Que sont les plongements vectoriels ?
Définition des plongements vectoriels
Les plongements vectoriels convertissent les mots, les phrases et d'autres données en nombres qui en capturent le sens et les relations.Les plongements vectoriels représentent différents types de données sous forme de points dans un espace multidimensionnel, dans lequel des points de données similaires sont rassemblés à proximité les uns des autres. Ces représentations numériques aident les machines à comprendre et à traiter ces données avec plus d'efficacité.
Les plongements lexicaux et les plongements de phrases sont les deux sous-types les plus courants des plongements vectoriels, mais ce ne sont pas les seuls. Certains plongements vectoriels peuvent représenter des documents entiers. Il peut y avoir aussi des vecteurs d'images conçus pour correspondre à un contenu visuel, des vecteurs de profils d'utilisateur pour déterminer les préférences de l'utilisateur, ou encore des vecteurs de produits qui aident à identifier les produits similaires, et bien d'autres. Les plongements vectoriels aident les algorithmes de Machine Learning à repérer des schémas dans les données et à exécuter différentes tâches, telles que l'analyse des sentiments, la traduction, les systèmes de recommandation, etc.
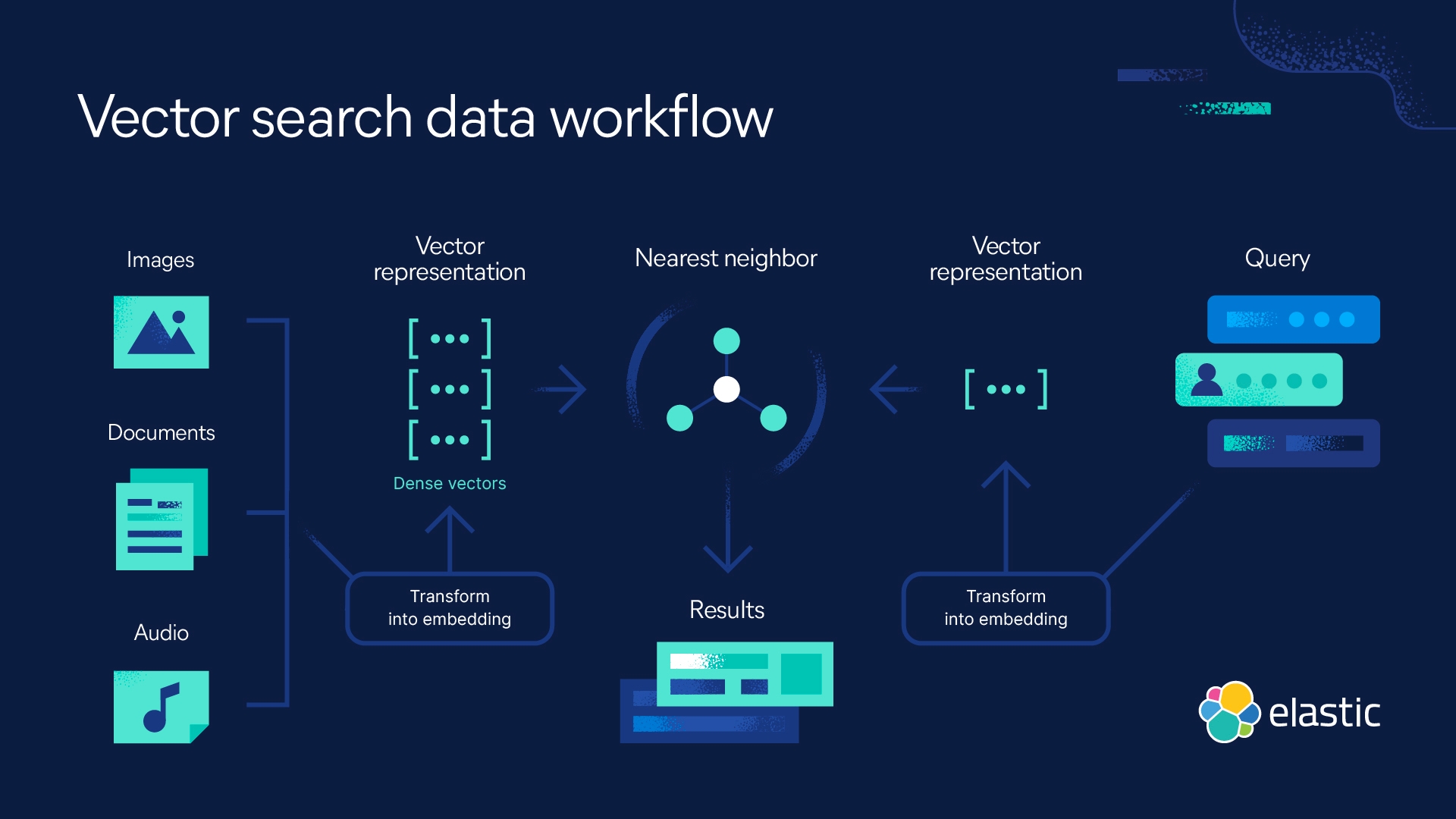
Types de plongements vectoriels
Il existe différents types de plongements vectoriels, qui sont couramment utilisés dans un large éventail d'applications. En voici quelques exemples :
Plongement lexical : ce type de plongement représente les mots sous forme de vecteurs. Plusieurs techniques sont disponibles, comme Word2Vec, GloVe et FastText. Pour apprendre un plongement lexical, ces techniques capturent les relations sémantiques et des informations contextuelles à partir de grands corpus de textes.
Plongement de phrase : ce type de plongement représente des phrases entières sous forme de vecteurs. Plusieurs modèles, comme Universal Sentence Encoder (USE) et SkipThought, génèrent des plongements qui capturent le sens dans sa globalité et le contexte des phrases.
Plongement de document : ce type de plongement représente les documents, quels qu'ils soient, sous forme de vecteurs. Il peut s'agir aussi bien d'articles de journaux que d'études universitaires ou encore de livres. Le plongement de document capture les informations sémantiques et le contexte d'un document dans son intégralité. Différentes techniques, comme Doc2Vec et Paragraph Vectors, sont conçues pour apprendre des plongements de documents.
Plongement d'image : ce type de plongement représente les images sous forme de vecteurs en capturant différentes fonctionnalités visuelles. Plusieurs techniques (comme les réseaux de neurones à convolution) et modèles pré-entraînés (ResNet, VGG, etc.) génèrent des plongements d'images pour différentes tâches, notamment la classification d'images, la détection d'objets et la similarité des images.
Plongement d'utilisateur : ce type de plongement représente les utilisateurs d'un système ou d'une plateforme sous forme de vecteurs. Il capture les préférences d'un utilisateur, ses comportements et ses caractéristiques. Les plongements d'utilisateur servent à des fins diverses et variées, comme les systèmes de recommandation, le marketing personnalisé ou encore la segmentation des utilisateurs.
Plongement de produit : ce type de plongement représente les produits du e-commerce ou des systèmes de recommandation sous forme de vecteurs. Il capture les attributs du produit, ses fonctionnalités et d'autres informations sémantiques qui le concernent. Les algorithmes peuvent ensuite utiliser ce type de plongement pour comparer, recommander et analyser des produits en fonction de leurs représentations vectorielles.
Les plongements et les vecteurs représentent-ils un même concept ?
Dans le cadre des plongements vectoriels, oui, les plongements et les vecteurs représentent un même concept. Ils désignent des représentations numériques des données, dans lesquelles chaque point de données est représenté par un vecteur dans un espace à haute dimensionnalité.
Le terme "vecteur" fait simplement référence à une série de nombres ayant une dimensionnalité spécifique. Dans le cas des plongements vectoriels, ces vecteurs représentent n'importe quel point de données parmi ceux cités ci-dessus dans un espace continu. Les "plongements", quant à eux, désignent plus précisément la technique qui consiste à représenter les données sous forme de vecteurs d'une façon qui capture des informations pertinentes, les relations sémantiques ou les caractéristiques contextuelles. Les plongements sont conçus pour capturer la structure ou les propriétés sous-jacentes des données. Ils sont généralement appris au moyen d'algorithmes ou de modèles d'entraînement.
Même si l'on peut utiliser les termes "plongement" et "vecteur" de manière interchangeable dans le cadre des plongements vectoriels, le terme "plongement" insiste sur le fait de représenter les données de façon pertinente et structurée, tandis que le terme "vecteur" fait référence à la représentation numérique en tant que telle.
Comment créer un plongement vectoriel ?
On peut créer un plongement vectoriel à l'aide d'un processus de Machine Learning, lors duquel un modèle est entraîné pour convertir une donnée en vecteur numérique. Voici un aperçu de ce processus :
- Tout d'abord, réunissez un vaste volume de données du type pour lequel vous souhaitez créer un plongement, par exemple des textes ou des images.
- Ensuite, préparez les données avant de les traiter. Cette préparation implique de nettoyer les données en supprimant le "bruit", en normalisant le texte, en redimensionnant les images ou en réalisant d'autres tâches diverses et variées selon le type de données avec lequel vous travaillez.
- Sélectionnez un modèle de réseau neuronal approprié selon vos objectifs et incorporez les données préparées dans ce modèle.
- Le modèle apprend les schémas et les relations qui existent au sein des données en ajustant ses paramètres internes au cours de l'entraînement. Par exemple, il apprend à associer des mots qui vont souvent de pair ou à reconnaître des éléments visuels dans les images.
- Au fur et à mesure de son apprentissage, le modèle génère des vecteurs numériques (ou plongements) qui représentent le sens ou les caractéristiques des données. Chaque point de données, qu'il s'agisse d'un mot ou d'une image, est représenté par un vecteur unique.
- À ce stade, vous pouvez évaluer la qualité ou l'efficacité des plongements en mesurant leurs performances sur des tâches spécifiques ou en faisant appel à des personnes pour évaluer la similarité des résultats renvoyés.
- Lorsque vous estimez que les plongements fonctionnent bien, vous pouvez les appliquer pour qu'ils analysent et qu'ils traitent vos ensembles de données.
À quoi ressemble un plongement vectoriel ?
La longueur ou la dimensionnalité d'un vecteur dépend de la technique de plongement que vous utilisez ou de la représentation que vous souhaitez obtenir pour les données. Par exemple, si vous créez des plongements lexicaux, ces derniers auront souvent des dimensions se comptant par centaines, voire par milliers. Pour des humains, il serait donc trop difficile de les représenter sous forme de schéma visuel. Les plongements de phrases ou de documents peuvent avoir une dimensionnalité plus élevée car ils capturent des informations sémantiques encore plus complexes.
Le plongement vectoriel en tant que tel est généralement représenté par une suite de nombres, comme [0.2, 0.8, -0.4, 0.6, etc.]. Chaque nombre de la suite correspond à un élément ou à une dimension spécifique, et contribue à la représentation globale du point de données. Ceci étant dit, les nombres réels au sein d'un vecteur n'ont pas de signification à proprement parler si on les prend seuls. Ce sont les valeurs relatives et les relations entre les nombres qui fournissent les informations sémantiques et permettent aux algorithmes de traiter et d'analyser les données avec efficacité.
Applications des plongements vectoriels
Les plongements vectoriels ont des applications diverses et variées dans de nombreux domaines. Ils sont notamment utiles dans les cas suivants :
Le traitement du langage naturel (NLP) a très souvent recours aux plongements vectoriels pour différentes tâches, comme l'analyse des sentiments, la reconnaissance d'entités nommées, la classification de textes, la traduction automatique, la réponse aux questions et la similarité de documents. Grâce aux plongements, les algorithmes peuvent comprendre et traiter plus efficacement les données textuelles.
Les moteurs de recherche se servent des plongements vectoriels pour récupérer des informations et déterminer les relations sémantiques. Les plongements vectoriels aident le moteur de recherche à étudier la requête d'un utilisateur et à renvoyer des pages web pertinentes sur le thème correspondant, à recommander des articles, à corriger les mots mal orthographiés dans la requête, ainsi qu'à suggérer des requêtes similaires qui pourraient être utiles à l'utilisateur. Cette application sert souvent à optimiser la recherche sémantique.
Les systèmes de recommandation personnalisés s'appuient sur les plongements vectoriels pour capturer les préférences des utilisateurs et les caractéristiques d'éléments. Ils aident à faire correspondre le profil d'un utilisateur avec des éléments qu'il pourrait apprécier, par exemple des produits, des films, des chansons ou encore des articles de journaux. Ils se basent pour cela sur des correspondances proches entre l'utilisateur et les éléments qui se trouvent dans un vecteur. Pensez par exemple au système de recommandation de Netflix. Vous vous êtes déjà demandé comment il sélectionnait des films qui pourraient correspondre à vos goûts ? Il se sert de mesures de similarité élément/élément pour suggérer un contenu similaire à ce que vous avez déjà regardé.
Les plongements vectoriels peuvent également servir à analyser des contenus visuels. Les algorithmes entraînés sur ce type de plongement vectoriel peuvent classer des images, identifier des objets et les repérer dans d'autres images, rechercher des images similaires, ou encore trier toutes sortes d'images (et de vidéos) en différentes catégories. La technologie de reconnaissance d'images que Google Lens utilise est un outil d'analyse des images fréquemment utilisé.
Les algorithmes de détection des anomalies s'appuient sur les plongements vectoriels pour identifier les schémas inhabituels ou les valeurs anormales dans différents types de données. L'algorithme s'entraîne avec des plongements qui représentent un comportement normal, afin d'apprendre à repérer les écarts d'après la distance ou les mesures de différence entre les plongements. C'est une pratique particulièrement utile dans les applications de cybersécurité.
L'analyse de graphes utilise des plongements de graphes, dans lesquels les graphes sont un ensemble de points (appelés nœuds) connectés par des lignes (appelées arêtes). Chaque nœud représente une entité, par exemple une personne, une page web ou un produit, et chaque arête représente une relation ou un lien entre ces entités. Ces plongements vectoriels peuvent être utilisés à de nombreuses fins, comme la suggestion d'amis sur les réseaux sociaux ou la détection d'anomalies de cybersécurité (comme décrit ci-dessus).
Les fichiers audio et la musique peuvent être traités et intégrés également. Les plongements vectoriels capturent des caractéristiques audio, sur lesquelles peuvent ensuite se baser les algorithmes pour analyser les données audio avec efficacité. Les applications dans ce domaine sont nombreuses : recommandations de musique, classifications de genre, recherche de morceaux similaires, reconnaissance vocale ou encore vérification des haut-parleurs.
Découvrez les plongements vectoriels avec Elasticsearch
La plateforme Elasticsearch intègre nativement un Machine Learning et une IA puissants dans les solutions, ce qui vous aide à créer des applications qui présentent de nombreux avantages pour les utilisateurs et qui accélèrent le travail. Elasticsearch est le composant principal de la Suite Elastic, un ensemble d'outils open source d'ingestion, d'enrichissement, de stockage, d'analyse et de visualisation de données.
Elasticsearch vous aide à :
- améliorer l'expérience utilisateur et augmenter le nombre de conversions ;
- découvrir de nouvelles informations exploitables et mettre en place l'automatisation, les analyses et le reporting ;
- améliorer la productivité des employés sur les documents et les applications internes.
Expérimentez des fonctions de recherche IA de pointe en utilisant vos propres données avec AI Playground.
Explorez nos ressources sur les plongements vectoriels
- Qu'est-ce que la recherche vectorielle ? Une recherche plus efficace avec le ML
- Qu'est-ce que le traitement du langage naturel (NLP) ?
- Que sont les plongements lexicaux ?
- Comment déployer le traitement du langage naturel : plongements textuels et recherche vectorielle
- 5 raisons pour lesquelles les responsables informatiques ont besoin de la recherche vectorielle pour améliorer les expériences de recherche