PRESS RELEASE
Elastic Stack 7.0 Now Available
Elastic N.V. (NYSE: ESTC), the company behind Elasticsearch and the Elastic Stack, announced the general availability of version 7.0 of the Elastic Stack. This release delivers several foundational changes including big improvements to query speed and relevance with the introduction of new query types in Elasticsearch, a fully revamped cluster coordination framework that hardens resiliency, and a completely redesigned Kibana interface that simplifies the user experience and navigation. Elastic Stack 7.0 is immediately available for download, or users can spin up fully managed deployments on the Elasticsearch Service on Elastic Cloud.
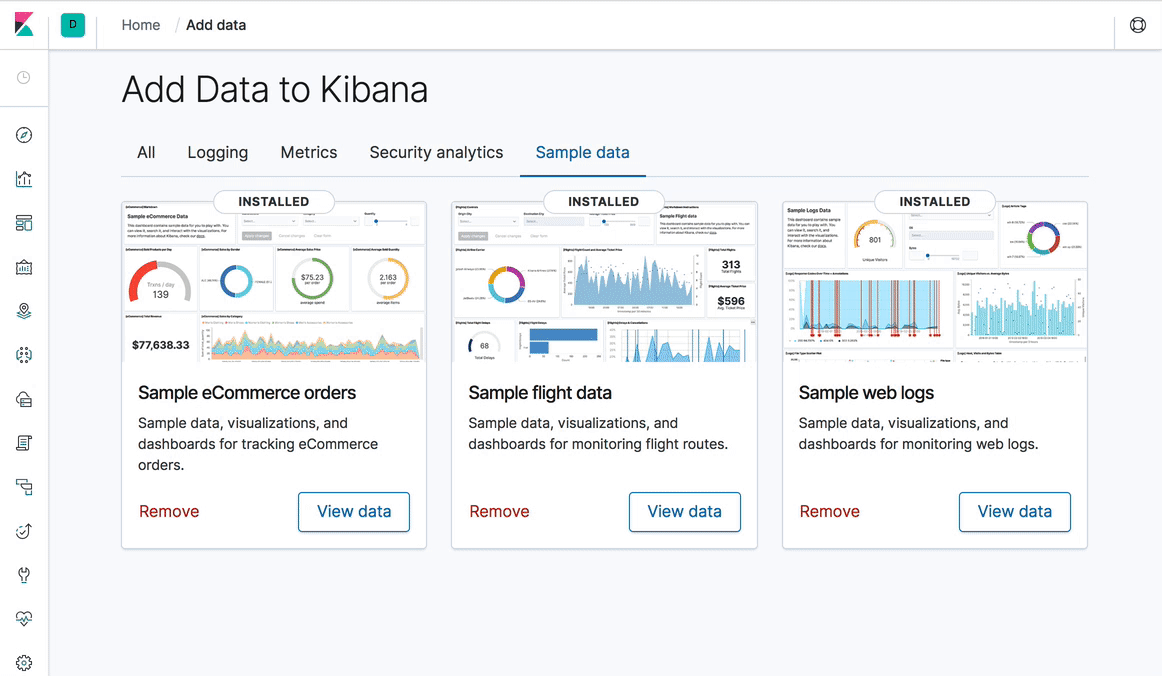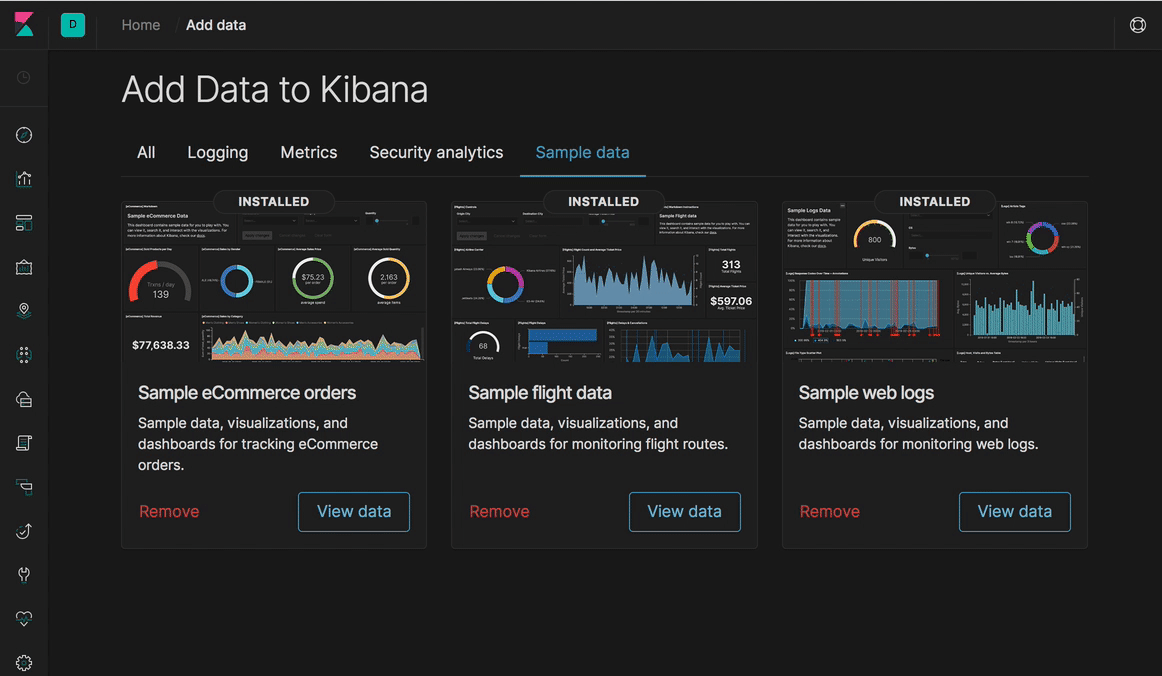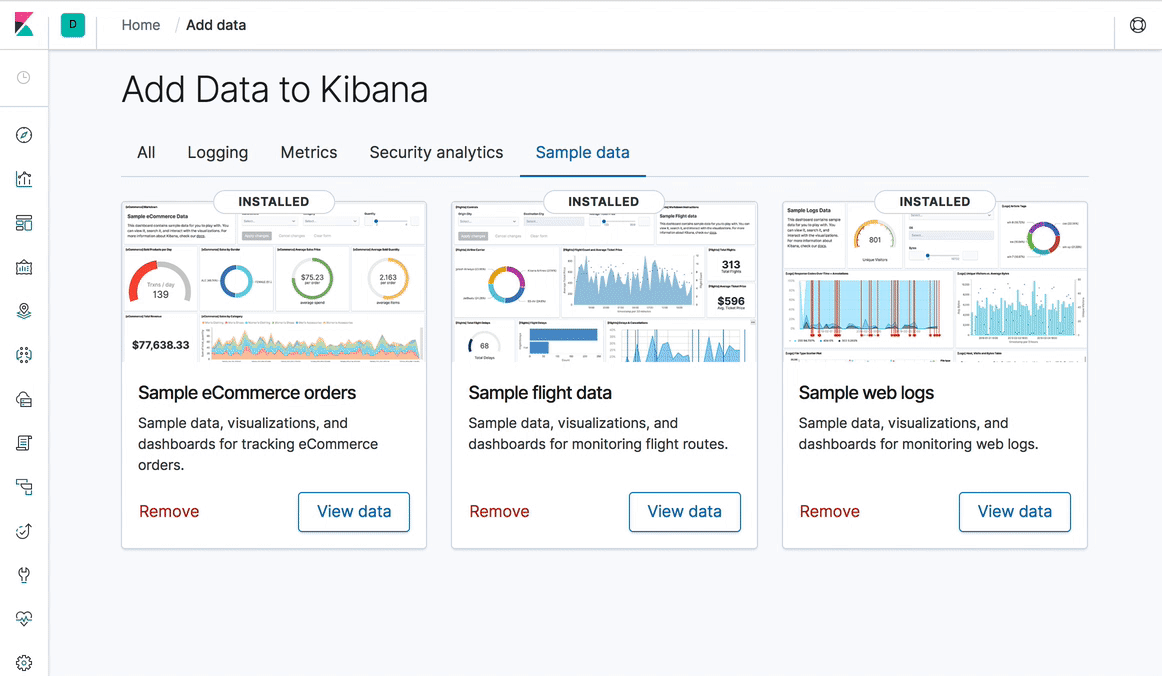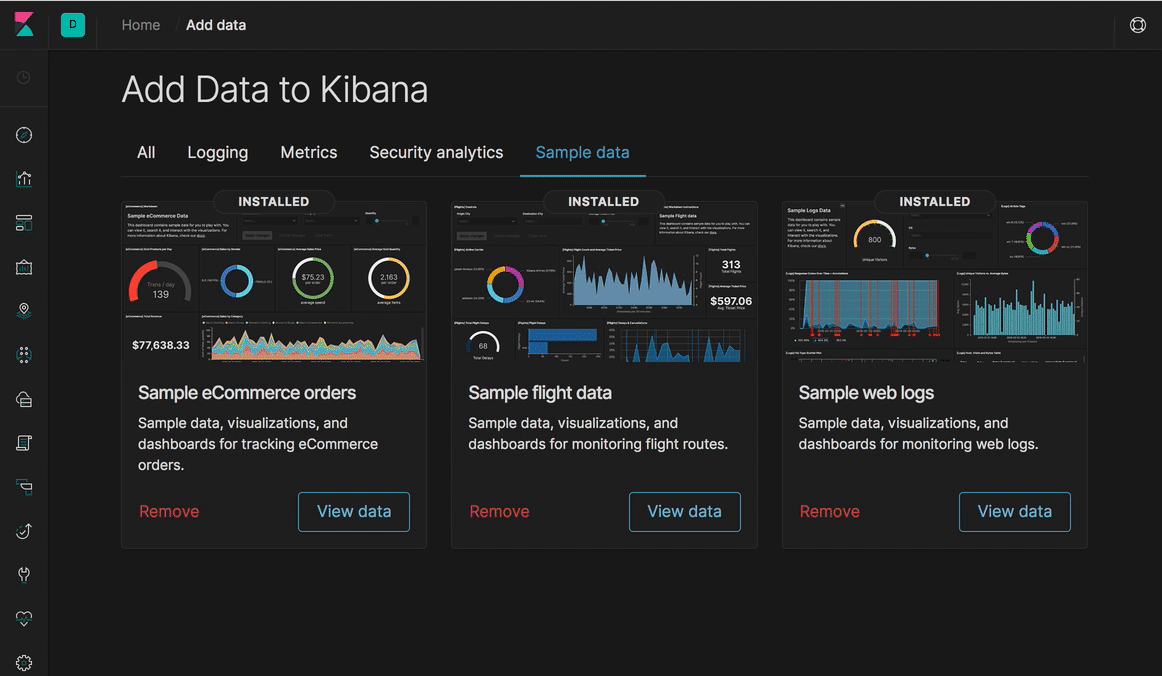
Kibana Welcomes a Fresh Design, New Navigation ... and Dark Mode
Kibana 7.0 delivers on a fresh user interface that embraces a lighter, cleaner, and more minimalist design aesthetic. The goal of the redesign is to put the content and data at the center of the user experience. The new design builds on months of engineering and design effort on the new Elastic UI framework, a set of consistent and reusable UI components that were first introduced in version 6.2. The result is a more uniform and consistent user experience across all touch points in Kibana. As another benefit of these changes, Kibana dashboards now have a responsive design, which is the first step in dramatically improving usability on mobile devices.
Kibana 7.0 also delivers on a much-requested feature: dark mode for all of Kibana. Previously, dark mode was limited to Kibana dashboards. By extending dark mode to all of Kibana, Elastic users that deploy Kibana in low-light environments, such as NOCs and SOCs, can enjoy an enhanced visual experience, with better contrast and improved readability of text.
Elasticsearch 7.0 Gives Relevance and Speed a Boost Across Use Cases
Relevance and speed are the cornerstones of most search experiences. And Elasticsearch 7.0 introduces several foundational features that improve both.
- Faster top k queries: In many search use cases, quickly seeing the top k (say 20) results on a query matters much more to the user than the exact hit count (i.e., total number of results matching the query). For example, if someone is searching for a product on an e-commerce website, they are much more interested in the 10 most relevant results than the other 120,897 results that matched their search query. Elasticsearch 7.0 (and Lucene 8.0) implements a new algorithm (Block-Max WAND) that provides a huge speed boost when retrieving top hits.
- Intervals queries: Some search use cases, such as legal and patent search, introduce the need to find records in which words or phrases are within a certain distance from each other. Intervals queries in Elasticsearch 7.0 introduce a brand new way of structuring such queries and are significantly simpler to use and define compared to the previous methods (span queries). Intervals queries are also much more resilient to edge cases compared to span queries.
- Function score 2.0: Custom scoring is the bread and butter of advanced search use cases, where one wants finer control over relevancy and results ranking. Elasticsearch has provided the ability to do this since its early days. 7.0 introduces the next generation of function score capability, providing a simpler, modular, and more flexible way to generate a ranking score per record. The new modular structure allows users to mix and match a set of arithmetic and distance functions to construct arbitrary function score calculations, giving them more control over how results are scored and ranked.
A New Era for Cluster Coordination Hardens Resiliency
Scale and resiliency have been central themes in Elasticsearch since the very beginning. The cluster coordination layer, called Zen Discovery, has been a key component of that resilient design.
With Elasticsearch 7.0, Elastic has completely rebuilt this cluster coordination layer to be faster, safer, and easier to use. 7.0 also includes a number of changes that reduce the likelihood of human error and provide clearer choices when recovering from catastrophic failures. The ground-up rebuild of the cluster coordination layer was a huge accomplishment — it’s not easy to improve reliability, performance, and user experience all at once, especially in such a central component. Most importantly, the new cluster coordination layer provides strong building blocks for the future of Elasticsearch, ensuring that Elastic can build functionality for even more advanced use cases to come.
Another improvement to resiliency in 7.0 is the introduction of the real memory circuit breaker, which much more accurately detects unserviceable requests made to a node and prevents them from making an individual node unstable. This change significantly improves the overall node and cluster reliability.
Smoother Zoom in Elastic Maps with Geotile Grid
Geo is an integral part of most search experiences, and it has been an area of constant engineering investment for Elastic. Elastic added support for ingesting and querying geo data in very early versions of Elasticsearch, and then recently moved geo_point and geo_shapes to Bkd-backed storage structures, with significant storage and query performance improvements (in some cases by 25x). On the visual exploration end, the introduction of Elastic Maps in version 6.7 provided a dramatically improved way to visually map, explore, and query location data.
With 7.0, the evolution of the geo story in the Elastic Stack continues with the addition of a new geotile_grid aggregation in Elasticsearch to handle (geo) map tiles in a way that allows a user to zoom in and out on the map without altering the shape of the result data. Elastic Maps in 7.0 is already using this new aggregation. Prior to this change, the fringes of the shape could slightly change with the change in the zoom level because the rectangular tiles would change orientation at different zoom levels. This level of accuracy is important, whether the user is protecting a network from attackers, investigating slow application response times in specific locations, or tracking a relative hiking the Pacific Crest Trail.
Strengthening Time Series Use Cases with Nanosecond-Precision Support
Whether it’s infrastructure metrics, system audit logs, network traffic, or a rover on Mars, time series data is central to how many people use the Elastic Stack. The ability to precisely order and correlate events across multiple systems and services is key.
Until now, Elasticsearch only stored timestamps with millisecond precision. 7.0 adds a few zeroes, bringing this to nanosecond precision, which gives users with high-frequency data collection needs the precision required to accurately store and sequence this data. The change was made possible by migrating from the historical JODA library to the official Java time API in JDK 8.
Learn More
- Read the Elastic Stack 7.0. blog
- Start a free trial with Elasticsearch Service
- 7.0 live launch event with creators
- Read about Elastic’s customers
About Elastic
Elastic is a search company. As the creators of the Elastic Stack (Elasticsearch, Kibana, Beats, and Logstash), Elastic builds self-managed and SaaS offerings that make data usable in real time and at scale for search, logging, security, and analytics use cases.
Elastic and associated marks are trademarks or registered trademarks of Elastic N.V. and its subsidiaries. All other company and product names may be trademarks of their respective owners.