Ask me anything: From query to natural language
Editor’s Note: Elastic joined forces with Endgame in October 2019, and has migrated some of the Endgame blog content to elastic.co. See Elastic Security to learn more about our integrated security solutions.
In our last post, we highlighted the design challenges we faced creating a chatbot for the security space. While the design considerations pose a significant challenge, equally daunting is building something that actually “understands” the end user. For instance, the banner graphic above demonstrates the wide gap between query language syntax when searching on endpoints and how a human would actually pose the question in reality.
Unfortunately, the computational transition to natural language is not necessarily a ahem... “natural” one. Building something that understands an English form SQL-like language is much simpler than the messy reality required to build a conversational interface. We’ll describe this process of transitioning from strict query syntax toward building a user-friendly interface flexible enough to answer questions. Guided by the user experience research, building a natural language processing pipeline is the essential second component to ensure our chatbot, Artemis, meets the operational needs of users across a range of expertise.
Chatbot
The concept of a chat interface is straightforward. The user is presented a text input window where they can perform a query. Upon entering some text in the window and hitting
- Text is sent to the bot
- Bot preprocesses/cleans incoming text
- Bot determines what the user wants to do
- Bot extracts important information
- Bot carries out user action
Easy enough, right? Well, not really. In fact, steps 2-4 are some of the toughest problems in a subfield field of Natural Language Processing (NLP), called Natural Language Understanding (NLU). This field has seen increased attention due to the rise of other mainstream intelligent assistants from companies like Amazon, Microsoft, and Google, as well as chatbots on Facebook Messenger and Slack. In short, NLU attempts to derive a user’s intention by performing semantic and syntactic analysis. Before we dive into our NLU pipeline, let’s first explore the core chatbot components required to successfully build a chatbot.
Utterance
Utterance refers to the words the user sends to the chatbot. Utterance is a catch-all term that covers whatever the bot might receive, anything from the word “hey” to a multi-sentence paragraph.
Dialog script
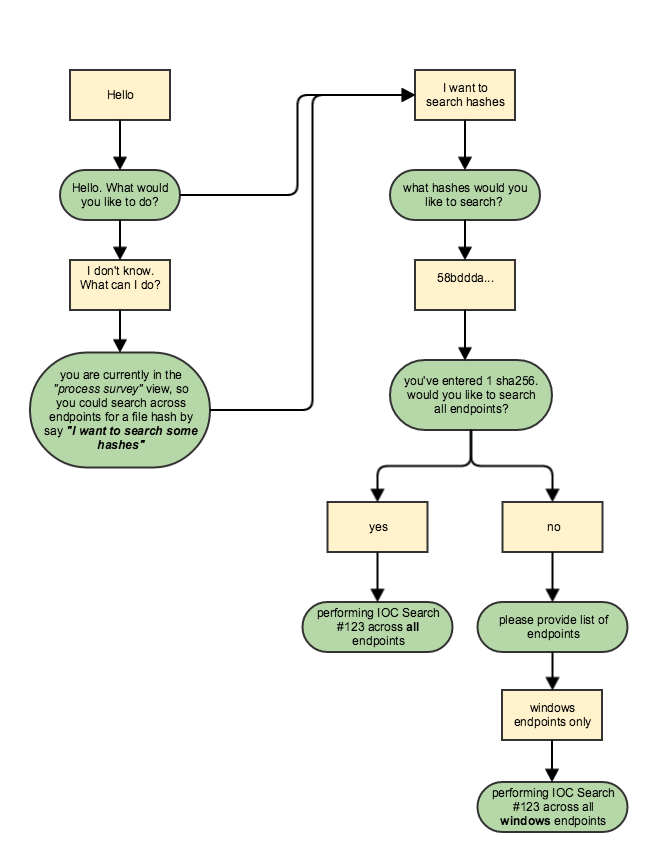
The flowchart in Figure 1 is one example of a dialog script. Dialog scripts provide a template of ideal interaction between bot and user. They are similar to a decision or process tree, and cover the potential range of outcomes and flows within a conversation.
Context
Context represents the current state of a conversation. Each context within an intent has constraints that must be met (e.g. context = search_process_no_query means a user must supply a hash or filename) to proceed. It might include the extracted entities, the intent itself, the history of past user actions, etc. Programmers could consider context the “state” of the dialog.
Action
The action of a chat varies depending on the application. At its most basic form, action is an API call that is only made when the bot receives the necessary parameters to satisfy a constraint. The Action is a database query using the search term(s) discovered from entity extraction. In the case of our tool, Artemis, we are trying to get results to the users in an intuitive way which promotes intelligent hunting and effortless hypothesis checking. The actions driven by Artemis are generally search and discovery, with the final result being an answer in the form of data. Within the Endgame platform, Artemis allows the user to run efficient distributed search functions with parameters they specify through chat.
Intent
The concept of an intent is intimately tied to actions, but it is the human-facing side of a set of actions. For example, searching for processes connecting to an IP and searching for IPs that received the most traffic are both ‘network’ intents, but the actions are different enough that the API calls internally are distinct. The intent could be considered the part that gathers the parameters for the action function, but it also may decide which exact action to call.
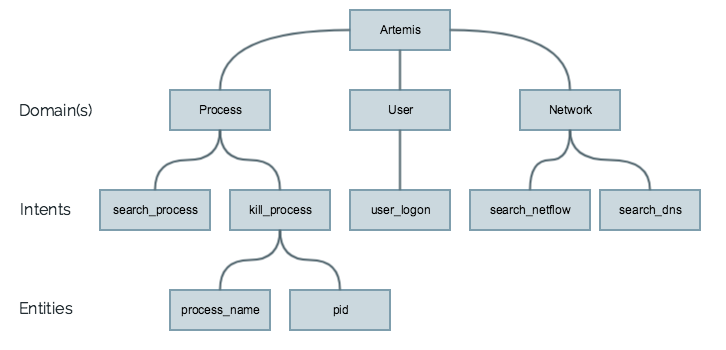
Entities
Entities are the final core component of our chatbot, Artemis. Entities can be thought of as the parameters needed to satisfy constraints stated within Intents that ultimately lead to the execution of Actions. For example, in the sentence: “Search processes for the filenames calc.exe;explorer.exe” we would like to perform Named Entity Recognition on the filenames. Unlike a finite list of known pizza toppings or airport codes, the list of possible process names is nearly infinite (well something more like 1.9820064666e+493 on Windows with a Latin-1) so we can’t possibly hardcode all of them. One option is to write (or copy from stack overflow) a regular expression akin to the 86 ascii characters for string lengths 1 to 255 to match filenames. Unfortunately, this would match all of the words in this paragraph as well, so we need the ‘file|filename|process’ tag specifier as well or use a Named Entity Recognizer model which we detail later.
Natural language understanding
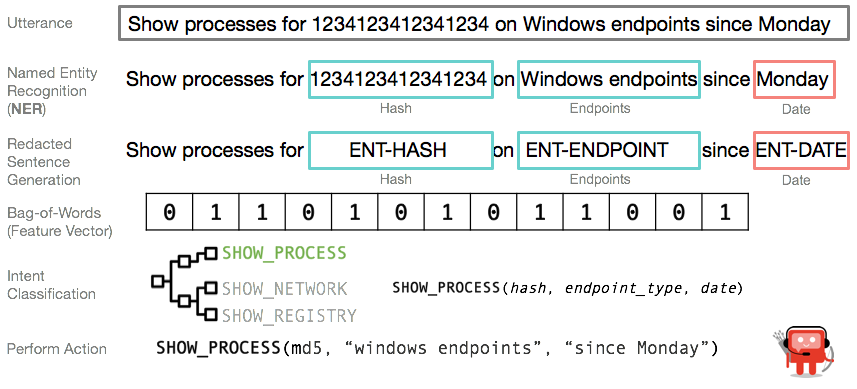
Although we built the architecture to handle a wide range of use cases, in every data scientist’s life, the inevitable handling of missing data must occur. To handle missing information, we had to improve Artemis’ ability to understand user supplied language. After all, we can only discover missing information after we identify what has already been supplied. We integrated a pipeline similar to what is depicted in Figure 3 to perform the following process:
- Take a user’s utterance and break apart the sentences into words (Tokenization)
- Create features from tokenized words (Bag-of-Words -- BoW)
- Perform Named Entity Recognition (NER) to extract the query parameters
- Redact the user utterance with entity labels (reduces the vocabulary Artemis needs to model)
- Extract Bag of Words to use as features against a supervised learning model
- Make a prediction on user input to determine intent (Intent Classification)
- Acquire all necessary data to carry out an action in Artemis (Perform Action).
Within this pipeline, there are several key components that warrant additional clarification, and are described below.
Tokenizing
Tokenizing refers to the breaking apart of sentences into separate words, often on whitespace. This facilitates the tagging and extraction in the subsequent steps.
POS tagging
Parts-of-speech tagging is different from named entity recognition in that instead of a proper name like “Windows Filename” we are looking for more universal parts of speech like “noun” or “verb”, etc. These parts of speech are defined through the grammar of the language, not by the problem domain (in our case: cybersecurity, aka computers). Many linguists often use tags to facilitate building relevant models.

Entity extraction
Entities are the items which are not parts of speech but are interesting to your domain of research. For example, in the domain of information security you might want to extract operating systems, IP addresses or CVEs. They are all generally “nouns” but you can assign more meaning to them by declaring them special entities in your NLP pipeline and either matching them explicitly or training named entity recognizers (NER) to identify what kind of entity they are. For example, if you have a corpus of text where “the vulnerability CVE-2017-0069” shows up if someone else writes “the vulnerability CVE-2017-0107”, an NER model can predict or infer “CVE-2017-0107” refers to a CVE. However, a regex may work better in production.
Intent classification
Intent classification can be thought of as taking a user input and assigning the appropriate category. This process is achieved by training a supervised learning model, which we have explained in previous posts. Unlike other intent classifiers, we leverage the entity extractor prior to classifying the user intent so the intent model can see a “redacted” sentence. This redacted sentence removes unique entities (i.e. filename or domain names) and replaces them with a label (i.e. ENT-FILE or ENT-DOMAIN). By performing this step first we can significantly reduce the size of our vocabulary, a core feature in our model. This reduces the overall size of the model and increases the overall speed of a response!
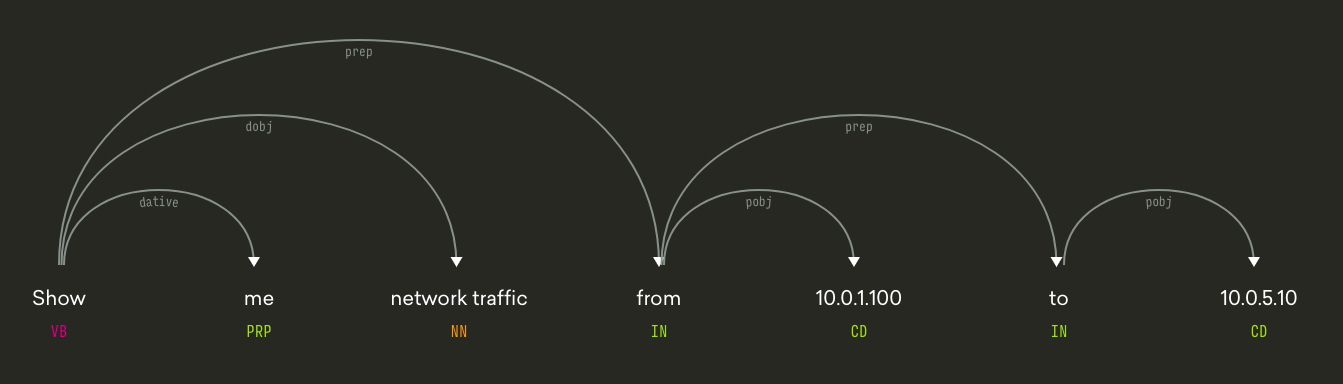
Dependency parsing
Dependency parsing involves analyzing a sentence based on the sequence of the words and which word comes next. When shown in graphical form (Figure 5), you can see how each word depends on another and how those links and the words represent parts of speech. For instance, the phrase: “Show me network traffic from 10.0.100 to 10.0.5.10” should be trivial for the intent classifier to correctly predict. After all the bigram “network traffic” is a strong indicator of the intent search_network. Likewise, entity extraction is simple enough since the structure of IP addresses are unique (i.e. all numbers with 3 periods). But for Artemis to return the correct data we must understand the source and the destination IPs. Otherwise, we could return suboptimal results.
Conclusion
Behind every successful chatbot, there is a logical, scientifically-driven NLU model. Having walked through the core components that together comprise the data science behind Endgame’s chatbot, Artemis, we hope that some of the mystery behind chatbots is replaced with a better understanding of the depth of research on which it was built. However, as we continue to emphasize, neither a well-designed user experience nor a properly specified NLU approach alone are sufficient to meet the needs of security analysts and operators. NLU and user experience together are required to ensure a chatbot moves beyond hype and provides an operationally essential capability for our customers.
Resources
If you want to learn more about building your own bots and the tools required to pull it off we recommend the following resources:
http://www.wildml.com/2016/04/deep-learning-for-ch...
http://www.wildml.com/2016/07/deep-learning-for-ch...
https://stanfy.com/blog/advanced-natural-language-...
https://medium.com/lastmile-conversations/do-it-yo...
https://medium.com/the-mission/how-i-turned-my-res...
https://blog.acolyer.org/2016/06/27/on-chatbots/
https://medium.com/@surmenok/chatbot-architecture-...
https://api.ai/blog/2015/11/09/SlotFilling/
https://x.ai/how-to-teach-a-machine-to-understand-...
https://textblob.readthedocs.io/en/dev/