Find strings within strings faster with the new wildcard field
In Elasticsearch 7.9, we’ll be introducing a new “wildcard” field type optimised for quickly finding patterns inside string values. This new field type addresses best practices for efficiently indexing and searching within logs and security data by taking a whole new approach to how we index string data. Depending on your existing field usage, wildcards can provide:
- Simpler search expressions (no need to AND words/phrases together)
- Simpler indexing (no need to define choices of analyzers)
- No more missing values
- Faster search
- Less disk usage
The most exciting feature of this new data type is its simplification of partial matches. With wildcards, you no longer need to worry about where your text pattern falls within a string. Just search using normal query syntax, and Elasticsearch will find all matches anywhere in a string. That's right, we did this all without requiring you to change your query syntax.
The wildcard data type addresses issues noted by those in the security field when it comes to partial matching of string values, but has applications in observability and beyond (covered below). In particular, users wanting to search machine-generated logs should find this new field type a more natural fit than existing options.
In this blog, we'll take a look at how we've been able to accomplish this, as well as how you'll be able to best benefit from wildcard fields. Let's take a look.
Existing options for indexing strings
Until 7.9, when it came to searching strings, Elasticsearch has broadly offered two choices:
- Text fields
- Keyword fields
Text fields “tokenize” strings into multiple tokens, each typically representing words. Searchers looking for quick foxes can therefore match articles talking about a quick brown fox.
Keyword fields tend to be used for shorter, structured content like a country code which would be indexed without analysis as a single token. These can then be used by analysts e.g. to visualize popular holiday destinations using aggregations.
Without an explicit mapping choice by users, Elasticsearch’s default index template assumes that string values presented in JSON documents should be indexed as both a text field and a keyword field. The intention is that Elasticsearch should work if the string represents prose that should be chopped into multiple word tokens for search or if it represents a single structured value (like the city name “New York”) that should be displayed as one item when displayed in a “top travel destinations” bar chart.
When text and keyword fields fall short
We don’t have to look very far for an example of string content that doesn’t work well as either text or keyword fields. Elasticsearch’s own log files produce messages that don’t fit neatly into either category. Let’s examine why.
Each Elasticsearch log file entry follows the classic minimal requirement for a logged event - a timestamp and a message. The messages that are logged are used to describe a variety of events in a semi-structured form e.g.:
- Indexes being created or deleted
- Servers joining or leaving the cluster
- Warnings of resources under pressure
- Detailed error messages with long stack traces
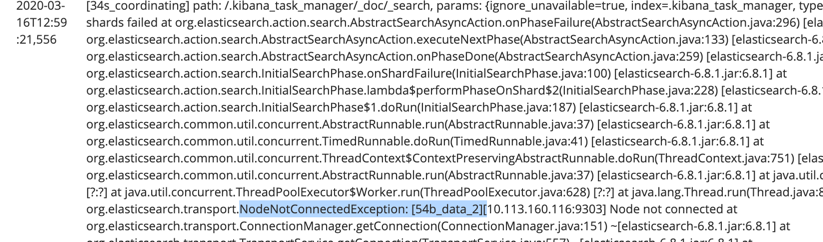
Above is an example of a logged event. Highlighted is a section of the message that I’d like to search for to find similar logged errors. That would be a simple “Cmd/Ctrl-F” key press in a text editor, but is not quite so simple using Elasticsearch. Remember, Elasticsearch operates at scale, so Ctrl-F is great for a small text file, but not for TBs of logs. An index of some kind is required to make searches fast.
Log message as text field
If we indexed the message content as a text field the end user immediately has a translation problem. The selected substring is “NodeNotConnectedException:[54b_data_2]” but the critical question is “how this is represented in the index”?
- Is it half a token?
- One token?
- One and a half tokens?
- Two? Two and a half? ...
The mystery arises because, unlike English text such as “quick brown fox”, we have no clue where words begin or end in log messages like the stack trace shown above. This is not a language humans speak naturally so it is easy to accidentally select only part of a word.
The match query can help users avoid having to know if the : or [ or _ characters in our selection are parts of word tokens or just used to split words. However, the match query will not help with knowing if the beginning or end of our selection happens to crop what would otherwise be a complete token. If the choice of analyzer kept the full stops in the Java package names we would have to use an expensive leading wildcard search for *NodeNotConnectedException or back-up the text selection to add the preceding org.elasticsearch.transport. characters in our “match” query.
Constructing a query that is respectful of tokenisation policies is a significant challenge, even for experienced Elasticsearch developers.
Log message as a keyword field
The keyword field has much less mystery about how the indexed content is stored — it’s one string and we can use a single regexp or wildcard expression to match arbitrary fragments like our search string inside the field values.
Search is made much simpler for users but there are two main issues with the execution:
- Search speed
- Missing data
Search speeds are very slow if, like our search, we are searching for something in the middle of strings and there are many unique values. Although keyword fields are indexed, it’s the wrong data structure for this task. An equivalent task would be a researcher trying to find all words with “oo” in the dictionary. They’d have to scan every word on every page from A to Z to find values “afoot” to “zoo”. That’s essentially what the keyword field has to do with every unique value and the index is of no help in speeding this up. Making things more difficult, log messages often produce many unique string values if, like those produced by Elasticsearch, they contain variables such as timings and memory sizes etc.
The other big issue with the keyword field is it can’t handle very long fields. The default string mapping ignores strings longer than 256 characters, silently dropping values from the list of indexed terms. The majority of Elasticsearch’s log file messages exceed this limit.
And even if you do raise the Elasticsearch limit, you cannot exceed the hard Lucene limit of 32k for a single token, and Elasticsearch certainly logs some messages that exceed this.
This makes a bit of a blind spot for our logging which is undesirable and, in some security cases, unacceptable.
Introducing the new wildcard field
To solve these issues we have a new wildcard field which is adept at finding any patterns in the middle of arbitrary string values.
- Unlike the text field, it does not treat strings as a collection of words separated by punctuation.
- Unlike the keyword field, it can be very fast to infix search many unique values and is free of size restrictions.
How it works
Detailed pattern-matching operations like wildcard or regular expressions can be expensive to run on large data sets. The key to speeding up these operations is to limit the amount of data on which you apply these detailed comparisons. If a quick approximate match can be applied to narrow the bulk of the data then the more expensive operation of detailed matching can be reserved to verifying a few promising candidate matches.
The new wildcard field automatically accelerates wildcard and regexp searches in this way using two data structures:
- An “n-gram” index of all 3 character sequences found in strings
- A “binary doc value” store of the full original document values
The first structure is used to provide a fast but rough narrowing of candidates based on matching n-gram fragments from the search string.
The second data structure is used to verify the match candidates produced by the n-gram match with an automaton query.
Wildcard example
A security analyst might be interested in finding any log messages where a hacker may have referred to the word “shell”. Given the wildcard query “*shell*” the wildcard field would automatically split this search string into 3 character n-grams, creating the equivalent of this Lucene query:
she AND ell
This would reduce the number of documents we need to consider but may produce some false positives — e.g. a document containing the string
/Users/Me/Documents/Fell walking trip with Sheila.docx
Obviously, the longer the search string the fewer false positives produced. A search for “*powershell.exe*”, for example would produce a much more selective n-gram query of
pow AND wer AND rsh AND hel AND l.e AND exe
Removing any false positives is a necessary finishing stage and so the wildcard field does this check on all the matches produced by the rough n-gram query. This is done by retrieving the full original value from a Lucene binary doc value store and running the wildcard or regexp pattern on the full value.
Regexp example
Regular expressions are more complex and can include choices of value paths — e.g. this search for references to DLL or EXE files:
.*\.(dll|exe)
To accelerate this sort of query the expression is parsed into n-grams arranged with this Boolean logic:
(.dl AND ll_) OR (.ex AND xe_)
Note in this example that the _ character is used to show where a non-printable character is added to mark the end of the indexed string.
Regular expressions and case sensitivity
We know security analysts have adapted their Elasticsearch regexp searches to use mixed case expressions e.g when searching for references to cmd.exe regardless of case they will write:
[Cc][Mm][Dd].[Ee][Xx][Ee]
The wildcard field recognises these mixed case expressions and the rough-cut query for the above expression would be optimised to the equivalent of this Lucene query:
cmd AND d.e AND exe
(Note the n-gram index used to accelerate queries is always lowercased).
Existing security rules that use these mixed case expressions on keyword fields should run faster when used on content indexed into a wildcard field.
However, these expressions still look ugly and are a pain to write, so in a future Elasticsearch release we also hope to introduce a case sensitive flag to the regexp query which can be set to “false” to make a query case insensitive. It will essentially make a search for abc search for [Aa][Bb][Cc] without the need for the user to write all those square brackets. The net result will be simpler, faster rules.
Comparison with keyword fields
One key goal of the wildcard field is to be a drop-in replacement for keyword fields where it makes sense. We have worked hard to ensure that it produces the same results for all query types — albeit sometimes wildcard will be faster and sometimes slower. This table should help compare the two fields:
| Feature | Keyword | Wildcard |
| Sorting speeds | Fast | Not quite as fast (see *1) |
| Aggregation speeds | Fast | Not quite as fast (see *1) |
| Prefix query speeds (foo*) | Fast | Not quite as fast (see *2) |
| Leading wildcard query speeds on low-cardinality fields (*foo) | Fast | Slower (see *3) |
| Leading wildcard or regexp query speeds on high-cardinality fields (*foo) | Terrible | Much faster |
| Term query. full value match (foo) | Fast | Not quite as fast (see *2) |
| Fuzzy query | Y (see *4) | Y |
| Regexp query | Y (see *4) | Y |
| Range query | Y (see *4) | Y |
| Supports highlighting | Y | N |
| Searched by "all field" queries | Y | Y |
| Disk costs for mostly unique values | high (see *5) | lower (see *5) |
| Disk costs for mostly identical values | low (see *5) | medium (see *5) |
| Max character size for a field value | 256 for default JSON string mappings, 32,766 Lucene max | unlimited |
| Supports normalizers in mappings | Y | N |
| Indexing speeds | Fast | Slower (see *6) |
- Somewhat slower as doc values retrieved from compressed blocks of 32
- Somewhat slower because approximate matches with n-grams need verification
- Keyword field visits every unique value only once but wildcard field assesses every utterance of values
- If “allow expensive queries” setting enabled
- It depends on common prefixes — keyword fields have common-prefix based compression whereas wildcard fields are whole-value LZ4 compression
- Will vary with content but a test indexing weblogs took 499 seconds Vs keyword’s 365 seconds
What’s next?
To make life easier for search and analytics applications contemplating the growing list of field types, we have simplified the way indexes describe fields in the field capabilities API. Physical fields like wildcard and constant_keyword that are functionally equivalent to the keyword field now describe themselves as belonging to the keyword family. The introduction of family types mean other field type groupings can be made in the future and adopted without downstream client applications needing to know about new physical field types. As long as they behave the same as other members of the same family they can be used without any changes to the client application.
Elastic Common Schema (ECS) defines standardised index mappings for popular data fields.
In 7.9, ECS has not been updated to use wildcard fields but in the future we can expect that several high-cardinality keyword fields will be changed over to use wildcard fields instead. When this happens client applications should typically not need to change anything as a result but should benefit from faster searches.
All sounds great, what does it cost me?
As usual, the answer is “it depends”. Storage costs mostly depend on the level of duplication in your field’s data. For mostly-unique values the storage costs can actually be less than those of using a keyword field. This is because we made an addition to Lucene to compress the binary doc value store used to access the original content.
We tested an example dataset of 2 million weblog records where each line in the file is indexed as a single value held in a single field. An index using a keyword field was 310MB but thanks to compression the equialent index using the new wildcard field was 227MB. Admittedly the timestamp helped ensure each document value was unique but combinations of URL, IP address and user-agent could also lead to many unique strings.
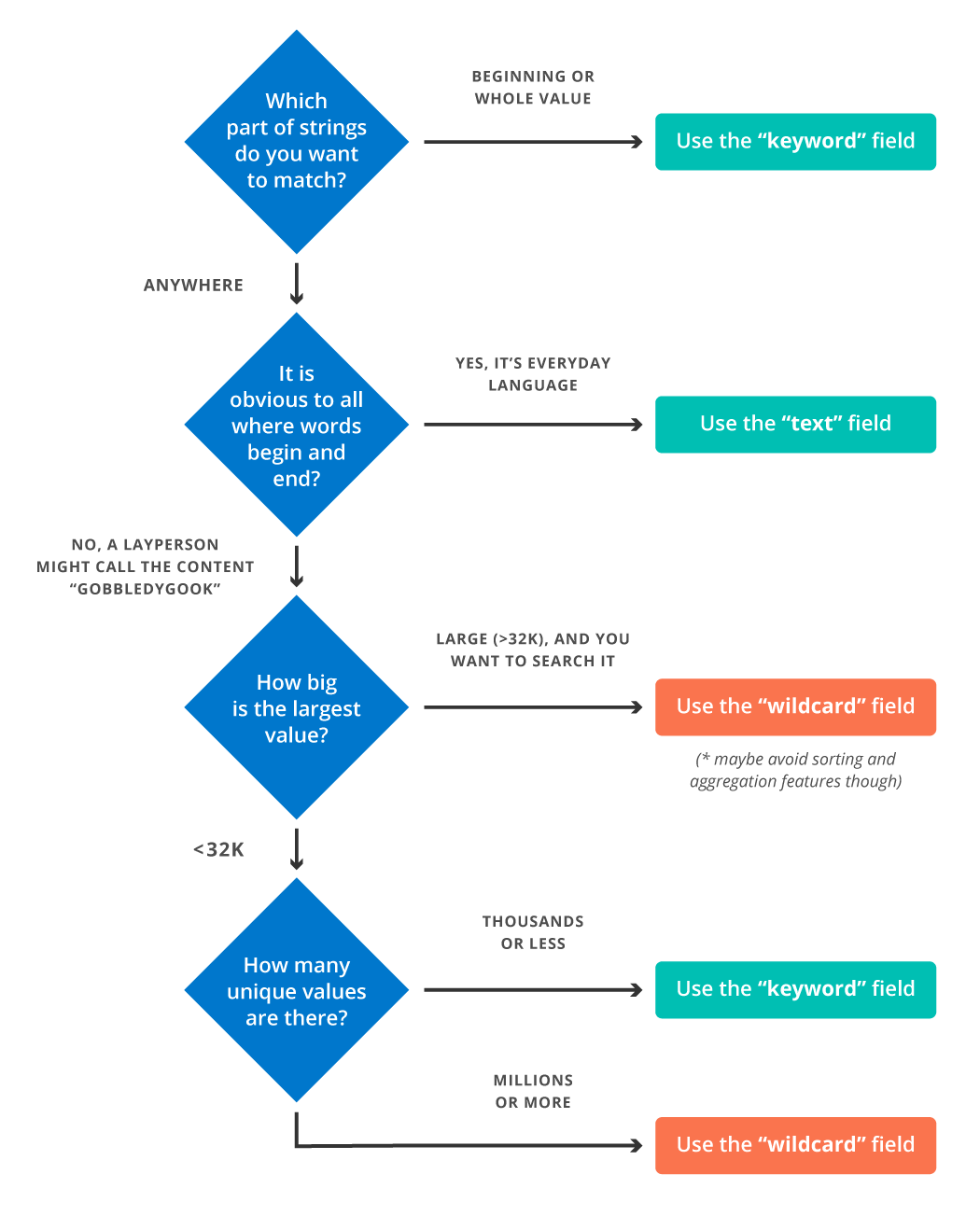
Summary cheat sheet — when should I use a wildcard field?
We recognise all of the above is a lot to think about so a rough guide to when a wildcard field is appropriate is given below.
Take it for a spin
As someone who’s helped develop this feature, I’m excited to see it production-ready. Wildcard fields can provide an immediate boost for almost every Elasticsearch user, not just folks in the security and observability spaces. I know I’ll be using it to search my own Elasticsearch log files.
If all this has piqued your interest, try wildcards out for yourself in a free trial of Elasticsearch Service, and let us know what you think in our forums. We’re always interested in learning about new use cases.
Happy searching!