Les snapshots interrogeables, une nouveauté d'Elasticsearch
Nous avons le plaisir de vous annoncer que la version 7.10 comprend la version bêta des snapshots interrogeables. Cette fonctionnalité révolutionne la manière dont vous pouvez utiliser le stockage d'objets de votre choix (comme AWS S3, Microsoft Azure Storage et Google Cloud Storage). Objectif ? Réduire de manière significative vos frais de stockage tout en ingérant et en conservant davantage de données dans la Suite Elastic mais aussi en bénéficiant des remarquables performances de recherche de cette dernière. Certes, nous prenions en charge depuis longtemps la sauvegarde des données dans des stockages d'objets à faible coût. Désormais, ils deviennent une part active du stockage de vos données et des recherches grâce aux snapshots interrogeables.
Les snapshots interrogeables nous aident aussi à soutenir deux nouveaux niveaux de données de qualité supérieure, à savoir le niveau "cold" également fourni avec la version 7.10 et un niveau "frozen" inédit. Depuis longtemps, nous prenons en charge plusieurs niveaux de données pour la gestion du cycle de vie des données, à savoir le niveau "hot" pour les données à grande vitesse et le niveau "warm" pour les performances et coûts réduits. Le nouveau niveau "cold", alimenté par les snapshots interrogeables, peut diminuer vos frais de stockage jusqu'à 50 %, tout en augmentant la densité du stockage local de vos données en lecture seule en reléguant la copie redondante des données à un stockage d'objet à faible coût. Pour aller plus loin, le niveau "frozen", actuellement en développement, stocke toutes les données contenues dans le stockage d'objet à faible coût tout en permettant de continuer à y mener des recherches. En effet, le cache local garantit des recherches rapides dans les données très exploitées. À l'instar de toutes les fonctionnalités que nous développons, des API contrôlent directement la manière dont les snapshots interrogeables chargent les données depuis votre stockage d'objet, les gèrent et mènent des recherches. Grâce à ces nouvelles fonctionnalités, vous pourrez gérer plus facilement, pour un moindre coût, vos volumes croissants de données dans Elastic, satisfaire vos exigences en matière de conservation des données sans augmenter vos frais en la matière et créer des cas d'utilisation. Ainsi, votre équipe pourra disposer d'un historique illimité des investigations de sécurité ou comparer les performances des remises proposées pendant le Black Friday d'une année sur l'autre.
Une histoire à rebondissements
Les données temporelles sont partout, dans les logs, les indicateurs, les traces et les événements de sécurité. Elles constituent la colonne vertébrale des cas d'utilisation de sécurité et d'observabilité, entre autres. Nous nous efforçons en permanence de rendre la gestion et la scalabilité de telles données plus faciles, rapides et rentables dans le temps, des aspects essentiels face à la rapidité de leur croissance. En effet, il faut compter sept téraoctets par semaine, si vous recueillez un téraoctet de données tous les jours, par exemple. Si vous conservez vos données sur plusieurs années, vous vous retrouvez facilement à gérer des pétaoctets de données. Pour gérer leur stockage à la croissance exponentielle, les utilisateurs ont besoin d'une méthode qui leur permet toujours d'y mener des recherches.
Pour résoudre ce problème, nous avons étudié le cycle de vie des données. Dès leur ingestion, les données sont susceptibles d'être soumises à de nombreuses recherches. Par exemple, lors de l'investigation d'un incident, vous avez besoin d'accéder rapidement à toutes les données pertinentes afin d'identifier le problème et de le résoudre. Lorsqu'un utilisateur malveillant compromet un hôte ou une application, l'impact de la défaillance dépend souvent de la vitesse de votre réaction. Toutefois, les données peuvent également être réparties à différents niveaux d'utilisation selon leur source ou leur type. La conservation de certaines données peut être uniquement requise à des fins juridiques ou de conformité ou encore pour alimenter occasionnellement un historique en vue de réaliser des comparaisons. Par conséquent, les utilisateurs doivent bénéficier de différents niveaux de stockage et de puissance de traitement (fondés sur l'âge ou la source des données, entre autres critères) correspondant à leurs besoins variés.
Pour répondre à vos besoins, nous nous efforçons de vous donner les moyens d'équilibrer vos coûts avec les performances et les fonctionnalités de vos systèmes. Dans ce but, nous devons investir à tous les niveaux de notre suite. Or, notre approche est fondée sur les niveaux de données permettant d'en gérer le cycle de vie. Ce concept n'est pas nouveau : nous y réfléchissons depuis les premières versions d'Elasticsearch. La gestion du cycle de vie des index fournit des conventions facilitant la gestion des données dans les nœuds hot (des machines rapides dotées de disques SSD) et warm (des machines à faible coût éventuellement dotées de disques rotatifs), qu'Elastic Cloud prend en charge depuis des années. La gestion du cycle de vie des snapshots facilite davantage l'utilisation des stockages d'objet à faible coût provenant d'AWS, de Google, d'Azure et de fournisseurs de solutions sur site en vue de constituer et de conserver des sauvegardes. Ces snapshots font partie intégrante de nombreux déploiements, au contraire du développement des niveaux de données. Pourquoi ? Tout simplement parce qu'il n'était pas possible de mener des recherches. La situation a évolué grâce aux snapshots interrogeables. Désormais, nous pouvons créer des niveaux de données moins chers qui exploitent ces stockages d'objet à faible coût tout en nous permettant de constituer des sauvegardes.
Les snapshots interrogeables
Nous sommes heureux de vous présenter les snapshots interrogeables, car ils nous permettent d'utiliser S3 et d'autres stockages d'objets de manières totalement inédites. Vous pouvez continuer à utiliser votre stockage d'objets pour vos données sauvegardées en tant que snapshots. De plus, vous pouvez maintenant conserver ce stockage en ligne et disponible en permanence en permettant à Elasticsearch de mener des recherches dans vos snapshots. Pour obtenir ce résultat et vous garantir une bonne expérience, nous avons modifié toutes les couches de nos produits, de Kibana jusqu'à Lucene en passant par Elasticsearch. Grâce à notre grande expertise avec Lucene, nous avons optimisé le mécanisme de recherche afin de récupérer uniquement les sous-ensembles des index de snapshots réellement nécessaires pour répondre à votre recherche ou charger votre tableau de bord. Avec les snapshots interrogeables, il est très facile et rapide de rétablir ou de récupérer des données à partir de vos index fondés sur les snapshots dans S3 ou d'autres stockages d'objet. En outre, nous pouvons développer de nouveaux niveaux de données qui vous apportent une valeur ajoutée pour un prix réduit.
Le niveau "cold"
Le nouveau niveau "cold", disponible dans la version bêta d'Elasticsearch 7.10, vous permet de bénéficier d'une réduction de votre stockage de cluster de 50 % au maximum par rapport au niveau "warm". Il garantit le même niveau de fiabilité et de redondance que vos niveaux "hot" et "warm", tout en prenant en charge la récupération automatique des données lors de toute défaillance matérielle survenant sur l'un de vos nœuds. Ainsi, vous bénéficiez d'une solution bien plus rentable pour trouver les réponses à vos questions sur vos données. Par exemple, vous pouvez comparer un pic d'activité aux données enregistrées le mois précédent ou savoir si un utilisateur s'est connecté à un système dont l'accès est restreint au cours des 6 derniers mois.
Comment est-ce possible ? Dans vos niveaux "hot" et "warm", la moitié de votre disque est utilisé pour stocker des partitions répliquées. Ces copies vous garantissent des recherches rapides, cohérentes et performantes mais aussi la résilience si une machine connaît une défaillance. Dans un tel cas, une réplique prend rapidement le relais en tant que ressource principale. Votre indexation et vos recherches ne sont en rien impactées.
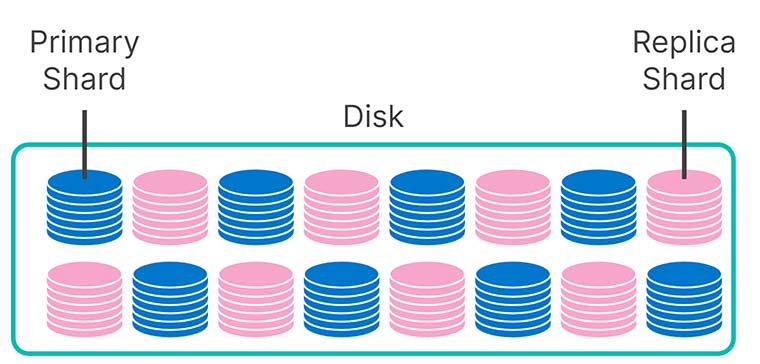
Une fois vos données disponibles en lecture seule, vous pouvez facilement abandonner les copies. Votre référentiel de snapshot est la situation idéale, car il est bien moins cher de stocker des données dans S3 au lieu de disques rotatifs ou SSD locaux. Ainsi, dans le niveau "cold", vos partitions répliquées sont stockées dans S3 en tant que snapshots. Par conséquent, nous avons doublé la capacité d'utilisation de vos nœuds "cold" sans augmentation de prix, avec toutefois un léger impact sur les performances de vos recherches.
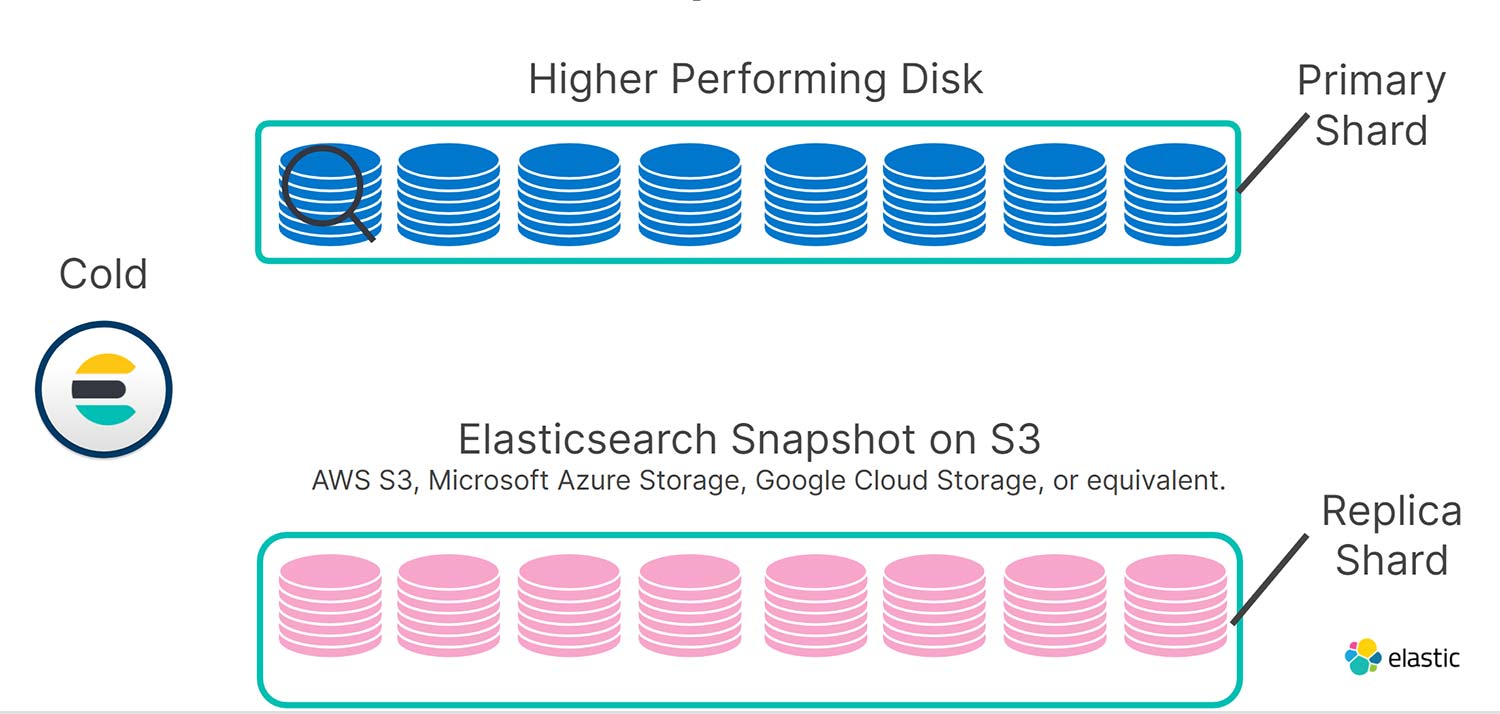
Si une défaillance touche un disque ou un nœud local dans le niveau "cold", nous utilisons les snapshots interrogeables pour récupérer automatiquement les données perdues à l'aide des index répliqués et stockés en tant que snapshots dans S3. Ainsi, ces derniers gèrent les requêtes de recherche en beaucoup moins de temps que la restauration classique d'un snapshot. Voilà comment ça marche !
Le niveau "frozen"
Imaginez si vous bénéficiez d'un historique illimité de vos investigations de sécurité ou si vous pouviez étudier en détail les données brutes d'APM pour observer l'évolution du comportement d'un client au cours des deux dernières années. C'est là que le niveau "frozen" entre en scène ! Il vous fournit de tout nouveaux cas d'utilisation contenant les types et volumes de données qui ne permettaient pas d'utiliser Elasticsearch de manière rentable. Si vous bénéficiez de données dans S3 où vous pouvez mener des recherches, vous obtenez une véritable valeur ajoutée pour atteindre vos objectifs commerciaux. Actuellement en développement, le niveau "frozen" vous permet de mener des recherches directement dans les données stockées dans S3 ou le stockage d'objet de votre choix. Grâce au niveau "frozen", les données seront stockées dans S3 en tant que snapshots, ce qui élimine le recours à des stockages locaux. Et cerise sur le gâteau, il ne sera plus nécessaire d'extraire vos données "frozen" et de les réactiver si vous avez besoin d'y accéder pour un audit ou une investigation de sécurité. Il vous suffit d'utiliser les snapshots interrogeables pour exécuter vos recherches directement.
La solution que nous offrons avec le niveau "frozen" est inégalée : elle permet de mener des recherches dans une quantité quasiment illimitée de données, à la demande, pour un coût approchant celui du stockage de données dans S3. L'ensemble du cycle de vie de vos données est automatisé à travers tous les niveaux ("hot", "warm", "cold" et "frozen"), tout en vous garantissant l'accès et les performances de recherche dont vous avez besoin pour des frais de stockage réduits au minimum.
La garantie d'une expérience utilisateur d'excellence
Nous nous efforçons toujours de vous fournir de nouvelles fonctionnalités innovantes. Pour vous offrir la meilleure expérience utilisateur possible, nous devons également garantir que nos autres solutions sont parfaitement compatibles avec ces nouveautés.
- Configuration simplifiée des niveaux de données : nous avons simplifié et rationalisé la méthode de configuration de vos niveaux de données et la configuration de vos politiques de gestion du cycle de vie des index en ajoutant de nouveaux rôles à attribuer à vos nœuds de données. Ces derniers sont ensuite utilisés par la Suite Elastic pour envoyer automatiquement vos données dans le niveau adéquat dans le cadre de la gestion du cycle de vie des index.
- Recherche asynchrone : nous avons rendu les recherches aussi rapides que possible dans S3. Toutefois, nous ne pouvons pas faire de miracles. Dans S3, quelques millisecondes ne sont pas toujours suffisantes pour traiter les requêtes. Quand c'est le cas, nous voulons vous fournir la meilleure expérience utilisateur possible. Ainsi, nous avons développé une méthode de recherche asynchrone dans Elasticsearch qui améliore de manière significative l'expérience dans Kibana avec les requêtes qui prennent du temps. Désormais, vous pouvez exécuter une requête de recherche en asynchrone sans devoir attendre les résultats. Vous pouvez suivre les avancées de votre requête et en récupérer les résultats ultérieurement. Vous pouvez même récupérer des résultats partiels dès qu'ils sont disponibles, avant même la fin du traitement de la recherche.
- Efficacité des recherches : nous avons apporté plusieurs améliorations afin d'ignorer les index sans aucune correspondance, voire superflus quand vous exécutez une recherche. Par exemple, les index qui ne donneront aucune correspondance sont automatiquement ignorés grâce aux préfiltrage en fonction de la date et l'heure ou d'autres propriétés des données. Le cas échéant, les recherches sont arrêtées de manière anticipée à l'aide de l'algorithme block-max WAND pour la recherche de texte, des requêtes triées répartissant les partitions dans lesquelles nous menons des recherches et des recherches arrêtées lorsque nous avons obtenu suffisamment de correspondances, entre autres.
Chaque amélioration vous apporte une valeur ajoutée. Ensemble, elles vous permettent de bénéficier de bien plus encore. Nous nous efforçons en permanence d'élargir nos horizons quand nous développons des fonctionnalités et en assurant la compatibilité avec celles déjà proposées dans la Suite Elastic.
La résolution pour les cas d'utilisation et nos solutions
Imaginez la valeur ajoutée dont vous pourriez bénéficier en effectuant une recherche simple et économique sur les logs, indicateurs et traces APM collectés depuis des années grâce aux snapshots interrogeables des services de stockage d'objets, comme S3. Dites bonjour à la réhydratation ! Avec les snapshots interrogeables et Elastic Observability, vous pourrez interroger directement des années de données archivées le tout, sans passer par un processus chronophage et coûteux de restauration d'index. C'est qu'on vous gâte !
Et si vous pouviez armer les analystes et les équipes en charge de la détection des menaces d'abondantes sources de données de sécurité conservées sur des services de stockage d'objets comme S3, facilement accessibles grâce aux snapshots interrogeables ? Grâce aux snapshots interrogeables et à Elastic Security, vous pouvez collecter des données de sécurité, comme IDS, NetFlow, DNS, PCAP ou les données aux points de terminaison, à plus grande échelle et les garder à portée de main plus longtemps sur de nouveaux niveaux qui réduisent les coûts et facilitent la recherche.
Enfin, imaginez être en mesure d'effectuer une recherche sur vos contenus d'application et vos enregistrements historiques sans vous ruiner en utilisant des snapshots interrogeables sur les services de stockage d'objets. Les snapshots interrogeables lancés dans la Suite Elastic seront également bien utiles à Elastic Enterprise Search. Que vous preniez en charge des volumes toujours croissants de contenus d'application ou que vous fassiez une recherche sur les enregistrements historiques de votre entreprise stockés en toute sécurité dans des services de stockage d'objets comme S3, vous pouvez conserver l'ensemble des contenus archivés et historiques de manière interrogeable sans vous ruiner.
Une foule de projets en stock
Nous sommes ravis de vous présenter les incroyables avancées réalisées avec la version bêta des snapshots interrogeables et le niveau "cold" dans Elasticsearch 7.10. L'avenir s'annonce tout aussi prometteur : le niveau "frozen" sera bientôt disponible, et tout comme le niveau "cold", le niveau "frozen" sera géré à l'aide de simples curseurs dans Elastic Cloud afin de simplifier les étapes d'inscription et d'abonnement pour les utilisateurs. Nous poursuivons donc notre route, portés par la valeur ajoutée que nous sommes constamment en mesure de vous apporter avec chaque nouvelle version.

Lancez-vous aujourd’hui
Pour commencer à utiliser les snapshots interrogeables et à stocker des données dans le niveau "cold", lancez-vous avec un cluster dans Elasticsearch Service ou installez la dernière version de la Suite Elastic. Vous utilisez déjà Elasticsearch ? Il vous suffit de mettre vos clusters à niveau vers la version 7.10 pour en découvrir les avantages. Si vous souhaitez en savoir plus, vous pouvez lire notre documentation dédiée aux niveaux de données et aux snapshots interrogeables.