Qu'est-ce que l'analyse des causes premières dans le développement de logiciels ?
Définition de l'analyse des causes premières
L'analyse des causes premières est une technique de dépannage éprouvée utilisée par les équipes de développement de logiciels pour identifier et résoudre des problèmes à la base, plutôt que de tenter de traiter les symptômes. L'analyse des causes premières est un processus structuré, étape par étape, conçu pour rechercher les causes primaires sous-jacentes en rassemblant et en analysant les données pertinentes et en testant des solutions qui les traitent.
Pourquoi l'analyse des causes premières est-elle importante ?
L'analyse des causes premières est essentielle dans le développement de logiciels, car l'approche systématique permet aux équipes de dépanner plus efficacement et de développer des solutions à long terme qui évitent que les problèmes ne se reproduisent. En traitant les causes premières des erreurs et des défauts, les développeurs peuvent s'assurer que leurs systèmes sont stables, fiables et efficaces, ce qui réduit les indisponibilités coûteuses et accélère le processus de développement. L'analyse des causes premières aide également les développeurs à hiérarchiser les problèmes selon leur impact et leur sévérité, ce qui leur permet de s'attaquer d'abord aux problèmes les plus critiques.
Comment réaliser une analyse des causes premières
Appliquée en tant que méthode de résolution de problèmes dans tous les secteurs et disciplines (science, ingénierie, fabrication, soins de santé, etc.), l'analyse des causes premières nécessite de suivre une série d'étapes spécifiques pour isoler et comprendre les facteurs fondamentaux contribuant à un défaut ou à une défaillance d'un système. Les étapes pour réaliser une analyse des causes premières dans le développement de logiciels suivent les mêmes principes universels de l'analyse des causes premières :
- 1e étape : Définir le problème et configurer des alertes (si possible)
La première étape de l'analyse des causes premières consiste à définir le problème et à s'assurer qu'il est bien compris. Pour cela, on peut configurer des alertes pour monitorer les problèmes potentiels, tels que le comportement anormal des applications, la dégradation des performances du système ou les incidents de sécurité. - 2e étape : Collecter et analyser des données pour déterminer les facteurs de causalité potentiels
Une fois le problème défini, l'étape suivante consiste à collecter et à analyser les données. Pour cela, on peut examiner les logs système, les indicateurs de performances des applications, les commentaires des utilisateurs et d'autres sources de données pertinentes. L'évaluation des données doit permettre d'établir une liste de facteurs de causalité potentiels qui pourraient contribuer au problème. - 3e étape : Déterminer les causes premières
Une fois l'analyse des données de la 2e étape terminée, utilisez l'une des nombreuses méthodes d'analyse des causes premières pour analyser les données et les facteurs de causalité potentiels afin de découvrir la ou les causes premières réelles du problème. L'analyse des causes premières doit suggérer des mesures correctives. - 4e étape : Implémenter les solutions et documenter les mesures
Une fois la cause première identifiée, la dernière étape consiste à implémenter des solutions pour résoudre le problème. Cela peut inclure des modifications du code, des paramètres de configuration ou un certain nombre d'ajustements du système. Il est important de documenter toutes les mesures prises pour résoudre le problème afin de s'assurer qu'elles sont efficaces et peuvent être répétées si nécessaire.
Méthodes et techniques d'analyse des causes premières en dehors du monde logiciel
De nombreux outils utiles ont été développés pour réaliser une analyse des causes premières efficace. Lors du brainstorming et de l'analyse des causes potentielles, ces méthodes vous permettent de visualiser et d'organiser les informations dans un framework utilisable pour résoudre les problèmes. Voici les techniques populaires d'analyse des causes premières :
- Les 5 pourquoi
Les 5 pourquoi sont une stratégie de résolution de problèmes qui aide à trouver les causes premières en itérant sur les questions "Pourquoi" jusqu'à ce que les causes immédiates d'un problème soient identifiées. Lorsque les équipes demandent "pourquoi" plusieurs fois, chaque question menant logiquement à la suivante, cela encourage la pensée critique et une recherche plus approfondie, ce qui permet d'éviter les solutions superficielles ou de surface. - Diagramme de Pareto
Le diagramme de Pareto se compose d'un diagramme à barres et d'un diagramme linéaire. Il cartographie la fréquence des causes premières les plus courantes du problème, en commençant par la plus probable. Selon le principe de Pareto, qui stipule que 80 % des effets proviennent de 20 % des causes, le diagramme répertorie les causes par ordre d'importance et montre l'impact cumulé de chacune, aidant ainsi les équipes à hiérarchiser les causes qui ont l'impact le plus important sur le problème. - Diagramme de dispersion
Un diagramme de dispersion utilise des points pour aider les équipes à identifier des schémas dans les données qui pourraient contribuer à un problème. Placer deux variables numériques sur un graphe facilite la recherche de toute corrélation entre elles. La technique peut vous aider à identifier rapidement toute relation significative entre des variables et à identifier les aberrations, qui pourraient être les causes potentielles que vous recherchez. - Diagramme en arêtes de poisson
Cet outil visuel, qui ressemble à un squelette de poisson, fournit une représentation graphique des facteurs qui pourraient contribuer à un problème, la tête représentant le problème et les arrêtes les catégories de causes potentielles. Il est particulièrement efficace pour favoriser la collaboration entre les équipes et peut aider à comprendre le problème de façon plus globale. - FMEA (Failure Mode and Effects Analysis, mode de défaillance et analyse des effets)
FMEA est une approche structurée et empirique qui aide à identifier les défaillances potentielles et leurs effets. Il s'agit d'une méthode systématique qui consiste à identifier les modes de défaillance potentielle, à évaluer leur sévérité et à déterminer la probabilité d'occurrence et de détection, puis à les classer en fonction de leur score de risque potentiel. Cela peut aider les équipes à se concentrer sur les problèmes les plus importants à résoudre en premier et également à éviter les problèmes avant qu'ils ne surviennent.
Outils d'analyse des causes premières pour les développeurs de logiciels
Dans le monde logiciel, l'analyse des causes premières peut révéler des problèmes profonds dans le code. Mais l'utilisation de technologies cloud-native et la complexité des applications modernes d'aujourd'hui rendent de plus en plus difficile la détermination de la cause première des problèmes. Les équipes peuvent utiliser des outils d'observabilité et de sécurité pour obtenir de puissants résultats d'analyse des causes premières, par exemple :
Observability
Observability fournit des informations en temps réel sur les performances et le comportement des logiciels grâce à la collecte et à l'analyse de données, ce qui vous permet d'identifier les problèmes et d'avoir une meilleure visibilité sur les causes premières en monitorant les indicateurs, les logs et les traces, et via des outils AIOps et d'observabilité, tels que :
- Machine Learning et AIOps
La recherche, la visualisation et le Machine Learning peuvent aider à identifier les anomalies et à mettre au jour la cause première d'un problème. Ainsi, vous pouvez prendre des décisions éclairées et prendre rapidement des mesures correctives. - Traçage distribué
Le suivi et l'analyse du flux de requêtes via des systèmes distribués complexes avec le traçage distribué donnent des informations sur les interactions entre les composants et les services, ce qui peut aider à identifier les goulots d'étranglement et d'autres problèmes susceptibles de causer des problèmes. - Analyse des schémas de logs
L'analyse des schémas de logs et des tendances générés par les applications et l'infrastructure permet d'identifier la cause première d'un problème. Elle permet également de détecter les anomalies, les erreurs et d'autres problèmes qui pourraient avoir un impact sur les performances des logiciels. - Mapping des dépendances des services
En identifiant les relations et les dépendances entre les différents composants d'un système, vous pouvez automatiquement mapper les dépendances des services susceptibles de causer des problèmes et comprendre l'impact des modifications apportées à un composant sur le reste du système. - Corrélations de latence et d'erreur
En analysant les données liées à la latence et aux taux d'erreur pour identifier les corrélations entre les deux, vous pouvez repérer des schémas et des relations entre les erreurs et les problèmes de performances qui peuvent aider à trouver les causes premières.
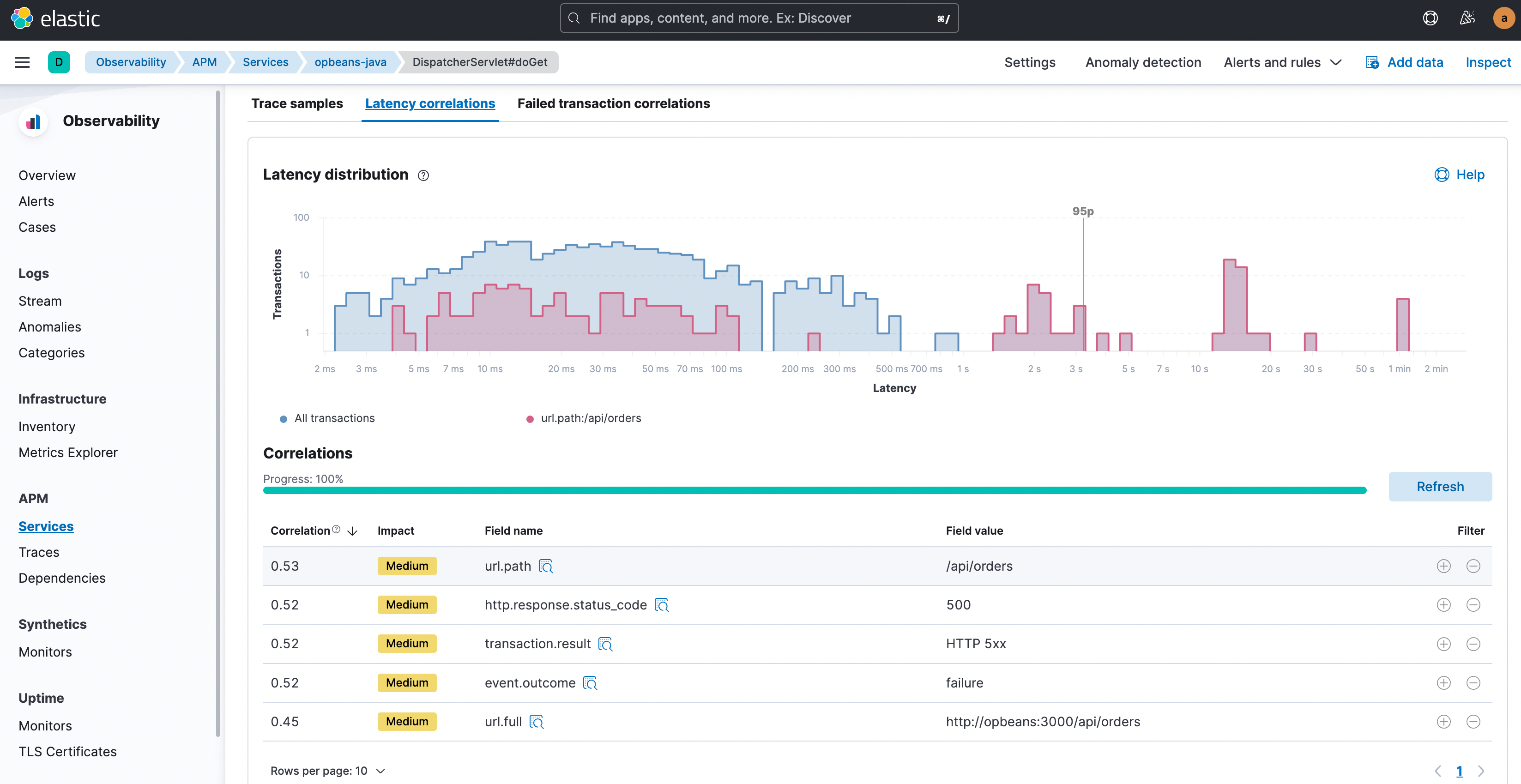
Sécurité
L'analyse des données liées à la sécurité pour identifier les vulnérabilités et les faiblesses du système est un aspect important de l'analyse des causes premières. Cela peut aider à éviter les failles de sécurité et d'autres problèmes qui pourraient avoir un impact sur les performances des logiciels.
- La détection des anomalies non supervisée offre une couche de défense supplémentaire
Une sécurité complète nécessite plusieurs couches de protection contre les menaces. Le Machine Learning non supervisé identifie les écarts par rapport à l'activité normale dans vos données, sans avoir à préciser ce qui est anormal, et peut intercepter les attaques que les approches standard de recherche des menaces sont susceptibles de manquer. - Enquêter sur les menaces et explorer les corrélations
L'analyse des données de sécurité liées aux événements détectés permet de déterminer s'ils représentent des menaces réelles ou s'ils peuvent être ignorés. Les analystes en sécurité reconnaissent les activités malveillantes en examinant les schémas des sessions, les chronologies des événements et les informations de diagnostic des hôtes.
Erreurs courantes à éviter avec l'analyse des causes premières
L'analyse des causes premières peut être très efficace pour identifier et résoudre les problèmes, mais il existe plusieurs erreurs courantes que les équipes doivent connaître :
- Absence de validation des données : ne pas valider les données utilisées dans votre analyse peut conduire à des conclusions erronées et à des solutions inefficaces.
- Choisir des solutions comme causes : des problèmes tels que le manque de formation et de support technique ou les contraintes budgétaires sont rarement la cause première d'un problème. Ce sont bien plus souvent les solutions. Il est essentiel d'explorer plus profondément pour remonter à l'origine d'un problème.
- Besoin de trouver une cause : il peut exister de nombreux facteurs contributifs qui conduisent à un problème, et il est important de tous les identifier, plutôt que de s'arrêter sur un qui est pratique.
- Ne pas impliquer les bonnes personnes : une analyse des causes premières valide et vraiment efficace nécessite la contribution de toutes les parties prenantes concernées, y compris les développeurs de logiciels, les testeurs et les analystes métier.
Avantages de l'analyse des causes premières
Les avantages de l'analyse des causes premières dans le développement de logiciels sont une résolution des problèmes améliorée, des coûts réduits et une plus grande efficacité, ce qui conduit à un meilleur produit et à un client plus satisfait. L'analyse des causes premières est un élément essentiel du développement de logiciels. Elle aide les équipes à identifier les origines des erreurs fondamentales et comment les corriger. L'analyse des causes premières permet également aux équipes d'éviter que les problèmes ne se reproduisent.
- Contribue à éviter que les problèmes ne se reproduisent : l'analyse des causes premières permet aux équipes d'implémenter des solutions qui traitent les causes premières plutôt que les seuls symptômes. En empêchant les problèmes de se reproduire, les équipes peuvent gagner du temps, réduire les coûts et améliorer la qualité globale de leurs logiciels. Par exemple, une équipe logicielle peut remarquer que la fonctionnalité particulière d'une application plante constamment. En effectuant une analyse des causes premières, elle peut découvrir que le problème provient d'un ensemble particulier d'entrées utilisateur qui ne sont pas gérées correctement. Avec ces informations, elle peut implémenter une solution correcte qui met un terme au problème.
- Améliore l'efficacité des processus : en identifiant les causes premières, les équipes peuvent optimiser leurs processus pour éviter que des problèmes similaires ne se produisent, ce qui se traduit par une efficacité accrue, une réduction des indisponibilités et un processus de développement plus rationalisé. Si une équipe de développement constate que son pipeline d'intégration continue échoue à plusieurs reprises en raison de problèmes liés à sa suite de tests, elle peut effectuer une analyse des causes premières pour savoir si le problème vient de tests lents qui entraînent l'expiration du pipeline. Elle peut désormais optimiser sa suite de tests pour éviter des problèmes similaires à l'avenir.
- Évite le mécontentement des clients : l'analyse des causes premières aide les équipes à résoudre les problèmes susceptibles d'avoir un impact sur la satisfaction des clients. Si, par exemple, une équipe reçoit des plaintes d'utilisateurs concernant une fonctionnalité trop lente à charger, elle peut utiliser une analyse des causes premières pour déterminer que le problème est une requête de base de données mal optimisée. En implémentant des solutions pour éviter que ce problème ne se reproduise, comme l'optimisation de la requête pour améliorer les performances, elle peut offrir une expérience utilisateur plus positive. Lorsqu'un logiciel répond systématiquement aux attentes des clients, il contribue grandement à renforcer la confiance et la fidélité, ce qui peut finalement conduire à une augmentation des revenus et à une croissance à long terme.
Conseils pour effectuer une analyse des causes premières
- Extraire des informations de plusieurs sources et comprendre vos données
Lors de l'analyse des causes premières, la qualité, la visibilité et la compréhension des données sont primordiales. Elastic propose une solution qui centralise toutes vos données dans un seul système. Vous visualisez vos données dans Kibana et vous bénéficiez d'outils interactifs qui vous permettent d'approfondir les problèmes d'observabilité et d'enquêter sur les incidents de sécurité. - Travailler avec une équipe pour avoir un regard différent sur les données et le problème
Elastic propose une prise en charge étendue de la collaboration personnalisée dans Kibana et O11y, ce qui vous aide à rationaliser les workflows et à faciliter les remontées avec votre équipe. - Prendre des notes
Elastic propose des alertes rationalisées et la gestion des incidents, ce qui vous permet d'obtenir des informations plus rapidement avec un contexte plus riche pour vos données et visualisations, y compris le sourcing dynamique d'annotations à partir de requêtes Elasticsearch dans Kibana. Pour les annotations basées sur des requêtes, vous avez également la possibilité d'ajouter manuellement des notes à la visualisation Kibana Lens.
Analyse des causes premières avec Elastic
La Elasticsearch Platform et ses solutions intégrées (Elastic Enterprise Search, Elastic Observability et Elastic Security) agissent collectivement comme un moteur à réaction pour faciliter l'analyse des causes premières. Solution la plus largement déployée pour transformer les indicateurs, les logs et les traces en données informatiques exploitables, Elastic Observability vous permet d'unifier l'observabilité sur l'ensemble de votre écosystème numérique. En outre, les analystes ont reconnu Elastic Security comme un leader de l'analyse de la sécurité et du SIEM.
Plus précisément, les fonctionnalités suivantes accélèrent l'analyse des causes premières dans ses différentes phases :
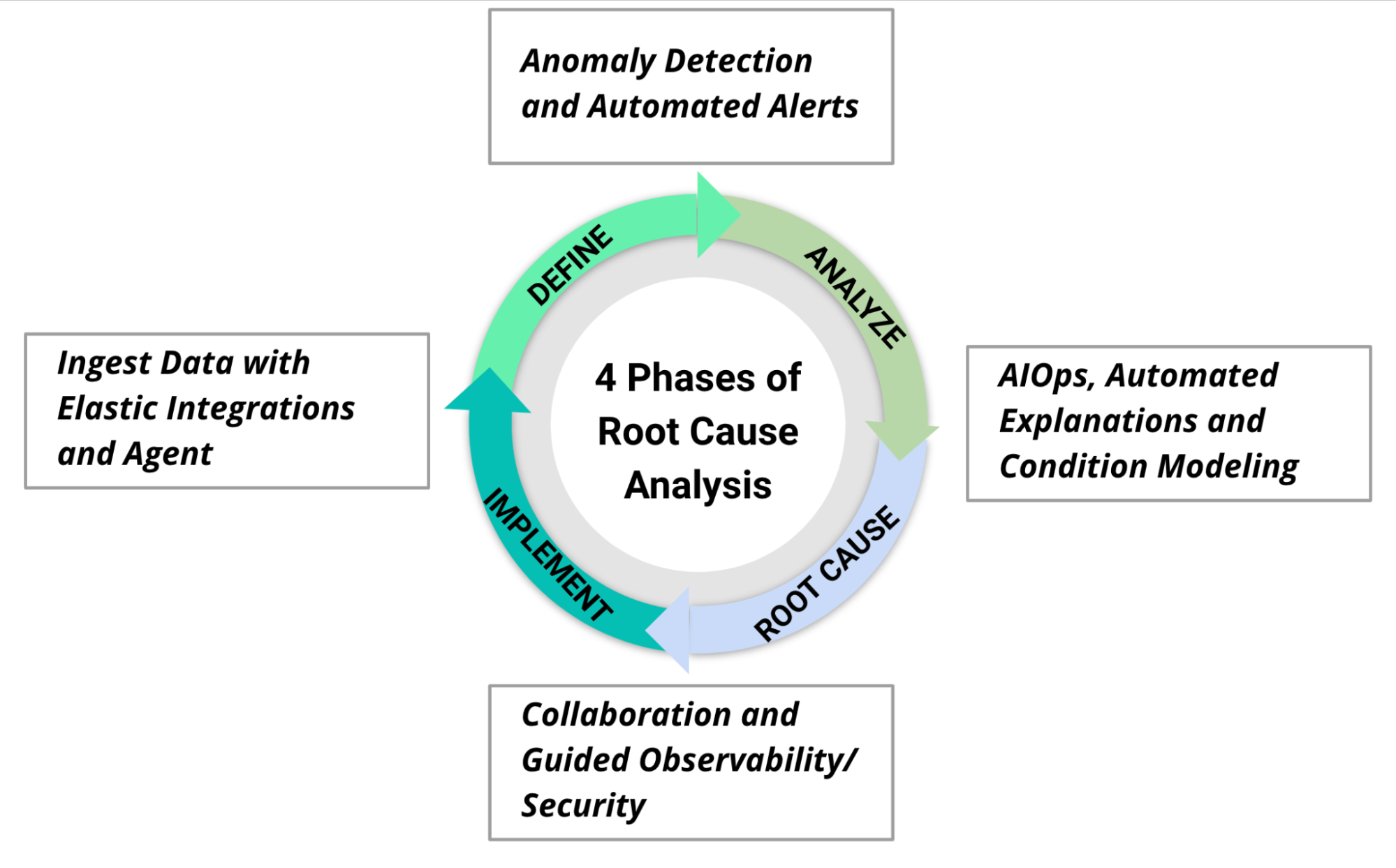
- Ingérez vos données avec Elastic Agent et des centaines d'intégrations.
- Recevez des notifications automatisées de problèmes potentiels à l'aide d'alertes préconfigurées et de la détection des anomalies, ce qui met efficacement votre monitoring sur "pilote automatique".
- Appliquez le Machine Learning et AIOps pour traiter de grands ensembles de données à grande échelle, avec des fonctionnalités interactives conçues sur mesure pour faciliter l'analyse des causes premières pour l'observabilité, y compris les corrélations APM et Expliquer les pics de taux de log, pour les enquêtes de sécurité avec des fonctionnalités telles que Session View, la chronologie des événements, et interroger les hôtes pour obtenir des informations de diagnostic à l'aide de Osquery.
- Déterminez les facteurs de causalité à l'aide de parcours accompagnés et collaborez sur la cause première et les solutions appropriées pour résoudre et éviter les problèmes à l'aide de la gestion des incidents Elastic.
Pour aider votre équipe à tirer le meilleur parti de l'analyse des causes premières, démarrez un essai gratuit et découvrez ce qu'Elastic peut faire pour vous.
Ressources de l'analyse des causes premières
- Analyse des causes premières pour les logs
- Automatisez la détection des anomalies et accélérez l'analyse des causes premières avec AIOps
- Elastic Security for SIEM et analyse de la sécurité
- Elastic Security pour la protection automatique contre les menaces
- Accélérer les enquêtes de sécurité grâce au Machine Learning et à l'analyse des causes premières interactive dans Elastic
- Appliquer Elastic à l'analyse des causes premières dans la fabrication
- Maintenance prédictive dans l'IoT industriel