Using Elastic as a global data mesh: Unify data access with security, governance, and policy


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
The term “data mesh” isn’t especially new, but the definition of what it is and does is perhaps not widely agreed upon, so let’s explore it a bit.
Data mesh vs. data fabric
We should probably start with what it’s not. A “data mesh” is not the same as a “data fabric.” A data fabric allows data flowing in from across the enterprise (from the edge, the network, the applications, the appliances . . . literally everywhere) to be confidently received and persisted, making it available for delivery to any consumers who might want to ingest that data. That’s really the important part: While some data fabric tools provide the ability to perform low-level data manipulation and logic-based routing, the data fabric cannot actually do anything with the data received except deliver it.
By contrast, a data mesh makes the data collected from across the entire network available to be retrieved and analyzed at any or all points of the ecosystem — as long as the user has permissions to access it. A data mesh provides a unified yet distributed layer that simplifies and standardizes data operations, such as search and retrieval, aggregations, correlation, analysis, and delivery. A data mesh creates a data product that other services and business operations can use to get faster, more comprehensive answers to base their decisions on.
So, perhaps a more concise way to define the difference is in the usability of the data: a data fabric delivers raw or semi-processed data; the data mesh lets you actually use it.
If there’s any hope for the data mesh to become more than a concept or marketing term, it has to deliver on a defined set of criteria that addresses valid business needs and provides solid value while doing it. To that end, let’s make the “data mesh” buzzword a little more real and practical.
A data mesh overcomes silos
Maybe you’re thinking, my organization isn’t that big — why would I ever need something like a data mesh? Making good business decisions (at every scale) requires fast access to all potentially relevant information, regardless of source, format, or location. To perform even the most basic operation, most organizations today not only have to search internal data repositories, but they also rely heavily on distributed, often cloud-based hyperscaler services to house their data. Unfortunately, that usually means gluing together services to create point-to-point connections between disparate and disjointed data platforms. Often it also involves combining near real-time data platforms with archived data storage systems that were designed for long-term low cost storage — not fast, flexible retrieval.
The problem is compounded by the fact that each different repository presents a completely different method for querying and retrieving (not to mention securing) the data within them. These are the infamous “data silos'' that prevent accurate, fast access to the relevant data needed for business operations to even function.
Core features of a data mesh
With that bleak description of the disjointed current state of data access for most organizations today, let’s define what core requirements a data mesh should have to be successful.
1. Data collection at the edge
First and foremost, a data mesh needs to be able to collect data at or near the edge. Collection from the edge to a centralized location is too slow for real-time analytics, too costly to duplicate the data, and detrimental to network operations. There can also be security concerns while the duplicated data is in transit, as well as data synchronization issues (which version is the authoritative one?) By collecting data at the edge, keeping it near where it was generated, and accessing it via the data mesh, you’re able to avoid clogging the network pipes and only retrieve query hits.
2. Near-real-time data access on all data, from a common platform
The collected data must be accessible in near real time via a single query — it can’t be stored in multiple single-use silos. You need a search analytics platform that’s built for speed, scale, and flexibility. The data mesh must be able to access all types of data together, using a common syntax. The main problem with so-called “federated search” systems is that the query and results translations between disparate repositories are done at query-time, whereas with a data mesh’s distributed mode of operations, all of the data is indexed and readily available to be queried (and ranked) in a common platform.
3. Flexible failover, high availability (HA), and continuous operations (COOP)
The data store needs the ability to automatically recover from hardware or network issues. If you can’t rely on the data being available even in the face of disruptions, the system isn’t strong enough to be called distributed. Data resilience and high availability are the only acceptable uses for copied data — replication rather than duplication. The data mesh needs to be able to co-locate data for speeding up widely distributed operations and allow for continuous operations when failure strikes critical parts of the network.
4. Truly distributed — no duplication, not centralized
We need to be able to query from any one location and get results from all remote sites as well. Duplicating data across the network for the purpose of querying things together is slow, inefficient, and doesn’t scale well. Also, with a distributed data platform, you get the benefits of parallelized compute resources; with monolithic centralized repositories, the larger they get, the slower they respond.
5. Integrated security, integrated data functions
Finally, you need a common platform that lets you run the full suite of analytics across local and remote clusters simultaneously and uniformly, while also taking into account data access controls. To be scalable and secure, data access controls have to be implemented within the data retrieval engine. Relying on each disparate repository (again, the “federated” model) to translate and apply controls equally is too slow and prone to errors. Post-filtering results (i.e., getting back everything matching the query and then deciding one by one which results to deliver) is slow and cumbersome, and it opens the door to data leaks. Data access controls need to be applied within the search engine, so that the user’s credentials (RBAC & ABAC) are included as part of the query and are used as filters to resolve internally which content is permitted before results are returned. This model also applies to security between remote nodes of the data mesh.
Now that we’ve established the bare minimum requirements that are needed to operate a distributed data mesh, what can we do with it once we have one?
A word on replication versus duplication
I’m making a distinction here between the terms “duplication”’ and “replication.” One of the core issues with the current state of most organizations is the unnecessary duplication of data between systems (and the related inefficient workaround of “federated” search) in order to bring disparate data together to support expanded use cases. Duplication is just that: copying data from one system to another, reusing the same data in multiple places. Replication, on the other hand, is for a wholly different purpose: you replicate data for high availability, for failover, for safekeeping (for example, for evidentiary or record-keeping purposes), or to bring the data closer to where it will be accessed (think of that last one like a CDN, a content delivery network that caches local copies of data for faster response times).
Integration at the data layer
Having all organizational data available in a unified layer that provides the speed and scale of internet search solves many problems at once. Where before each application was designed to access only the data from its own repository, now all data is combined and accessible together within a single access point, a unified API, using a normalized query and ranking methodology.
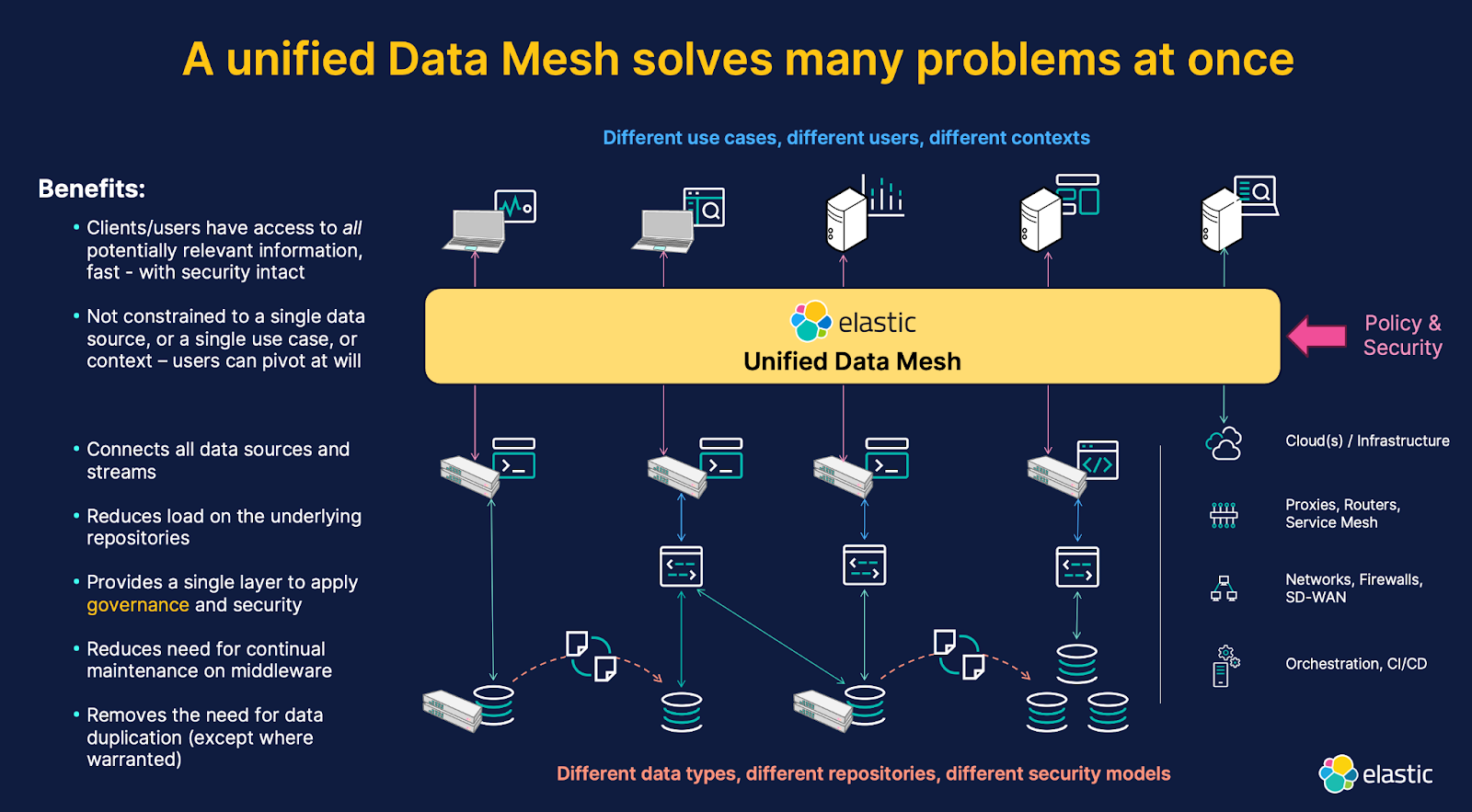
All relevant data is available to all use cases, regardless of original source or format. This means that you’re no longer faced with a choice of where (or in which solution) the data will reside, nor will you be forced to duplicate data needed for multiple use cases. A data mesh still allows for data replication where necessary — such as for data colocation and caching, or for ensuring that records are kept for investigative or evidentiary purposes — but you no longer have to maintain copies of the same data in multiple places for each use case that needs it.
The data can remain in the original repositories as desired, and the data mesh provides a unification layer that not only speeds up and simplifies access to all data together, but also reduces unplanned-for loads on the underlying repositories. Most repositories were designed to support only the query volumes associated with their supported applications; they can’t handle any additional unexpected or ad hoc query loads without additional resources.
Another benefit of using a unified data mesh over a federated search system is that you can leverage all the common powerful query syntax and ranking mechanisms the data mesh provides, on all types and sources of data; you aren't restricted to the “lowest common denominator” capabilities of the data repositories you’re querying.
Unified data security, governance, and policy
A powerful side benefit of a unified data mesh is the ability to also unify global data management operations, such as data security, governance, and policy applications. These are particularly thorny problems when trying to apply security or governance to disjointed systems because each system has different (and not equivalent) security control mechanisms, different access protocols, and different policy controls. Security and governance can be applied at the data mesh layer and can often be simplified to apply more generally to the nature of the data rather than the specific use case the data supports.
Elastic as the global data mesh
Elastic®’s search analytics platform incorporates all the core features of a data mesh and enables a wide array of additional functions on all data ingested into the platform — capabilities such as machine learning, natural language processing (NLP) and semantic search, detections, alerting, visualizations, dashboards, reporting, and many others all in a single platform.
There are essentially two key capabilities that make the Elastic platform a uniquely powerful global data mesh:
Cross cluster search (CCS) is what makes Elastic able to operate as a distributed data platform. CCS enables the ability to connect remote data clusters together and search across them as if they were all in the same distributed cluster, regardless of where they are physically located or what platform they are deployed to. This means you can connect your on-premises clusters to remote clusters across the globe, in public or private cloud/multi-cloud hosted environments, or even to partner clusters outside your organization if desired. The data shared across those remote clusters is still protected by the host cluster’s security.
Elastic’s searchable snapshots capability makes the data mesh cost-effective and extends its reach back potentially years in time. Elastic has the ability to use policy-driven data management to automate handling data at different densities and access patterns. We call this feature index lifecycle management (ILM).
Searchable snapshots are used at two of the ILM tiers — in the Cold tier, where you can reduce your required Elasticsearch® data node by half by using searchable snapshots to store replicas, and secondly in the Frozen tier, where only the index of the data is maintained in memory while the data itself is stored on inexpensive object stores (like Amazon S3, Azure Blob Storage, or even local file shares). This allows huge savings and the ability to keep much more data alive and fully searchable throughout its lifecycle. The tradeoff is response times: where it usually takes hours or days for data to be “rehydrated” (pulled back into a live system from an archive), Frozen tier data is still fully indexed and typically responds in seconds to minutes.
With a data mesh powering your organization, the sky’s the limit with regard to making data available where it’s needed in near real time. A global data mesh is an enabling technology for so many business operations, and in fact, many of the latest data security and analytics designs (for example, Zero Trust) absolutely depend on the capabilities that only a fully unified data layer can provide.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print