Définition
Qu'est-ce que la recherche vectorielle ?
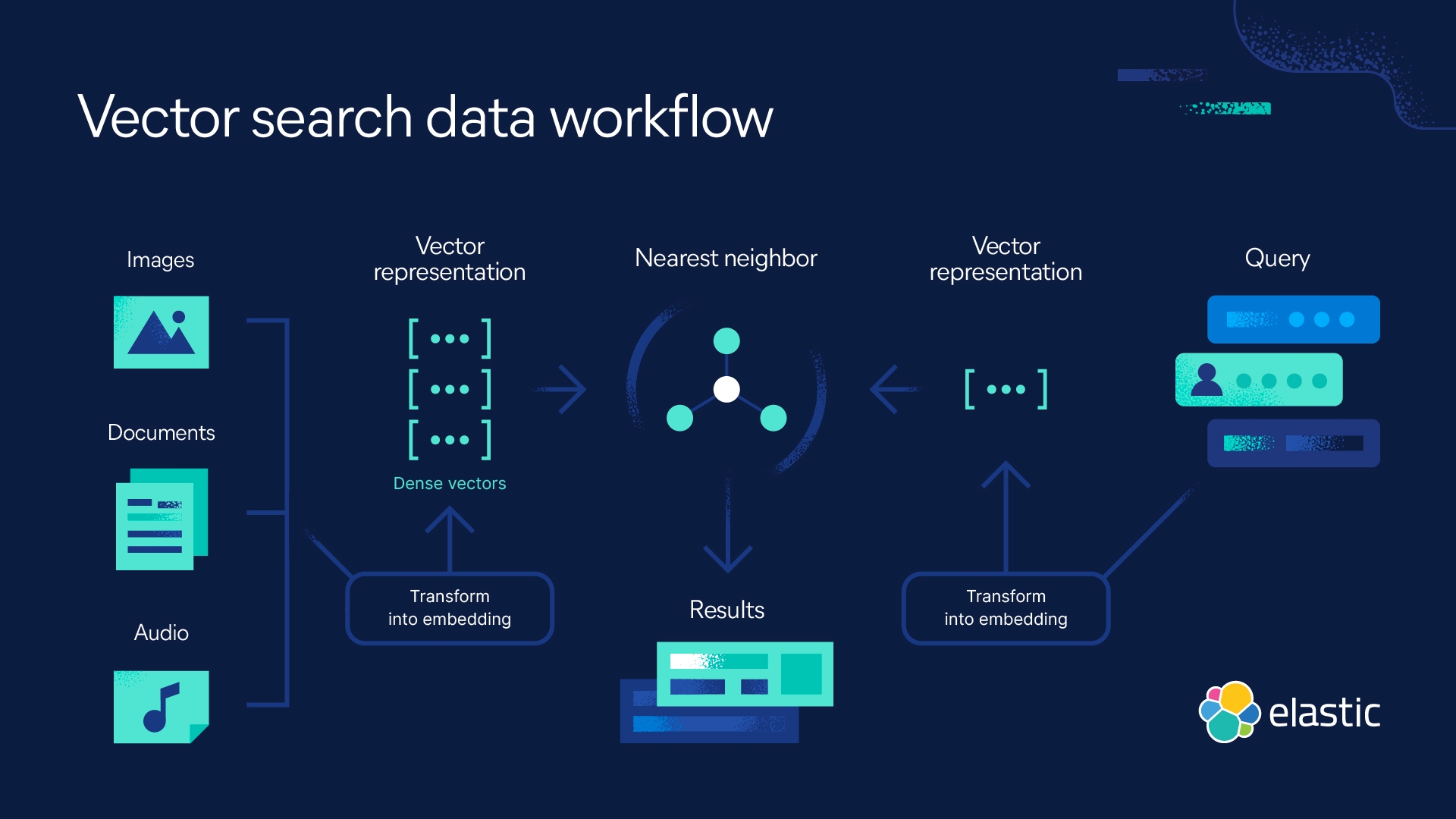
La recherche vectorielle s'appuie sur le Machine Learning (ML) pour capturer le sens et le contexte des données non structurées, notamment les textes et les images, qu'elle transforme en représentation numérique. Généralement utilisée pour la recherche sémantique, la recherche vectorielle trouve des données similaires à l'aide d'algorithmes de recherche du plus proche voisin approximatif (ANN). Par rapport à la recherche traditionnelle par mots clés, la recherche vectorielle renvoie des résultats plus pertinents et s'exécute plus rapidement.

Pourquoi la recherche vectorielle est-elle importante ?
Combien de fois avez-vous recherché quelque chose sans en connaître vraiment le nom ? Vous savez comment fonctionne cet élément ou comment le décrire. Mais sans mots clés, votre recherche risque de s'éterniser.
La recherche vectorielle surmonte cette difficulté en vous permettant de faire une recherche selon votre intention. Des réponses aux requêtes basées sur la recherche de similarité peuvent être rapidement fournies. Cela est dû au plongement vectoriel qui capture les données non structurées au-delà du texte, telles que des vidéos, des images et des fichiers audio. Vous pouvez améliorer l'expérience de recherche en combinant la recherche vectorielle avec un filtrage et des agrégations pour optimiser la pertinence en mettant en œuvre une recherche hybride et en l'associant avec une attribution traditionnelle de scores.
Comment fonctionne un moteur de recherche vectorielle ?
Les moteurs de recherche vectorielle, qu'on appelle aussi recherche dans des bases de données vectorielles, recherche sémantique ou recherche cosinus, identifient les plus proches voisins d'une requête (vectorisée) donnée.
Alors que la recherche traditionnelle s'appuie sur des mots clés, la similarité lexicale et la fréquence d'occurrence d'un terme, les moteurs de recherche vectorielle utilisent les distances dans l'espace de plongement pour représenter la similarité. L'identification des données en lien avec votre requête revient à rechercher ses plus proches voisins.
Cas d'utilisation de la recherche vectorielle
Non seulement la recherche vectorielle sous-tend la nouvelle génération d'expériences de recherche, mais elle ouvre aussi la voie à de nombreuses possibilités.
Premiers pas
La recherche vectorielle et le NLP en toute simplicité avec Elastic
Pas besoin de déplacer des montagnes pour mettre en œuvre la recherche vectorielle et appliquer les modèles de NLP. Avec Elasticsearch Relevance Engine™ (ESRE), vous avez à votre disposition un ensemble d'outils pour développer des applications de recherche en IA pouvant être utilisées avec l'IA générative et les grands modèles de langage (LLM).
Avec ESRE, vous pouvez concevoir des applications de recherche innovantes, générer des plongements, stocker et rechercher des vecteurs et mettre en œuvre la recherche sémantique avec Elastic Learned Sparse Encoder. Découvrez comment utiliser Elasticsearch en tant que base de données vectorielle ou suivez cette formation pratique à votre rythme pour la recherche vectorielle.
