


Partager sur Twitter


Partager sur LinkedIn


Partager sur Facebook


Partage par e-mail


Imprimer
Prise en charge par Elastic des modèles de Machine Learning dont vous avez besoin
Elastic® vous permet d'appliquer la solution de Machine Learning adaptée à votre cas d'utilisation et à votre expertise dans ce domaine. Vous disposez de plusieurs options :
- Tirez parti de modèles intégrés. Outre les modèles ciblant des menaces de sécurité spécifiques et les types de problèmes système au sein de notre solution d'observabilité et de sécurité, vous pouvez utiliser notre modèle Elastic Learned Sparse Encoder propriétaire prêt à l'emploi ainsi qu'une fonctionnalité de détection de la langue, ce qui est très utile si vous travaillez avec des données textuelles dans une autre langue que l'anglais.
- Accédez aux modèles PyTorch tiers provenant de n'importe quelle source, y compris le hub de modèles HuggingFace.
- Chargez un modèle que vous avez entraîné vous-même. Il s'agit principalement de transformateurs de traitement du langage naturel à cette étape.
En utilisant des modèles intégrés, vous en tirez immédiatement une valeur sans devoir disposer d'une expertise en Machine Learning. Ainsi, vous pouvez essayer en toute flexibilité différents modèles et choisir celui qui obtient les meilleures performances avec vos données.
Nous avons conçu notre gestion de modèles afin qu'elle soit scalable sur de nombreux nœuds au sein d'un cluster, tout en garantissant aussi de bonnes performances d'inférence pour les charges de travail à débit élevé comme à faible latence. Dans cette optique, les pipelines d'ingestion peuvent exécuter une inférence et des nœuds dédiés sont utilisés pour l'inférence des modèles les plus gourmands en ressources de calcul lors de l'ingestion, mais aussi de l'analyse et de la recherche.
Lisez cet article pour découvrir la bibliothèque Eland grâce à laquelle vous pouvez charger des modèles dans Elastic. Apprenez aussi comment elle s'inscrit par rapport aux différents types de Machine Learning que vous pourriez utiliser au sein d'Elasticsearch®, depuis les derniers modèles de transformateur et de traitement du langage naturel jusqu'aux modèles d'arborescence optimisée pour la régression.
Chargement de vos modèles de Machine Learning dans Elastic avec Eland
Notre bibliothèque Eland fournit une interface conviviale pour charger des modèles de Machine Learning dans Elasticsearch, à condition qu'ils aient été entraînés à l'aide de PyTorch. Grâce à la bibliothèque native libtorch et aux modèles qui ont été exportés ou sauvegardés en tant que représentation TorchScript, Elasticsearch évite d'exécuter un interpréteur Python lors de l'inférence des modèles.
En intégrant l'un des formats les plus populaires pour créer des modèles de traitement du langage naturel dans PyTorch, Elasticsearch peut fournir une plateforme qui fonctionne avec un vaste éventail de cas d'utilisation et de tâches de traitement du langage naturel. Nous nous pencherons plus en détail sur ce point dans la section dédiée aux transformateurs ci-dessous.
Vous disposez de trois alternatives pour utiliser Eland en vue de charger un modèle, à savoir la ligne de commande, Docker et directement depuis votre propre code Python. Docker est moins complexe, car il ne nécessite aucune installation locale d'Eland ni de l'ensemble de ses dépendances. Quand vous accédez à Eland, l'échantillon de code ci-dessous vous montre comment charger un modèle NER DistilBERT à titre d'exemple.

Plus bas dans cet article, nous passerons en revue chaque argument d'eland_import_hub_model. Vous pouvez également émettre la même commande depuis un conteneur Docker.
Après le chargement, l'interface utilisateur de la fonctionnalité de gestion des modèles de Machine Learning de Kibana vous permet de gérer les modèles dans un cluster Elasticsearch, y compris en augmentant les allocations pour un débit supplémentaire, mais aussi en arrêtant/relançant des modèles tout en (re)configurant votre système.
Quels modèles sont pris en charge ?
Elastic prend en charge un éventail de modèles de transformateur et la plupart des bibliothèques d'apprentissage supervisé les plus populaires :
- Modèles de plongement et de traitement du langage naturel. Il s'agit de tous les transformateurs conformes à l'interface de modèle BERT standard et qui utilisent l'algorithme de conversion en tokens WordPiece. Obtenez la liste complète des architectures de modèles prises en charge.
- Apprentissage supervisé. Il s'agit des modèles entraînés provenant des bibliothèques scikit-learn, XGBoost et LightGBM qui peuvent être sérialisés et utilisés en tant que modèle d'inférence dans Elasticsearch. Notre documentation fournit un exemple d'entraînement d'une classification XGBoost à l'aide de données dans Elastic. Vous pouvez également exporter et importer dans Elastic des modèles supervisés entraînés à l'aide de nos analyses des trames de données.
- IA générative. Vous pouvez utiliser l'API fournie pour les grands modèles de langage afin de transférer des requêtes (potentiellement enrichies à l'aide du contexte récupéré auprès d'Elastic) et de traiter les résultats obtenus. Pour obtenir de plus amples instructions, consultez cet article qui contient des liens vers un référentiel GitHub et un échantillon de code pour la communication via l'API de ChatGPT.
Ci-dessous, nous vous fournissons des informations supplémentaires au sujet du type de modèle que vous êtes plus susceptible d'utiliser dans le contexte des applications de recherche, à savoir les transformateurs de traitement du langage naturel.
Méthode d'application des transformateurs et du traitement du langage naturel dans Elastic en toute simplicité
Nous allons vous expliquer pas à pas comment charger et utiliser un modèle de traitement du langage naturel, par exemple un modèle NER populaire provenant de Hugging Face, tout en passant en revue les arguments identifiés dans l'extrait de code ci-dessous.

- Indiquez l'identifiant Elastic Cloud. Vous pouvez également utiliser --url.
- Renseignez les informations d'authentification pour accéder à votre cluster. Vous pouvez consulter les méthodes d'authentification disponibles.
- Indiquez l'identifiant pour le modèle provenant du hub Hugging Face.
- Indiquez le type de tâche de traitement du langage naturel. Les valeurs prises en charge sont fill_mask, ner, text_classification, text_embedding et zero_shot_classification.
Après avoir chargé le modèle, vous devez le déployer depuis la page "Model Management" (Gestion des modèles) dans l'onglet Machine Learning de Kibana. Ensuite, vous devriez tester le modèle pour vous assurer qu'il fonctionne correctement.
Désormais, vous pouvez utiliser le modèle déployé pour l'inférence. Par exemple, pour extraire les entités nommées, vous appelez le point de terminaison _infer dans le modèle NER chargé.
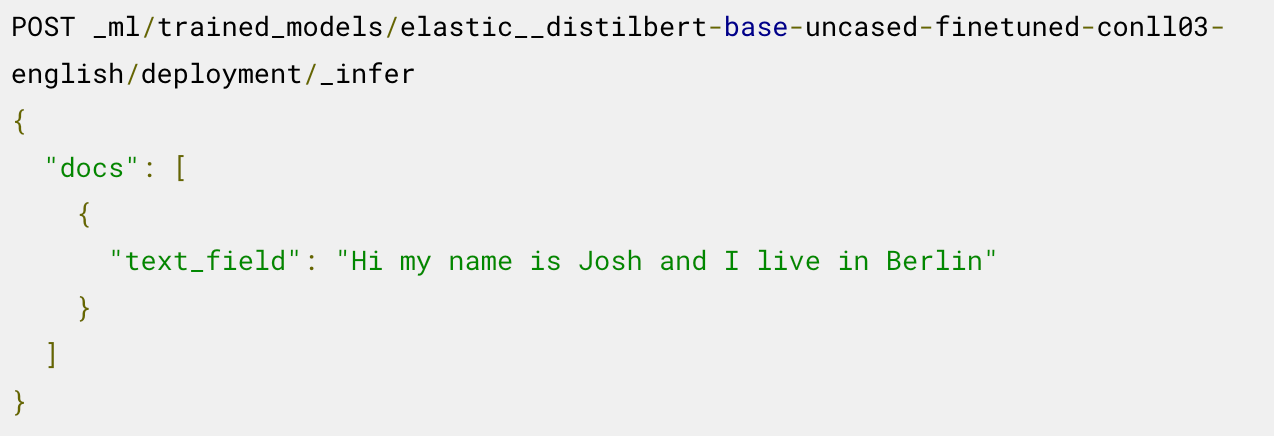
Le modèle identifie deux entités : la personne "Josh" et le lieu "Berlin".

Pour connaître les étapes supplémentaires, comme l'utilisation de ce modèle dans un pipeline d'inférence et le réglage du déploiement, lisez cet article qui décrit cet exemple.
Voulez-vous apprendre à appliquer la recherche sémantique, par exemple à créer des plongements pour les textes, puis à appliquer la recherche vectorielle en vue de trouver les documents connexes ? Cet article vous explique la procédure étape par étape, y compris la validation de la performance des modèles.
Vous ne savez pas quel type de tâche associer à quel modèle ? Ce tableau devrait vous aider à vous lancer.
Modèle HuggingFace | task-type |
|---|---|
NER | |
text_embedding | |
text_classification | |
zero_shot_classification | |
| Réponse aux questions | question_answering |
Elastic prend aussi en charge la comparaison de la similarité entre deux extraits de texte en tant que type de tâche text_similarity. Cela peut être utile pour classer le texte du document quand vous le comparez à une autre entrée textuelle fournie. Parfois, cette opération est appelée le cross-encodage.
Ressources à consulter pour en savoir plus
- Prise en charge des transformateurs PyTorch, y compris les considérations relatives à la conception pour Eland
- Étapes de chargement des transformateurs dans Elastic et de leur utilisation dans l'inférence
- Article expliquant comment lancer une requête dans vos données propriétaires à l'aide de ChatGPT
- Adaptation d'un transformateur préentraîné à une tâche de classification de textes et chargement d'un modèle personnalisé dans Elastic
- Détection de la langue intégrée vous permettant d'identifier les textes écrits dans une autre langue que l'anglais avant de les transférer dans des modèles prenant uniquement en charge les contenus anglais
Elastic, Elasticsearch et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Partager
Partager sur Twitter
Partager sur LinkedIn
Partager sur Facebook
Partage par e-mail
Imprimer


Comment accéder aux modèles de Machine Learning dans Elastic