Características de Elasticsearch
Elasticsearch es un motor de analítica y búsqueda de RESTful distribuido que almacena de forma centralizada tus datos para que puedas buscar, indexar y analizar datos de todas formas y tamaños.
Ingestar y enriquecer
Almacenamiento de datos
Flexibilidad
Buscar y analizar
Búsqueda de texto completo
Administración y operaciones
Administración y operaciones
Escalabilidad y resistencia
Elasticsearch opera en un entorno distribuido diseñado desde cero para una tranquilidad permanente. Nuestros clusters crecen con tus necesidades; solo agrega otro nodo.
Agrupación y alta disponibilidad
Un cluster es una recopilación de uno o más nodos (servidores) que posee en conjunto todos tus datos y brinda capacidades de indexación y búsqueda federadas en todos los nodos. Los clusters de Elasticsearch tienen shards primarios y de réplica para proporcionar conmutación en caso de que deje de funcionar un nodo. Cuando un shard primario deja de funcionar, la réplica toma su lugar.
Obtén información sobre la agrupación y la alta disponibilidadRecuperación automática de nodos
Cuando un nodo sale del cluster por cualquier motivo, intencional o no, el nodo maestro reacciona reemplazando el nodo con una réplica y volviendo a balancear los shards. Estas acciones tienen como objetivo proteger el cluster frente a la pérdida de datos asegurándose de que cada shard se replique por completo lo más pronto posible.
Obtén información sobre la asignación de nodosRebalanceo automático de datos
El nodo maestro en tu cluster de Elasticsearch decidirá automáticamente qué shards asignar a qué nodos, y cuándo mover los shards entre los nodos a fin de rebalancear el cluster.
Obtén información sobre el rebalanceo automático de datosEscalabilidad horizontal
A medida que tu uso aumenta, Elasticsearch escala contigo. Agrega más datos, agrega más casos de uso y, cuando comiences a quedarte sin recursos, simplemente agrega otro nodo a tu cluster para aumentar su capacidad y fiabilidad. Cuando agregas más nodos a un cluster, asigna automáticamente shards de réplica para que estés preparado para el futuro.
Obtén información sobre el escalado horizontalReconocimiento de racks
Puedes usar atributos de nodo personalizados como atributos de reconocimiento a fin de permitir a Elasticsearch tener en cuenta tu configuración física de hardware al asignar los shards. Si Elasticsearch conoce qué nodos se encuentran en el mismo servidor físico, en el mismo rack o en la misma zona, puede distribuir el shard primario y sus shards réplica para minimizar el riesgo de perder todas las copias de shard en caso de falla.
Obtén información sobre el reconocimiento de asignaciónReplicación entre clusters
La característica de replicación entre clusters (CCR) permite la replicación de índices en clusters remotos a un cluster local. Esta funcionalidad puede usarse en casos de uso de producción comunes.
Obtén información sobre CCRRecuperación ante desastres: si un cluster primario falla, un cluster secundario puede funcionar como backup caliente.
Proximidad geográfica: las lecturas pueden hacerse de forma local, lo cual disminuye la latencia de red.
Replicación entre datacenters
La replicación entre datacenters es desde hace tiempo un requisito para las aplicaciones esenciales en Elasticsearch; y previamente se resolvía de forma parcial con tecnologías adicionales. Con la replicación entre clusters en Elasticsearch, no se necesitan tecnologías adicionales para replicar los datos en todos los datacenters, las regiones geográficas o los clusters de Elasticsearch.
Lee sobre la replicación entre datacentersAdministración y operaciones
Gestión
Elasticsearch incluye una variedad de herramientas de administración y API para permitir un control completo sobre los datos, usuarios, operaciones de cluster y más.
Recuperación desde snapshot
Los clusters de Elasticsearch que usan almacenamiento de objetos en el cloud ahora pueden transferir ciertos datos (como replicación de shards y recuperación de shards) desde los nodos ES y el almacenamiento de objetos, en lugar de transferir los datos entre nodos ES, y esto logra reducir los costos de almacenamiento y transferencia de datos.
Obtén información sobre la recuperación desde snapshotGestión del ciclo de vida de los índices
La gestión del ciclo de vida de los índices (ILM) permite al usuario definir y automatizar políticas para controlar por cuánto tiempo debe permanecer un índice en cada una de las cuatro fases y el conjunto de acciones que se deben realizar en el índice durante cada una de ellas. Esto permite un mejor control del costo de operación, dado que los datos pueden colocarse en diferentes niveles de recursos.
Obtén información sobre ILMCaliente: actualización y consultas activas
Tibio: sin actualización, pero consultado
Frío/congelado: sin actualización y consultado esporádicamente (la búsqueda es posible, pero más lenta)
Borrar: ya no se necesita
Niveles de datos
Los niveles de datos son la manera formalizada de dividir los datos en nodos calientes, tibios y fríos a través de un atributo de rol de nodo que define automáticamente la política de gestión de ciclo de vida del índice para tus nodos. Mediante la asignación de roles de nodos caliente, tibio y frío, puedes simplificar y automatizar en gran medida el proceso de mover datos de un almacenamiento con rendimiento y costos más altos a uno con rendimiento y costos más bajo, todo sin comprometer la información.
Obtén información sobre los niveles de datos- Caliente: actualización y búsqueda activas en la instancia con mejor rendimiento
Tibio: datos consultados con menor frecuencia en instancias con menor rendimiento
Frío: solo lectura, consultado esporádicamente, reducción significativa del almacenamiento sin degradación del rendimiento, impulsado por snapshots buscables
Gestión de ciclo de vida de snapshots
Como gestor de snapshots en segundo plano, las API de gestión de ciclo de vida de snapshot (SLM) permiten a los administradores definir la cadencia con la que se toman snapshots de un cluster de Elasticsearch. Con una UI dedicada, SLM empodera a los usuarios para configurar la retención de las políticas de SLM y crear, programar y borrar snapshots automáticamente; lo que garantiza que se realicen backups adecuados de un cluster dado con la frecuencia necesaria para poder realizar una restauración que cumpla con los SLA del cliente.
Obtén información sobre SLMSnapshot y restauración
Un snapshot es un backup que se hace desde un cluster de Elasticsearch en ejecución. Puedes hacer un snapshot de índices individuales o del cluster completo y almacenar el snapshot en un repositorio en un sistema de archivos compartidos. Hay disponibles plugins que también admiten repositorios remotos.
Obtén información sobre snapshot y restauraciónSnapshots buscables
Los snapshots buscables te brindan la capacidad de buscar directamente en tus snapshots y en una fracción del tiempo que llevaría completar una restauración desde snapshot típica. Esto se logra leyendo solo las piezas necesarias de cada índice de snapshots para completar la solicitud. Junto con el nivel frío, los snapshots buscables pueden reducir significativamente los costos de almacenamiento de datos mediante un backup de tus shards de réplica en sistemas de almacenamiento basados en objetos, como Amazon S3, Azure Storage o Google Cloud Storage, y aún proporcionar acceso de búsqueda total a ellos.
Obtén información sobre los snapshots buscablesData rollups
Tener al alcance los datos históricos para análisis es sumamente útil, pero suele evitarse debido al costo financiero de archivar grandes cantidades de datos. Los períodos de retención quedan entonces regidos por las realidades financieras y no por la utilidad que presenta contar con una gran cantidad de datos históricos. La característica rollup brinda una manera de resumir y almacenar datos históricos para que puedan usarse en análisis, pero a una fracción del costo de almacenamiento de los datos sin procesar.
Obtén información sobre los rollups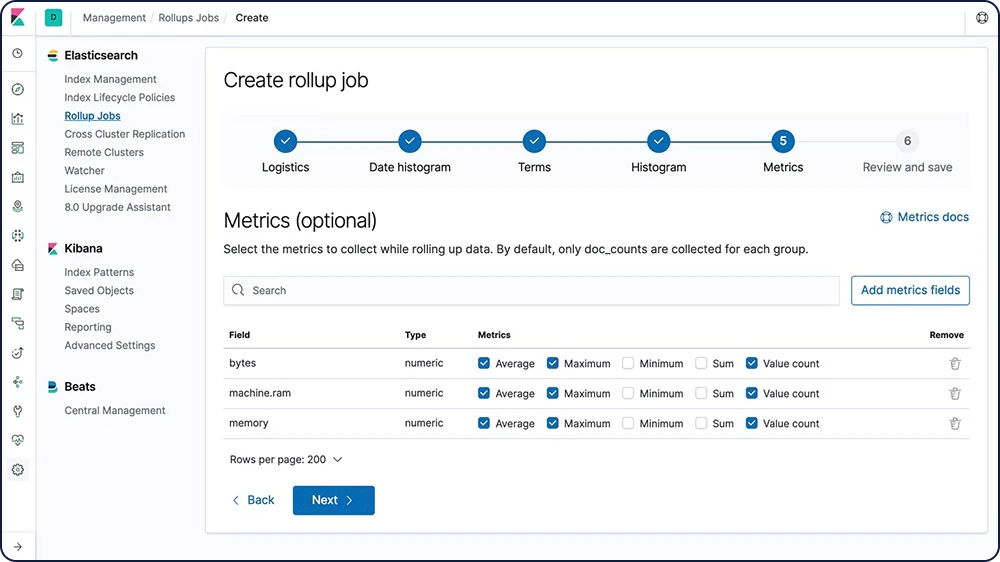
Flujos de datos
Los flujos de datos son una forma conveniente y escalable de ingestar, buscar y gestionar datos de series temporales generados continuamente.
Conoce más sobre los flujos de datosTransformaciones
Las transformaciones son estructuras de datos tabulares de dos dimensiones que permiten una mejor digestión de los datos indexados. Las transformaciones realizan agregaciones que reorganizan los datos en un nuevo índice centrado en la entidad. Al transformar y resumir los datos, es posible visualizarlos y analizarlos de maneras alternativas, incluso como una fuente para otras analíticas de machine learning.
Obtén información sobre las transformacionesAPI de asistente de actualización
La API de asistente de actualización te permite controlar el estado de la actualización de tu cluster de Elasticsearch y volver a indexar los índices que se crearon en la versión principal anterior. El asistente te ayuda a prepararte para la próxima versión principal de Elasticsearch.
Obtén información sobre la API de asistente de actualizaciónGestión de claves de API
La gestión de claves de API debe ser lo suficientemente flexible para permitir a los usuarios gestionar sus propias clave, lo cual limita el acceso a sus roles respectivos. A través de una UI dedicada, los usuarios pueden crear claves de API y usarlas para brindar credenciales a largo plazo mientras interactúan con Elasticsearch, lo que es habitual con scripts automatizados o integración de flujos de trabajo en otro software.
Obtén información sobre la gestión de claves de APIAdministración y operaciones
Seguridad
Las características de seguridad del Elastic Stack dan el acceso adecuado a las personas correctas. Los equipos de IT, operaciones y aplicaciones confían en ellas para administrar usuarios bien intencionados y mantener alejados a los actores maliciosos, mientras los ejecutivos y clientes pueden estar tranquilos sabiendo que los datos almacenados en el Elastic Stack están seguros.
Configuración segura de Elasticsearch
Algunas configuraciones son confidenciales, y confiar en los permisos del sistema de archivos para proteger sus valores no es suficiente. Para este caso de uso, Elasticsearch proporciona un almacén de claves para evitar el acceso no deseado a configuraciones de cluster confidenciales. El almacén de claves puede protegerse de manera opcional con contraseña para seguridad adicional.
Obtén más información sobre la configuración seguraComunicaciones encriptadas
Los ataques basados en la red en datos de nodos de Elasticsearch pueden desbaratarse a través de la encriptación de tráfico con SSL/TLS, certificados de autenticación de nodos y más.
Obtén información sobre la encriptación de comunicacionesSoporte de encryption at rest
Si bien el Elastic Stack no implementa encryption at rest de fábrica, se recomienda que la encriptación a nivel del disco se configure en todas las máquinas host. Además, los snapshot targets también deben asegurar que los datos se encripten en reposo.
Control de acceso basado en roles (RBAC)
El control de acceso basado en roles (RBAC) te permite autorizar a los usuarios mediante la asignación de privilegios a los roles y la asignación de los roles a los usuarios o grupos.
Obtén información sobre RBAC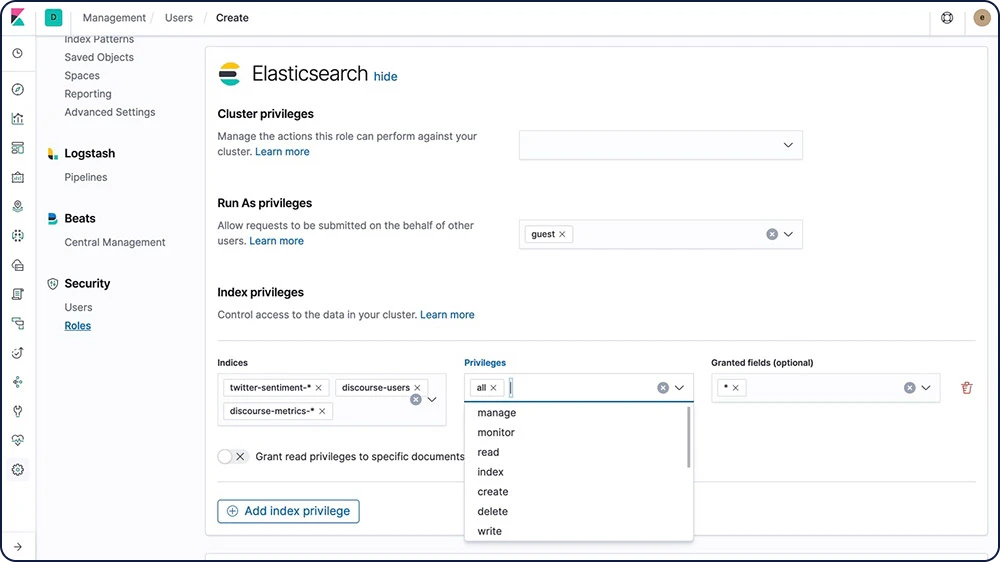
Control de acceso basado en atributos (ABAC)
Las características de seguridad del Elastic Stack también proporcionan un mecanismo de control de acceso basado en atributos (ABAC), que te permite usar atributos para restringir el acceso a los documentos en búsquedas y agregaciones. Esto te permite implementar una política de acceso en una definición de rol para que los usuarios puedan leer un documento específico solo si tienen todos los atributos necesarios.
Obtén información sobre ABACSeguridad a nivel de campo y documento
La seguridad a nivel de campo restringe los campos que los usuarios pueden leer. En particular, restringe a qué campos se puede acceder desde las API de lectura basadas en documentos.
Obtén información sobre la seguridad a nivel de campoLa seguridad a nivel de documento restringe los documentos que los usuarios pueden leer. En particular, restringe a qué documentos se puede acceder desde las API de lectura basadas en documentos.
Obtén información sobre la seguridad a nivel de campo y documentoLogs de auditoría
Puedes habilitar la auditoría para hacer un seguimiento de los eventos relacionados con la seguridad, como errores de autenticación y conexiones rechazadas. Registrar estos eventos en logs te permite monitorear el cluster en busca de actividad sospechosa y proporciona evidencia en caso de un ataque.
Obtén información sobre los logs de auditoríaFiltrado IP
Puedes aplicar el filtrado IP a los clientes de aplicación, clientes de nodo o clientes de transporte, además de otros nodos que intentan unirse al cluster. Si la dirección IP de un nodo se encuentra en la lista negra, las características de seguridad de Elasticsearch permiten la conexión a Elasticsearch, pero se interrumpe inmediatamente y no se procesan las solicitudes.
Rango o dirección IP
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Whitelist
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Nombre de host
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Obtén información sobre filtrado IP
Realms de seguridad
Las características de seguridad del Elastic Stack autentican usuarios mediante el uso de realms y uno o más servicios de autenticación basados en tokens. Se usa un realm para resolver y autenticar usuarios según los tokens de autenticación. Las características de seguridad proporcionan varios realms integrados.
Obtén información sobre los realms de seguridadInicio de sesión único (SSO)
El Elastic Stack cuenta con soporte de inicio de sesión único (SSO) de SAML en Kibana, y usa Elasticsearch como un servicio de backend. La autenticación SAML permite a los usuarios iniciar sesión en Kibana con un proveedor de identidad externo, como Okta o Auth0.
Obtén información sobre SSOIntegración de seguridad de terceros
Si usas un sistemas de autenticación para el cual las características de seguridad del Elastic Stack no cuenten con soporte de fábrica, puedes crear un realm personalizado para autenticar a los usuarios.
Obtén información sobre la seguridad de tercerosAdministración y operaciones
Alertas
Nuestras características de alerta del Elastic Stack te brindan todo el poder del lenguaje de búsqueda de Elasticsearch para identificar los cambios en tus datos que sean de tu interés. En otras palabras, si puedes buscar algo en Elasticsearch, puedes recibir alertas al respecto.
Alertas escalables de alta disponibilidad
Hay un motivo por el cual las organizaciones grandes y pequeñas confían en el Elastic Stack para que maneje sus necesidades de alertas. Mediante la ingesta de datos de forma confiable y segura desde cualquier fuente y en cualquier formato, los analistas pueden buscar, analizar y visualizar datos claves en tiempo real, todo con alertas confiables personalizadas.
Obtén información sobre alertasNotificaciones por correo electrónico, webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters
Vincula las alertas con integraciones incorporadas para correo electrónico, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters y Slack. Integra con cualquier otro sistema de terceros a través de una salida de webhook.
Obtén información sobre las opciones de notificación de alertas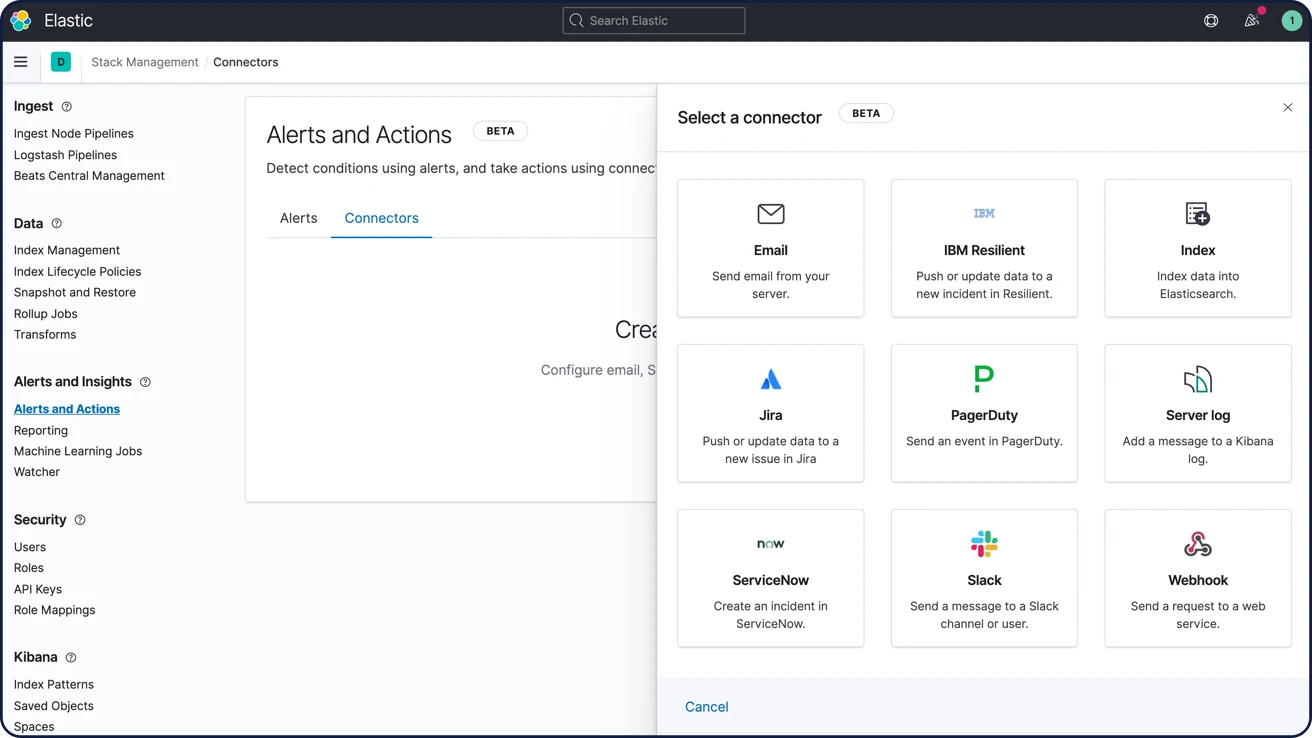
Administración y operaciones
Clientes
Elasticsearch te permite trabajar con datos de la forma que te resulte más cómoda. Con las API RESTful, clientes de lenguaje, DSL robusto y más (incluso SQL), somos flexibles para que no encuentres obstáculos.
Clientes de lenguaje
Elasticsearch usa API RESTful estándar y JSON. También creamos y mantenemos clientes en muchos lenguajes como Java, Python, .NET, SQL y PHP. Además, nuestra comunidad ha contribuido con muchos más. Es fácil trabajar con ellos, su uso se siente natural y, al igual que Elasticsearch, no limitan lo que posiblemente desees hacer con ellos.
Explora los clientes de lenguaje disponiblesDSL de Elasticsearch
Elasticsearch proporciona un DSL (lenguaje específico de dominio) de búsqueda completo basado en JSON para definir las búsquedas. El DSL de búsqueda brinda opciones de búsqueda poderosas para la búsqueda de texto completo, incluida la coincidencia de términos y frases, la imprecisión, los comodines, regex, búsquedas anidadas y más.
Obtén información sobre el DSL de ElasticsearchGET /es/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL es una característica que permite que las consultas del tipo de SQL se ejecuten en tiempo real en Elasticsearch. Ya sea que se use la interfaz REST, la línea de comando o JDBC, cualquier cliente puede usar SQL para buscar y agregar datos de forma nativa dentro de Elasticsearch.
Obtén información sobre Elasticsearch SQL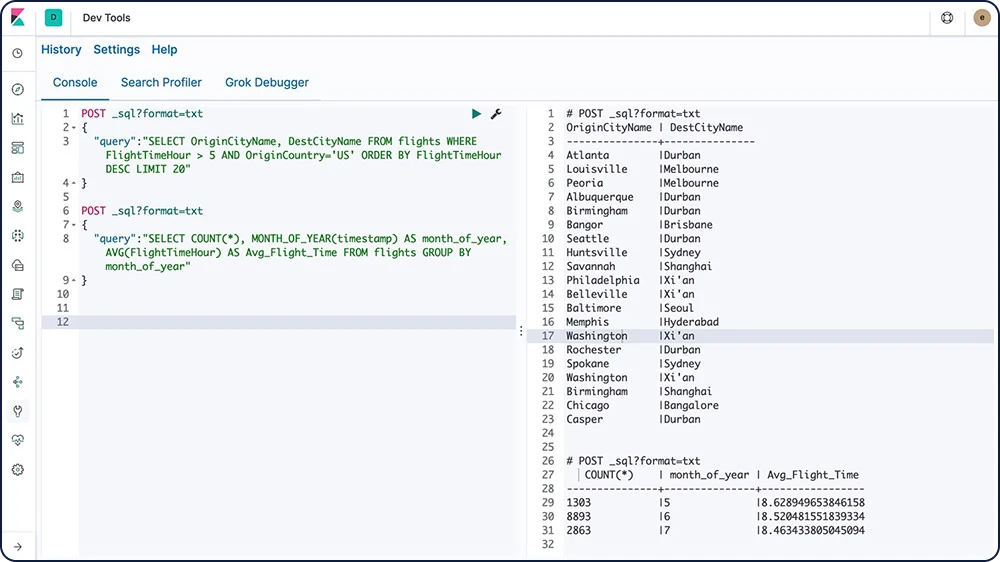
Lenguaje de búsqueda de eventos (EQL)
Con la capacidad de buscar secuencias de eventos que coincidan con condiciones específicas, el lenguaje de búsqueda de eventos (EQL) está diseñado para casos de uso como la analítica de seguridad.
Obtén información sobre EQLCliente JDBC
El controlador JDBC para Elasticsearch SQL es un controlador JDBC completo con todas las características para Elasticsearch. Es un controlador tipo 4, lo que significa que es un controlador Java puro que no está vinculado a la plataforma, es independiente y directo a la base de datos, y que convierte las llamadas de JDBC a Elasticsearch SQL.
Obtén información sobre el cliente JDBCCliente ODBC
El controlador ODBC para Elasticsearch SQL es un controlador ODBC 3.80 con todas las características para Elasticsearch. Es un controlador a nivel del núcleo, que expone toda la funcionalidad accesible a través de la API de ODBC para Elasticsearch SQL y convierte las llamadas de ODBC a Elasticsearch SQL.
Obtén información sobre el cliente ODBCTableau Connector para Elasticsearch
Tableau Connector para Elasticsearch facilita a los usuarios de Tableau Desktop y Tableau Server acceder a los datos en Elasticsearch.
Descarga Tableau ConnectorHerramientas de CLI
Elasticsearch proporciona una variedad de herramientas para configurar la seguridad y realizar otras tareas desde la línea de comando.
Explora las diferentes herramientas de CLIAdministración y operaciones
API REST
Elasticsearch proporciona una API REST integral y poderosa que puedes usar para interactuar con tu cluster.
API de documento
Realiza operaciones CRUD (crear, leer, actualizar, borrar) en documentos individuales o en varios documentos con las API de documento.
Explora las API de documento disponiblesAPI de búsqueda
Las API de búsqueda de Elasticsearch te permiten implementar más que una simple búsqueda de texto completo. También te ayudan a implementar herramientas de sugerencia (término, frase, sugerencia para completar y más), realizan la evaluación de clasificación e incluso proporcionan comentarios sobre por qué se devolvió o no un documento con la búsqueda.
Explora las API de búsqueda disponiblesAPI de agregación
El marco de trabajo de agregaciones ayuda a proporcionar datos agregados con base en una consulta de búsqueda. Se basa en bloques de creación simples denominados "agregaciones" que pueden combinarse a fin de crear resúmenes complejos de los datos. Una agregación puede considerarse una unidad de trabajo que crea información analítica sobre un conjunto de documentos.
Explora las API de agregación disponiblesAgregaciones de métricas
Agregaciones de cubetas
Agregaciones de pipelines
Agregaciones de matrices
Agregaciones de cardinalidad acumulativa
Agregaciones de Geohexgrid
API de ingesta
Usa las API de ingesta para realizar operaciones CRUD en tus pipelines de datos o usa la API de simulación de pipeline para ejecutar un pipeline específico en un conjunto de documentos.
Explora las API de ingesta disponiblesAPI de administración
Administra tu cluster de Elasticsearch de forma programática con una variedad de API relacionadas con la administración. Hay API para la administración de índices y mapeos, clusters y nodos, licencias y seguridad, y mucho más. Y si necesitas los resultados en un formato que pueda ser leído por personas, solo tienes que usar las API de cat.
Administración y operaciones
Integraciones
Como aplicación open source e independiente del lenguaje, es fácil ampliar la funcionalidad de Elasticsearch con plugins e integraciones.
Elasticsearch-Hadoop
Elasticsearch para Apache Hadoop (Elasticsearch-Hadoop o ES-Hadoop) es una pequeña biblioteca gratuita y abierta, independiente y autónoma que permite que los trabajos de Hadoop interactúen con Elasticsearch. Úsalo para crear con facilidad aplicaciones de búsqueda dinámicas e integradas para proporcionar tus datos de Hadoop o realizar analíticas detalladas y de baja latencia usando búsquedas y agregaciones geoespaciales de texto completo.
Obtén información sobre ES-HadoopApache Hive
Elasticsearch para Apache Hadoop ofrece soporte de primera clase para Apache Hive, un sistema de almacén de datos para Hadoop que facilita el resumen de datos fáciles, las búsquedas ad hoc y el análisis de grandes sets de datos almacenados en sistemas de archivos compatibles con Hadoop.
Obtén información sobre la integración en Apache HiveApache Spark
Elasticsearch para Apache Hadoop ofrece soporte de primera clase para Apache Spark, un sistema informático rápido y de clusters generales. Proporciona API de alto nivel en Java, Scala y Python, y un motor optimizado que soporta grafos de ejecución generales.
Obtén información sobre la integración en Apache SparkInteligencia comercial (BI)
Gracias a sus interfaces JDBC y ODBC, una gran variedad de aplicaciones de BI de terceros puede usar las capacidades de Elasticsearch SQL.
Explora las integraciones de BI y SQL disponiblesPlugins e integraciones
Como aplicación gratuita, abierta e independiente del lenguaje, es fácil ampliar la funcionalidad de Elasticsearch con plugins e integraciones. Los plugins son una forma de mejorar la funcionalidad esencial de Elasticsearch de manera personalizada, mientras que las integraciones son módulos o herramientas externas que facilitan trabajar con Elasticsearch.
Explora los plugins de Elasticsearch disponiblesPlugins de extensión de API
Plugins de alerta
Plugins de análisis
Plugins de descubrimiento
Plugins de ingesta
Plugins de gestión
Plugins de mapeo
Plugins de seguridad
Plugins de repositorio de restauración/snapshots
Plugins de almacenamiento
Administración y operaciones
Despliegue
Cloud público, cloud privado o algo intermedio; te facilitamos la ejecución y administración de Elasticsearch.
Descarga e instala
Comenzar es más fácil que nunca. Solo descarga e instala Elasticsearch y Kibana como un archivo o con un administrador de paquetes. Estarás indexando, analizando y visualizando datos en un instante. Y con la distribución predeterminada, también puedes probar las características Platino, como machine learning, seguridad, analítica de grafo y más gracias a la prueba gratuita de 30 días.
Descarga el Elastic StackElastic Cloud
Elastic Cloud es nuestra creciente familia de ofertas de SaaS que facilitan el despliegue, la operación y el escalado de productos y soluciones de Elastic en la nube. Desde una experiencia de Elasticsearch hospedado y administrado fácil de usar hasta soluciones de búsqueda potentes y listas para usar, Elastic Cloud es tu trampolín para poner a Elastic a trabajar para ti sin problemas. Prueba cualquiera de nuestros productos de Elastic Cloud de forma gratuita por 14 días; no se requiere tarjeta de crédito.
Primeros pasos en Elastic CloudComienza una prueba gratuita de Elasticsearch Service
Elastic Cloud Enterprise
Con Elastic Cloud Enterprise (ECE), puedes provisionar, gestionar y monitorear Elasticsearch y Kibana en cualquier escala y cualquier infraestructura, y gestionar todo desde una consola única. Elige dónde ejecutar Elasticsearch y Kibana: hardware físico, entorno virtual, cloud privado, zona privada en un cloud público o simplemente un cloud público (por ejemplo, Google, Azure, AWS). Los tenemos a todos cubiertos.
Prueba ECE de forma gratuita durante 30 díasElastic Cloud en Kubernetes
Desarrollado sobre el patrón de Kubernetes Operator, Elastic Cloud en Kubernetes (ECK) amplía las capacidades de orquestación de Kubernetes para brindar soporte a la configuración y gestión de Elasticsearch y Kibana en Kubernetes. Con Elastic Cloud en Kubernetes, simplifica los procesos de despliegue, las actualizaciones, los snapshots, el escalado, la alta disponibilidad, la seguridad y más para ejecutar Elasticsearch en Kubernetes.
Despliega con Elastic Cloud en KubernetesHelm Charts
Despliega en minutos con Elasticsearch y Kibana Helm Charts oficiales.
Lee sobre Elastic Helm Charts oficialContenedorización de Docker
Ejecuta Elasticsearch y Kibana en Docker con los contenedores oficiales desde Docker Hub.
Ejecuta el Elastic Stack en DockerIngestar y enriquecer
Ingestar y enriquecer
Ingestar
Ingresa datos en el Elastic Stack de la forma que desees. Usa API RESTful, clientes de lenguaje, nodos de ingesta, agentes ligeros o Logstash. No estás limitado a una lista de lenguajes, y como somos open source, ni siquiera estás limitado con el tipo de datos que se pueden ingestar. Si necesitas enviar un tipo de datos único, proporcionamos las bibliotecas y los pasos para crear tus propios métodos de ingesta únicos. Y si lo deseas, puedes compartirlos con la comunidad para que la próxima persona no tenga que crear algo que ya existe.
Clientes y API
Elasticsearch usa API RESTful estándar y JSON. También creamos y mantenemos clientes en muchos lenguajes como Java, Python, .NET, SQL y PHP. Además, nuestra comunidad ha contribuido con muchos más. Es fácil trabajar con ellos, su uso se siente natural y, al igual que Elasticsearch, no limitan lo que posiblemente desees hacer con ellos.
Nodo de ingesta
Elasticsearch ofrece una variedad de tipos de nodos, uno de los cuales es específico para la ingesta de datos. Los nodos de ingesta pueden ejecutar pipelines de preprocesamiento, compuestos por uno o más procesadores de ingesta. Según el tipo de operaciones realizadas por los procesadores de ingesta y los recursos requeridos, puede ser una buena idea tener nodos de ingesta dedicados que solo realicen esta tarea específica.
Beats
Los Beats son agentes de datos open source que instalas como agentes en tus servidores para enviar datos operativos a Elasticsearch o Logstash. Elastic proporciona Beats para capturar una variedad de logs comunes, métricas y otros tipos de datos varios.
Auditbeat para logs de auditoría de Linux
Filebeat para archivos de log
Functionbeat para datos en el cloud
Heartbeat para datos de disponibilidad
Journalbeat para diarios systemd
Metricbeat para métricas de infraestructura
Packetbeat para tráfico de red
Winlogbeat para logs de eventos de Windows
Logstash
Logstash es un motor de recopilación de datos open source con capacidades de creación de pipeline en tiempo real. Logstash puede unificar dinámicamente los datos de fuentes diferentes y normalizar los datos en los destinos que elijas. Limpia y democratiza todos tus datos para diversos casos de uso de visualización y analíticas posteriores avanzadas.
Agentes comunitarios
Si tienes un caso de uso específico para resolver, te alentamos a crear un Beat comunitario. Creamos una infraestructura para simplificar el proceso. La biblioteca libbeat, escrita íntegramente en Go, ofrece la API que todos los Beats usan para enviar datos a Elasticsearch, configurar las opciones de entrada, implementar logging y más.
Con más de 100 Beats aportados por la comunidad, existen agentes para métricas y logs de Cloudwatch, actividades de GitHub, temas de Kafka, MySQL, MongoDB Prometheus, Apache, Twitter y mucho más.
Explora los Beats desarrollados por la comunidad disponiblesIngestar y enriquecer
Enriquecimiento de datos
Con una variedad de analizadores, tokenizadores, filtros y opciones de enriquecimiento, Elasticsearch convierte los datos sin procesar en información valiosa.
Elastic Common Schema
Analiza de manera uniforme datos de distintas fuentes con Elastic Common Schema (ECS). Las reglas de detección, los trabajos de machine learning, los dashboards y otro contenido de seguridad pueden aplicarse de manera más amplia, las búsquedas pueden diseñarse de manera más limitada, y los nombres de campo son más fáciles de recordar.
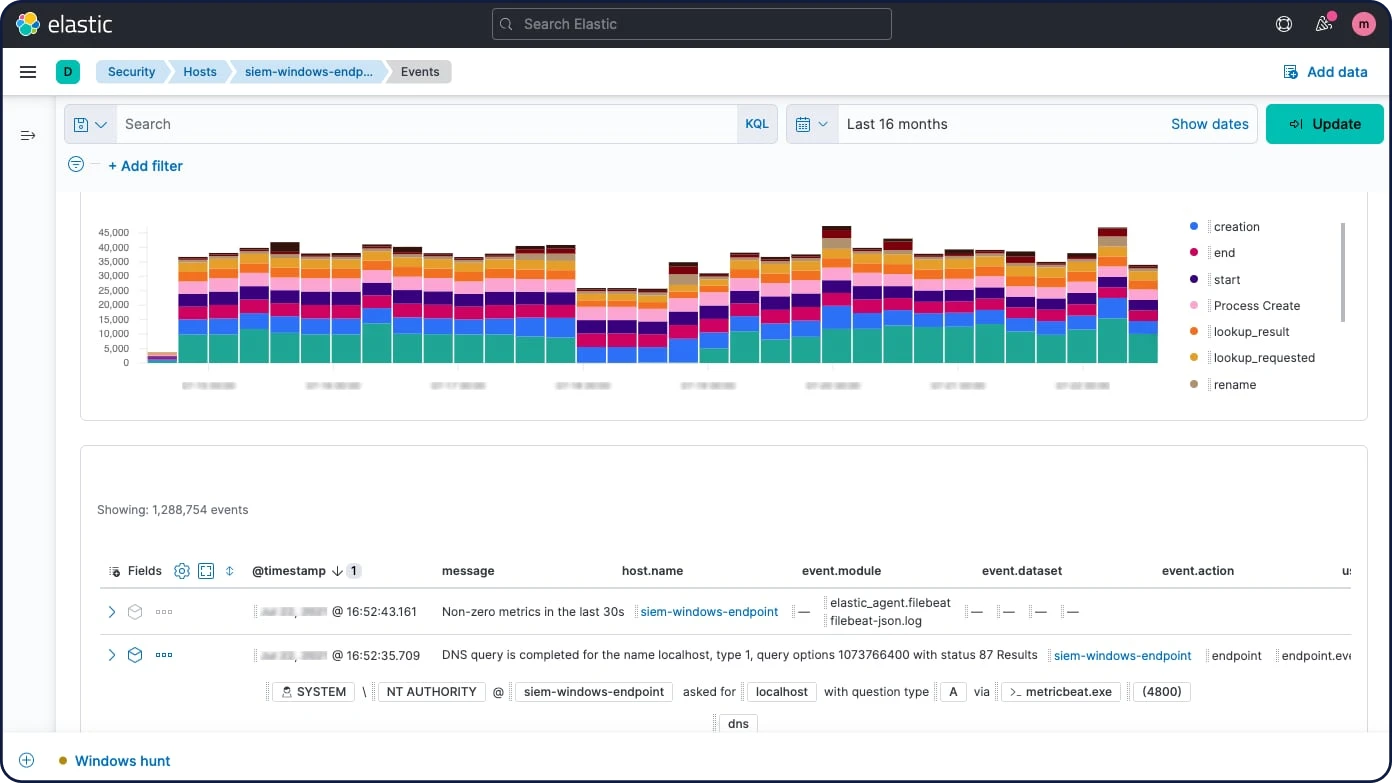
Procesadores
Usa un nodo de ingesta para preprocesar los documentos antes de que ocurra la indexación real de los documentos. El nodo de ingesta intercepta las solicitudes de índice y bulk, aplica transformaciones y luego pasa los documentos de regreso al índice o las API de bulk. El nodo de ingesta ofrece más de 25 procesadores diferentes, entre ellos: append, convert, date, dissect, drop, fail, grok, join, remove, set, split, sort, trim y más.
Analizadores
El análisis es el proceso de convertir texto, como el cuerpo de cualquier correo electrónico, en tokens o términos que se agregan al índice invertido para búsqueda. El análisis lo realiza un analizador que puede ser un analizador integrado o uno personalizado definido por índice con una combinación de tokenizadores y filtros.
Ejemplo: Analizador estándar (predeterminado)
Entrada: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone".
Salida: the 2 quick brown foxes jumped over the lazy dog's bone
Tokenizadores
Un tokenizador recibe un flujo de caracteres, lo divide en tokens individuales (generalmente, palabras individuales) y genera un flujo de tokens como salida. El tokenizador también es responsable de registrar el orden o la posición de cada término (que se usa para búsquedas por proximidad de palabras y frases) y las compensaciones de caracteres de inicio y fin de la palabra original que representa el término (que se usa para resaltar fragmentos de búsqueda). Elasticsearch tiene varios tokenizadores integrados que pueden usarse para crear analizadores personalizados.
Ejemplo: tokenizador whitespace
Entrada: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone".
Salida: The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filtros
Los filtros de token aceptan un flujo de tokens de un tokenizador y pueden modificar tokens (por ejemplo, minúscula), eliminar tokens (por ejemplo, eliminar palabras vacías) o agregar tokens (por ejemplo, sinónimos). Elasticsearch tiene varios filtros de token integrados que pueden usarse para crear analizadores personalizados.
Los filtros de caracteres se usan para preprocesar el flujo de caracteres antes de que se pase al tokenizador. Un filtro de caracteres recibe el texto original como un flujo de caracteres y puede transformar el flujo agregando, eliminando o cambiando caracteres. Elasticsearch tiene varios filtros de caracteres integrados que pueden usarse para crear analizadores personalizados.
Obtén información sobre los filtros de caracteresAnalizadores de lenguaje
Busca en tu idioma. Elasticsearch ofrece más de 30 analizadores de lenguaje diferentes, que incluyen varios idiomas con caracteres no latinos, como ruso, árabe y chino.
Mapeo dinámico
No es necesario definir los campos y los tipos de mapeo antes de usarlos. Gracias al mapeo dinámico, los nombres de campo nuevos se agregarán automáticamente, simplemente con la indexación de un documento.
Procesador de enriquecimiento con coincidencia
El procesador de ingesta con coincidencia permite a los usuarios buscar datos en el momento de la ingesta e indica el índice desde el cual se pueden extraer datos enriquecidos. Esto ayuda a los usuarios de Beats que necesitan agregar algunos elementos a sus datos; en lugar de cambiar de Beats a Logstash, los usuarios pueden consultar el pipeline de ingesta directamente. Los usuarios también podrán normalizar los datos con el procesador para mejores analíticas y búsquedas más comunes.
Procesador de enriquecimiento con coincidencia geográfica
El procesador de enriquecimiento con coincidencia geográfica es una forma útil y práctica de permitir a los usuarios mejorar sus capacidades de búsqueda y agregación gracias al aprovechamiento de sus datos geográficos sin necesidad de definir búsquedas o agregaciones en términos de coordenadas geográficas. De forma similar al procesador de enriquecimiento con coincidencia, los usuarios pueden buscar datos en el momento de la ingesta y encontrar el índice óptimo desde el cual se pueden extraer datos enriquecidos.
Almacenamiento de datos
Almacenamiento de datos
Flexibilidad
El Elastic Stack es una solución poderosa que puede aplicarse en casi cualquier caso de uso. Y si bien es mejor conocido por sus capacidades de búsqueda avanzada, su diseño flexible lo convierte en una herramienta óptima para muchas necesidades diferentes, incluido el almacenamiento de documentos, el análisis y las métricas temporales, y las analíticas geoespaciales.
Tipos de datos
Elasticsearch soporta varios tipos de datos diferentes para los campos de un documento, y cada uno de esos tipos de datos ofrece sus propios diversos subtipos. Esto te permite almacenar, analizar y utilizar datos de la forma más eficaz y efectiva posible, independientemente de los datos. Estos son algunos de los tipos de datos para los que está optimizado Elasticsearch:
Texto
Formas
Números
Vectores
Histogramas
Series temporales o de fechas
Campo aplanado
Puntos geográficos/formas geométricas
Datos no estructurados (JSON)
Datos estructurados
Búsqueda de texto completo (índice invertido)
Elasticsearch usar una estructura llamada índice invertido, que está diseñada para permitir búsquedas de texto completo muy rápidas. Un índice invertido consiste en una lista de todas las palabras únicas que aparecen en cualquier documento y, para cada palabra, una lista de documentos en los que aparece. Para crear un índice invertido, primero dividimos el campo de contenido de cada documento en palabras separadas (que llamamos "términos" o "tokens"), creamos una lista ordenada de todos los términos únicos y luego incluimos en qué documento aparece cada término.
Almacén de documentos (documentos no estructurados)
Elasticsearch no requiere que los datos sean estructurados para ingestarlos o analizarlos (aunque la estructuración mejorará las velocidades). Este diseño facilita dar los primeros pasos, pero también hace que Elasticsearch sea un almacén de documentos efectivo. Si bien Elasticsearch no es una base de datos NoSQL, proporciona una funcionalidad similar.
Serie temporal/analíticas (almacén columnar)
Un índice invertido permite que las búsquedas consulten los términos de búsqueda rápidamente, pero la clasificación y agregaciones requieren un patrón de acceso a los datos diferente. En lugar de buscar el término y encontrar documentos, deben poder buscar el documento y encontrar los términos que tiene en un campo. Los valores de documentos son la estructura de datos en el disco en Elasticsearch, creada al momento de indexación del documento, lo que posibilita este patrón de acceso a los datos y permite que la búsqueda ocurra de forma columnar. Esto permite a Elasticsearch destacarse con la analítica de métricas y series temporales.
Geoespacial (árboles de BKD)
Elasticsearch usa las estructuras de árboles de BKD en Lucene para almacenar datos geoespaciales. Esto permite el análisis eficiente tanto de los puntos geográficos (latitud y longitud) como de las formas geográficas (rectángulos y polígonos).
Almacenamiento de datos
Seguridad
La seguridad no se detiene a nivel del cluster. Mantén los datos seguros hasta el nivel del campo dentro de Elasticsearch.
Seguridad de API a nivel de campo y de documento
La seguridad a nivel de campo restringe los campos que los usuarios pueden leer. En particular, restringe a qué campos se puede acceder desde las API de lectura basadas en documentos.
La seguridad a nivel de documento restringe los documentos que los usuarios pueden leer. En particular, restringe a qué documentos se puede acceder desde las API de lectura basadas en documentos.
Obtén información sobre seguridad a nivel de campo y documentoSoporte de encryption at rest de datos
Si bien el Elastic Stack no implementa encryption at rest de fábrica, se recomienda que la encriptación a nivel del disco se configure en todas las máquinas host. Además, los snapshot targets también deben asegurar que los datos se encripten en reposo.
Almacenamiento de datos
Gestión
Elasticsearch te da la posibilidad de administrar por completo tus clusters y sus nodos, tus índices y sus shards, y lo que es más importante, todos los datos contenidos.
Índices en clusters
Un cluster es una recopilación de uno o más nodos (servidores) que posee en conjunto todos tus datos y brinda capacidades de indexación y búsqueda federadas en todos los nodos. Esta arquitectura facilita el escalado horizontal. Elasticsearch proporciona varias UI y una API REST integral y poderosa que puedes usar para gestionar los clusters.
Snapshot y restauración de datos
Un snapshot es un backup que se hace desde un cluster de Elasticsearch en ejecución. Puedes hacer un snapshot de índices individuales o del cluster completo y almacenar el snapshot en un repositorio en un sistema de archivos compartidos. Hay disponibles plugins que también admiten repositorios remotos.
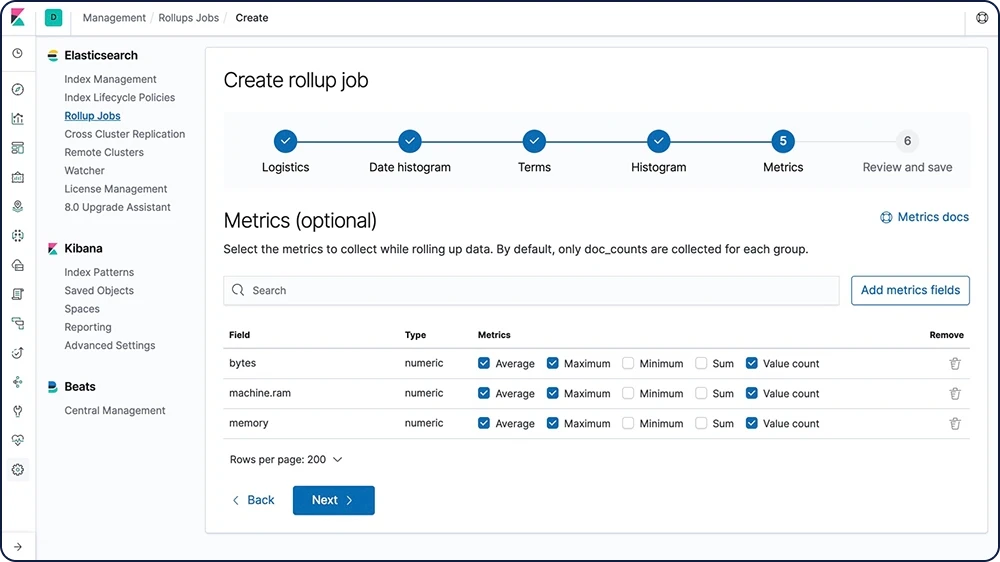
Índices de rollup
Tener al alcance los datos históricos para análisis es sumamente útil, pero suele evitarse debido al costo financiero de archivar grandes cantidades de datos. Los períodos de retención quedan entonces regidos por las realidades financieras y no por la utilidad que presenta contar con una gran cantidad de datos históricos. La característica rollup brinda una manera de resumir y almacenar datos históricos para que puedan usarse en análisis, pero a una fracción del costo de almacenamiento de los datos sin procesar.
Buscar y analizar
Buscar y analizar
Búsqueda de texto completo
Elasticsearch es conocido por sus poderosas capacidades de búsqueda de texto completo. Su velocidad proviene de un índice invertido en su núcleo, y su poder proviene de la relevancia ajustable, DSL de búsqueda avanzada y la amplia gama de características que mejoran la búsqueda.
Índice invertido
Elasticsearch usar una estructura llamada índice invertido, que está diseñada para permitir búsquedas de texto completo muy rápidas. Un índice invertido consiste en una lista de todas las palabras únicas que aparecen en cualquier documento y, para cada palabra, una lista de documentos en los que aparece. Para crear un índice invertido, primero dividimos el campo de contenido de cada documento en palabras separadas (que llamamos "términos" o "tokens"), creamos una lista ordenada de todos los términos únicos y luego incluimos en qué documento aparece cada término.
Campos de tiempo de ejecución
Un campo de tiempo de ejecución es un campo que se evalúa al momento de la búsqueda (esquema durante la lectura). Los campos de tiempo de ejecución pueden introducirse o modificarse en cualquier momento, incluso luego de que los documentos se hayan indexado, y pueden definirse como parte de una búsqueda. Los campos de tiempo de ejecución se exponen a búsquedas con la misma interfaz que los campos indexados, de modo que un campo puede ser un campo de tiempo de ejecución en algunos índices de un flujo de datos y un campo indexado en otros índices de ese flujo de datos, y no es necesario que las búsquedas estén al tanto de esto. Mientras que los campos indexados proporcionan un rendimiento de búsqueda óptimo, los campos de tiempo de ejecución los complementan introduciendo flexibilidad para cambiar la estructura de datos una vez que los documentos hayan sido indexados.
Campo de tiempo de ejecución de búsqueda
Los campos de tiempo de ejecución de búsqueda te brindan la flexibilidad de agregar información desde un índice de búsqueda a los resultados de un índice primario mediante la definición de una clave en ambos índices que vincule los documentos. Al igual que los campos de tiempo de ejecución, esta característica se usa al momento de la búsqueda y proporciona un enriquecimiento flexible de los datos.
Búsqueda entre clusters
La característica de búsqueda entre clusters (CCS) permite que cualquier nodo actúe como cliente federado en varios clusters. Un nodo de búsqueda entre clusters no se unirá al cluster remoto, sino que se conectará a un cluster remoto de forma ligera para ejecutar solicitudes de búsqueda federadas.
Relevancia
Una similitud (relevancia/modelo de clasificación) define cómo se califican los documentos que coinciden. De forma predeterminada, Elasticsearch usa la similitud BM25 (una similitud avanzada basada en TF/IDF con normalización tf integrada óptima para campos breves, como nombres); pero hay disponibles muchas otras opciones de similitud.
Búsqueda de vectores (ANN)
Tomando como base el soporte de nuevo vecino más cercano aproximado o ANN de Lucene 9 basado en el algoritmo HNSW, el nuevo endpoint de API _knn_search facilita una búsqueda más escalable y de mejor rendimiento por similitud de vectores. Lo logra permitiendo una compensación entre la recuperación y el rendimiento; es decir, permite un rendimiento mucho mejor en sets de datos muy grandes (en comparación con el método de similitud de vectores de fuerza bruta existente) haciendo pequeños compromisos con respecto a la recuperación.
DSL de búsqueda
La búsqueda de texto completo requiere de un lenguaje de búsqueda sólido. Elasticsearch proporciona un DSL (lenguaje específico de dominio) de búsqueda completo basado en JSON para definir las búsquedas. Crea búsquedas simples para encontrar coincidencias de términos y frases, o desarrolla búsquedas compuestas que puedan combinar varias búsquedas. Además, los filtros pueden aplicarse al momento de la búsqueda para eliminar documentos antes de que se les asigne una relevancia.
Búsqueda asíncrona
La API de búsqueda asíncrona permite a los usuarios ejecutar búsquedas de larga ejecución en segundo plano, rastrear el progreso de las búsquedas y recuperar resultados parciales a medida que están disponibles.
Resaltadores
Los resaltadores te permiten obtener fragmentos resaltados de uno o más campos en tus resultados de búsqueda de modo que puedas mostrar a los usuarios dónde se encuentran las coincidencias con la búsqueda. Cuando solicitas que se resalte, la respuesta contiene un elemento de resaltado adicional para cada coincidencia de búsqueda que incluye los campos resaltados y los fragmentos resaltados.
Autocompletar
La herramienta de sugerencias para completar proporciona la funcionalidad de autocompletar o buscar a medida que escribes. Es una característica de navegación que guía a los usuarios a resultados relevantes a medida que escriben, lo que mejora la precisión de búsqueda.
Herramientas de sugerencia ("quisiste decir")
La herramienta de sugerencia de frases agrega la funcionalidad "quisiste decir" a tu búsqueda creando una lógica adicional sobre la herramienta de sugerencia de términos para seleccionar frases completas correctas en lugar de tokens individuales ponderados según modelos de idioma de n-gramas. En la práctica, esta herramienta de sugerencia podrá tomar mejores decisiones sobre cuáles tokens elegir según la coocurrencia y las frecuencias.
Correcciones (corrector ortográfico)
La herramienta de sugerencia de términos es la base del corrector ortográfico, sugiere términos según la distancia de edición. El texto de sugerencia proporcionado se analiza antes de sugerir los términos. Los términos sugeridos se proporcionan por token de texto de sugerencia analizado.
Percoladores
Un cambio del modelo de búsqueda estándar en el cual se usa una búsqueda para encontrar un documento almacenado en un índice: los percoladores pueden usarse para buscar coincidencias entre los documentos y las búsquedas almacenadas en un índice. La búsqueda percolate en sí contiene el documento que se usará como búsqueda para establecer la coincidencia con las búsquedas almacenadas.
Generador de perfiles de búsqueda/optimizador
La API de perfil proporciona información de tiempo detallada sobre la ejecución de componentes individuales en una solicitud de búsqueda. Brinda información sobre cómo se ejecutan las solicitudes de búsqueda a un nivel bajo para poder comprender por qué ciertas solicitudes son lentas y tomar medidas para mejorarlas.
Resultados de búsqueda basados en permisos
La seguridad a nivel de campo y la seguridad a nivel de documento restringen los resultados de búsqueda solo a lo que los usuarios tienen acceso de lectura. En particular, restringe a qué campos y documentos se puede acceder desde las API de lectura basadas en documentos.
Sinónimos actualizables dinámicamente
Con la API para volver a cargar analizadores, puedes desencadenar la nueva carga de la definición de sinónimos. Los contenidos del archivo de sinónimos configurados se volverán a cargar, y la definición de sinónimos que usa el filtro se actualizará. La API _reload_search_analyzers puede ejecutarse en uno o más índices, y desencadenará la nueva carga de los sinónimos desde el archivo configurado.
Fijación de resultados
Promueve documentos seleccionados para que se clasifiquen mejor que aquellos que coinciden con una búsqueda dada. Esta característica se usa típicamente para guiar a quienes realizan búsquedas a documentos curados que están promocionados por sobre cualquier coincidencia "orgánica" en una búsqueda. Los documentos promocionados o "fijados" se identifican con el ID de documento almacenado en el campo _id.
Buscar y analizar
Analíticas
La búsqueda de datos es solo un comienzo. Las características analíticas poderosas de Elasticsearch te permiten tomar los datos que buscaste y encontrarles un significado más profundo. Ya sea a través del agregado de resultados, el hallazgo de relaciones entre los documentos o la creación de alertas basadas en valores de umbral, todo surge a partir de la funcionalidad de búsqueda poderosa.
Agregaciones
El marco de trabajo de agregaciones ayuda a proporcionar datos agregados con base en una consulta de búsqueda. Se basa en bloques de creación simples denominados "agregaciones" que pueden combinarse a fin de crear resúmenes complejos de los datos. Una agregación puede considerarse una unidad de trabajo que crea información analítica sobre un conjunto de documentos.
Agregaciones de métricas
Agregaciones de cubetas
Agregaciones de pipelines
Agregaciones de matrices
Agregaciones de Geohexgrid
Agregaciones de muestreador aleatorio
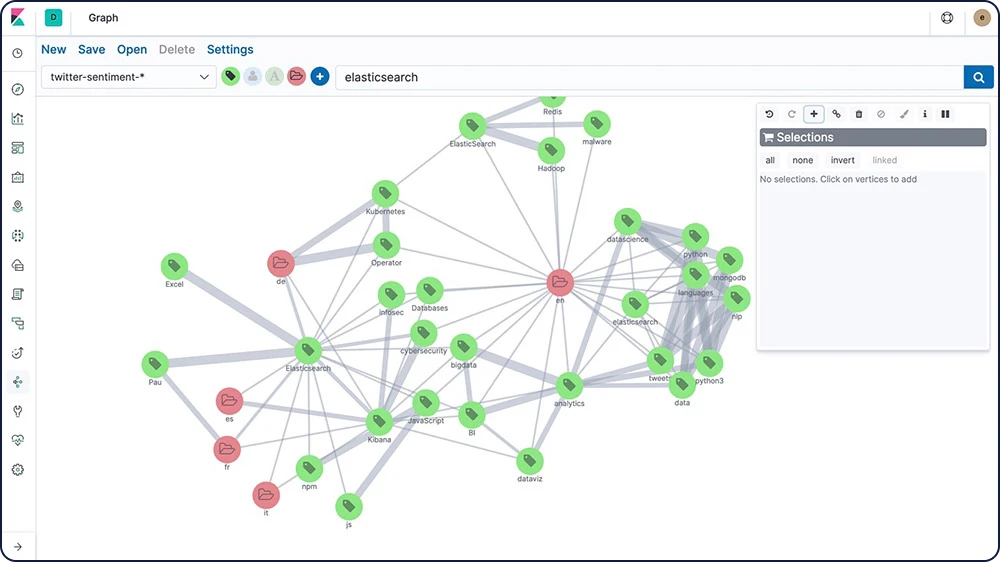
Exploración de Graph
La API de exploración de Graph te permite extraer y resumir información sobre los documentos y términos en tu índice de Elasticsearch. La mejor forma de comprender el comportamiento de esta API es usar Graph en Kibana para explorar las conexiones.
Buscar y analizar
Machine learning
Las características de machine learning de Elastic modelan automáticamente el comportamiento de tus datos de Elasticsearch (tendencias, periodicidad y más) en tiempo real para identificar más rápido los problemas, optimizar el análisis de la causa raíz y disminuir los falsos positivos.
Previsión en series temporales
Después de que el machine learning de Elastic crea las bases de referencia del comportamiento normal de los datos, puedes usar esa información para extrapolar el comportamiento futuro. Luego, crea una previsión para estimar un valor de serie temporal en una fecha futura específica o calcula la probabilidad de que un valor de serie temporal ocurra en el futuro.
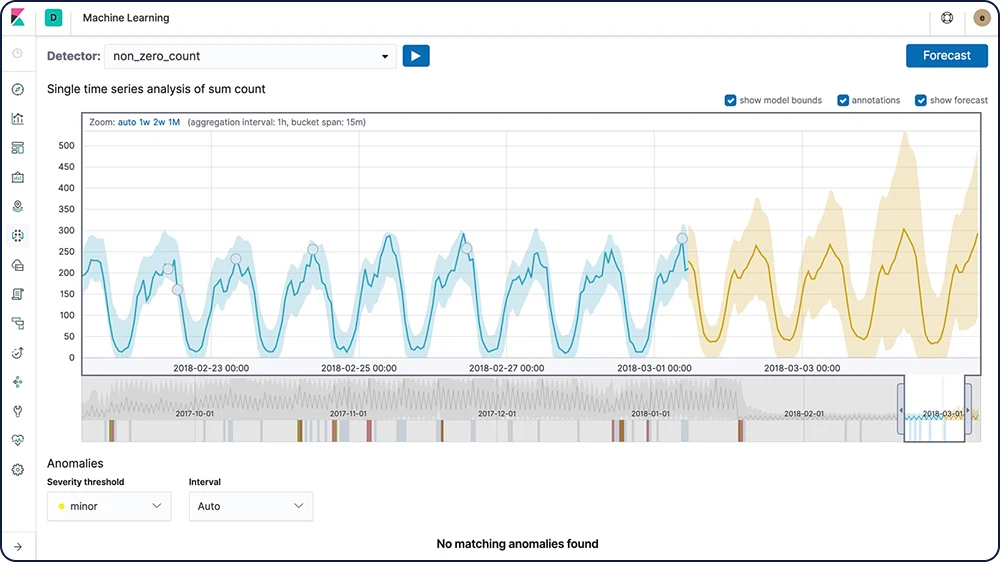
Detección de anomalías en series temporales
Las características de machine learning de Elastic automatizan el análisis de los datos temporales mediante la creación de bases de referencia precisas del comportamiento normal en los datos y la identificación de patrones anómalos en esos datos. Las anomalías se detectan, califican y vinculan con influencias estadísticamente importantes en los datos mediante algoritmos patentados de machine learning.
Anomalías relacionadas con desviaciones temporales de valores, recuentos o frecuencias
Rareza estadística
Comportamientos inusuales para un miembro de una población
Alerta de anomalías
Para los cambios que son más difíciles de definir con reglas y umbrales, combina las alertas con características de machine learning sin supervisión para encontrar el comportamiento inusual. Luego, usa las puntuaciones de anomalías en el marco de trabajo de alertas para recibir notificaciones cuando surjan problemas.
Inferencia
La inferencia te permite usar procesos de machine learning supervisados, como la regresión o clasificación, no solo como análisis de batch, sino de forma continua. La inferencia permite usar modelos de machine learning entrenados sobre datos entrantes.
Identificación de idiomas
La identificación de idioma es un modelo entrenado que puedes usar para determinar el idioma del texto. Puedes usar como referencia el modelo de identificación del idioma en un procesador de inferencias.