Recursos do Elasticsearch
O Elasticsearch é um mecanismo de análise e busca RESTful distribuído que armazena seus dados de forma centralizada para que você possa buscar, indexar e analisar dados de todas as formas e tamanhos.
Ingestão e enriquecimento
Armazenamento de dados
Flexibilidade
Security
Busca e análise
Busca de texto completo
Gerenciamento e operações
Gerenciamento e operações
Escalabilidade e resiliência
O Elasticsearch opera em um ambiente distribuído projetado do zero para garantir tranquilidade constante. Nossos clusters crescem de acordo com as suas necessidades — basta adicionar outro nó.
Clustering e alta disponibilidade
Um cluster é uma coleção de um ou mais nós (servidores) que juntos armazenam todos os seus dados e fornecem indexação federada e recursos de busca em todos os nós. Os clusters do Elasticsearch apresentam shards principais e de réplica para fornecer failover no caso de um nó ficar inativo. Quando um shard principal fica inativo, a réplica assume seu lugar.
Saiba mais sobre clustering e alta disponibilidadeRecuperação automática de nós
Quando um nó sai do cluster por qualquer motivo, intencional ou não, o nó master reage substituindo o nó por uma réplica e rebalanceando os shards. Essas ações destinam-se a proteger o cluster contra perda de dados, garantindo que cada shard seja totalmente replicado o mais rápido possível.
Saiba mais sobre a alocação de nósRebalanceamento automático de dados
O nó master no seu cluster do Elasticsearch decidirá automaticamente quais shards alocar para quais nós e quando mover shards entre nós para rebalancear o cluster.
Saiba mais sobre o rebalanceamento automático de dadosEscalabilidade horizontal
À medida que seu uso cresce, o Elasticsearch é redimensionado para acompanhar suas necessidades. Adicione mais dados, adicione mais casos de uso e, quando começar a ficar sem recursos, basta adicionar outro nó ao cluster para aumentar sua capacidade e confiabilidade. E quando você adiciona mais nós a um cluster, ele aloca automaticamente shards de réplica para que você esteja preparado(a) para o futuro.
Saiba como aplicar a escalabilidade horizontalReconhecimento de rack
Você pode usar atributos de nó customizados como atributos de reconhecimento para que o Elasticsearch consiga levar em consideração sua configuração de hardware físico ao alocar shards. Se o Elasticsearch souber quais nós estão no mesmo servidor físico, no mesmo rack ou na mesma zona, ele poderá distribuir o shard principal e seus shards de réplica para minimizar o risco de perder todas as cópias de shard em caso de falha.
Saiba mais sobre o reconhecimento de alocaçãoReplicação entre clusters
O recurso de replicação entre clusters (CCR) permite a replicação de índices em clusters remotos para um cluster local. Essa funcionalidade pode ser usada em casos de uso de produção comuns.
Saiba mais sobre o CCRRecuperação de desastres: se um cluster principal falhar, um cluster secundário poderá servir como backup dinâmico.
Geoproximidade: as leituras podem ser servidas localmente, diminuindo a latência da rede.
Replicação entre datacenters
A replicação entre datacenters é um requisito para aplicações de missão crítica no Elasticsearch há algum tempo, e antes era resolvida parcialmente com tecnologias adicionais. Com a replicação entre clusters no Elasticsearch, nenhuma tecnologia adicional é necessária para replicar dados em datacenters, regiões geográficas ou clusters do Elasticsearch.
Leia sobre a replicação entre datacentersGerenciamento e operações
Gestão
O Elasticsearch vem com uma variedade de APIs e ferramentas de gerenciamento para proporcionar total controle sobre dados, usuários, operações de cluster e muito mais.
Faça a recuperação de um snapshot
Os clusters do Elasticsearch que usam armazenamento de objetos na nuvem agora podem transferir determinados dados, como replicação e recuperação de shards de nós do ES e armazenamento de objetos, em vez de transferir dados entre nós do ES, reduzindo assim os custos de transferência e armazenamento de dados.
Saiba mais sobre a recuperação de um snapshotGestão de ciclo de vida de índices
A gestão de ciclo de vida de índices (ILM) permite que o usuário defina e automatize políticas para controlar quanto tempo um índice deve durar em cada uma das quatro fases, bem como o conjunto de ações a serem tomadas no índice durante cada fase. Isso proporciona um melhor controle do custo da operação, pois os dados podem ser colocados em diferentes camadas de recursos.
Saiba mais sobre o ILMHot: atualizado e consultado ativamente
Warm: não mais atualizado, mas ainda consultado
Cold/Frozen: não mais atualizado e raramente consultado (a busca é possível, mas mais lenta)
Excluir: não é mais necessário
Camadas de dados
As camadas de dados são a maneira formalizada de particionar dados em nós Hot, Warm e Cold por meio de um atributo de função de nó que define automaticamente a política de gestão de ciclo de vida de índices para seus nós. Ao atribuir funções de nó Hot, Warm e Cold, você pode simplificar e automatizar muito o processo de movimentação de dados de um armazenamento de custo e desempenho mais alto para um de custo e desempenho mais baixo, tudo sem comprometer os insights.
Saiba mais sobre as camadas de dados- Hot: atualizado e consultado ativamente na instância de maior desempenho
Warm: dados consultados com menos frequência em instâncias de desempenho inferior
Cold: somente leitura, raramente consultado, redução significativa do armazenamento sem degradação do desempenho, com tecnologia de snapshots buscáveis
Gestão de ciclo de vida de snapshot
Como um gerenciador de snapshots em segundo plano, as APIs de gestão de ciclo de vida de snapshot (SLM) possibilitam aos administradores definir a cadência para a geração de snapshots de um cluster do Elasticsearch. Com uma UI dedicada, a SLM permite que os usuários configurem a retenção para políticas de SLM e criem, programem e excluam snapshots automaticamente, garantindo que backups apropriados de um determinado cluster sejam feitos com frequência suficiente para poder restaurar em conformidade com os SLAs do cliente.
Saiba mais sobre a SLMSnapshot e restauração
Um snapshot é um backup gerado de um cluster do Elasticsearch em execução. Você pode gerar um snapshot de índices individuais ou de todo o cluster e armazená-lo em um repositório em um sistema de arquivos compartilhado. Existem plugins disponíveis que também oferecem suporte para repositórios remotos.
Saiba mais sobre snapshot e restauraçãoSnapshots buscáveis
Os snapshots buscáveis oferecem a capacidade de consultar diretamente seus snapshots em uma fração do tempo que levaria para concluir uma restauração típica de um snapshot. Isso é conseguido lendo apenas as partes necessárias de cada índice de snapshot para concluir a solicitação. Juntamente com a camada cold, os snapshots buscáveis podem reduzir significativamente seus custos de armazenamento de dados ao fazer backup dos seus shards de réplica em sistemas de armazenamento baseado em objetos, como Amazon S3, Azure Storage ou Google Cloud Storage, com acesso completo de busca neles.
Saiba mais sobre os snapshots buscáveisRollups de dados
Manter os dados históricos disponíveis para análise é extremamente útil, mas muitas vezes evitado devido ao custo financeiro de arquivar grandes quantidades de dados. Os períodos de retenção são, portanto, influenciados pelas realidades financeiras e não pela utilidade dos dados históricos. O recurso de rollup fornece um meio de resumir e armazenar dados históricos para que ainda possam ser usados para análise, mas por uma fração do custo de armazenamento de dados brutos.
Saiba mais sobre os rollups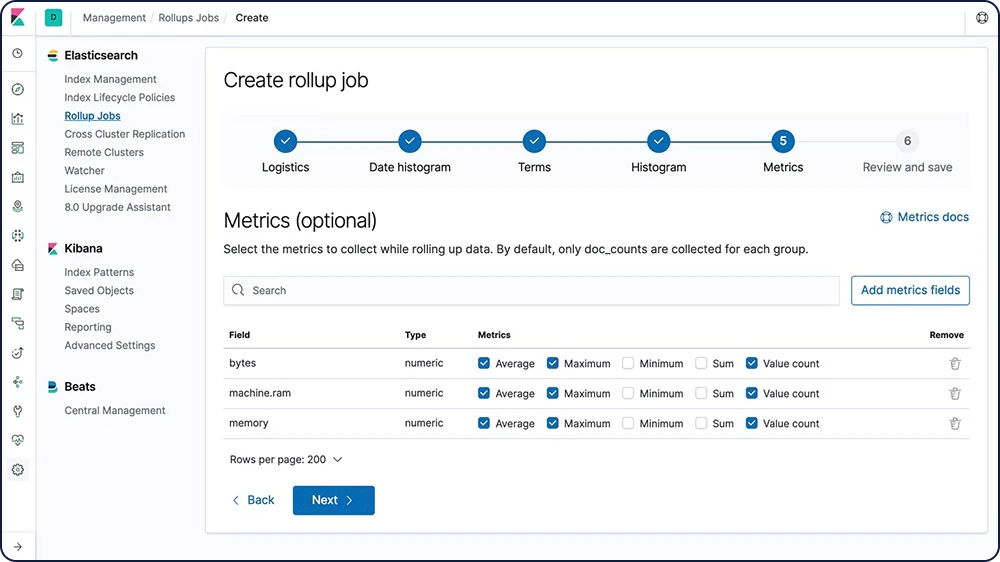
Fluxos de dados
Os fluxos de dados são uma maneira conveniente e escalável de ingerir, buscar e gerenciar dados de série temporal gerados continuamente.
Saiba mais sobre os fluxos de dadosTransformações
As transformações são estruturas de dados tabulares bidimensionais que tornam os dados indexados mais digeríveis. As transformações executam agregações que dinamizam seus dados em um novo índice centrado na entidade. Ao transformar e resumir seus dados, você pode visualizá-los e analisá-los de maneiras alternativas, inclusive como fonte para outra analítica de machine learning.
Saiba mais sobre as transformaçõesAPI do Upgrade Assistant
A API do Upgrade Assistant permite verificar o status de atualização do cluster do Elasticsearch e reindexar os índices que foram criados na versão principal anterior. O assistente ajuda você a se preparar para a próxima versão principal do Elasticsearch.
Saiba mais sobre a API do Upgrade AssistantGerenciamento de chaves de API
O gerenciamento de chaves de API precisa ser flexível o suficiente para permitir que os usuários gerenciem suas próprias chaves, limitando o acesso às suas respectivas funções. Por meio de uma UI dedicada, os usuários podem criar chaves de API e usá-las para fornecer credenciais de longo prazo enquanto interagem com o Elasticsearch, o que é comum com scripts automatizados ou integração de fluxo de trabalho com outro software.
Saiba mais sobre o gerenciamento de chaves de APIGerenciamento e operações
Security
Os recursos de segurança do Elastic Stack oferecem o acesso certo às pessoas certas. As equipes de TI, de operações e de aplicações contam com esses recursos para gerenciar os usuários bem-intencionados e afastar os mal-intencionados, enquanto executivos e clientes podem ficar tranquilos, sabendo que os dados armazenados no Elastic Stack estão seguros e protegidos.
Configurações seguras do Elasticsearch
Algumas configurações são confidenciais, e depender de permissões de sistema de arquivos para proteger seus valores não é suficiente. Para esse caso de uso, o Elasticsearch fornece um keystore para evitar o acesso indesejado a configurações confidenciais do cluster. Opcionalmente, o keystore pode ser protegido por senha para dar mais segurança.
Saiba mais sobre as configurações segurasComunicações criptografadas
Ataques via rede aos dados de nós do Elasticsearch podem ser frustrados por meio de criptografia de tráfego usando SSL/TLS, certificados de autenticação de nó e outros recursos.
Saiba mais sobre a criptografia de comunicaçõesSuporte para criptografia em repouso
Embora o Elastic Stack não implemente a criptografia em repouso, é recomendável que a criptografia no nível do disco seja configurada em todas as máquinas host. Além disso, os destinos dos snapshots também devem garantir que os dados sejam criptografados em repouso.
Controle de acesso por função (RBAC)
O controle de acesso por função (RBAC) permite que você autorize usuários atribuindo privilégios a funções e atribuindo funções a usuários ou grupos.
Saiba mais sobre o RBAC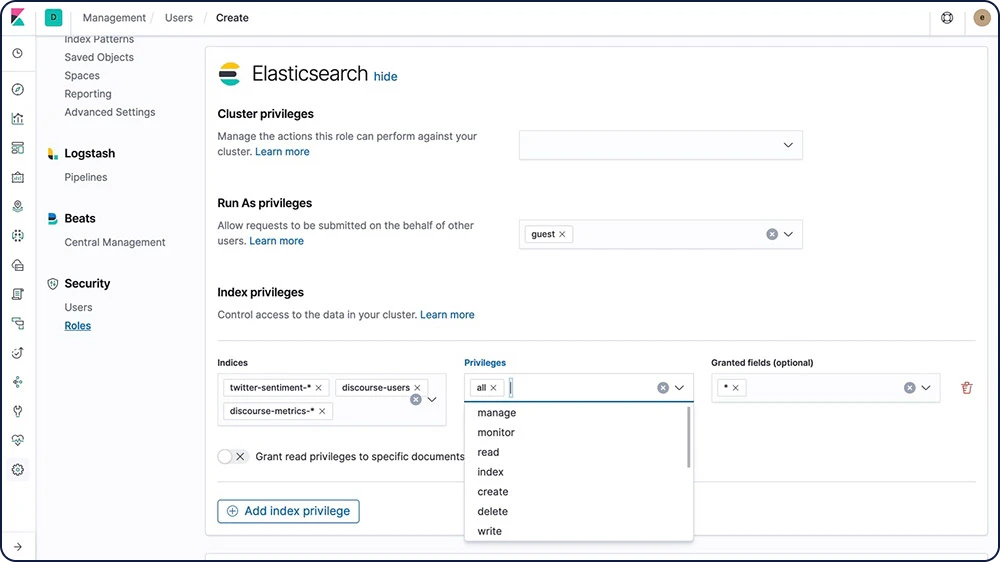
Controle de acesso baseado em atributos (ABAC)
Os recursos de segurança do Elastic Stack também fornecem um mecanismo de controle de acesso baseado em atributos (ABAC), com o qual é possível usar atributos para restringir o acesso a documentos em consultas de busca e agregações. Assim, você pode implementar uma política de acesso em uma definição de função para que os usuários possam ler um documento específico somente se tiverem todos os atributos necessários.
Saiba mais sobre o ABACSegurança em nível do campo e do documento
A segurança em nível do campo restringe os campos aos quais os usuários têm acesso de leitura. Em particular, restringe quais campos podem ser acessados por APIs de leitura baseadas em documentos.
Saiba mais sobre a segurança em nível do campoA segurança em nível do documento restringe os documentos aos quais os usuários têm acesso de leitura. Em particular, restringe quais documentos podem ser acessados por APIs de leitura baseadas em documentos.
Saiba mais sobre a segurança em nível do documentoLogging de auditoria
Você pode habilitar a auditoria para acompanhar eventos relacionados à segurança, como falhas de autenticação e conexões recusadas. O log desses eventos permite que você monitore seu cluster quanto a atividades suspeitas e fornece evidências no caso de um ataque.
Saiba mais sobre o logging de auditoriaFiltragem de IP
Você pode aplicar a filtragem de IP a clientes de aplicações, clientes de nós ou clientes de transporte, além de outros nós que estejam tentando ingressar no cluster. Se o endereço IP de um nó está na lista proibida, os recursos de segurança permitem a conexão com o Elasticsearch, mas ele é descartado imediatamente e nenhuma solicitação é processada.
Endereço IP ou intervalo
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Lista de permissões
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Hostname
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Saiba mais sobre a filtragem de IP
Reinos de segurança
Os recursos de segurança do Elastic Stack autenticam usuários usando reinos e um ou mais serviços de autenticação baseados em token. Um reino é usado para resolver e autenticar usuários com base em tokens de autenticação. Os recursos de segurança fornecem vários reinos integrados.
Saiba mais sobre os reinos de segurançaLogin único (SSO)
O Elastic Stack oferece suporte para o login único (SSO) com SAML no Kibana, usando o Elasticsearch como um serviço de backend. A autenticação SAML permite que os usuários façam login no Kibana com um provedor de identidade externo, como Okta ou Auth0.
Saiba mais sobre o SSOIntegração de segurança de terceiros
Se estiver usando um sistema de autenticação não compatível com os recursos de segurança do Elastic Stack, você pode criar um reino customizado para autenticar usuários.
Saiba mais sobre segurança de terceirosGerenciamento e operações
Alerta
Os recursos de alertas do Elastic Stack lhe proporcionam todo o poder da linguagem de consulta do Elasticsearch para identificar alterações nos dados que interessam a você. Em outras palavras, se você pode consultar algo no Elasticsearch, pode alertar sobre isso também.
Alertas de alta disponibilidade e escaláveis
Há uma razão pela qual organizações de grande e pequeno porte confiam no Elastic Stack para lidar com as necessidades de alerta. Com a ingestão de dados de maneira confiável e segura de qualquer fonte, em qualquer formato, os analistas podem buscar, analisar e visualizar dados importantes em tempo real, tudo com alertas personalizados e confiáveis.
Saiba mais sobre os alertasNotificações por e-mail, webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters
Vincule alertas com integrações para e-mail, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters e Slack. Integre com qualquer outro sistema de terceiros por meio de uma saída de webhook.
Saiba mais sobre as opções de notificação de alerta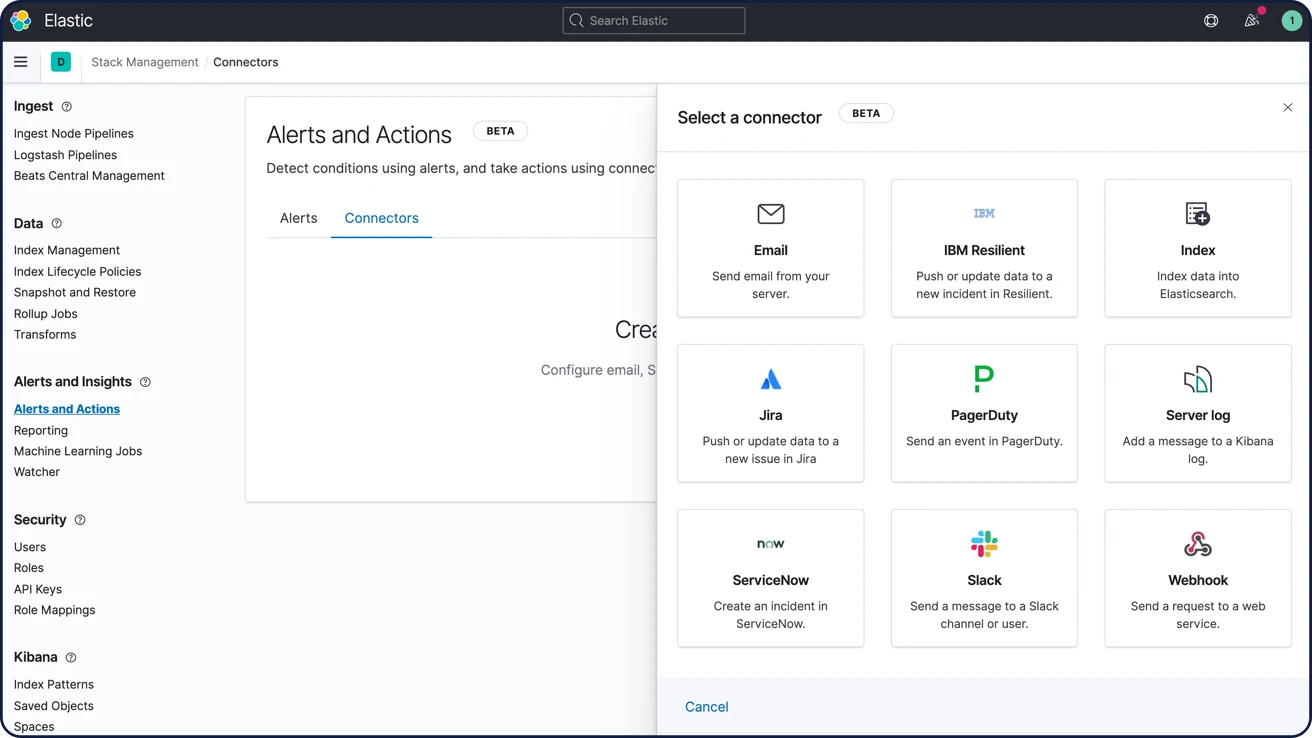
Gerenciamento e operações
Clientes
O Elasticsearch permite que você trabalhe com os dados da maneira que lhe for mais confortável. Com suas RESTful APIs, clientes de linguagem, DSL robusta e muito mais (até SQL), somos flexíveis para que você não se sinta limitado.
Clientes de linguagem
O Elasticsearch usa APIs RESTful e JSON padrão. Também desenvolvemos e mantemos clientes em muitas linguagens, como Java, Python, .NET, SQL e PHP. Além disso, nossa comunidade contribui com muitas outras. Elas são fáceis de trabalhar, a sensação é de naturalidade ao usar e, assim como o Elasticsearch, não limitam o que você quer fazer com elas.
Explore os clientes de linguagem disponíveisDSL do Elasticsearch
O Elasticsearch fornece uma DSL (linguagem específica do domínio) de consulta completa baseada em JSON para definir consultas. A DSL de consulta fornece opções poderosas para busca de texto completo, incluindo correspondência de termos e frases, imprecisão, curingas, regex, consultas aninhadas, consultas geo e muito mais.
Saiba mais sobre a DSL do ElasticsearchGET /pt/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
O Elasticsearch SQL é um recurso que possibilita a execução de consultas semelhantes ao SQL em tempo real no Elasticsearch. Seja usando a interface REST, a linha de comando ou o JDBC, qualquer cliente pode usar o SQL para buscar e agregar dados nativamente dentro do Elasticsearch.
Saiba mais sobre o Elasticsearch SQL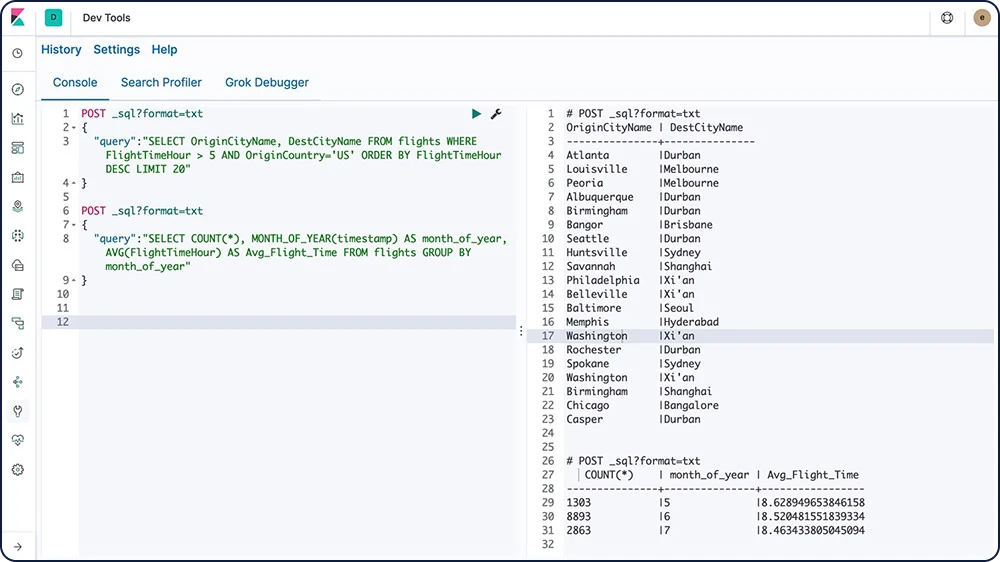
EQL (Event Query Language)
Com a capacidade de consultar sequências de eventos que correspondem a condições específicas, o EQL (Event Query Language) foi criado especialmente para casos de uso como a analítica de segurança.
Saiba mais sobre o EQLCliente JDBC
O driver JDBC do Elasticsearch SQL é um driver JDBC rico e completo para o Elasticsearch. É um driver Tipo 4, o que significa que é um driver Java puro, independente de plataforma, autônomo e direto ao banco de dados, que converte chamadas JDBC em Elasticsearch SQL.
Saiba mais sobre o cliente JDBCCliente ODBC
O driver Elasticsearch SQL ODBC é um driver ODBC 3.80 rico em recursos para o Elasticsearch. É um driver de nível básico, expondo toda a funcionalidade acessível por meio da API ODBC do Elasticsearch SQL e convertendo chamadas ODBC em Elasticsearch SQL.
Saiba mais sobre o cliente ODBCTableau Connector para Elasticsearch
Com o Tableau Connector para Elasticsearch, os usuários do Tableau Desktop e do Tableau Server podem acessar dados no Elasticsearch facilmente.
Baixar o Tableau ConnectorFerramentas de CLI
O Elasticsearch fornece várias ferramentas para configurar a segurança e realizar outras tarefas na linha de comando.
Explore as diferentes ferramentas de CLIGerenciamento e operações
REST APIs
O Elasticsearch fornece uma REST API abrangente e poderosa que você pode usar para interagir com o seu cluster.
APIs de documentos
Execute operações CRUD (criar, ler, atualizar, excluir, pelas iniciais em inglês) em um ou vários documentos usando APIs de documentos.
Explore as APIs de documentos disponíveisAPIs de busca
As APIs de busca do Elasticsearch permitem que você implemente mais do que apenas busca de texto completo. Elas também ajudam você a implementar sugeridores (termo, frase, conclusão e outros), realizar avaliação de classificação e até fornecer feedback sobre por que um documento foi ou não retornado com a busca.
Explore as APIs de busca disponíveisAPIs de agregações
O framework de agregações ajuda a fornecer dados agregados com base em uma consulta de busca. Ele é baseado em blocos de construção simples chamados agregações que podem ser compostos para construir resumos complexos dos dados. Uma agregação pode ser vista como uma unidade de trabalho que constrói informações analíticas sobre um conjunto de documentos.
Explore as APIs de agregações disponíveisAgregação de métricas
Agregações de bucket
Agregações de pipeline
Agregações de matriz
Agregações de cardinalidade cumulativa
Agregações geohexgrid
APIs de ingestão
Use as APIs de ingestão para realizar operações CRUD nos seus pipelines de dados ou use a simulate pipeline API para executar um pipeline específico no conjunto de documentos.
Explore as APIs de ingestão disponíveisAPIs de gerenciamento
Gerencie o seu cluster do Elasticsearch de forma programática com uma variedade de APIs relacionadas ao gerenciamento. Existem APIs para o gerenciamento de índices e mapeamentos, clusters e nós, licenciamento e segurança, e muito mais. E se você precisar de seus resultados em formato legível por humanos, basta usar as Cat APIs.
Gerenciamento e operações
Integrações
Como o Elasticsearch é uma aplicação open source e independente de linguagem, é fácil estender sua funcionalidade com plugins e integrações.
Elasticsearch-Hadoop
O Elasticsearch para Apache Hadoop (Elasticsearch-Hadoop ou ES-Hadoop) é uma pequena biblioteca gratuita e aberta, independente e autocontida que permite que os trabalhos do Hadoop interajam com o Elasticsearch. Use-o para desenvolver facilmente aplicações de busca dinâmicas e incorporadas e oferecer dados do Hadoop ou executar analítica profunda e de baixa latência usando consultas e agregações geoespaciais de texto completo.
Saiba mais sobre o ES-HadoopApache Hive
O Elasticsearch para Apache Hadoop oferece suporte de primeira classe para Apache Hive, um sistema de data warehouse para Hadoop que facilita o resumo dos dados, consultas ad-hoc e a análise de grandes conjuntos de dados armazenados em sistemas de arquivos compatíveis com Hadoop.
Saiba mais sobre a integração do Apache HiveApache Spark
O Elasticsearch para Apache Hadoop oferece suporte de primeira classe para o Apache Spark, um sistema de computação em cluster rápido e de uso geral. Ele fornece APIs de alto nível em Java, Scala e Python e um mecanismo otimizado que dá suporte a gráficos de execução geral.
Saiba mais sobre a integração do Apache SparkInteligência de negócios (BI)
Graças às suas interfaces JDBC e ODBC, uma ampla variedade de aplicações de BI de terceiros pode usar as funcionalidades do Elasticsearch SQL.
Explore as integrações de BI e SQL disponíveisPlugins e integrações
Como o Elasticsearch é uma aplicação gratuita, aberta e independente de linguagem, é fácil estender sua funcionalidade com plugins e integrações. Os plugins são uma maneira de aprimorar a funcionalidade principal do Elasticsearch de maneira customizada, enquanto as integrações são ferramentas ou módulos externos que facilitam o trabalho com o Elasticsearch.
Explore os plugins do Elasticsearch disponíveisPlugins de extensão de API
Plugins de alerta
Plugins de análise
Plugins de descoberta
Plugins de ingestão
Plugins de gerenciamento
Plugins mapeadores
Plugins de segurança
Plugins de repositório de restauração/snapshot
Plugins de armazenamento
Gerenciamento e operações
Implantação
Facilitamos a execução e o gerenciamento do Elasticsearch para você, seja na nuvem pública, na nuvem privada ou em uma combinação das duas.
Baixar e instalar
Começar é mais fácil do que nunca. Basta baixar e instalar o Elasticsearch e o Kibana como um arquivo ou com um gerenciador de pacotes. Num instante, você estará indexando, analisando e visualizando dados. E com a distribuição padrão, você também pode testar os recursos da opção Platina, como machine learning, segurança, análise de dados gráficos e muito mais com uma avaliação gratuita de 30 dias.
Baixar o Elastic StackElastic Cloud
O Elastic Cloud é a nossa família que não para de crescer, composta por produtos SaaS que facilitam implantar, operar e escalonar os produtos e soluções da Elastic na nuvem. Desde uma experiência com o Elasticsearch hospedado e gerenciado de maneira simples até soluções de busca sofisticadas e instantâneas, o Elastic Cloud é o ponto de partida para colocar a Elastic para trabalhar para você. Experimente qualquer um dos nossos produtos do Elastic Cloud gratuitamente por 14 dias, sem necessidade de informar cartão de crédito.
Comece a usar o Elastic CloudInicie uma avaliação gratuita do Elasticsearch Service
Elastic Cloud Enterprise
Com o Elastic Cloud Enterprise (ECE), você pode provisionar, gerenciar e monitorar o Elasticsearch e o Kibana em qualquer escala, em qualquer infraestrutura, gerenciando tudo com um único console. Escolha onde executar o Elasticsearch e o Kibana: hardware físico, ambiente virtual, nuvem privada, zona privada em uma nuvem pública ou simplesmente em uma nuvem pública normal (por exemplo, Google, Azure, AWS). Atendemos a todas as versões.
Experimente o ECE gratuitamente por 30 diasElastic Cloud on Kubernetes
Desenvolvido sobre o padrão do Kubernetes Operator, o Elastic Cloud on Kubernetes (ECK) estende os recursos básicos de orquestração do Kubernetes para oferecer suporte à configuração e ao gerenciamento do Elasticsearch e do Kibana no Kubernetes. O Elastic Cloud on Kubernetes simplifica os processos em torno de implantação, atualizações, snapshots, redimensionamento, alta disponibilidade, segurança e muito mais para a execução do Elasticsearch no Kubernetes.
Faça a implantação com o Elastic Cloud on KubernetesGráficos Helm
Implante em minutos com os gráficos Helm oficiais do Elasticsearch e do Kibana.
Leia sobre os gráficos Helm oficiais da ElasticContainerização do Docker
Execute o Elasticsearch e o Kibana no Docker com os containers oficiais do Docker Hub.
Execute o Elastic Stack no DockerIngestão e enriquecimento
Ingestão e enriquecimento
Ingestão
Coloque os dados no Elastic Stack da maneira que desejar. Use RESTful APIs, clientes de linguagem, nós de ingestão, agentes lightweight ou o Logstash. Você não fica limitado a uma lista de linguagens e, como somos open source, você não tem limitações quanto ao tipo de dados que pode ser ingerido. Se precisar enviar um tipo de dados exclusivo, forneceremos as bibliotecas e as etapas para você criar seus próprios métodos de ingestão exclusivos. E, se quiser, você poderá compartilhá-los com a comunidade para que a próxima pessoa não precise reinventar a roda.
Clientes e APIs
O Elasticsearch usa APIs RESTful e JSON padrão. Também desenvolvemos e mantemos clientes em muitas linguagens, como Java, Python, .NET, SQL e PHP. Além disso, nossa comunidade contribui com muitas outras. Elas são fáceis de trabalhar, a sensação é de naturalidade ao usar e, assim como o Elasticsearch, não limitam o que você quer fazer com elas.
Nó de ingestão
O Elasticsearch oferece uma variedade de tipos de nós, um dos quais é específico para ingestão de dados. Os nós de ingestão podem executar pipelines de pré-processamento, compostos por um ou mais processadores de ingestão. Dependendo do tipo de operações realizadas pelos processadores de ingestão e dos recursos necessários, pode fazer sentido ter nós de ingestão dedicados que realizarão apenas essa tarefa específica.
Beats
Os Beats são agentes de dados open source que você instala como agentes nos seus servidores para enviar dados operacionais ao Elasticsearch ou ao Logstash. A Elastic fornece Beats para capturar uma variedade de logs, métricas e outros tipos de dados comuns.
Auditbeat para logs de auditoria do Linux
Filebeat para arquivos de log
Functionbeat para dados na nuvem
Heartbeat para dados de disponibilidade
Journalbeat para diários do systemd
Metricbeat para métricas de infraestrutura
Packetbeat para tráfego de rede
Winlogbeat para logs de eventos do Windows
Logstash
O Logstash é um mecanismo open source de coleta de dados com recursos de pipeline em tempo real. O Logstash pode unificar dinamicamente dados de fontes diferentes e normalizar os dados em destinos de sua escolha. Limpe e democratize todos os seus dados para diversos casos de uso avançados de analítica e visualização downstream.
Agentes da comunidade
Se você tem um caso de uso específico para resolver, recomendamos que você crie um Beat de comunidade. Criamos uma infraestrutura para simplificar o processo. A biblioteca libbeat, escrita inteiramente em Go, oferece a API que todos os Beats usam para enviar dados ao Elasticsearch, configurar as opções de entrada, implementar logging e muito mais.
Com mais de 100 Beats contribuídos pela comunidade, há agentes para logs e métricas do Cloudwatch, atividades do GitHub, tópicos do Kafka, MySQL, MongoDB Prometheus, Apache, Twitter e muito mais.
Explore os Beats desenvolvidos pela comunidade disponíveisIngestão e enriquecimento
Enriquecimento de dados
Com uma variedade de analisadores, tokenizador, filtros e opções de enriquecimento, o Elasticsearch transforma dados brutos em informações valiosas.
Elastic Common Schema
Analise uniformemente dados de diversas fontes com o Elastic Common Schema (ECS). Regras de detecção, trabalhos de machine learning, dashboards e outros conteúdos de segurança podem ser aplicados de forma mais ampla, as buscas podem ter mais filtros e os nomes dos campos ficam mais fáceis de lembrar.
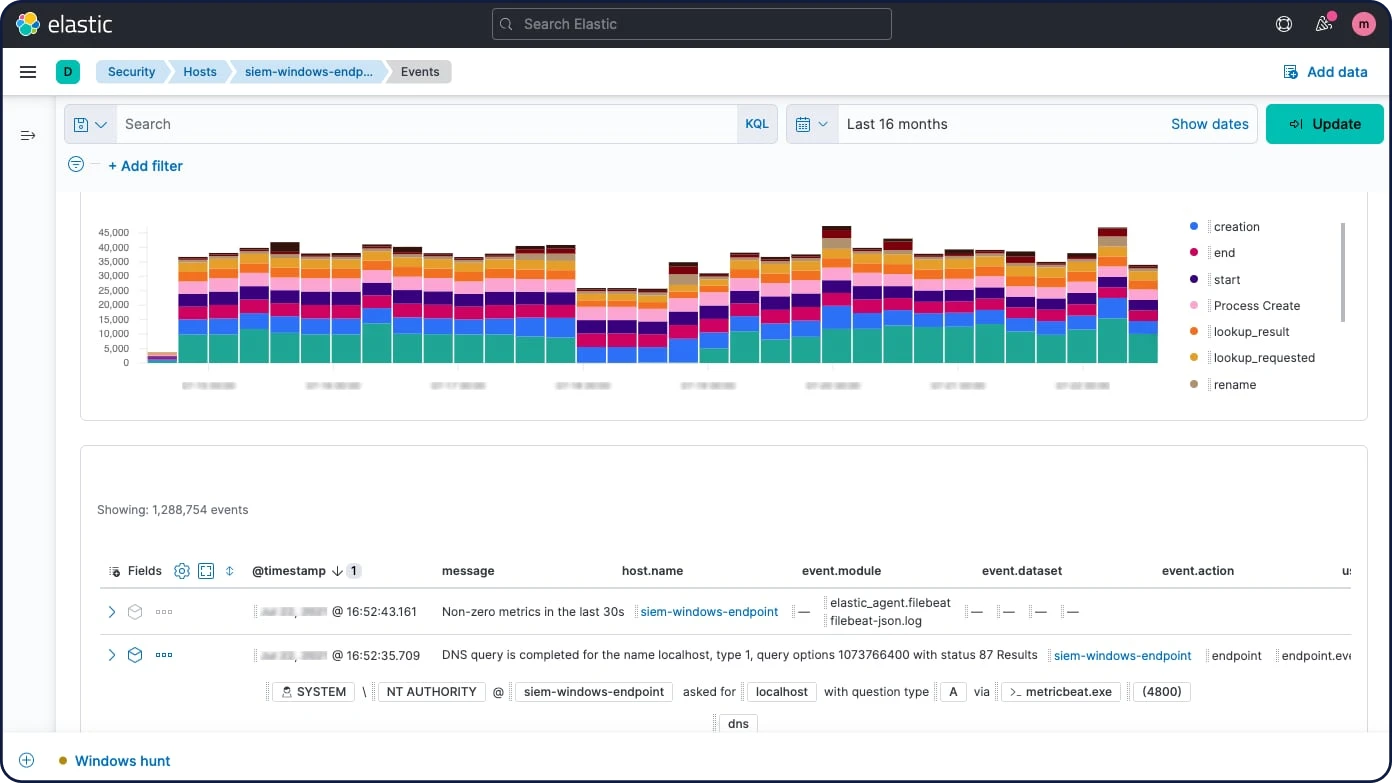
Processadores
Use um nó de ingestão para pré-processar documentos antes que a indexação real do documento aconteça. O nó de ingestão intercepta solicitações em massa e de índice, aplica transformações e, em seguida, passa os documentos de volta para o índice ou bulk APIs. O nó de ingestão oferece mais de 25 processadores diferentes, incluindo append, convert, date, dissect, drop, fail, grok, join, remove, set, split, sort, trim e outros.
Analisadores
A análise é o processo de conversão de texto, como o corpo de qualquer email, em tokens ou termos que são adicionados ao índice invertido para busca. A análise é realizada por um analisador que pode ser integrado ou customizado, definido a cada índice usando uma combinação de tokenizadores e filtros.
Exemplo: Analisador padrão (padrão)
Entrada: “The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.”
Saída: the 2 quick brown foxes jumped over the lazy dog's bone
Tokenizadores
Um tokenizador recebe um fluxo de caracteres, divide-o em tokens individuais (geralmente palavras individuais) e gera um fluxo de tokens. O tokenizador também é responsável por registrar a ordem ou posição de cada termo (usado para consultas de proximidade de frase e palavra) e os deslocamentos de caractere inicial e final da palavra original que o termo representa (usado para destacar snippets de busca). O Elasticsearch tem vários tokenizadores integrados que podem ser usados para criar analisadores personalizados.
Exemplo: Tokenizador de espaço em branco
Entrada: “The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.”
Saída: The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filtros
Os filtros de token aceitam um fluxo de um tokenizador e podem modificar tokens (por exemplo, aplicar letras minúsculas), excluir tokens (por exemplo, remover palavras irrelevantes) ou adicionar tokens (por exemplo, sinônimos). O Elasticsearch tem vários filtros de token integrados que podem ser usados para criar analisadores customizados.
Os filtros de caracteres são usados para pré-processar o fluxo de caracteres antes que ele seja passado para o tokenizador. Um filtro de caracteres recebe o texto original como um fluxo de caracteres e pode transformar o fluxo adicionando, removendo ou alterando caracteres. O Elasticsearch tem vários filtros de caracteres integrados que podem ser usados para criar analisadores customizados.
Saiba mais sobre os filtros de caracteresAnalisadores de idioma
Faça buscas em seu próprio idioma. O Elasticsearch oferece mais de 30 analisadores de idioma diferentes, incluindo muitos idiomas com conjuntos de caracteres não latinos, como russo, árabe e chinês.
Mapeamento dinâmico
Campos e tipos de mapeamento não precisam ser definidos antes de serem usados. Graças ao mapeamento dinâmico, novos nomes de campos serão adicionados automaticamente, apenas indexando um documento.
Processador enrich de correspondência
O processador de ingestão de correspondência permite que os usuários pesquisem dados no momento da ingestão e indica o índice do qual extrair dados enriquecidos. Isso ajuda os usuários dos Beats que precisam adicionar alguns elementos a seus dados — em vez de alternar dos Beats para o Logstash, os usuários podem consultar o pipeline de ingestão diretamente. Os usuários também poderão normalizar os dados com o processador para obter melhores análises e consultas mais comuns.
Processador enrich de correspondência geográfica
O processador enrich de correspondência geográfica é uma maneira útil e prática de permitir que os usuários aprimorem seus recursos de busca e agregação, utilizando seus dados geográficos sem precisar definir consultas ou agregações em termos de coordenadas geográficas. De forma semelhante ao processador enrich de correspondência, os usuários podem pesquisar dados no momento da ingestão e encontrar o índice ideal do qual extrair dados enriquecidos.
Armazenamento de dados
Armazenamento de dados
Flexibilidade
O Elastic Stack é uma solução poderosa que pode ser aplicada a praticamente qualquer caso de uso. E, embora seja mais conhecido por seus recursos avançados de busca, seu design flexível faz com que ele seja uma ferramenta ideal para muitas necessidades diferentes, incluindo armazenamento de documentos, análises e métricas de séries temporais e analítica geoespacial.
Tipos de dados
O Elasticsearch é compatível com vários tipos de dados diferentes para os campos em um documento, e cada um desses tipos de dados oferece seus próprios e múltiplos subtipos. Isso lhe permite armazenar, analisar e utilizar dados da maneira mais eficiente e eficaz possível, independentemente de seu tipo. Alguns dos tipos de dados para os quais o Elasticsearch é otimizado:
Texto
Formas
Números
Vetores
Histograma
Séries de data/hora
Campo achatado
Pontos/formas geo
Dados não estruturados (JSON)
Dados estruturados
Busca de texto completo (índice invertido)
O Elasticsearch usa uma estrutura chamada índice invertido, que é projetada para permitir buscas de texto completo muito rápidas. Um índice invertido consiste em uma lista de todas as palavras únicas que aparecem em qualquer documento e, para cada palavra, uma lista dos documentos em que ela aparece. Para criar um índice invertido, primeiro dividimos o campo de conteúdo de cada documento em palavras separadas (que chamamos de termos ou tokens), criamos uma lista ordenada de todos os termos únicos e, em seguida, listamos em qual documento cada termo aparece.
Armazenamento de documentos (dados não estruturados)
O Elasticsearch não exige que os dados sejam estruturados para serem ingeridos ou analisados (embora a estruturação melhore a velocidade). Esse design faz com que começar seja simples e também torna o Elasticsearch um armazenamento de documentos eficaz. Embora o Elasticsearch não seja um banco de dados NoSQL, ele oferece funcionalidade semelhante.
Séries temporais/analítica (armazenamento colunar)
Um índice invertido permite que as consultas pesquisem termos de busca rapidamente, mas para a classificação e as agregações, é necessário um padrão de acesso a dados diferente. Em vez de pesquisar o termo e localizar documentos, eles precisam poder pesquisar o documento e encontrar os termos que ele contém em um campo. Os valores doc são a estrutura de dados em disco no Elasticsearch, construída no momento da indexação do documento, o que possibilita esse padrão de acesso aos dados para que a busca ocorra de forma colunar. Isso permite que o Elasticsearch se destaque na análise de séries temporais e de métricas.
Armazenamento de dados
Security
A segurança não para no nível do cluster. Mantenha os dados seguros até o nível do campo no Elasticsearch.
Segurança de API no nível de campo e de documento
A segurança no nível de campo restringe os campos aos quais os usuários têm acesso de leitura. Em particular, restringe quais campos podem ser acessados por APIs de leitura baseadas em documentos.
A segurança no nível de documento restringe os documentos aos quais os usuários têm acesso de leitura. Em particular, restringe quais documentos podem ser acessados por APIs de leitura baseadas em documentos.
Saiba mais sobre a segurança no nível de documentoSuporte para criptografia de dados em repouso
Embora o Elastic Stack não implemente a criptografia em repouso, é recomendável que a criptografia no nível do disco seja configurada em todas as máquinas host. Além disso, os destinos dos snapshots também devem garantir que os dados sejam criptografados em repouso.
Armazenamento de dados
Gestão
O Elasticsearch oferece a capacidade de gerenciar totalmente seus clusters e seus respectivos nós, seus índices e seus respectivos shards e — o mais importante — todos os dados contidos neles.
Índices clusterizados
Um cluster é uma coleção de um ou mais nós (servidores) que juntos armazenam todos os seus dados e fornecem indexação federada e recursos de busca em todos os nós. Essa arquitetura simplifica o redimensionamento horizontal. O Elasticsearch fornece uma REST API abrangente e poderosa e UIs que você pode usar para gerenciar seus clusters.
Snapshot e restauração de dados
Um snapshot é um backup gerado de um cluster do Elasticsearch em execução. Você pode gerar um snapshot de índices individuais ou de todo o cluster e armazená-lo em um repositório em um sistema de arquivos compartilhado. Existem plugins disponíveis que também oferecem suporte para repositórios remotos.
Índices de rollup
Manter os dados históricos disponíveis para análise é extremamente útil, mas muitas vezes evitado devido ao custo financeiro de arquivar grandes quantidades de dados. Os períodos de retenção são, portanto, influenciados pelas realidades financeiras e não pela utilidade dos dados históricos. O recurso de rollup fornece um meio de resumir e armazenar dados históricos para que ainda possam ser usados para análise, mas por uma fração do custo de armazenamento de dados brutos.
Busca e análise
Busca e análise
Busca de texto completo
O Elasticsearch é conhecido por seus poderosos recursos de busca de texto completo. Sua velocidade vem de um índice invertido em sua essência, e seu poder vem de sua pontuação de relevância ajustável, da DSL de consulta avançada e de uma ampla variedade de recursos de aprimoramento de busca.
Índice invertido
O Elasticsearch usa uma estrutura chamada índice invertido, que é projetada para permitir buscas de texto completo muito rápidas. Um índice invertido consiste em uma lista de todas as palavras únicas que aparecem em qualquer documento e, para cada palavra, uma lista dos documentos em que ela aparece. Para criar um índice invertido, primeiro dividimos o campo de conteúdo de cada documento em palavras separadas (que chamamos de termos ou tokens), criamos uma lista ordenada de todos os termos únicos e, em seguida, listamos em qual documento cada termo aparece.
Campos de tempo de execução
Um campo de tempo de execução é um campo que é avaliado no momento da consulta (esquema na leitura). Os campos de tempo de execução podem ser introduzidos ou modificados a qualquer momento, inclusive após a indexação dos documentos, e podem ser definidos como parte de uma consulta. São expostos a consultas com a mesma interface dos campos indexados; portanto, um campo pode ser um campo de tempo de execução em alguns índices de um fluxo de dados e um campo indexado em outros índices desse fluxo de dados, e as consultas não precisam estar cientes disso. Embora os campos indexados forneçam um desempenho de consulta ideal, os campos de tempo de execução os complementam apresentando flexibilidade para alterar a estrutura de dados após a indexação dos documentos.
Campo de tempo de execução de pesquisa
Os campos de tempo de execução de pesquisa oferecem a flexibilidade de adicionar informações de um índice de pesquisa aos resultados de um índice principal, definindo uma chave em ambos os índices que vincula os documentos. Assim como os campos de tempo de execução, esse recurso é usado no momento da consulta, proporcionando um enriquecimento de dados flexível.
Busca entre clusters
O recurso de busca entre clusters (CCS) permite que qualquer nó atue como um cliente federado em vários clusters. Um nó de busca entre clusters não ingressará no cluster remoto; em vez disso, ele se conecta a um cluster remoto de maneira leve para executar solicitações de busca federada.
Pontuação de relevância
Uma similaridade (pontuação de relevância/modelo de classificação) define como os documentos correspondentes são pontuados. Por padrão, o Elasticsearch usa a similaridade BM25 — uma similaridade avançada baseada em TF/IDF que tem uma normalização tf integrada ideal para campos curtos (como nomes) — mas muitas outras opções de similaridade estão disponíveis.
Busca vetorial (ANN)
Com base no novo vizinho mais próximo aproximado do Lucene 9 ou suporte para ANN com base no algoritmo HNSW, o novo endpoint da API _knn_search facilita uma pesquisa mais escalável e com mais desempenho por similaridade de vetor. Ele faz isso permitindo uma compensação entre recall e desempenho, ou seja, permitindo um desempenho muito melhor em conjuntos de dados muito grandes (em comparação com o método de similaridade de vetor de força bruta existente) ao fazer pequenos compromissos no recall.
DSL de consulta
A busca de texto completo requer uma linguagem de consulta robusta. O Elasticsearch fornece uma DSL (linguagem específica do domínio) de consulta completa baseada em JSON para definir consultas. Crie consultas simples para corresponder a termos e frases ou desenvolva consultas compostas que possam combinar várias consultas. Além disso, filtros podem ser aplicados no momento da consulta para remover documentos antes que recebam uma pontuação de relevância.
Busca assíncrona
A API de busca assíncrona permite que os usuários executem consultas demoradas em segundo plano, acompanhem o andamento das consultas e recuperem resultados parciais assim que estiverem disponíveis.
Realçadores
Os realçadores permitem que você obtenha snippets realçados de um ou mais campos nos resultados da busca para poder mostrar aos usuários onde estão as correspondências da consulta. Quando você solicita realces, a resposta contém um elemento de realce adicional para cada ocorrência de busca que inclui os campos e os fragmentos realçados.
Digitação antecipada (preenchimento automático)
O sugeridor de preenchimento fornece a funcionalidade de preenchimento automático/busca ao digitar. Esse é um recurso de navegação para guiar os usuários para resultados relevantes enquanto eles digitam, melhorando a precisão da busca.
Sugeridores (você quis dizer)
O sugeridor de frase adiciona a funcionalidade “você quis dizer” à sua busca, criando lógica adicional em cima do sugeridor de termos para selecionar frases corrigidas inteiras, em vez de tokens individuais ponderados com base nos modelos de linguagem de n-grama. Na prática, esse sugeridor poderá tomar melhores decisões sobre quais tokens escolher com base na coocorrência e nas frequências.
Correções (verificação ortográfica)
O termo sugeridor está na raiz da verificação ortográfica, sugerindo termos com base na distância de edição. O texto de sugestão fornecido é analisado antes de os termos serem sugeridos. Os termos sugeridos são fornecidos por token de texto de sugestão analisado.
Percoladores
Invertendo o modelo de busca padrão de usar uma consulta para encontrar um documento armazenado em um índice, os percoladores podem ser usados para corresponder documentos a consultas armazenadas em um índice. A própria consulta percolate contém o documento que será usado como uma consulta para corresponder às consultas armazenadas.
Perfilador/otimizador de consultas
A API de perfil fornece informações detalhadas de tempo sobre a execução de componentes individuais em uma solicitação de busca. Ela fornece insight sobre como as solicitações de busca são executadas especificamente para que você possa entender por que certas solicitações são lentas e tomar medidas para melhorá-las.
Resultados da busca com base em permissões
A segurança no nível de campo e a segurança no nível de documento restringem os resultados da busca apenas ao que os usuários têm acesso de leitura. Em particular, restringe quais campos e documentos podem ser acessados por meio de APIs de leitura baseadas em documentos.
Sinônimos atualizáveis dinamicamente
Usando a API de recarregamento do analisador, você pode disparar o recarregamento da definição de sinônimos. O conteúdo do arquivo de sinônimos configurado será recarregado, e a definição de sinônimos que o filtro usa será atualizada. A API _reload_search_analyzers pode ser executada em um ou mais índices e disparará o recarregamento dos sinônimos do arquivo configurado.
Fixação de resultados
Promove documentos selecionados para uma classificação mais alta do que aqueles que correspondem a uma determinada consulta. Esse recurso é normalmente usado para direcionar os pesquisadores para documentos selecionados que são promovidos acima de quaisquer correspondências “orgânicas” para uma busca. Os documentos promovidos ou “fixados” são identificados usando os IDs de documentos armazenados no campo _id.
Busca e análise
Analítica
A busca por dados é apenas um começo. Com os poderosos recursos analíticos do Elasticsearch, você pode pegar os dados que buscou e encontrar um significado mais profundo. Seja agregando resultados, encontrando relações entre os documentos ou criando alertas com base nos valores limite, tudo isso é construído sobre uma base de poderosa funcionalidade de busca.
Agregações
O framework de agregações ajuda a fornecer dados agregados com base em uma consulta de busca. Ele é baseado em blocos de construção simples chamados agregações que podem ser compostos para construir resumos complexos dos dados. Uma agregação pode ser vista como uma unidade de trabalho que constrói informações analíticas sobre um conjunto de documentos.
Agregação de métricas
Agregações de bucket
Agregações de pipeline
Agregações de matriz
Agregações geohexgrid
Agregações de amostradores aleatórios
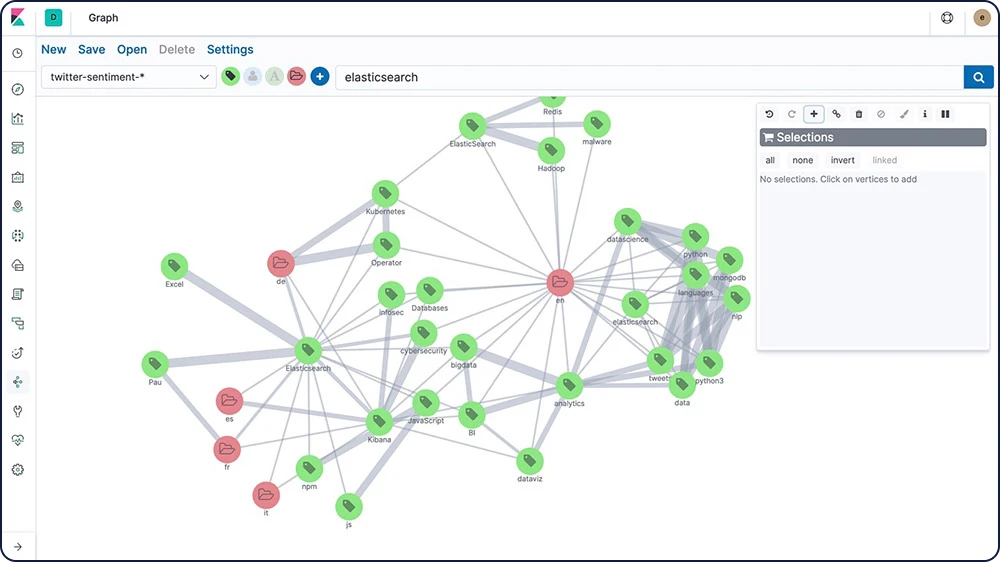
Exploração de gráfico
A Graph explore API permite extrair e resumir informações sobre os documentos e termos no seu índice do Elasticsearch. A melhor maneira de entender o comportamento dessa API é usar o Graph no Kibana para explorar as conexões.
Busca e análise
Machine learning
Os recursos de machine learning da Elastic modelam automaticamente o comportamento dos seus dados do Elasticsearch — tendências, periodicidade e muito mais — em tempo real para identificar problemas mais rapidamente, agilizar a análise de causa raiz e reduzir falsos positivos.
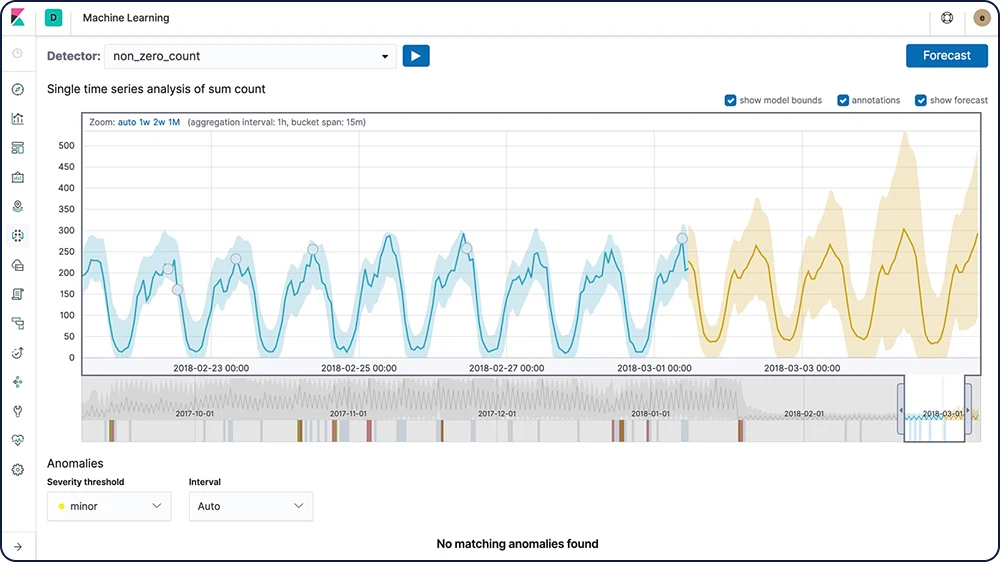
Projeção sobre séries de tempo
Depois que o machine learning da Elastic cria linhas de base de comportamento normal para seus dados, você pode usar essas informações para extrapolar o comportamento futuro. Em seguida, crie uma previsão para estimar um valor de série temporal em uma data futura específica ou estime a probabilidade de um valor de série temporal ocorrer no futuro
Detecção de anomalias em séries de tempo
Os recursos de machine learning da Elastic automatizam a análise de dados de série temporal criando linhas de base precisas de comportamento normal nos dados e identificando padrões anômalos nesses dados. As anomalias são detectadas, pontuadas e vinculadas a influenciadores estatisticamente significativos nos dados usando algoritmos proprietários de machine learning.
Anomalias relacionadas a desvios temporais em valores, contagens ou frequências
Raridade estatística
Comportamentos incomuns para um membro de uma população
Alerta sobre anomalias
Para alterações mais difíceis de definir com regras e limites, combine alertas com recursos de machine learning sem supervisão para encontrar o comportamento incomum. Então, use as pontuações de anomalia no framework de alerta para receber notificações quando surgirem problemas.
Inferência
A inferência permite que você use processos de machine learning supervisionado, como regressão ou classificação, não apenas como uma análise de lote, mas de maneira contínua. A inferência torna possível o uso de modelos de machine learning treinados nos dados recebidos.
Identificação de idioma
A identificação de idioma é um modelo treinado que você pode usar para determinar o idioma do texto. Você pode fazer referência ao modelo de identificação de idioma em um processador de inferência.