Elasticsearch and data architecture: 4 essential tools for improved analysis and storage

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Organizations are becoming increasingly more reliant on data to make effective, evidence-based decisions to drive business outcomes. Whether this be assessing market conditions and improving customer experience, ensuring application uptime, or securing an organization, data from multiple sources — including consumers and internal systems — is critical to day-to-day operations.
This data-driven approach requires organizations to collect, store, and analyze mountainous volumes of data at speed for timely decision making. Often this means performing correlation and analysis across multiple sources and formats of varying degrees of complexity at scale.
Elasticsearch® provides the scalability and flexibility to ingest, store, and search these data sets to find relevant and actionable insights from a business, observability, and security lens. However, as more and more data is ingested, it can become unwieldy and expensive if consideration is not given to taking advantage of data architecture and structures made possible by the Elasticsearch platform.
Solving common data challenges with Elastic
As an Elastic Consultant, I have helped many customers with onboarding multiple data sources that are transformed and correlated to provide support for business decision-making, platform availability, and security. These are some of the challenges I help organizations solve, particularly ones with a large variety of data sources:
- Attribution of ingest volumes by data source: This can be tricky without proper labeling/tagging policies and enforcement.
- Analysis and correlation across multiple data sources: This can often be difficult due to conflicting field names in each data set (e.g., host_name, host.name, name).
- Storage costs: Sometimes I see an inability to capitalize on storage tiering due to poorly planned index design and understanding of data sources ingested. Sometimes I also find that customers are unaware of new, cost-saving features.
The development and documentation of a data architecture addresses the challenges above through planning and design of data sources within the organization. A data architecture details the policies and standards for how data is collected, processed, and stored for use by systems and people within the organization. Once defined, the following four tools can be used to address these challenges at a technical layer using the Elastic Stack.
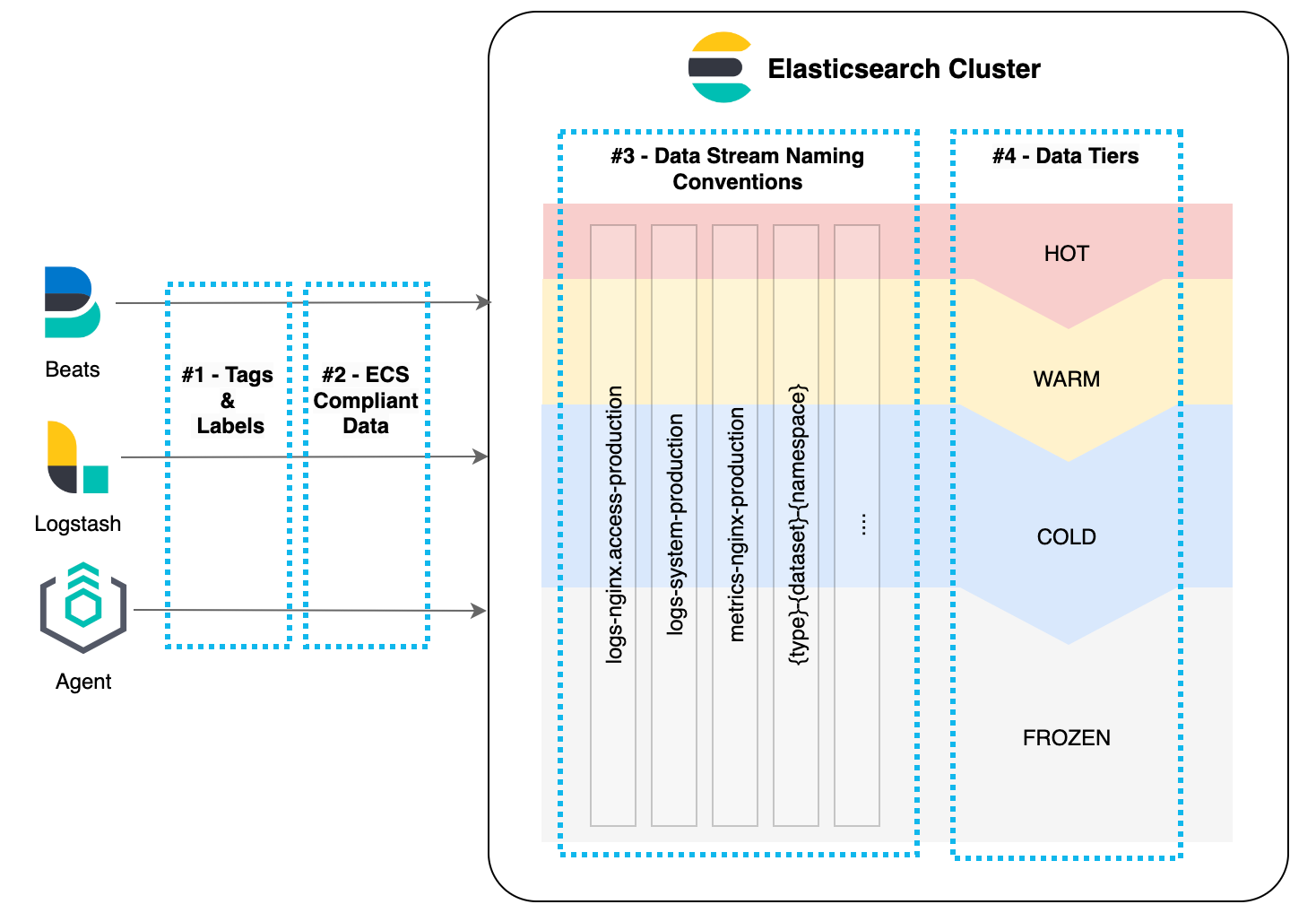
1. Labels and tags
Elastic Stack ingestion tools such as Agent, Beats, and Logstash® all provide the ability to add custom tags and labels, allowing each document to be easily identified once stored in Elasticsearch. A tagging or labeling standard that aligns to an organization’s data architecture provides clarity on how data sources should be handled.
Being able to quickly segregate data sources by filtering on a specific tag allows for data sources to be identified accurately and quickly. This reduces time required for important data management activities, such as capacity planning, analyzing ingest volumes, or migrating data sources between indices.
For some customers where Elastic deployments are shared across multiple teams, the attribution of data for charge back/license consumption can be easily reported by using a standard that aligns to specific consumer groups. In advanced cases, tags and labels can also be used to support document level security for Role Based Access Controls.
The use of tagging and labeling standards can also reduce the time for developing visualizations and performing investigation activities for an application or system that spans multiple data sources.
2. Elastic Common Schema
Correlation across data sets becomes more complex if fields are not consistently named across data sources. This inconsistency can lead to complex queries across multiple fields that all represent the same information (e.g., host.name: “serverA” or host_name: “serverA” or name: “serverA”).
The Elastic Common Schema (ECS) provides a standard blueprint for storing event-based data in Elasticsearch. By default, Elastic’s integrations and ingestion tools (Agent, Beats, and Logstash) adhere to this standard to provide consistent field names and data types across multiple data sources. This makes it easy to query across all of your data, allowing organizations to leverage pre-built out-of-the-box dashboards and our turn-key solutions such as Elastic Observability and Elastic Security.
The ECS complements an organization’s data architecture and can assist as a base layer for capturing a common, standard set of fields for each data source that answers the question of “What data does this source give me?”
In fact, ECS has been accepted by the OpenTelemetry project to benefit users across logging, distributed tracing, metrics, and security events.
3. Data stream conventions
Elastic introduced data streams in version 7.9 as an improved way for managing time series data for Observability and Security use cases. As part of this feature, a naming scheme was introduced to better manage data sets at the index layer by introducing the use of the following:
- type: Generic type describing the data
- dataset: Describes the data ingested and its structure
- namespace: User-configurable arbitrary grouping
These three parts are combined by a “-” and result in data streams like logs-nginx.access-production . This means all data streams are named in the following way:
{type}-{dataset}-{namespace}
The use of the namespace option, in particular, provides organizations with a flexible method to organize and store data in the way they need in alignment with the data architecture.
Read more on data streams.
4. Data tiers
Elasticsearch provides the ability to spread data across different hardware profiles to balance retention and infrastructure costs for data storage. As data ages, cheaper and less performant tiers can be used to reduce storage costs while retaining access to data. This is done using data streams and index lifecycle management policies, tools that automatically move data between the different data tiers.
A data architecture provides a clear overarching picture of the data sources being ingested and how they should be stored within Elasticsearch. This is a key input that can be used for designing a scalable tiered storage structure within Elasticsearch clusters that caters to a variety of data sources and use cases within an organization.
For example, certain Security use cases require logs to be stored for a long period of time, in which case a Cold or Frozen tier should be considered as a cost effective solution that not only retains data, but keeps it readily searchable in the event of an investigation. However for Observability use cases, many of the Agent and APM data sources require a fast Hot tier for immediate investigation to quickly resolve or notify of any performance issues.
Read more on managing data with data tiers.
In summary
The considerations above will help you avoid some of these common pitfalls and realize more value from your Elastic deployment:
- Labels and tags and data stream naming conventions enable organizations to easily secure, aggregate, and filter data by data sources for analysis and management purposes.
- Elastic Common Schema compliance allows organizations to leverage turnkey solutions, making data correlation across multiple sources simple and seamless.
- Scalable data tiers provide a scalable solution to optimizing storage costs for increasing volumes of data, enabling organizations to store the data they need without sacrificing speed.
Get started with a free 14-day trial of Elastic Cloud to see how these tools can be applied.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print