Intégration de la recherche basée sur l'IA dans vos applications
Elasticsearch Relevance Engine™ (ESRE) est conçu pour propulser des applications de recherche fondées sur l'intelligence artificielle. ESRE permet d'appliquer immédiatement une recherche sémantique avec un niveau de pertinence supérieur (sans adaptation de domaine), d'effectuer une intégration à de grands modèles de langage externes, d'implémenter une recherche hybride et d'utiliser des modèles de transformateur tiers ou les vôtres.

Pour configurer Elasticsearch Relevance Engine, c'est très simple. On vous montre comment faire.
Regarder la vidéo de prise en main rapideConcevez des applications avancées basées sur la RAG à l'aide d'ESRE.
S'inscrire à la formationUtilisez les données internes privées pour donner du contexte aux fonctionnalités des modèles d'IA générative afin de fournir des réponses fiables et à jour aux questions des utilisateurs.
Regarder la vidéoIA pour l'ensemble des développeurs
Amélioration de la recherche à l'aide de l'intelligence artificielle
Intégrez des fonctionnalités de pertinence avancées et fondées sur l'intelligence artificielle à votre application grâce à ESRE, indépendamment de votre niveau d'expertise. ESRE est doté d'un éventail de fonctionnalités qui vous aide à vous lancer avec l'intelligence artificielle et à développer votre expérience en la matière. Vous bénéficiez de la flexibilité et du contrôle nécessaires pour déployer des applications de recherche propulsées par l'intelligence artificielle générative et de Machine Learning qui répondent à vos besoins.



Elasticsearch Relevance Engine
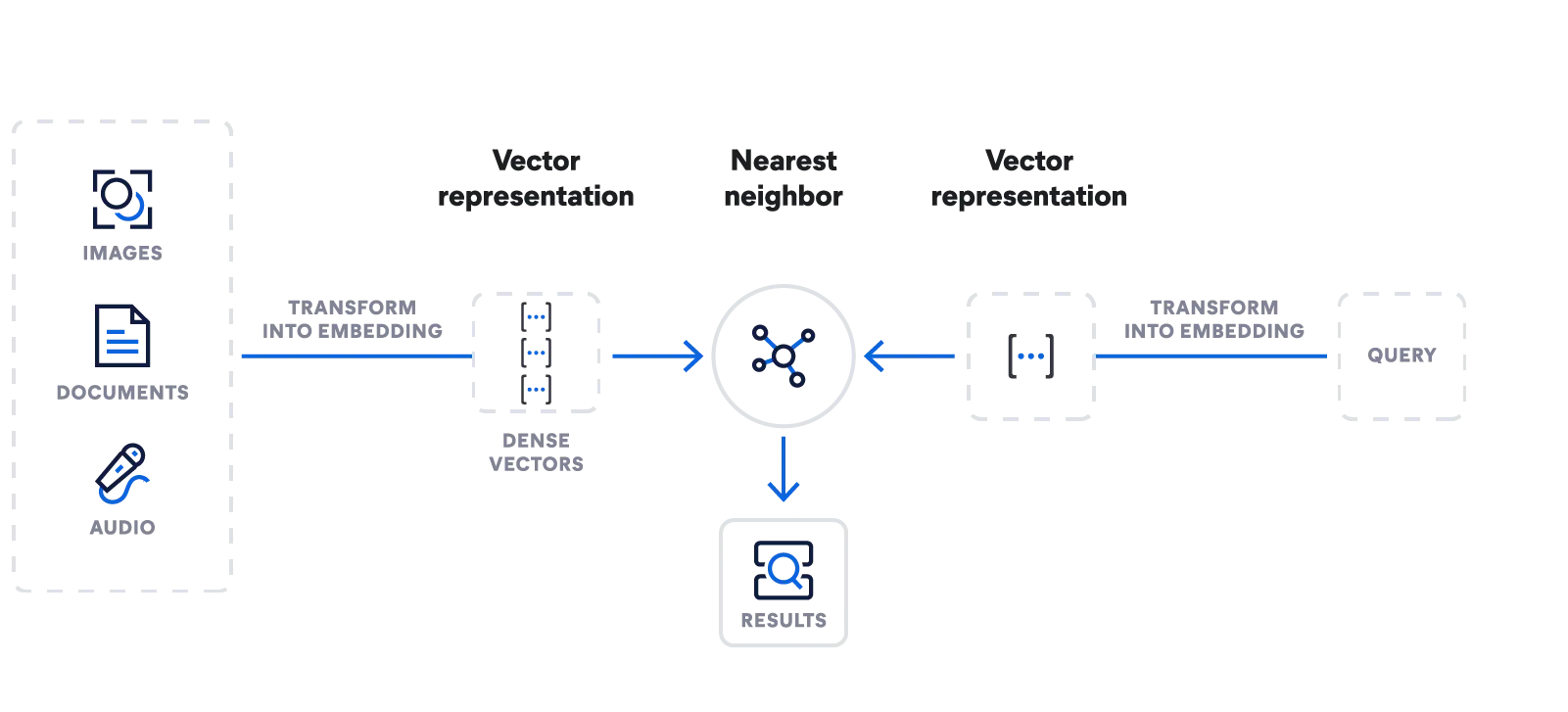
Elasticsearch - un poids lourd de la recherche vectorielle centralisée
Générez des plongements. Stockez des vecteurs, recherchez-les et gérez-les. Bénéficiez de la recherche sémantique grâce au propre modèle de Machine Learning Learned Sparse Encoder d'Elastic. Ingérez tous types de données. Intégrez-les à l'aide de grands modèles de langage à l'évolution rapide.
Échantillons de code
Lancement de la conception de la recherche vectorielle
Utilisez une seule API pour importer un modèle de plongement, générer des plongements et saisir des requêtes de recherche à grande échelle à l'aide du plus proche voisin approximatif.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--cloud-id $CLOUD_ID \
-u <username> -p <password> \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--startQuestions fréquentes
Qu'est-ce qu'Elasticsearch Relevance Engine ?
Qu'est-ce qu'Elasticsearch Relevance Engine ?
Elasticsearch Relevance Engine est un ensemble de fonctionnalités qui aident les développeurs à concevoir des applications de recherche propulsées par l'IA. Il comprend notamment :
- des fonctionnalités avancées et de pointe de classement par pertinence, y compris la recherche traditionnelle par mot-clé avec BM25, sur lesquelles se fonde la recherche hybride pertinente pour l'ensemble des domaines ;
- les fonctionnalités complètes de la base de données vectorielle, y compris la capacité à créer des plongements, en plus du stockage et de la récupération des vecteurs ;
- Elastic Learned Sparse Encoder, notre nouveau modèle de Machine Learning pour la recherche sémantique dans un éventail de domaines ; le classement hybride (RRF) pour l'association des fonctionnalités de recherche vectorielle et textuelle afin de garantir une pertinence optimale dans un vaste éventail de domaines ;
- la prise en charge de l'intégration à des modèles tiers de transformateur, comme OpenAI GPT-3 et 4 via des API ;
- une suite complète d'outils d'ingestion des données, comme des connecteurs de base de données, des intégrations de données tierces, des robots d'indexation et des API, qui permet de créer des connecteurs personnalisés ;
- des outils de développement permettant de concevoir des applications de recherche pour tous les types de données, notamment textuelles, images, temporelles, géographiques et multimédias.
Que puis-je développer à l'aide d'Elasticsearch Relevance Engine ?
Que puis-je développer à l'aide d'Elasticsearch Relevance Engine ?
Elasticsearch est une technologie de recherche de pointe pour les sites web (comme la découverte et les produits d'e-commerce) et l'information en interne (notamment la recherche d'entreprise et les bases de connaissances de témoignages de clients). Avec Elasticsearch Relevance Engine, nous mettons à votre disposition un kit d'outils permettant de garantir des expériences de recherche propulsées par l'IA. Donnez aux utilisateurs la possibilité de saisir leurs requêtes en langage naturel sous forme de question ou de description du type d'informations recherchées. Associez cette fonctionnalité de langage naturel à l'IA générative pour améliorer davantage les capacités de ces modèles en apportant un contexte provenant de vos propres données privées ou propriétaires.
Elasticsearch et Elasticsearch Relevance Engine désignent-ils la même chose ?
Elasticsearch et Elasticsearch Relevance Engine désignent-ils la même chose ?
Oui, les fonctionnalités comprises dans Elasticsearch Relevance Engine sont conçues et intégrées à l'API _search dans Elasticsearch. Les développeurs peuvent utiliser les API d'Elastic ou leurs outils de prédilection, comme Kibana, pour interagir avec les fonctionnalités d'Elasticsearch Relevance Engine avec Elasticsearch pour garantir une expérience sans accroc.
Qu'est-ce qu'Elastic Learned Sparse Encoder ?
Qu'est-ce qu'Elastic Learned Sparse Encoder ?
Elastic Learned Sparse Encoder est un modèle conçu par Elastic pour la recherche sémantique hautement pertinente dans un vaste éventail de domaines. Actuellement, il s'agit d'un modèle de Machine Learning disponible en anglais uniquement. Il capture les relations entre les significations et les mots à des fins de récupération d'informations. Souhaitez-vous en savoir plus sur les études comparatives avec notre nouveau modèle de récupération ? Vous trouverez des informations utiles à ce sujet dans notre article.
Qu'est-ce qu'un transformateur ? Elastic Learned Sparse Encoder est-il un modèle de transformateur ?
Qu'est-ce qu'un transformateur ? Elastic Learned Sparse Encoder est-il un modèle de transformateur ?
Un transformateur est une architecture de réseau de neurones profond qui sert de base aux grands modèles de langage. Les transformateurs comprennent plusieurs composants. Ils peuvent être dotés d'encodeurs, de décodeurs et de nombreuses couches de réseau de neurones "profond" avec plusieurs millions (voire milliards) de paramètres. En règle générale, ils sont entraînés à l'aide d'un très grand corpus de données textuelles disponibles en ligne, et peuvent être spécialement conçus pour effectuer un vaste éventail de tâches liées au traitement du langage naturel. Notre nouveau modèle de récupération utilise une architecture de transformateur, mais ne comprend qu'un seul encodeur spécialement conçu pour la recherche sémantique dans un vaste éventail de domaines.
Comment se lancer avec Elasticsearch Relevance Engine ? Faut-il l'acheter séparément ?
Comment se lancer avec Elasticsearch Relevance Engine ? Faut-il l'acheter séparément ?
Toutes les fonctionnalités d'Elasticsearch Relevance Engine sont fournies dans le cadre des plans Platinum et Enterprise d'Elastic Enterprise Search, lors du lancement de la version 8.8. Vous pouvez facilement vous lancer avec les plongements et la recherche vectorielle, mais aussi essayer le modèle de récupération. Regardez notre démonstration des fonctionnalités d'Elastic Learned Sparse Encoder. Si vous possédez une licence Elasticsearch, Elasticsearch Relevance Engine est compris dans votre achat.