Le sans état : le nouvel état de la recherche avec Elasticsearch
Simplifiez votre déploiement grâce à l'évolution de l'architecture d'Elasticsearch



Partager sur Twitter


Partager sur LinkedIn


Partager sur Facebook


Partage par e-mail


Imprimer
Notre point de départ
La première version d'Elasticsearch a été publiée en 2010. Il s'agissait d'un moteur de recherche scalable et distribué permettant aux utilisateurs de rapidement rechercher et obtenir des informations critiques. Douze ans et plus de 65 000 validations plus tard, Elasticsearch continue de fournir aux utilisateurs des solutions qui ont fait leurs preuves pour un large éventail de problèmes liés à la recherche. Grâce aux efforts déployés par plus de 1 500 contributeurs, dont des centaines d'employés Elastic à temps plein, Elasticsearch n'a cessé d'évoluer pour répondre aux nouveaux défis qui se posent dans le domaine de la recherche.
Au début de l'existence d'Elasticsearch, lorsque des problèmes de perte de données ont été soulevés, l'équipe Elastic s'est efforcée pendant plusieurs années de réécrire le système de coordination du cluster pour garantir le stockage sécurisé des données reconnues. Lorsqu'il est devenu clair que la gestion des index dans de grands clusters constituait un problème, l'équipe a travaillé sur l'implémentation d'une solution ILM complète pour automatiser ce travail en permettant aux utilisateurs de prédéfinir des modèles d'indexation et des actions lors du cycle de vie. Comme les utilisateurs avaient besoin de stocker des quantités importantes d'indicateurs et de données temporelles, diverses fonctionnalités telles qu'une meilleure compression ont été ajoutées pour réduire la taille des données. Au fur et à mesure que le coût de stockage lié à la recherche de grandes quantités de données cold augmentait, nous avons investi dans la création de snapshots interrogeables permettant de rechercher des données utilisateur directement sur des magasins d'objets peu onéreux.
Ces investissements préparent le terrain pour la prochaine évolution d'Elasticsearch. Avec la croissance des services cloud-native et des nouveaux systèmes d'orchestration, nous avons décidé de faire évoluer Elasticsearch pour améliorer l'expérience d'utilisation des systèmes cloud-native. Ces changements présentent d'après nous des opportunités d'amélioration des opérations, des performances et des coûts lors de l'exécution d'Elasticsearch sur Elastic Cloud.
Prochaines étapes : un futur sans état
L'un des principaux défis rencontrés lors de l'exploitation ou de l'orchestration du service Elasticsearch est qu'il dépend de nombreux éléments ayant un état persistant, ce qui en fait donc un système avec état. Les trois principaux éléments sont le translog, le magasin d'index et les métadonnées de cluster. Cet état signifie que le stockage doit être persistant et qu'il ne peut pas être perdu lors du redémarrage ou du remplacement d'un nœud.
L'architecture Elasticsearch actuelle sur Elastic Cloud doit dupliquer l'indexation sur plusieurs zones de disponibilité pour fournir une redondance en cas de panne. Nous avons l'intention de déplacer la persistance de ces données des disques locaux vers un magasin d'objets, comme AWS S3. En nous appuyant sur des services externes pour stocker ces données, nous supprimerons le besoin de réplication de l'indexation, ce qui réduira considérablement le matériel associé à l'ingestion. Cette architecture offre également des garanties de durabilité très élevées en raison de la manière dont les magasins d'objets cloud tels qu'AWS S3, Google Cloud et Stockage Blob Azure répliquent les données dans différentes zones de disponibilité.
Le déchargement du stockage d'index dans un service externe nous permettra également de réorganiser Elasticsearch en séparant les responsabilités d'indexation et de recherche. Au lieu d'instances principales et de répliques gérant les deux charges de travail, nous aurons un niveau d'indexation et un niveau de recherche. La séparation de ces charges de travail permettra leur scaling indépendant et un meilleur ciblage lors de la sélection de matériel pour les cas d'utilisation concernés. Cela résoudra également un problème de longue date lié aux charges de recherche et d'indexation qui peuvent avoir un impact l'une sur l'autre.
Après une phase de preuve de concept et d'expérimentation qui a duré plusieurs mois, nous sommes convaincus que ces services de magasin d'objets répondent aux exigences que nous avions imaginées pour le stockage d'index et les métadonnées de cluster. Nos tests et évaluations indiquent que ces services de stockage peuvent répondre aux besoins d'indexation élevés des plus grands clusters observés dans Elastic Cloud. De plus, la sauvegarde des données dans le magasin d'objets réduit les coûts d'indexation et permet un ajustement simple des performances de la recherche. Pour réaliser des recherches parmi les données, Elasticsearch utilisera le modèle éprouvé de snapshots interrogeables : dans ce modèle, les données sont conservées en permanence dans le magasin d'objets cloud-native, et les disques locaux sont utilisés comme caches pour les données fréquemment consultées.
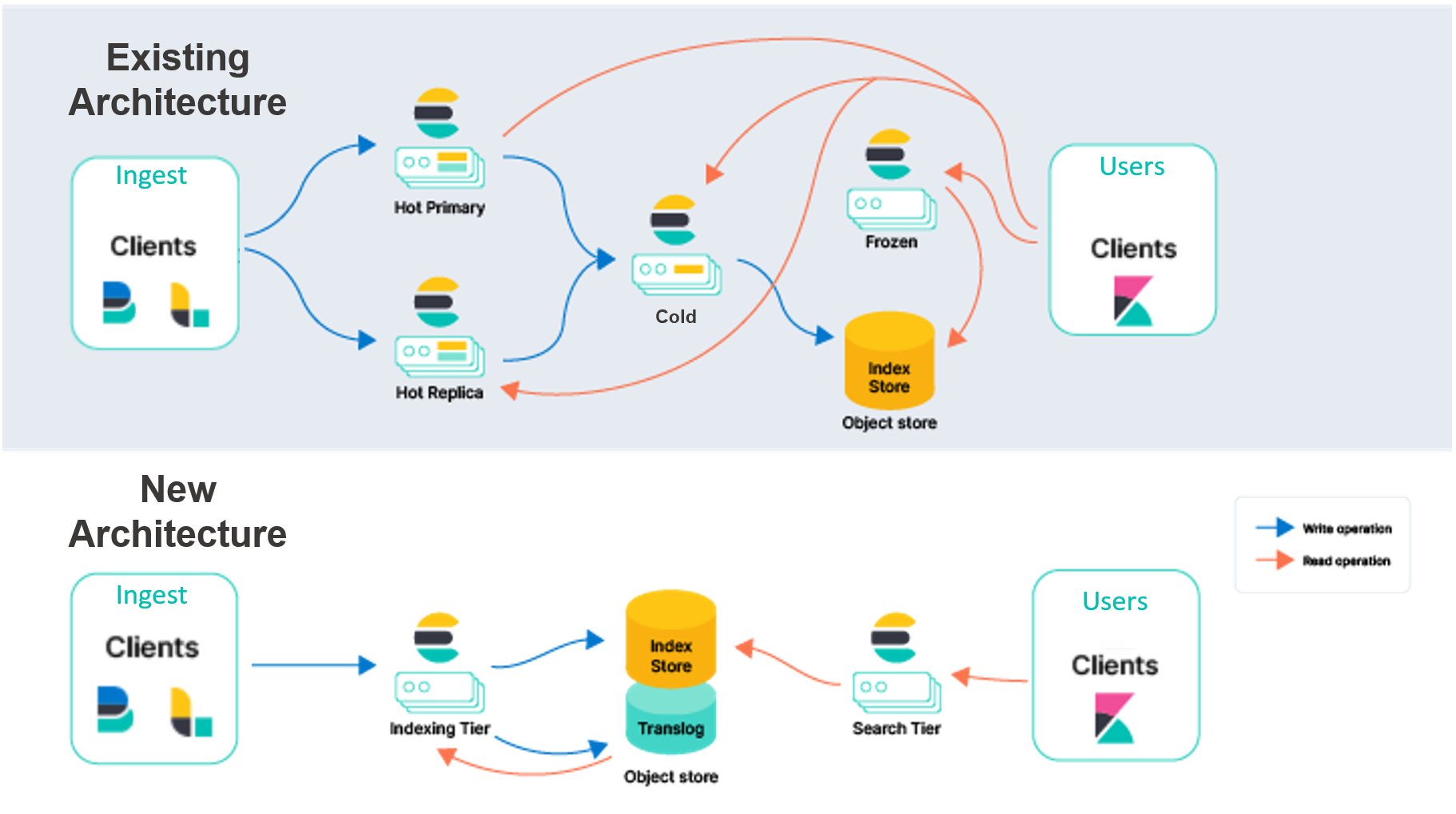
Pour plus de clarté, nous décrivons notre modèle existant comme une réplication « nœud à nœud ». Dans le niveau hot de ce modèle, les partitions primaires et répliquées effectuent le même travail intensif pour gérer l'ingestion et répondre aux demandes de recherche. Ces nœuds sont « avec état », c'est-à-dire qu'ils s'appuient sur leurs disques locaux pour conserver en toute sécurité les données des partitions qu'ils hébergent. De plus, les partitions primaires et répliquées communiquent en permanence pour maintenir la synchronisation. Pour ce faire, elles répliquent les opérations effectuées sur la partition principale vers la partition répliquée. Ainsi, le coût de ces opérations (lié au CPU, principalement) est facturé pour chaque réplique spécifiée. Les partitions et nœuds qui effectuent ce travail pour l'ingestion répondent également aux demandes de recherche, de sorte que le provisionnement et le scaling doivent être effectués en gardant à l'esprit les deux charges de travail.
Au-delà de la recherche et de l'ingestion, les partitions du modèle de réplication nœud à nœud gèrent d'autres responsabilités intensives, telles que la fusion des segments Lucene. Bien que cette conception ait des avantages, nous avons découvert de nombreuses opportunités basées sur ce que nous avons appris des clients au fil des années et sur l'évolution de l'écosystème cloud au sens large.
La nouvelle architecture permet de nombreuses améliorations immédiates et futures. En voici quelques exemples :
- Vous pouvez augmenter considérablement le débit d'ingestion sur le même matériel ou, en d'autres termes, améliorer considérablement l'efficacité pour la même charge de travail d'ingestion. Cette augmentation est possible grâce à la suppression de la duplication des opérations d'indexation pour chaque réplique. Les opérations d'indexation gourmandes en CPU n'ont besoin de se produire qu'une seule fois sur le niveau d'indexation, qui expédie ensuite les segments résultants vers un magasin d'objets. À partir de là, le niveau de recherche peut consommer les données telles quelles.
- Vous pouvez séparer le calcul du stockage pour simplifier la topologie de votre cluster. Aujourd'hui, Elasticsearch dispose de plusieurs niveaux de données (content, hot, warm, cold et frozen) pour mettre en correspondance les données avec le profil matériel. Le niveau hot est dédié à la recherche en temps quasi réel, et le niveau frozen aux données qui font l'objet de moins de recherches. Bien que ces niveaux apportent de la valeur, ils augmentent également la complexité. Dans la nouvelle architecture, les niveaux de données ne seront plus nécessaires, ce qui simplifiera la configuration et le fonctionnement d'Elasticsearch. Nous séparons également l'indexation de la recherche, ce qui réduit encore la complexité et nous permet de faire évoluer les deux charges de travail indépendamment.
- Vous pouvez améliorer les coûts de stockage au niveau de l'indexation en réduisant la quantité de données devant être stockées sur un disque local. Actuellement, Elasticsearch doit stocker une copie complète des partitions sur les nœuds hot (à la fois principaux et répliques) à des fins d'indexation. Avec l'approche sans état de l'indexation directe dans le magasin d'objets, seule une partie de ces données locales est requise. Pour les cas d'utilisation impliquant uniquement des ajouts, seules certaines métadonnées devront être stockées pour l'indexation. Cela réduira considérablement le stockage local requis pour l'indexation.
- Vous pouvez réduire les coûts de stockage associés aux requêtes de recherche. En faisant du modèle de snapshots interrogeables le mode natif de recherche de données, le coût de stockage associé aux requêtes de recherche diminuera considérablement. En fonction des besoins de latence de recherche des utilisateurs, Elasticsearch autorisera des ajustements pour augmenter la mise en cache locale sur les données fréquemment demandées.
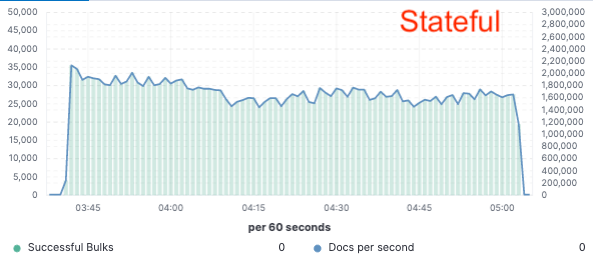
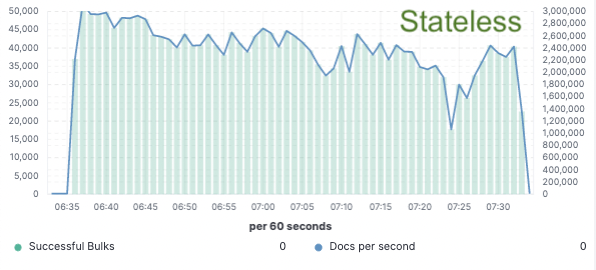
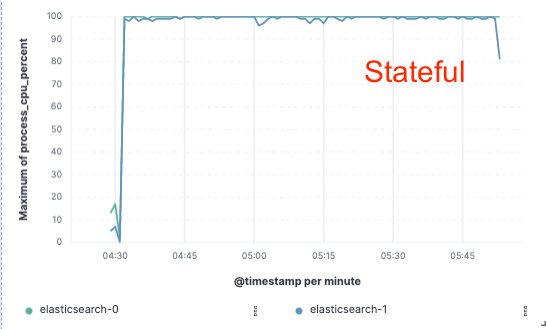
Évaluation comparative : amélioration de 75 % du débit d'indexation
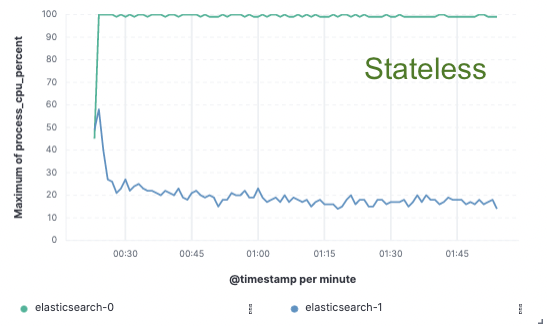
Afin de valider cette approche, nous avons implémenté une preuve de concept étendue dans laquelle les données n'étaient indexées que sur un seul nœud et la réplication était réalisée via des magasins d'objets cloud. Nous avons découvert que nous pouvions obtenir une amélioration de 75 % du débit d'indexation en supprimant la nécessité de dédier du matériel à la réplication de l'indexation. De plus, le coût du CPU associé à la simple extraction des données du magasin d'objets était bien inférieur à celui de l'indexation des données et de leur écriture locale, comme cela est nécessaire pour le niveau hot aujourd'hui. Cela signifie que les nœuds de recherche pourront entièrement dédier leur CPU à la recherche.
Ces tests de performances ont été effectués sur un cluster à deux nœuds afin d'effectuer une comparaison avec les trois principaux fournisseurs de cloud public (AWS, GCP et Azure). Nous avons l'intention de continuer à développer des tests d'évaluation plus larges à mesure que nous poursuivrons une implémentation sans état en production.
Débit de l'indexation
Utilisation du CPU
Une approche « sans état » synonyme d'économies
L'architecture sans état sur Elastic Cloud vous permettra de réduire les frais généraux d'indexation, d'adapter indépendamment l'ingestion et la recherche, de simplifier la gestion du niveau de données et d'accélérer les opérations, telles que le scaling ou la mise à niveau. Il s'agit de la première étape vers une modernisation substantielle de la plateforme Elastic Cloud.
Vous pouvez vous aussi partager notre vision sans état
Vous souhaitez tester cette solution en avant-première ? Contactez-nous sur le forum de discussion ou sur notre canal Slack de la communauté. Nous aimerions recevoir vos commentaires pour nous aider à façonner l'orientation que nous allons donner à notre nouvelle architecture.
Partager
Partager sur Twitter
Partager sur LinkedIn
Partager sur Facebook
Partage par e-mail
Imprimer

