Le rôle d'Elastic Observability dans la SRE et la réponse aux incidents
Priorité à la fiabilité des services
En cette ère numérique, les services logiciels sont au cœur des entreprises modernes. Il suffit de regarder les applications qui se trouvent sur votre smartphone. Shopping, services bancaires, streaming, jeux, lecture, messagerie, covoiturage, agenda, recherche... Et la liste est encore longue. La société ne jure que par les services logiciels. Résultat : ce secteur a explosé pour répondre à la demande. Aujourd'hui plus que jamais, une multitude de choix s'offrent à nous pour dépenser notre argent ou détourner notre attention. Pour attirer les clients et les fidéliser, les entreprises mettent la barre haut, car ceux-ci peuvent passer d'un service à l'autre en un claquement de doigts.
De manière générale, nous attendons tous que les services soient fiables. Nous voulons qu'un service, quel qu'il soit, soit rapide et fonctionnel. Sinon, nous le "balayons" pour passer à un autre service qui respecte nos conditions. Par exemple, Amazon a connu une grosse panne en 2018 lors de l'Amazon Prime Day. On a estimé qu'Amazon avait perdu 1,2 million de dollars par minute d'indisponibilité. Mais pas besoin d'être un géant de la technologie pour donner la priorité à la fiabilité des services. Outre la perte de revenus immédiate, l'indisponibilité et la dégradation des performances peuvent nuire à la réputation d'une entreprise sur le long terme. C'est pourquoi les entreprises investissent massivement dans les opérations. En 2018, on estime qu'elles ont dépensé 5,2 milliards de dollars dans les logiciels DevOps.
Dans cet article, nous allons nous pencher sur l'ingénierie de fiabilité des sites, sur le cycle de vie de la réponse aux incidents et sur le rôle d'Elastic Observability dans l'optimisation de la fiabilité. Le contenu s'adresse aux responsables et ingénieurs techniques qui ont pour mission de veiller à ce qu'un service logiciel réponde aux attentes des utilisateurs. Au terme de votre lecture, vous aurez une idée claire de la façon dont les équipes des opérations mettent en œuvre l'ingénierie de fiabilité des sites et la réponse aux incidents, et de la façon dont elles atteignent leurs objectifs à l'aide d'une solution technologique comme Elastic Observability.
La SRE, qu'est-ce que c'est ?
L'ingénierie de fiabilité des sites, ou SRE, est la pratique qui consiste à faire en sorte qu'un service logiciel réponde aux attentes des utilisateurs en matière de performances. En bref, la SRE veille à ce que les services soient fiables. Cette responsabilité date de la même époque que l'avènement du "software as a service". Récemment, les ingénieurs de Google ont inventé le terme "ingénierie de fiabilité des sites" et ont codifié le framework dans ce qui est devenu un livre majeur, Site Reliability Engineering. Cet article reprend des concepts abordés dans le livre.
Les ingénieurs de fiabilité des sites (SRE) sont chargés d'atteindre les objectifs de niveau de service à l'aide d'indicateurs tels que la disponibilité, la latence, la qualité et la saturation. Ces types de variables ont une incidence directe sur l'expérience vécue par l'utilisateur en matière de service. Le cas métier des ingénieurs SRE est donc le suivant : un service satisfaisant génère des revenus et des opérations efficaces permettent de maîtriser les coûts. Pour parvenir à ces fins, les ingénieurs ont souvent deux casquettes : ils gèrent la réponse aux incidents pour protéger la fiabilité des services et ils instituent des solutions et des bonnes pratiques grâce auxquelles les équipes des opérations et de développement peuvent optimiser la fiabilité des services et réduire le coût du travail.
Les ingénieurs SRE expriment souvent l'état attendu pour les services sous forme de SLA, SLO et SLI :
- Accord de niveau de service (SLA) : "Quelles sont les attentes de l'utilisateur ?" Un SLA est une promesse que fait un fournisseur de service à ses utilisateurs par rapport au comportement du service qu'il propose. Certains SLA sont entérinés par contrat : de ce fait, le fournisseur de service est tenu d'indemniser les clients si le SLA n'a pas été respecté. D'autres SLA sont implicites et se basent sur le comportement de l'utilisateur qui a été observé.
- Objectif de niveau de service (SLO) : "Dans quelles situations devons-nous prendre des mesures ?" Un SLO est un seuil interne au-dessus duquel le fournisseur de service prend des mesures afin d'éviter tout non-respect d'un SLA. Par exemple, si le fournisseur de service promet une disponibilité à 99 % dans un SLA, il peut définir un SLO plus strict, par exemple une disponibilité à 99,9 %. Cela lui permettra d'avoir suffisamment de temps pour prendre les mesures nécessaires et éviter le non-respect du SLA.
- Indicateur de niveau de service (SLI) : "Qu'est-ce que nous mesurons ?" Un SLI est un indicateur observable qui décrit l'état d'un SLA ou d'un SLO. Par exemple, si le fournisseur de service promet une disponibilité de 99 % dans un SLA, il peut se servir du pourcentage de requêtes ping réussies au service comme SLI.
Voici quelques-uns des SLI les plus courants surveillés par les ingénieurs SRE :
- La disponibilité mesure le temps de fonctionnement d'un service. Conformément aux attentes des utilisateurs, un service doit répondre aux requêtes envoyées. C'est l'un des indicateurs les plus simples et les plus importants à monitorer.
- La latence mesure les performances d'un service. Pour les utilisateurs, un service doit répondre en temps et en heure aux requêtes envoyées. Selon le type de requête soumise, le temps de réponse attendu varie.
- Les erreurs mesurent la qualité et l'exactitude d'un service. Conformément aux attentes des utilisateurs, un service doit répondre correctement aux requêtes envoyées. Selon le type de requête soumise, l'exactitude de la réponse attendue varie.
- La saturation mesure la consommation de ressources des services. Elle peut indiquer qu'il est nécessaire de scaler les ressources pour répondre aux demandes du service.
Quiconque développe et exécute un service est tenu d'en assurer la fiabilité, même s'il ne s'agit pas d'un ingénieur SRE. En général, cela inclut :
- l'équipe produit qui dirige le service ;
- l'équipe de développement qui conçoit le service ;
- l'équipe des opérations qui gère l'infrastructure ;
- l'équipe de support technique qui fait remonter les incidents rencontrés par les utilisateurs ;
- l'équipe d'astreinte qui résout les incidents.
Les organisations ayant des services complexes peuvent avoir une équipe d'ingénieurs SRE dédiés pour tenir les rênes et assurer l'interface entre les différentes équipes. Dans ce cas, les ingénieurs SRE sont des intermédiaires entre la partie "Dev" et la partie "Ops". Pour terminer, quelle que soit la mise en œuvre, la fiabilité des sites constitue une responsabilité collective dans le cycle DevOps.
La réponse aux incidents, qu'est-ce que c'est ?
Dans le cadre de la SRE, la réponse aux incidents consiste à rétablir un déploiement se trouvant dans un état non souhaité à l'état attendu. Les ingénieurs SRE comprennent les états attendus. C'est pourquoi ce sont souvent eux qui gèrent le cycle de vie de la réponse aux incidents de sorte à maintenir les états attendus. En général, le cycle de vie implique prévention, découverte et résolution, avec l'objectif final d'automatiser le plus de tâches possible. Approfondissons le sujet.
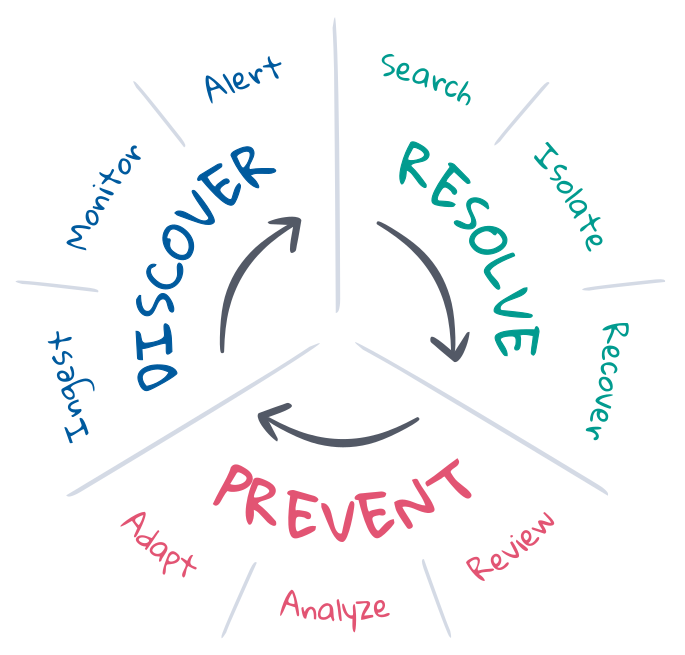
La prévention est la première et la dernière étape de la réponse aux incidents. Dans l'idéal, on évite les incidents en effectuant des tests lors du développement dans le pipeline d'intégration et de livraison continues. Malheureusement, les choses ne se déroulent pas toujours comme prévu en production. Les ingénieurs SRE optimisent la prévention grâce à la planification, l'automatisation et le feedback. Avant qu'un incident se produise, ils définissent les critères de l'état attendu et mettent en place les outils nécessaires pour détecter un état non souhaité et y remédier. Après la survenue d'un incident, ils réalisent une analyse à froid pour étudier ce qui s'est passé et discuter de la marche à suivre pour éviter que cet incident ne se reproduise. Au fil du temps, ils peuvent analyser les KPI et utiliser les informations qui en ressortent pour soumettre des requêtes d'amélioration aux équipes produit, de développement et des opérations.
La découverte consiste à savoir lorsqu'un incident s'est produit et à alerter qui de droit pour y répondre. Il est préférable d'automatiser la découverte pour optimiser la couverture de réponse aux incidents, réduire le temps moyen de détection (MTTD) et protéger les SLO. Pour que l'automatisation soit efficace, les trois éléments suivants sont nécessaires : une observabilité continue sur l'état du déploiement intégral, un monitoring continu de l'état attendu et un alerting immédiat en cas d'état non souhaité. La couverture et la pertinence de la découverte d'un incident dépendent dans une large mesure de la définition de l'état attendu, ce, même si le Machine Learning peut aider à détecter les fluctuations d'un état pouvant indiquer ou expliquer des incidents.
La résolution permet de rétablir un déploiement à l'état attendu. Pour certains incidents, il existe des solutions automatisées. C'est le cas par exemple du scaling automatique des services lorsque la capacité arrive à saturation. Mais de nombreux incidents nécessitent un œil humain, notamment lorsque les symptômes ne sont pas reconnus ou que la cause est inconnue. Pour résoudre ces incidents, il faut donc faire appel aux experts compétents pour analyser la cause profonde, isoler et reproduire le problème pour prescrire une solution, et rétablir le déploiement à l'état attendu. Il s'agit d'un processus itératif qui peut impliquer de nombreux experts, beaucoup de recherches et des échecs de tentatives. Pour que la résolution aboutisse, la recherche et la communication jouent un rôle central. Les informations contribuent à raccourcir les cycles, réduire le temps moyen de résolution (MTTR) et protéger les SLE.
Le rôle d'Elastic dans la SRE et la réponse aux incidents
Avec Elastic Observability, le cycle de vie de réponse aux incidents se place sous le signe de l'observabilité, du monitoring, de l'alerting et de la recherche. Dans cet article, nous allons aborder les avantages que présente Elastic Observability : observabilité continue de l'état du déploiement de la pile, monitoring continu des SLI pour anticiper le non-respect des SLO, envoi automatique d'alertes à l'équipe de réponse aux incidents en cas de non-respect, et expériences de recherche intuitives pour trouver une solution rapidement. Avec tous ces éléments mis bout à bout, la solution réduit le temps moyen de résolution (MTTR) pour protéger la fiabilité des services et conserver la fidélité des clients.
Observabilité et données
Évidemment, on ne peut pas résoudre un problème si on ne peut pas l'observer. Pour pouvoir répondre à un incident, il est nécessaire d'avoir une visibilité sur l'ensemble de la pile du déploiement concerné au fil du temps. Malheureusement, les services distribués restent extrêmement complexes, même pour un événement logique simple, comme on peut le voir ci-dessous. Chaque composant de la pile peut être à l'origine de la dégradation des performances ou de l'échec d'un élément qui se trouve en aval. L'équipe de réponse aux incidents doit prendre en compte l'état de chaque composant lors de la résolution, voire le contrôler et le reproduire. La complexité est le cauchemar de la productivité. Il est impossible de résoudre un incident dans les limites d'un SLA strict à moins d'avoir un emplacement centralisé pour observer l'état de chaque composant au fil du temps.

Pour répondre au problème que pose la complexité, nous avons Elastic Common Schema (ECS). ECS est une spécification de modèle de données open source pour l'observabilité. Elle normalise les conventions de dénomination, les types de données et les relations entre les services distribués modernes et l'architecture. Le schéma présente une vue unifiée de la pile du déploiement au fil du temps à l'aide de données qui étaient jusque-là cloisonnées. Les traces, les indicateurs et les logs de chaque couche de la pile coexistent dans ce schéma unique, pour permettre une expérience de recherche fluide lors de la réponse aux incidents.
Grâce à la normalisation opérée par ECS, il est désormais possible d'assurer l'observabilité avec un minimum d'efforts. Les agents APM et Beats d'Elastic capturent automatiquement les traces, les indicateurs et les logs de vos déploiements. Ils adaptent les données au schéma commun, qu'ils transfèrent ensuite à une plateforme de recherche centralisée afin qu'elles soient examinées. Avec les intégrations aux sources de données populaires, telles que les plateformes cloud, les conteneurs, les systèmes et les frameworks d'application, il est vraiment très simple d'ingérer et de gérer les données au fur et à mesure que vos déploiements se complexifient.
Chaque pile de déploiement est spécifique à son entreprise. C'est pourquoi vous pouvez étendre ECS pour optimiser votre workflow de réponse aux incidents. Les noms de projet des services et de l'infrastructure aident l'équipe de réponse aux incidents à trouver ce qu'elle recherche, ou du moins à savoir ce qu'elle examine. Les ID de "commit" des applications aident les développeurs à trouver l'origine des bugs tels qu'ils existaient dans le système de contrôle des versions au moment de la création. Les "feature flags" fournissent des informations sur l'état des déploiements en version canari ou les résultats des tests A/B. Tout élément qui aide à décrire vos déploiements, exécuter vos workflows ou satisfaire les exigences de votre entreprise peut être intégré dans le schéma.
Monitoring, alerting et actions
Elastic Observability automatise le cycle de vie de réponse aux incidents en monitorant les SLI et les SLO essentiels, en détectant les anomalies et en envoyant des alertes. Pour le monitoring, la solution inclut : Uptime, APM, Metrics et Logs. Uptime monitore la disponibilité en envoyant des Heartbeats externes à des points de terminaison des services. APM monitore la latence et la qualité en mesurant et en capturant les événements directement à partir des applications. Metrics monitore la saturation en mesurant la consommation de ressources de l'infrastructure. Logs monitore l'exactitude en capturant des messages venant des systèmes et des services.
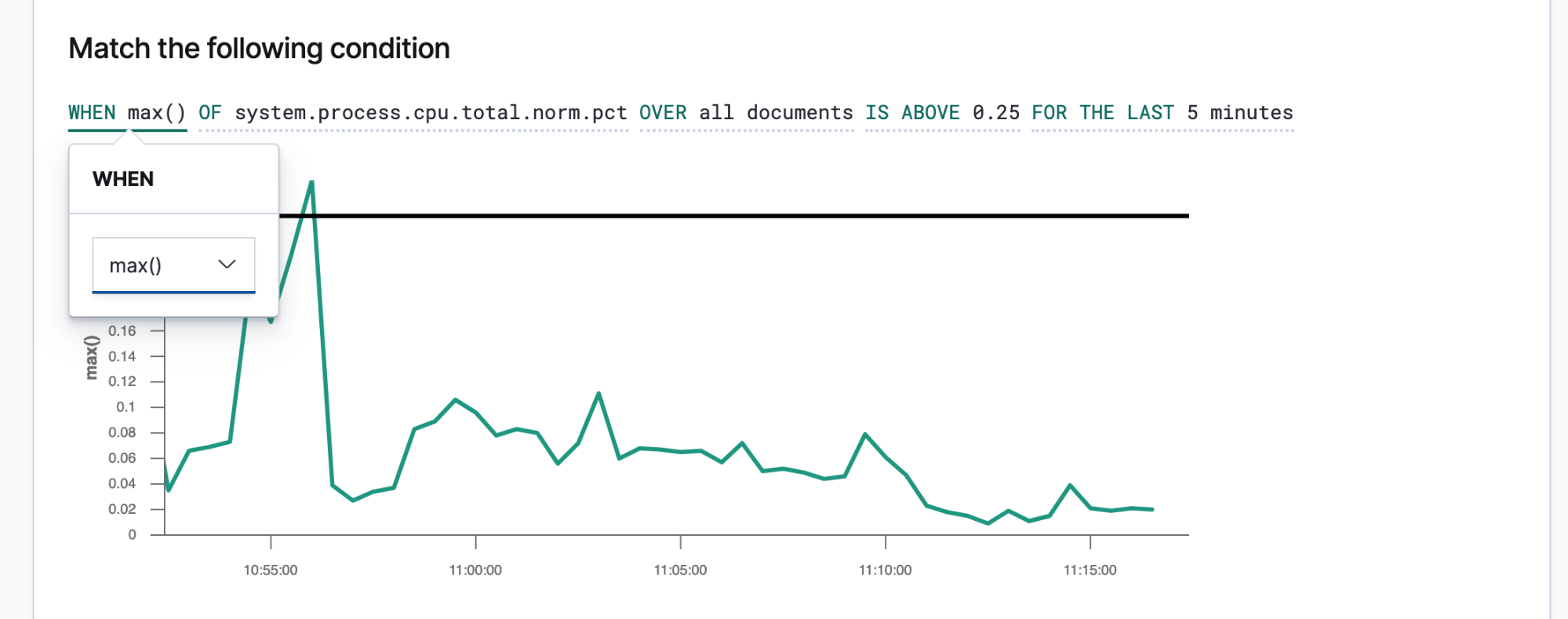
Une fois que vous connaissez vos SLI et vos SLO, vous pouvez les définir en tant qu'alertes et actions afin que les données pertinentes soient communiquées aux bonnes personnes en cas de non-respect d'un SLO. Les alertes Elastic sont des requêtes planifiées qui déclenchent des actions lorsque les résultats remplissent certaines conditions. Ces conditions sont des expressions d'indicateurs (SLI) et de seuils (SLO). Les actions sont des messages envoyés à un ou plusieurs canaux, par exemple un système d'appel ou un système de suivi des incidents, pour signaler le démarrage d'un processus de réponse aux incidents.
Les alertes succinctes et exploitables guideront l'équipe de réponse vers une solution rapide. Celle-ci doit disposer d'informations suffisantes pour reproduire l'état de l'environnement et le problème observé. Vous devriez créer un modèle de message fournissant tous ces détails à l'équipe de réponse. Voici quelques détails que vous pourriez y inclure :
- Titre : "Quel est l'incident rencontré ?"
- Gravité : "Quelle est la priorité de l'incident ?"
- Environnement : "Quel est l'impact de cet incident sur les activités ?"
- État observé : "Qu'est-ce qui s'est passé ?"
- État attendu : "Qu'est-ce qui aurait dû se passer ?"
- Contexte : "Quel était l'état de l'environnement ?" Utilisez les données de l'alerte pour décrire la date/heure, le cloud, le réseau, le système d'exploitation, le conteneur, le processus et d'autres éléments contextuels de l'incident.
- Liens : "Où dois-je continuer ?" Utilisez les données de l'alerte pour créer des liens qui redirigeront l'équipe de réponse vers des tableaux de bord, des rapports d'erreur et d'autres éléments utiles.
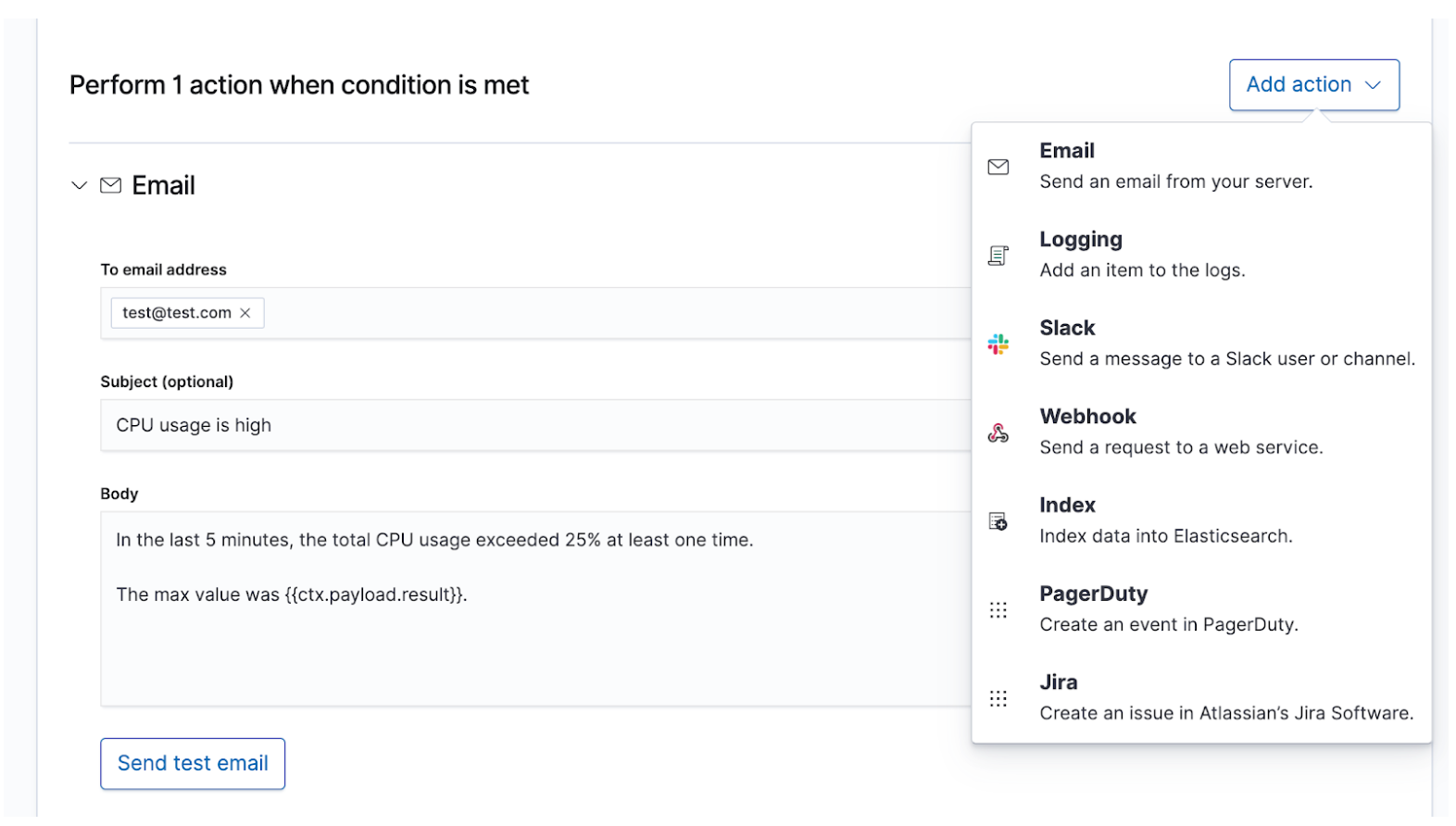
Pour les incidents les plus graves, qui nécessitent une attention humaine immédiate, une alerte doit être émise par le biais de canaux en temps réel tels que PagerDuty ou Slack pour avertir l'équipe d'astreinte de réponse aux incidents. Par exemple, en cas d'indisponibilité d'un service nécessitant une disponibilité d'au moins 99 %. Ce SLA n'autorise au maximum de 15 minutes d'indisponibilité par jour, ce qui est déjà moins que ce dont l'équipe de réponse aux incidents pourrait avoir besoin pour résoudre le problème. Pour les incidents de moindre gravité mais qui nécessitent, à terme, un œil humain, il peut être possible de créer un ticket dans un système de suivi des incidents comme JIRA. Par exemple, une augmentation de la latence ou des taux d'erreur pour des services n'ayant pas un impact direct sur les revenus. Vous pouvez choisir d'alerter plusieurs destinataires à la fois, avec un message approprié pour chacun, dans le but de garder une trace des messages ou de communiquer le plus possible.
Examen et recherche
Que se passe-t-il une fois que l'équipe de service a reçu l'alerte ? Les étapes menant à la résolution varient d'un incident à l'autre, mais certaines choses restent sûres. Des personnes aux compétences et aux expériences différentes travailleront sous pression pour résoudre un problème obscur avec rapidité et précision, tout en gérant un tsunami de données. Elles devront identifier les symptômes signalés, reproduire le problème, analyser la cause profonde, appliquer une solution et voir si cela résout le problème. Elles devront probablement faire plusieurs tentatives. Elles découvriront peut-être qu'elles se sont engouffrées dans un labyrinthe. Pour tous ces efforts, elles auront besoin de caféine de réponses. Pour concrétiser la réponse aux incidents avec une résolution adaptée, il leur faut des informations.
La réponse aux incidents est un problème de recherche. La recherche apporte des réponses rapides et pertinentes aux questions. Une bonne expérience de recherche ne se résume pas à la "barre de recherche". C'est l'interface utilisateur dans son ensemble qui anticipe vos questions et vous guide vers les bonnes réponses. Repensez à votre dernière expérience en matière de shopping en ligne. Lorsque vous parcourez le catalogue, l'application anticipe l'intention de vos clics et effectue une recherche afin de vous présenter les recommandations et les filtres les plus adaptés, ce qui vous incite à dépenser plus, plus rapidement. Vous n'avez pas écrit de requête structurée. Vous ne savez peut-être même pas ce que vous recherchez, et pourtant, vous le trouvez rapidement. Les mêmes principes régissent la réponse aux incidents. La façon dont l'expérience de recherche est conçue a également un impact majeur sur le temps nécessaire à la résolution d'un incident.
La recherche joue un rôle primordial dans la rapidité de la réponse, non pas parce que la technologie est rapide, mais parce que l'expérience est intuitive. Personne n'a à apprendre la syntaxe d'un langage de requête. Personne n'a à référencer un schéma. Personne n'a à être parfait comme une machine. Faites simplement une recherche. Et vous trouverez ce que vous cherchez en quelques secondes. Est-ce que vous recherchiez autre chose ? La recherche peut vous guider. Vous souhaitez faire une recherche par champ ? Commencez à taper dans la barre de recherche : celle-ci vous suggérera des champs. Un pic dans un graphique vous interpelle ? Cliquez dessus. Le reste du tableau de bord s'affichera pour vous présenter ce qui s'est passé lors du pic. La recherche est souple et flexible. Lorsqu'elle est correctement exécutée, elle donne à l'équipe de réponse aux incidents la possibilité d'agir rapidement et avec précision, malgré ses "imperfections" humaines.
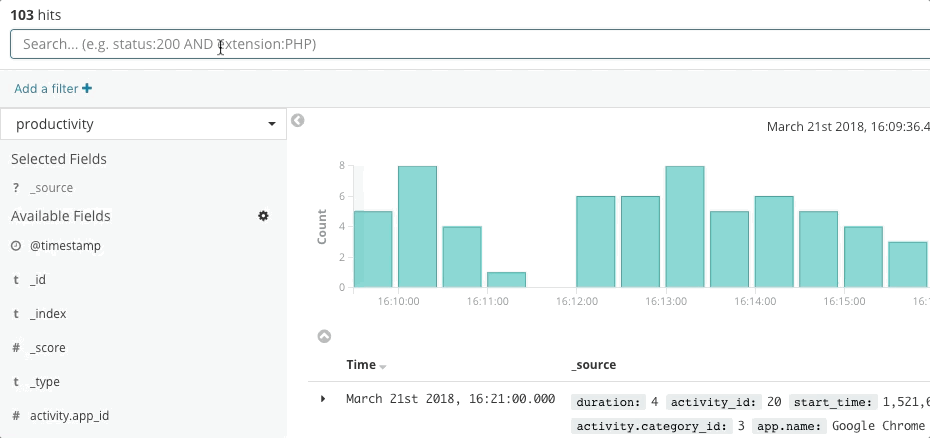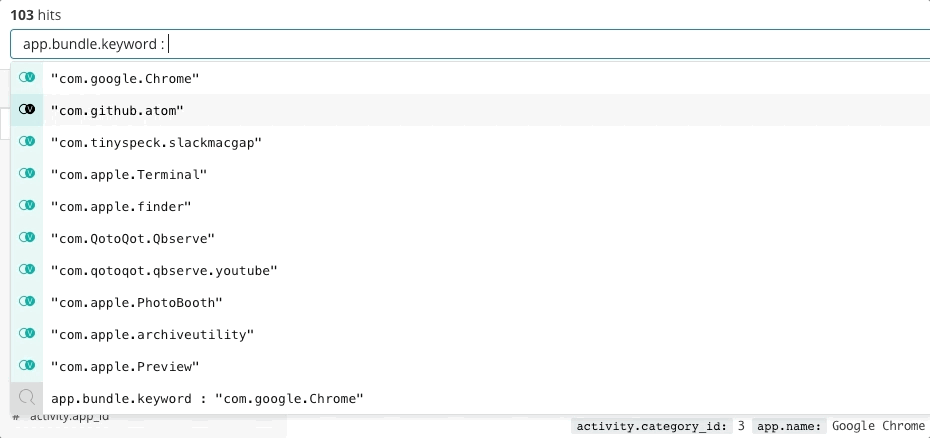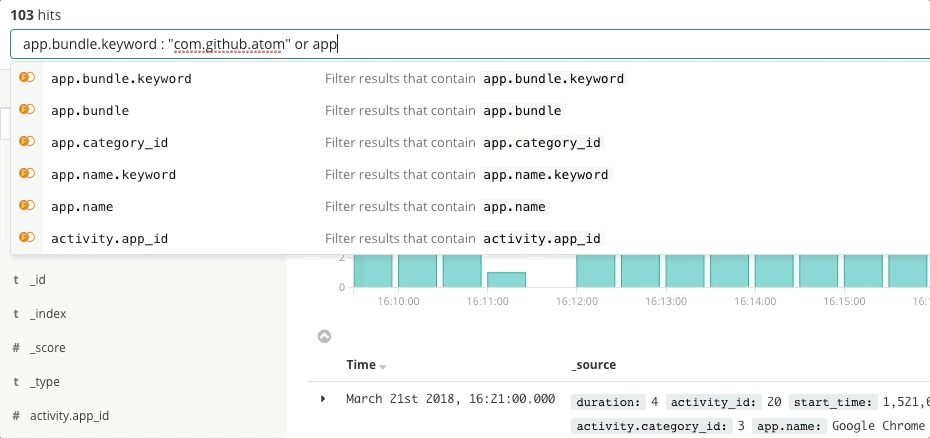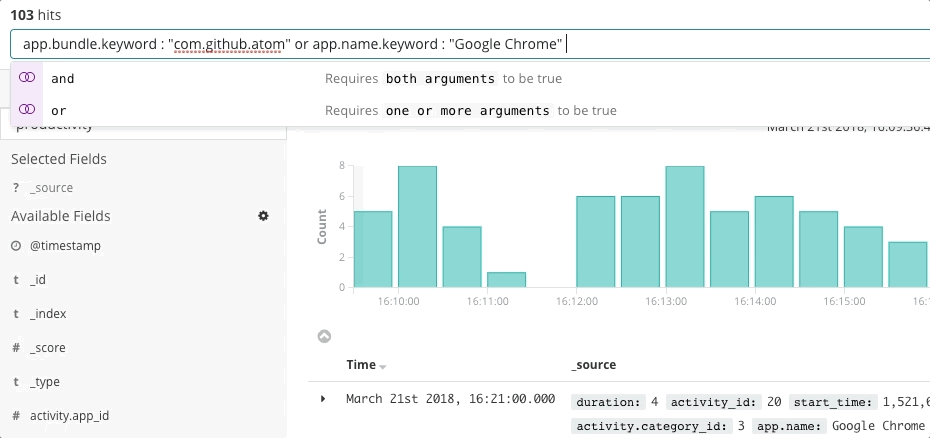
Dans le cadre de la réponse aux incidents, Elastic Observability propose une expérience de recherche qui anticipe les questions, les attentes et les objectifs de l'équipe de réponse aux incidents. La façon dont l'expérience est conçue est similaire pour chaque composante traditionnelle, à savoir Uptime, APM, Metrics et Logs, ce qui permet de guider l'équipe de réponse pendant son parcours afin d'avoir une vue sur l'ensemble de la pile de déploiement. Tout cela est possible car les données en tant que telles existent dans un schéma commun, non cloisonné. Effectivement, la conception répond aux premières questions qui se posent concernant la disponibilité, la latence, les erreurs et la saturation, puis navigue jusqu'à la cause profonde à l'aide d'une expérience adaptée, quelle qu'elle soit.
Pour illustrer cette expérience, étudions quelques exemples.
Elastic Uptime répond aux questions de base concernant la disponibilité. Par exemple : "Quels sont les services en panne ? Quand le service est-il tombé en panne ? L'agent de monitoring de la disponibilité était-il en panne ?". Les alertes concernant les SLO de disponibilité amèneront probablement l'équipe de réponse sur cette page. Après avoir identifié les symptômes d'un service indisponible, l'équipe de réponse peut suivre les liens pour explorer les traces, les indicateurs ou les logs du service touché et de son infrastructure de déploiement au moment de la panne. Pendant que l'équipe effectue sa recherche, le contexte de l'analyse reste filtré sur le service concerné. Ainsi, l'équipe peut approfondir sa recherche pour déterminer la cause profonde de l'indisponibilité de ce service.
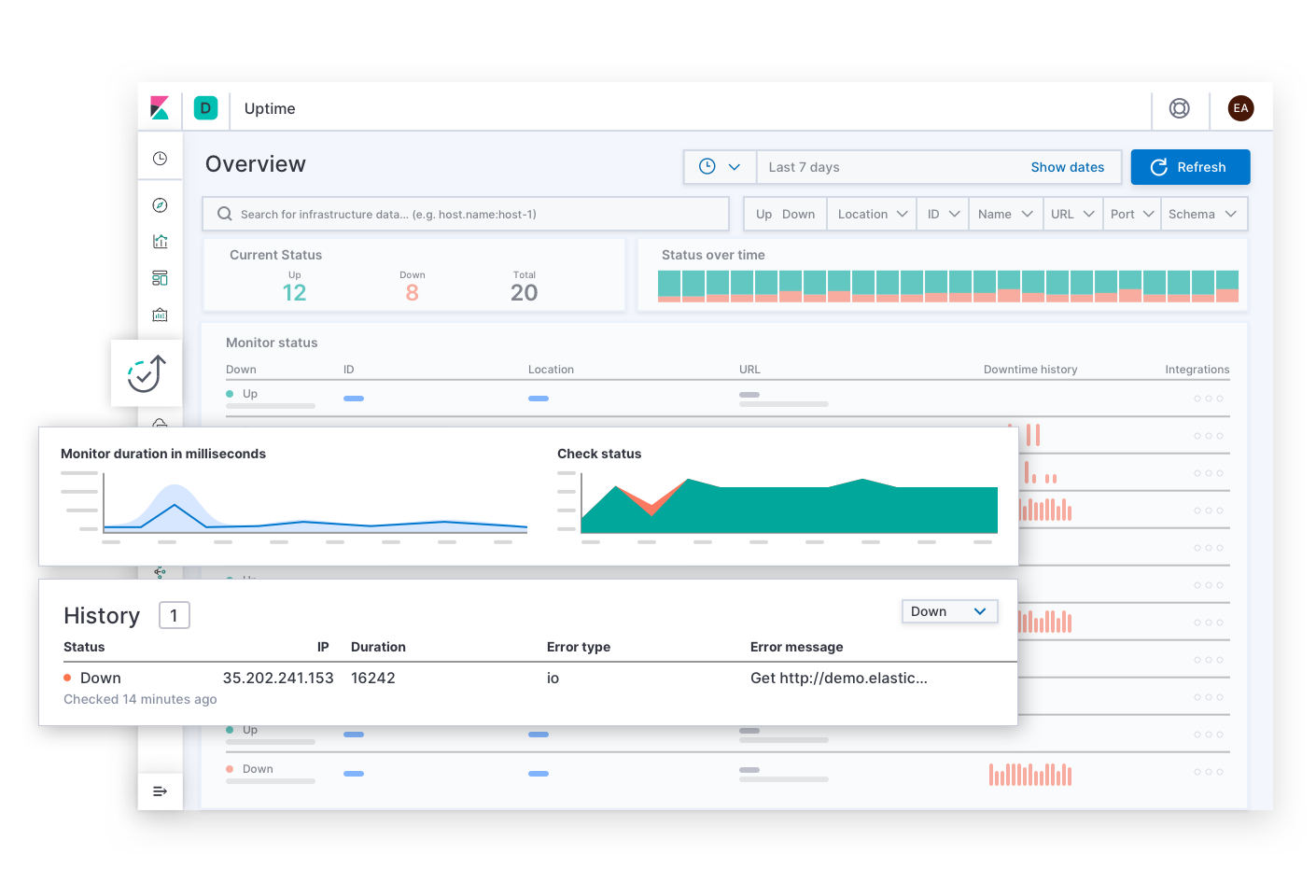
Elastic APM répond aux questions concernant la latence et les erreurs du service. Par exemple : "Quels sont les points de terminaison qui nuisent le plus à l'expérience utilisateur ? Quels sont les intervalles qui ralentissent les transactions ? Comment tracer les transactions des services distribués ? Où se trouvent les éventuelles erreurs dans le code source ? Comment reproduire dans un environnement de développement une erreur rencontrée dans l'environnement de production ?". Les alertes concernant les SLO de latence et d'erreurs amèneront probablement l'équipe de réponse sur cette page. Avec APM, les développeurs d'applications obtiennent les informations dont ils ont besoin pour chercher, reproduire et résoudre des bugs. L'équipe de réponse peut explorer la cause d'une latence en plongeant dans les détails de la pile pour consulter les indicateurs de l'infrastructure de déploiement du service touché.
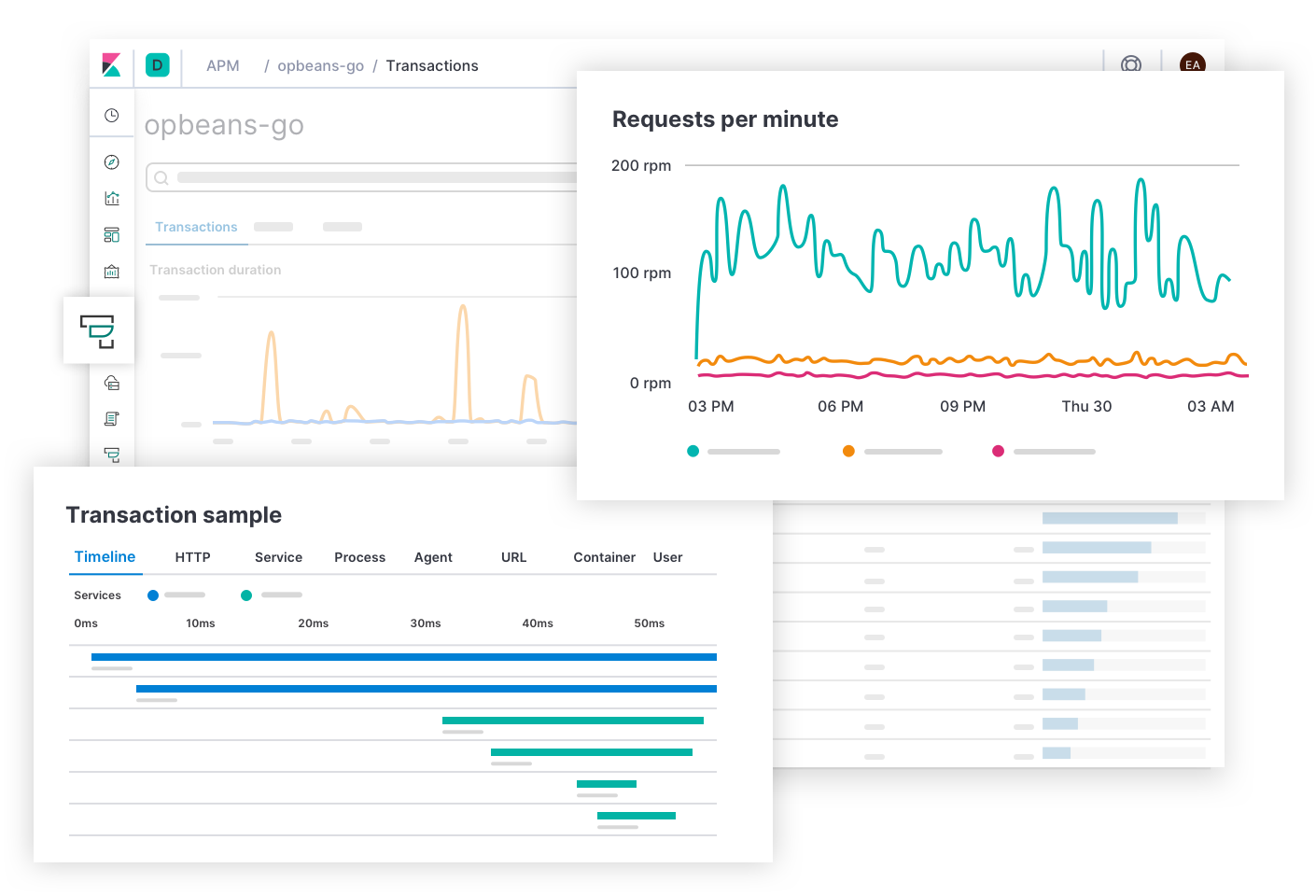
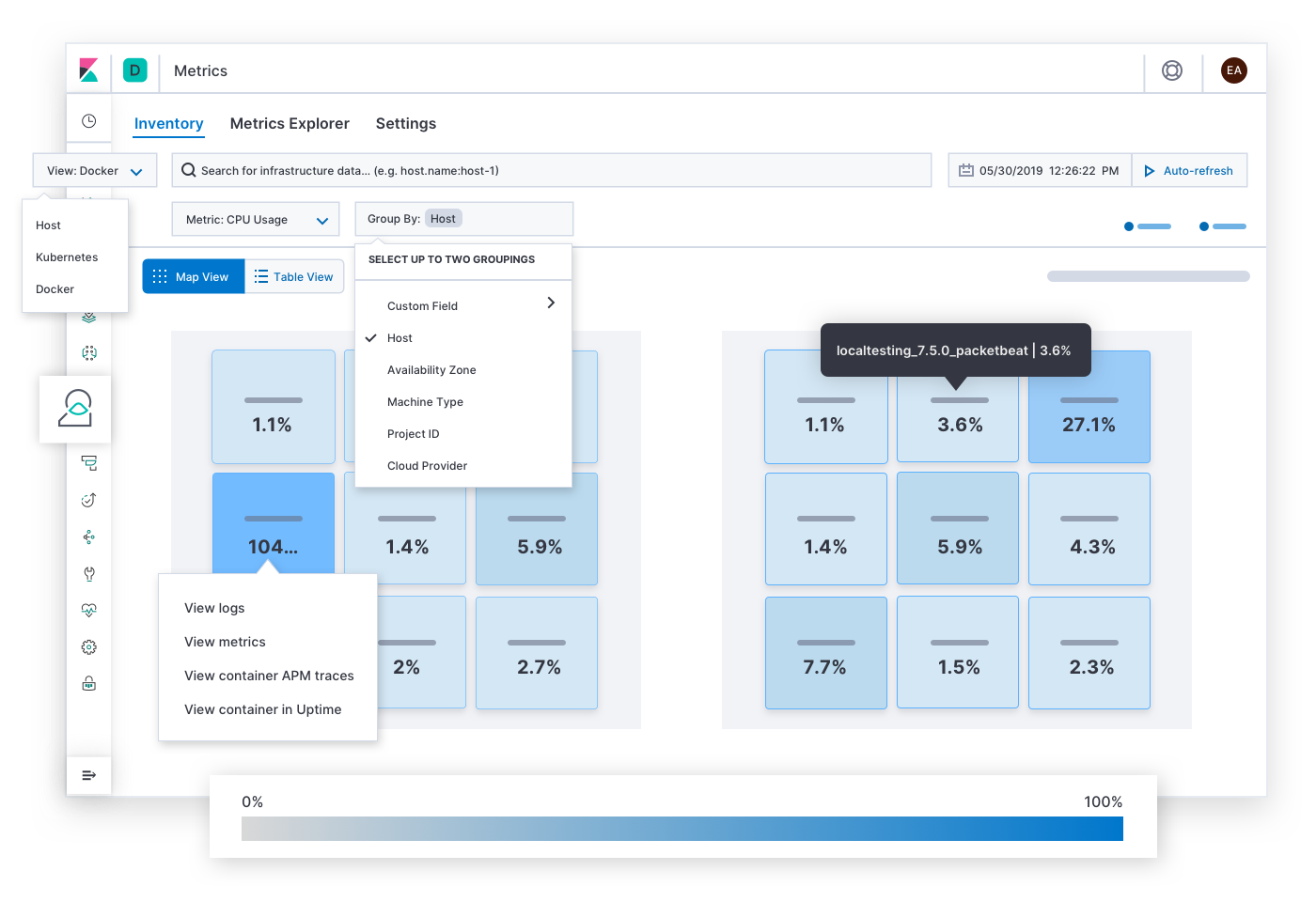
Elastic Metrics répond aux questions concernant la saturation des ressources. Par exemple : "Quels sont les hôtes, pods ou conteneurs qui consomment beaucoup de mémoire ? Peu de mémoire ? Beaucoup de stockage ? Peu de stockage ? Beaucoup de puissance de calcul ? Peu de puissance de calcul ? Beaucoup de trafic réseau ? Peu de trafic réseau ? Que puis-je en déduire si je les regroupe par fournisseur cloud, région géographique, zone de disponibilité ou autre valeur ?". Les alertes concernant les SLO de saturation amèneront probablement l'équipe de réponse sur cette page. Après avoir identifié des symptômes de congestion, des hotspots ou des baisses de tension, l'équipe de réponse peut développer les indicateurs et logs historiques de l'infrastructure touchée ou plonger dans les détails pour déterminer le comportement des services qui s'y exécutent.
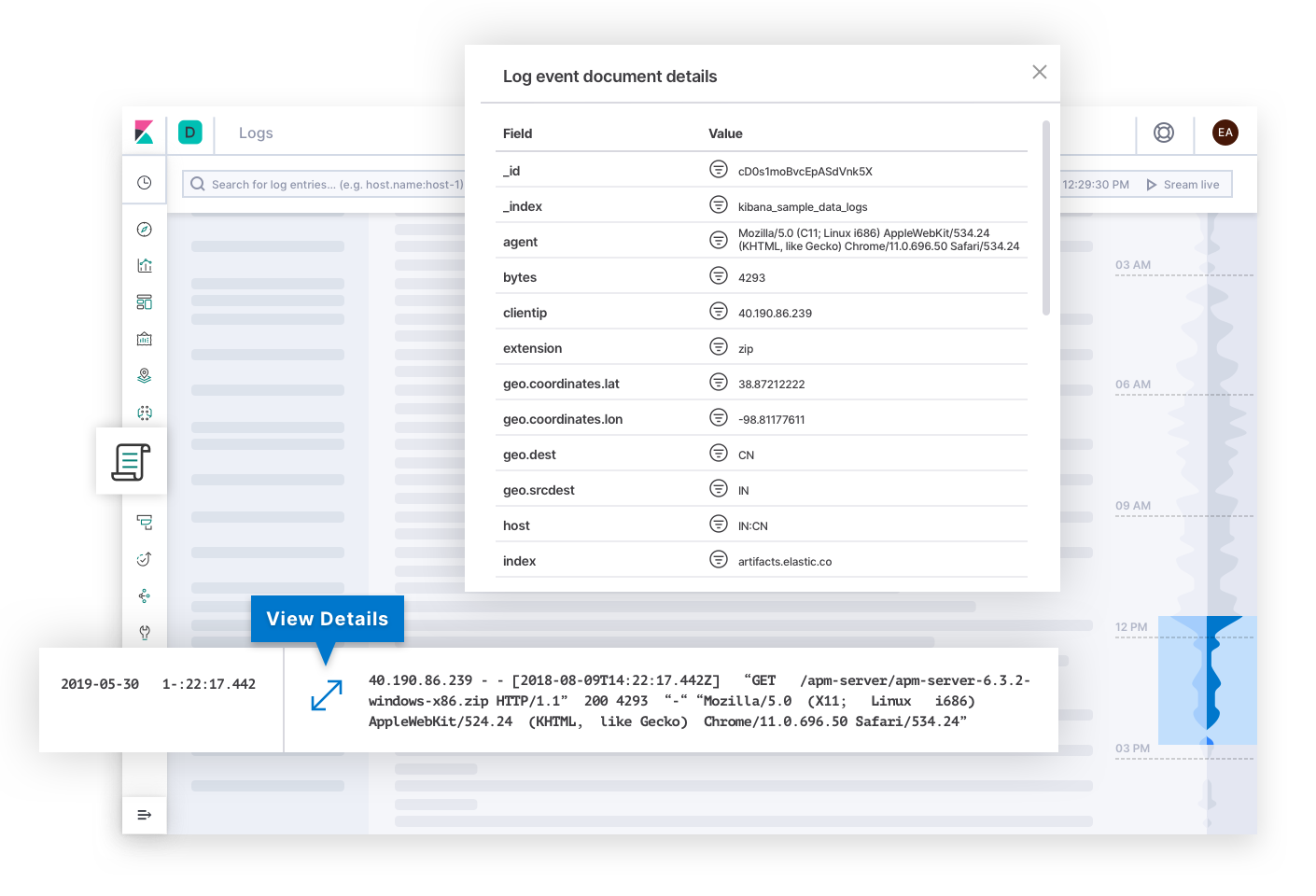
Elastic Logs répond aux questions concernant la source centralisée de vérité des événements émis par différents systèmes et applications. Les alertes concernant les SLO de qualité ou d'exactitude amèneront probablement l'équipe de réponse sur cette page. Les logs peuvent expliquer la cause profonde d'une panne et, de ce fait, mettre un terme à l'analyse. Ou ils peuvent expliquer l'origine d'autres symptômes, qui finiront par conduire l'équipe de réponse jusqu'à la cause profonde. En coulisses, la technologie peut classer les logs par catégorie et révéler des tendances dans le texte pour donner à l'équipe de réponse des indices qui peuvent expliquer les changements d'état d'un déploiement.
Les ingénieurs Elastic ont mis au point une expérience de recherche quasi-universelle en matière d'observabilité grâce aux apports de milliers de clients et de membres de la communauté. Enfin, les ingénieurs SRE sont les experts de leurs propres déploiements. Vous pouvez imaginer une expérience différente, adaptée aux besoins uniques de vos opérations. C'est pour cette raison que vous pouvez créer vos propres tableaux de bord personnalisés et visualisations à l'aide de n'importe quelles données dans Elastic, puis les partager avec tous les utilisateurs appropriés. Comment ? Par simple glisser-déposer.
Au-delà des tâches quotidiennes, Canvas est un moyen créatif d'exprimer des KPI pour les équipes ou au niveau hiérarchique. Voyez-les comme des infographies qui racontent des histoires de l'entreprise, plutôt que comme des tableaux de bord qui résolvent des problèmes techniques. Y a-t-il une meilleure façon de présenter l'expérience utilisateur aujourd'hui qu'une grille de SLO symbolisés par des smileys joyeux et des smileys tristes ? Y a-t-il une meilleure façon d'expliquer le bilan des erreurs restantes aujourd'hui qu'une bannière indiquant "Vous avez 12 minutes pour tester le code en production !" (Plus sérieusement, ne faites pas ça s'il vous plaît !) Lorsque vous connaissez votre public, Canvas vous permet d'illustrer une situation complexe en une histoire percutante à laquelle le public pourra adhérer.

Exemples
Étudions quelques exemples pratiques d'Elastic Observability. Chaque scénario démarre par une alerte concernant un SLI (différent à chaque fois), qui ne peut être résolue que d'une façon spécifique, en impliquant des personnes de différentes équipes. Elastic aide les équipes de réponse aux incidents à régler le problème tambour battant dans différentes circonstances.
Disponibilité : Pourquoi le service est-il en panne ?
Elastic avertit l'équipe d'astreinte après avoir détecté qu'un service nécessitant une disponibilité de 99 % ne répond plus. Dans l'équipe des opérations, c'est Ramesh qui prend la main. Il clique sur un lien pour consulter l'historique de disponibilité. Il vérifie l'intégrité de l'agent de monitoring, afin d'écarter la possibilité que l'alerte soit un faux positif. Il se penche sur le service touché et navigue pour consulter les indicateurs de son hôte, puis il regroupe les indicateurs par hôte et par conteneur. Aucun conteneur de l'hôte ne fournit d'indicateurs. "Le problème doit se situer plus haut dans la pile." Il regroupe les données par zone de disponibilité et par hôte. Dans la zone touchée, d'autres hôtes ont conservé leur intégrité. Mais lorsqu'il applique un filtre sur les hôtes exécutant une réplique du service touché, les hôtes ne renvoient aucun résultat. "Pourquoi les hôtes ne renvoient-ils aucun résultat pour ce service ?" Il partage un lien vers le tableau de bord sur le canal #ops dans Slack. Une ingénieure indique qu'elle a récemment mis à jour le playbook qui configure les hôtes exécutant ce service. Elle annule les changements effectués. Les indicateurs s'affichent de nouveau correctement. L'hémorragie est stoppée. Il leur a fallu 12 minutes pour résoudre le problème. Ils respectent donc le SLA de 99 %. Par la suite, l'ingénieure va passer en revue les logs de l'hôte pour déterminer pourquoi les changements qu'elle a apportés ont entraîné la panne, puis elle appliquera des changements appropriés.
Latence : Pourquoi le service est-il lent ?
Elastic crée un ticket dans le système de suivi des incidents après avoir détecté une latence anormale dans plusieurs services. Les développeurs d'applications organisent une réunion pour vérifier les traces échantillon afin de déterminer les intervalles qui favorisent la latence. Ils constatent qu'il existe une forme de latence pour les services qui communiquent avec un service de validation des données. Sandeep, le développeur qui gère ce service, approfondit l'analyse de ces intervalles. D'après les intervalles, certaines requêtes mettent du temps à s'exécuter dans la base de données, ce qui est corroboré par un taux de logs anormal dans le slowlog. Il contrôle les requêtes et les reproduit dans un environnement local. Il s'avère que les instructions rejoignent des colonnes non indexées. Ce problème était passé inaperçu jusqu'à ce qu'une insertion récente et massive de données provoque le ralentissement. Il optimise le tableau, ce qui permet d'amoindrir la latence du service, mais pas suffisamment pour atteindre le SLO requis. Il décide alors d'orienter son analyse différemment : il compare la trace échantillon à une version précédente du service à l'aide de filtres contextuels. Il constate que de nouveaux intervalles traitent les résultats des requêtes. Il suit la trace de la pile dans son environnement local avec une méthode qui évalue un ensemble d'expressions régulières pour chaque résultat de requête. Il ajuste le code pour précompiler les schémas avant la boucle. Après qu'il a validé ses changements, les services respectent à nouveau leurs SLO en matière de latence. Sandeep marque le problème comme résolu.
Erreurs : Pour le service génère-t-il des erreurs ?
Esther est une développeuse logiciel qui dirige le service d'enregistrement des comptes pour un détaillant en ligne. Elle reçoit une notification du système de suivi des incidents de son équipe. Cette notification indique qu'Elastic a détecté un taux d'erreurs excessif dans le service d'enregistrement de la production de la région de Singapour. Cela pourrait compromettre les nouvelles activités. Elle clique sur un lien dans la description du problème qui la renvoie vers un groupe d'erreurs avec une "erreur de décodage Unicode" non gérée dans le point de terminaison de soumission du formulaire. Elle ouvre un échantillon et trouve des informations sur le "coupable", notamment le nom du fichier, la ligne de code où se trouve l'erreur, la trace de la pile, le contexte relatif à l'environnement, et même le hachage de validation ("commit") du code source au moment où l'application a été créée. Elle consulte les entrées du formulaire d'enregistrement, avec des données adaptées pour se conformer aux réglementations en matière de confidentialité. Elle constate que les entrées contiennent des caractères Unicode vietnamiens. Elle reproduit le problème sur sa machine locale en se servant de toutes les informations recueillies. Après avoir corrigé le gestionnaire Unicode, elle valide ses changements. Le pipeline d'intégration et de livraison continues exécute les tests qu'elle a définis, lesquels aboutissent, puis déploie l'application mise à jour en production. Esther marque le problème comme résolu et retourne à ses tâches quotidiennes.
Saturation : Où la capacité est-elle sur le point d'arriver à saturation ?
Elastic crée un ticket dans le système de suivi des incidents après avoir détecté une anomalie au niveau de l'utilisation de la mémoire, indiquant que la région cloud fait partie des facteurs d'influence. Une opératrice clique sur un lien pour consulter l'utilisation de la mémoire régionale au fil du temps. La région de Berlin affiche un pic soudain, indiqué par un point rouge, après quoi l'utilisation augmente lentement au fil du temps. Elle prévoit que la mémoire va bientôt arriver à saturation si les choses se poursuivent ainsi. Elle consulte les indicateurs récents de mémoire de tous les pods du monde entier. Les pods de Berlin sont clairement les plus saturés par rapport aux autres régions. Elle affine la recherche en regroupant les pods par nom de service et en filtrant sur Berlin. Un service ressort des résultats : le service de recommandation des produits. Elle étend la recherche pour voir les répliques de ce service dans le monde entier. Berlin présente la plus forte utilisation de mémoire et le plus grand nombre de pods de réplique. Elle creuse davantage sur les transactions de ce service à Berlin. Elle envoie un lien vers ce tableau de bord au développeur d'applications qui gère le service. Le développeur étudie le contexte des transactions. Il trouve une étiquette personnalisée d'un "feature flag" qui a été déployé uniquement à Berlin dans le cadre d'un test A/B. Il optimise le service en appliquant un "lazy-loading" à l'ensemble de données qui croît au fil du temps. Le pipeline d'intégration et de livraison continues déploie ce service mis à jour. L'utilisation de mémoire revient à la normale. De fait, l'opératrice marque le problème comme résolu. Rien n'indique que ce problème a affecté l'entreprise. Cependant, d'après les prévisions, ça aurait été le cas à terme si le pic n'avait pas été détecté.
Études de cas
Pour vanter la valeur d'Elastic Observability, ce ne sont pas les témoignages client qui manquent. Un exemple intéressant vient de Verizon Communications, conglomérat américain de télécommunications qui fait partie de l'indice Dow Jones Industrial Average (DJIA). Dans son rapport annuel 2019 à la SEC, Verizon a cité "la qualité, la capacité et la couverture du réseau" et "la qualité du service client" comme faisant partie des plus grands risques concurrentiels pour ses activités. Cette année-là, sur les 130,9 milliards de dollars de son chiffre d'affaires total, 69,3 % étaient issus du segment "sans fil" avec Verizon Wireless. Une équipe d'opérations d'infrastructure de Verizon Wireless a déclaré que, grâce au remplacement de sa solution de monitoring existante par Elastic, elle a pu "réduire son MTTR, qui est passé de 20-30 minutes à 2-3 minutes", ce qui s'est "traduit directement en une qualité de service accrue pour les clients". La fiabilité des services, la réponse aux incidents et la Suite Elastic : voilà trois éléments essentiels pour qu'une entreprise comme celle-ci, qui doit fournir un service fiable (comme tant d'autres), puisse se positionner de manière concurrentielle.
Et ensuite ?
Voici quelques étapes à suivre pour optimiser la fiabilité de vos services logiciels et inspirer confiance :