HeartbeatおよびElastic Stackによる稼働状況の監視
Elastic Stack 6.5のリリースに伴い、Heartbeatの一般提供が開始されることになりました。2017年1月に初めて導入された軽量シッパーのHeartbeatは、Elasticのその他のBeats(Metricbeat、Filebeat、Winlogbeatなど)と類似していますが、異なる点はアップタイムの監視を目的として設計されているということです。
Heartbeatはネットワークの内部または外部から運用することができます。必要なのは、目的のHTTP、TCP、またはICMPエンドポイントへのネットワークアクセスだけです。監視するURLのリストをHeartbeatに提供するだけで簡単に構成できます。Heartbeatは、エンドポイントがアップまたはダウンしているかを検証するために定期的にチェックを実行し、その情報をその他の有益なメトリックとともにElasticsearchにレポートします。これらの情報は、事前構築されたKibanaダッシュボードに自動的に表示され、設定作業を行うことなくすぐにアップタイムを監視できます。
では、Elastic StackでHeartbeatをセットアップし、使用する方法を詳しく見てみましょう。
Heartbeatをインストール
Heartbeatをインストールするには、ご使用のプラットフォーム用の事前構築済み実行ファイルをダウンロードし、抽出する必要があります。ここでは例としてmacOSを使用しますが、その他多くのオペレーティングシステムをサポートしているため、ご使用のシステムで該当するコマンドを使用して実行してください。
Heartbeatの最新バージョンをダウンロードおよび抽出します。
curl -l -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-6.5.0-darwin-x86_64.tar.gz tar xzvf heartbeat-6.5.0-darwin-x86_64.tar.gz
アップタイム監視を構成
チェックするサービスをHeartbeatに指示するためには、URLのリストが必要です。この構成は、/heartbeatフォルダーの下のheartbeat.ymlファイルで指定します。 下記は、Heartbeatで複数のHTTPをチェックする例です。チェックは10秒ごとに実行されます。
# Configure monitors
heartbeat.monitors:
- type: http
# List or urls to query
urls:
- "https://www.elastic.co"
- "https://discuss.elastic.co"
# Configure task schedule
schedule: '@every 10s'
Heartbeatでは、HTTP/Sの監視に加えてTCPおよびICMPのチェックも可能なため、サービスの異なるレイヤーにわたってより優れたインサイトを取得できます。また、チェックの追加レイヤーを定義することもできます。たとえば、 HTTP/S監視により、応答コード、本文、およびヘッダーをチェックできます。TCP監視では、ポートチェックおよび文字列チェックを定義できます。
heartbeat.monitors:
- type: http
# List or urls to query
urls: ["http://localhost:9200"]
# request details:
check.request:
method:GET
check.response:
body:"You Know, for Search"
# Configure task schedule
schedule: '@every 10s'
上記はHTTP本文チェックの例です。このチェックでは、Heartbeatが文字列「You Know, for Search」をhttp://localhost:9200(構成ファイルで指定した唯一のURL)で検索します。
Heartbeatによる監視のすべてにおいて、name、timeout、およびscheduleなど、追加のパラメーターを定義できます。構成に関する完全なインストラクションについては、こちらのドキュメント(Heartbeatの構成)をご確認ください。
構成の最後の手順は、Heartbeatの出力先(つまりデータの送信先)をセットアップすることです。サポートされている出力先には、セルフマネージドのElasticsearchクラスター、Elastic Cloud、Logstashなどがあります。 下記の例では、HeartbeatのデータをローカルのElasticsearchインスタンス(「localhost:9200」)に送信しています。
output.elasticsearch: # Array of hosts to connect to. hosts: ["localhost:9200"] # Optional protocol and basic auth credentials. #protocol: "https" username: "elastic" password: "changeme"
完全な構成のサンプルファイルは、heartbeat.reference.ymlファイルで見つけることができます。
初めてHeartbeatを使用する場合
Heartbeatには、大きな利点を提供する事前構築済みのダッシュボードが付属しています。このダッシュボードはすぐに使うことができます。下記のコマンドを使用することで、ダッシュボードをセットアップし、Heartbeatを稼働させることができます。
KibanaでHeartbeatダッシュボードをセットアップする場合:(任意。実行は1回のみ必要)
./heartbeat setup --dashboards
Heartbeatを稼働させる場合:
./heartbeat -e
Heartbeatは起動するとすぐに、構成されたURLのリストをチェックし、Elastic Stackに情報を返送し、それらの情報をKibanaダッシュボードに事前入力します。
Kibanaでアップタイムデータを可視化
Kibanaを開き、Heartbeatインデックス(デフォルトではheartbeat-*)を選択すると、[Discover]タブにHeatbeatの情報が表示されます。
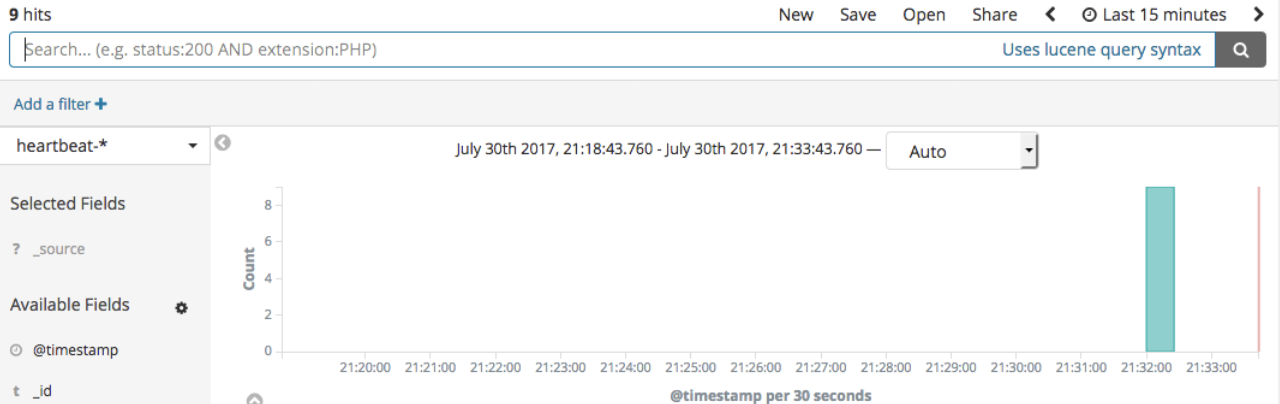
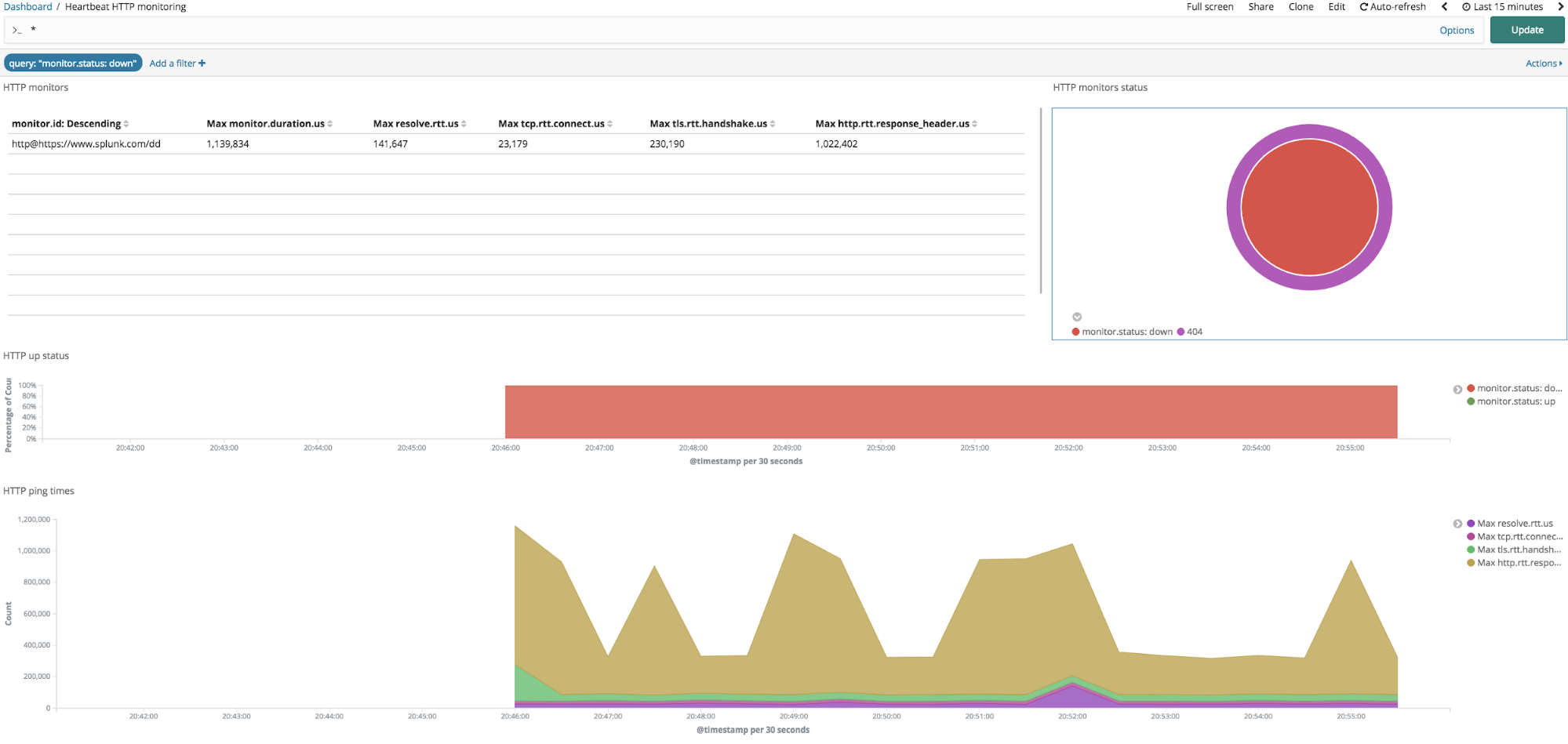
複数のダッシュボードの中に「Heartbeat HTTP monitoring」ダッシュボードがあり、Heartbeatから送信されたすべての情報が入力されています。
以下がデフォルトのHeartbeatダッシュボードです。
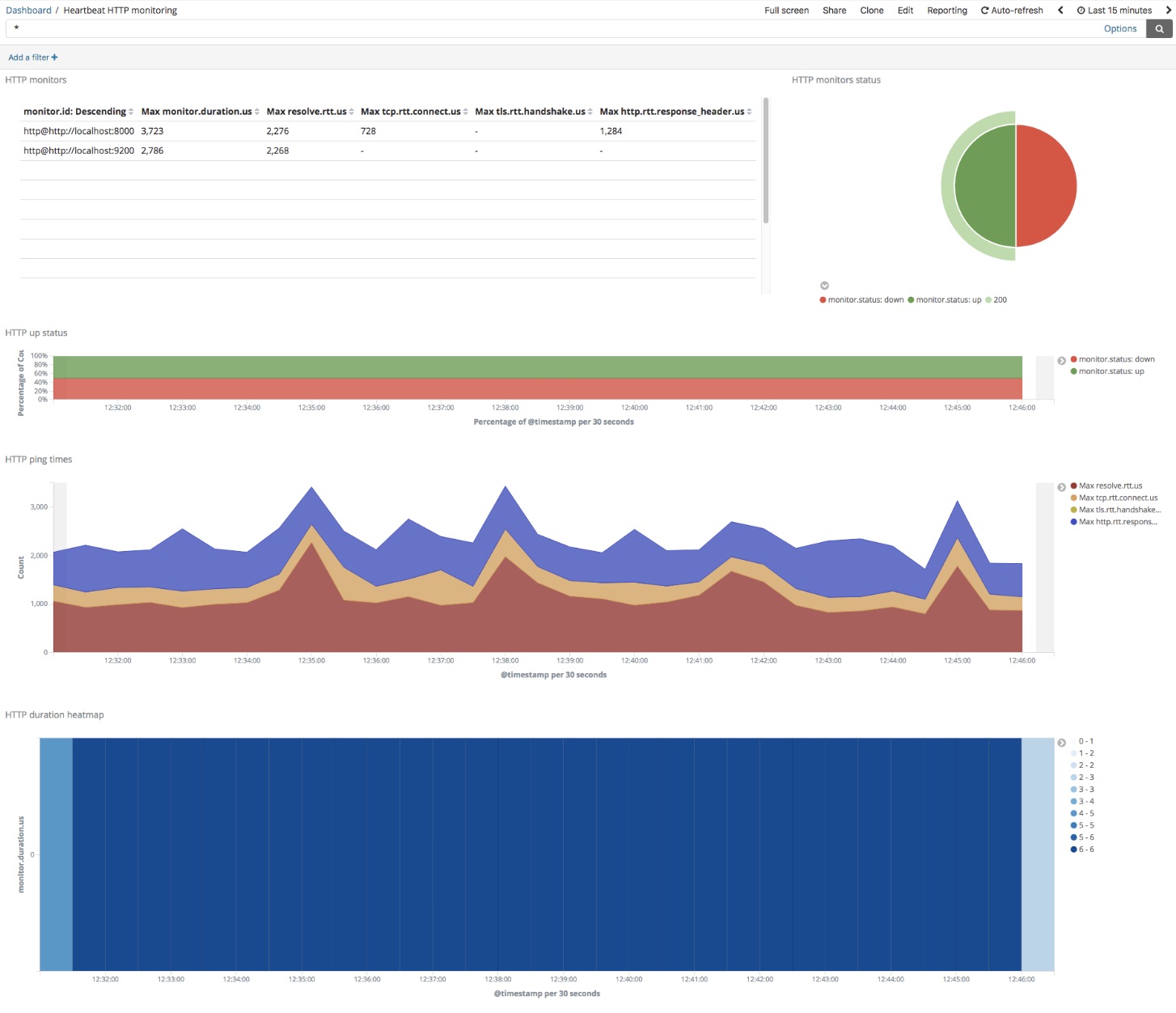
上部の左隅に、Heartbeatが監視している全エンドポイントの一覧が表示され、それぞれの応答時間が示されます。上部の右隅には、監視ステータスコードの概要が表示され、その下には監視ステータスの割合(アップまたはダウン)、経時的な応答時間、および経時的なチェック総数を示す追加のグラフが表示されています。
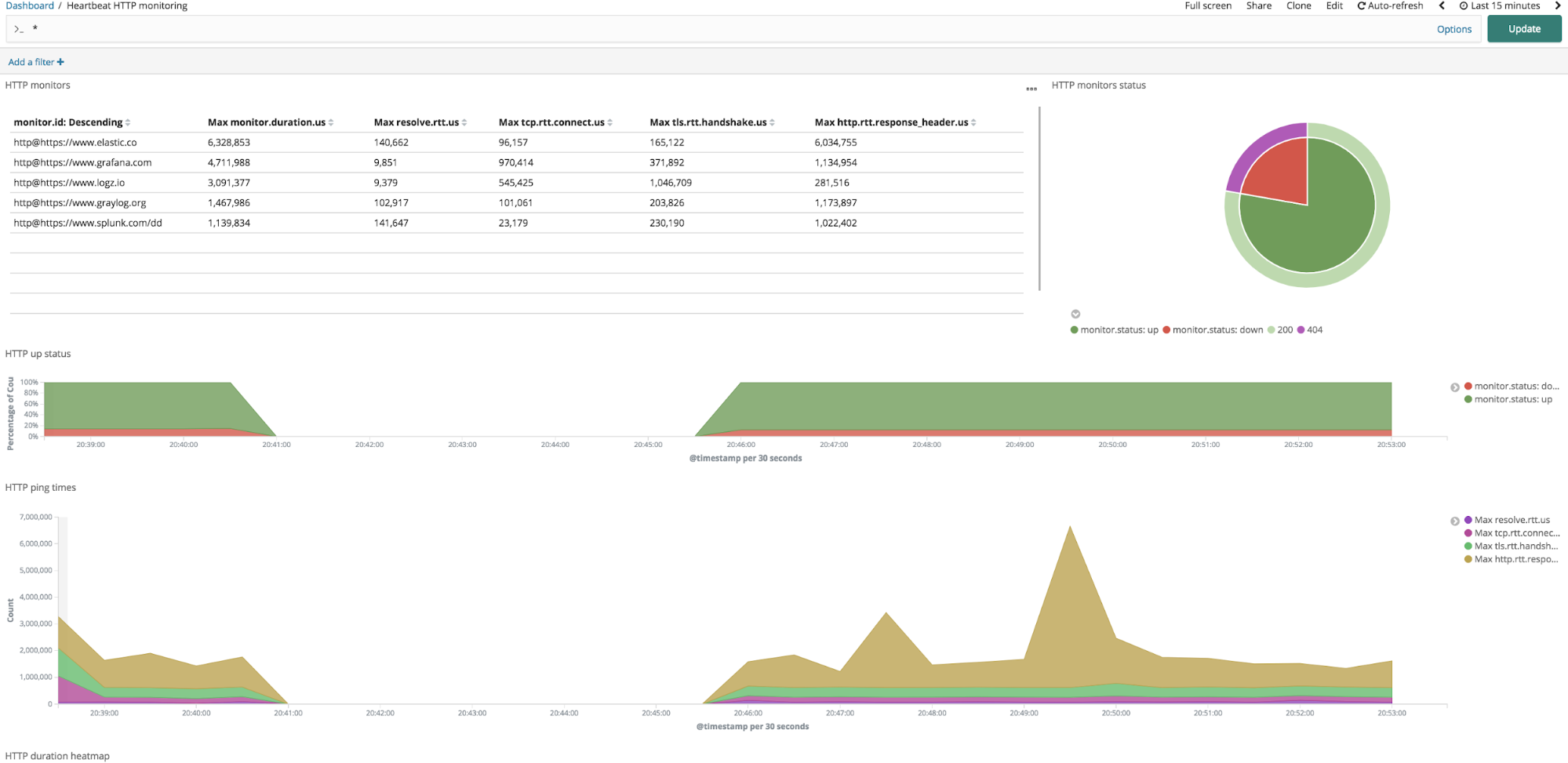
Heartbeatのダッシュボードはインタラクティブです。デフォルトのHeartbeatダッシュボードでは、監視ステータスがダウンとなっていることを示している部分(上記ダッシュボードの右上隅にある、HTTP監視ステータスの円グラフの赤色部分)をクリックすることで、特定のエンドポイントがアップまたはダウンしていることを簡単に認識できます。その部分をクリックすることでダッシュボードにフィルターが適用され、ダウン状態のエンドポイントのみが表示されます。
Heartbeat Kibanaダッシュボードとビジュアライゼーションは、ニーズを満たすためにカスタマイズすることが可能です。そのためには、ダッシュボードの右上隅にある[Edit]ボタンをクリックし、各ビジュアライゼーションのギアマークをクリックして[Edit VIsualization]を選択します。また、Heartbeatデータを基にして新たにビジュアライゼーションを作成することもできます。Heartbeatメトリックとその他のログ、メトリック、APMデータソースを組み合わせることや、運用中の任意のダッシュボードに追加することも可能です。
Heartbeatデータを他の運用データソースと組み合わせる
Heartbeatデータを、Metricbeat、Filebeat、APMなどの他のデータソースと組み合わせることで、 停止のトリアージに対して重要な情報を提供できます。Heartbeatは特定のサービスがダウンしている場合に通知し、MetricbeatとAPMはその原因の可能性を提示できます。これらはMTTRの大幅な改善に役立ち、誰もが適切な場所に注目して確認できるようになるため、指令室で行われるような典型的な「責任のなすり合い」を回避できます。
Elasticのロギング、メトリック、APMソリューションの詳細については、ソリューションページをご覧ください。
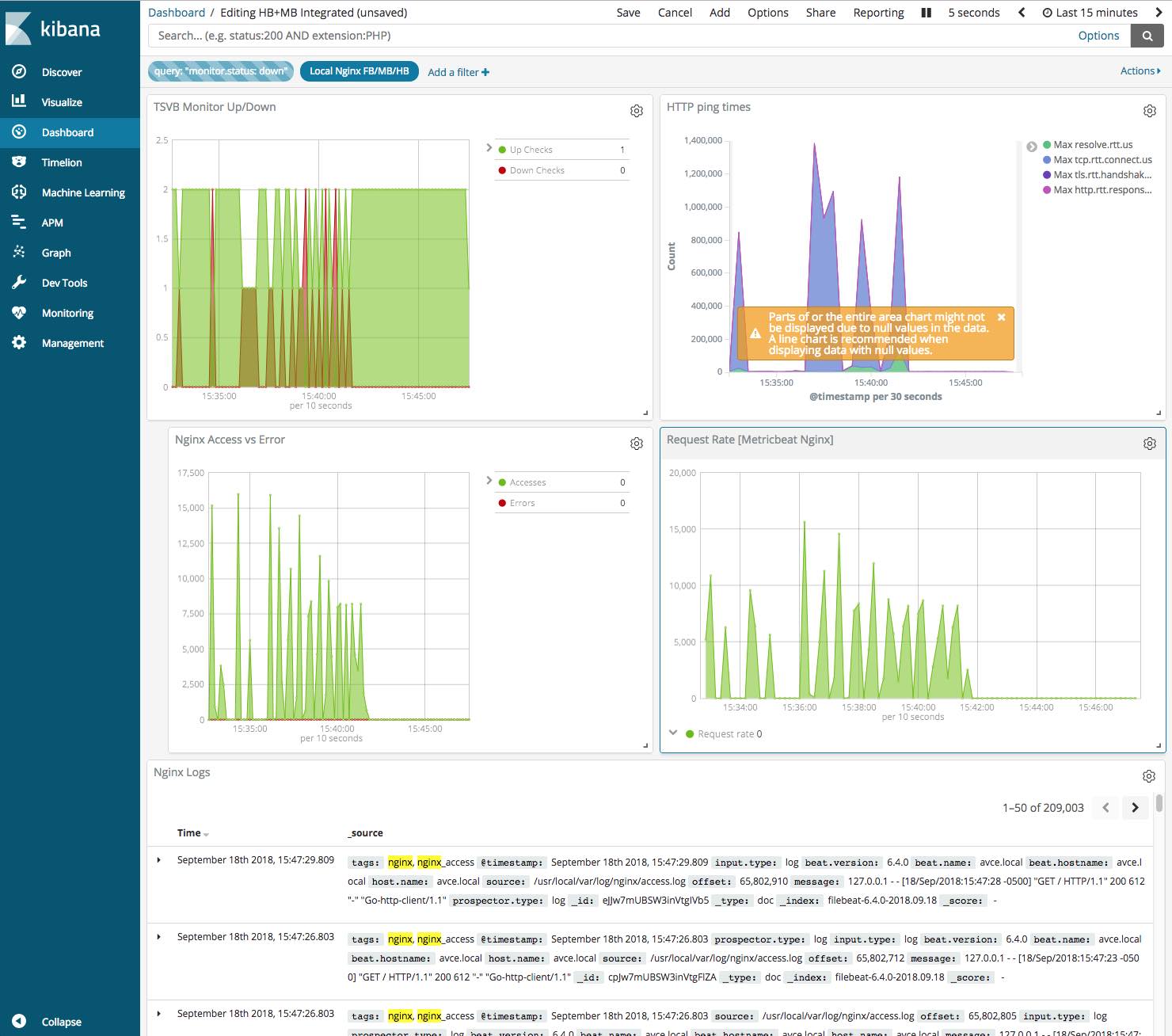
下記は、Heartbeat(上部2つのパネル)とMetricbeat(下部2つのパネル)のメトリックを組み合わせたKibanaダッシュボードの例です。
- 左側では、Heartbeatがエンドポイントのダウンを検知すると常に、MetricbeatがNginxモジュールを通じて検知するエラー数が増加することが分かります。
- 右側では、HTTP ping時間が増大すると常に、NGINXサーバーでのリクエストレートの上昇がMetricbeatで検知されることが明確に分かります。
この一致から分かることは、リクエストレートの大規模な急上昇によってNginxのエラーが引き起こされ、そのためにHeartbeatによるチェックが失敗しているということです。
アラートと異常検知
アラート機能を使用することで、Heartbeatによる監視データで停止またはパフォーマンスの低下が検知された場合に、アラートおよび通知を受け取ることができます。また、Elastic Stackの機械学習機能を使用して、Heartbeatデータの時系列分析に基づいて異常を検知することもできます。詳細については、Heartbeatに関する次回のブログで取り上げる予定です。
まとめ
監視は大変な仕事です。迅速に問題を識別し、アラートの通知から解決へと進めていく必要があります。現在、アプリケーションやインフラストラクチャー全体に対する可視性を得るために複数の異なるツールを使用しているなら、その作業はなおさら骨の折れる仕事となっているでしょう。
Heartbeatは、Elastic Stackの既存のログ、メトリック、およびAPM機能の上に、効果的なアップタイム監視機能を追加します。単独で使用することも、その他の運用データの貴重なソースと組み合わせて使用することも可能であり、稼働状態を常に把握できます。
Heartbeatに関するリソース
今回は以上です。この概要が役に立つことを願っています。Heartbeatをダウンロードして開始しましょう。機能の詳細については、Heartbeatのドキュメントをご覧ください。Heartbeatをすぐに活用する方法の1つは、アップタイムデータをElastic Cloud上のElasticsearch Serviceに送信することです。Elastic Serviceは、Elasticのプロジェクトの作成者たちが提供する、ホスト型のElasticsearchおよびKibanaサービスです。
ご質問がある場合は、Heartbeatに関するディスカッションフォーラムに投稿してください。問題に気付いた場合や強化に関してリクエストする場合は、Githubをご利用ください。