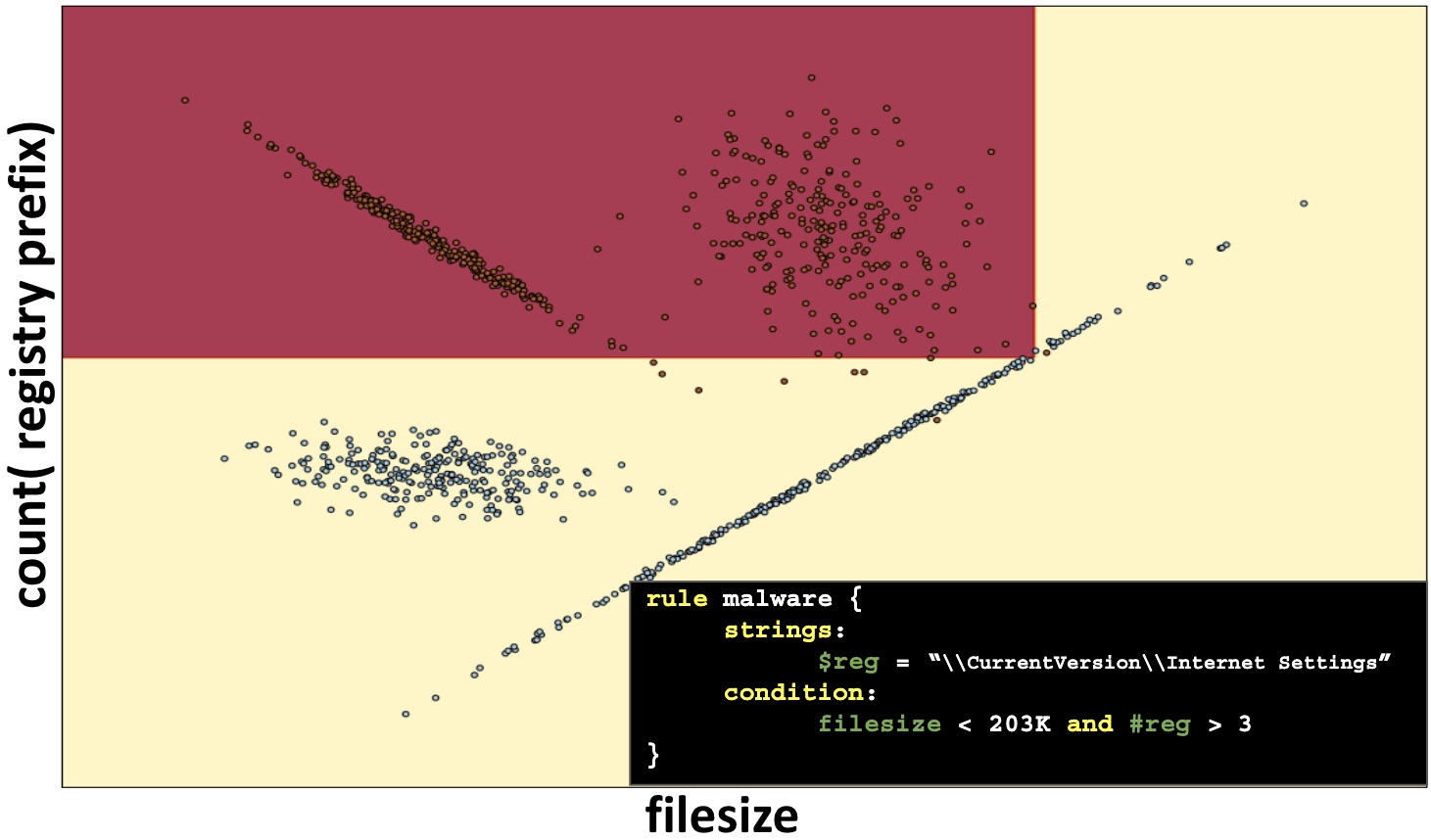
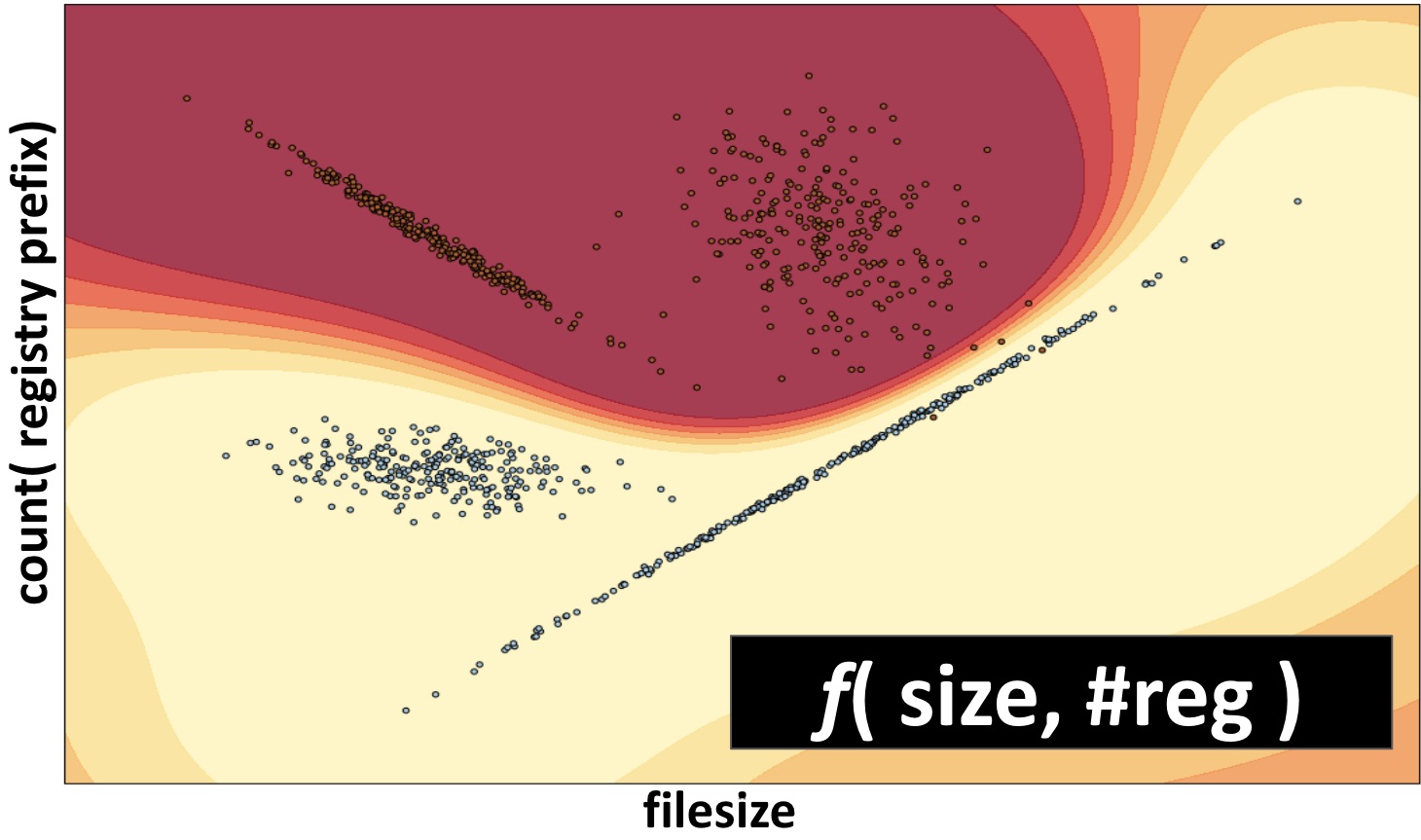
No free security lunch
Marketing campaigns notwithstanding, machine learning has generally been a benefit to security. But, the truth is that machine learning for security brings a number of substantive challenges:
- False positives — When compared to hand-crafted rules and heuristics, machine learning generally trades an increased “true positive rate” (detect new behavior) for a modest increase in false positives (FPs). While the FP rate is still less than, say, 1 in 2000, this is discouraging when the model chooses your favorite application to flag as malicious. “Fixing” a FP is not straightforward. To borrow a concept from Microsoft, the challenge of deploying machine learning is that “one doesn’t so much fix errors in ML as much as encourage toward the correct answer.” In fatalistic irony, FPs actually increase analyst workload, reducing the overall effectiveness of a solution, especially when defenders respond to FPs by the age-old approach of ignoring or turning off alerting.
- Explainability — In many cases, from a human’s perspective, the results of a machine learning model may seem incoherent or inconsistent. Trust is paramount in security, and the explainability of a model may be at odds with its sophistication and accuracy. Indeed, when offered, some explanations of model decision come across as trend diagnosis, e.g., “this file is malicious because of imports and high entropy in .text,” which does not provide a true explanation, but instead reinforces a notion that machine learning amounts to “bias automation.”
- Adversarial drift — Dataset drift in machine learning is present in many applications due to the natural evolution of observations. In security, where an adversary — a who not a what — is the focus of observed data, the drift is driven in an adversarial way: an adversary is incentivized to adjust behaviors to evade defensive detections. In this scenario, the fundamental assumption of machine learning — that the training conditions of a model are identical to deployment conditions — is broken. Instead, this assumption must be relaxed to “deployment conditions are almost identical to training conditions for some period of time [until they aren’t].” To keep up, defenders must recollect, retrain, and redeploy machine learning models, typically at a much slower pace than brittle signature and rule-based approaches.
Tackling these and other considerations motivate the need for security data science and engineering at Elastic. So, where have we applied machine learning? Here, we’ll describe where machine learning plays a role in Elastic Endpoint Security protections. In a follow-up, we’ll highlight where it plays a role in detecting and searching from bulk event data in Elastic SIEM.
Endpoint security protections: MalwareScore™
Both custom and common software tools are employed by threat actors across all tactics in the MITRE ATT&CK framework. In particular, custom software, macros, or scripts may be used to gain initial access, access credentials, establish command-and-control communications, or render the adversary’s desired impact, such as data encryption for ransomware. MalwareScore is a prevention in Elastic Endpoint Security that detects these malicious files via a trained machine learning model.
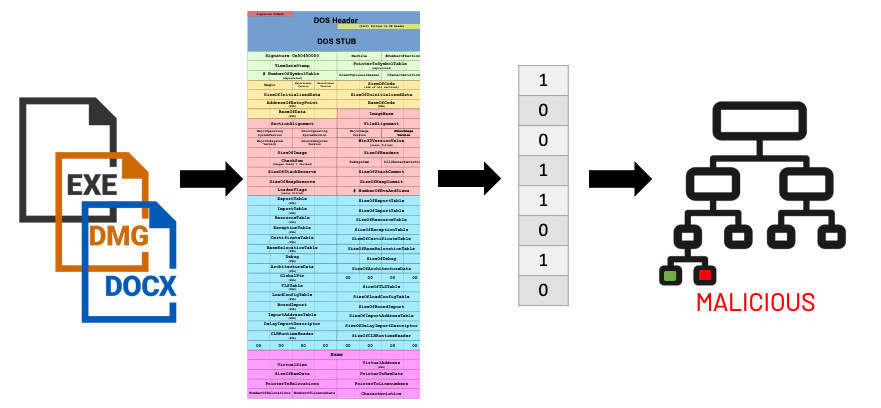
Writing rules or heuristics for every type of known malicious software tool is not sustainable, especially as malware variants evolve. Instead, MalwareScore leverages the scale and automation benefits of machine learning. MalwareScore models are trained to generalize from patterns discovered in large corpora of malicious and benign files: exceeding 150M files for Windows executable files for recent model versions.
MalwareScore consists of three malicious software models: Windows PE files, macro-based Office documents, and macOS binaries (Mach-O). We apply domain expertise from our threat intelligence team to identify features of these files important in determining whether the file is likely good or bad. For instance, Windows PE files are summarized by features that are derived from aspects of the file that include:
- Header and rich signature
- File section characteristics
- Version data
- Debug info included by the compiler
- Imported and exported functions
- The overlay (appended to the file)
- Resources section
- The entry point
- Thread local storage callbacks
- The distribution of byte patterns in the file
Mach-O binaries are summarized from similar information. Macros embedded within Office documents are characterized by both macro content and document properties.
Features like those listed above are readily converted into a format (vector of numbers) that can be ingested and analyzed by machine learning algorithms. MalwareScore leverages gradient boosting decision trees because these model types offer a nice combination of excellent efficacy (high detection rate with a low false positive rate) and computational simplicity (essentially, a series of if/then statements). Indeed, the models are designed to be lightweight (roughly 5MB) with low CPU utilization.
MalwareScore is a supervised machine learning model, meaning that each file is paired with a malicious or benign label. The model is trained to minimize prediction errors of these target labels on the training set, with model regularization employed so that the model generalizes to samples not in the training set, rather than just memorizing. While the features and the model type are important, the richness and distribution of the training data and the quality of the labels are fundamental to providing a good model.
What’s next?
MalwareScore-supervised machine learning models bring an important element of protection to the Elastic Stack. Users who install Elastic Endpoint Security are protected against malware as part of a layered protection strategy that includes behavioral rules. You can try a recent version of MalwareScore in VirusTotal. Upload or search for a PE, macro, or Mach-O file, and view the results yourself!
An even broader security and operational perspective can be attained in Elastic SIEM. In addition to endpoint events collected by Elastic Endpoint Security or other technologies, the SIEM app may include audit events, authentication logs, and firewall logs in holistic detail. In the next blog, we’ll discuss how machine learning in Elastic SIEM can be used to expose unknown threats via anomaly detection in an unsupervised learning paradigm. This allows you to protect against behaviors at the endpoint, and discover unexpected behavior in Elastic SIEM.