Monitoreo en Prometheus a escala con el Elastic Stack
Herramientas. Como ingenieros, nos encantan las buenas herramientas que ayudan a nuestros equipos a trabajar de forma productiva, resolver problemas más rápido y ser mejores. Pero las herramientas pueden tender a aumentar en número, requerir mantenimiento adicional y, lo que es más importante, crear silos. Cada equipo tiene ciertas responsabilidades y busca constantemente herramientas que puedan cumplir con requisitos específicos de la mejor manera. Como resultado, los equipos se vuelven eficientes como una unidad, pero el efecto secundario de tal autonomía eficaz es una falta de información sobre otras partes de la organización. Si multiplicas esto por la cantidad de equipos, verás rápidamente clusters aislados que desestiman una visión holística de cómo le va a tu negocio.
Prometheus es un ejemplo excelente de este tipo de herramientas. Ha crecido rápidamente y se ha convertido en la herramienta predilecta para el monitoreo y las alertas de sistemas de contenedor. Su principal fortaleza radica en el monitoreo y almacenamiento eficientes de métricas del lado del servidor. Prometheus es completamente open source y posee una comunidad activa que amplía su cobertura a muchos sistemas de terceros en forma de exportadores. Como la mayoría de las herramientas especializadas, Prometheus está pensado para ser simple y fácil de operar. Esta simpleza conlleva compensaciones particularmente relevantes en los casos de despliegues a gran escala y colaboración entre equipos. En este blog, examinaremos algunas de estas compensaciones y veremos cómo el Elastic Stack puede ayudar a resolverlas.
Retención de datos a largo plazo
Prometheus almacena datos de forma local en la instancia. Tener tanto almacenamiento de datos como cómputos en un nodo puede facilitar la operación, pero también dificulta escalar y garantizar la alta disponibilidad. Por lo tanto, Prometheus no está optimizado para ser un almacenamiento de métricas a largo plazo. Según el tamaño de tu entorno, la tasa de retención óptima de series temporales en Prometheus puede ser de tan solo varios días o incluso horas.
Para retener los datos de Prometheus de manera escalable y durable para análisis extendido (por ejemplo, estacionalidad de series temporales), necesitarás complementar Prometheus con una solución de almacenamiento a largo plazo. Y existen muchas soluciones para elegir, como otras TSDB o bases de datos columnares optimizadas para series temporales. Estas soluciones, si bien son eficientes para almacenar métricas, comparten una desventaja, están especializadas en solo un tipo de datos: métricas. Las métricas son muy importantes para ayudar a comprender cómo se comportan tus sistemas, sin embargo, representan solo una parte de lo que hace observables a los sistemas.
Cuando los usuarios piensan en observabilidad, intentan combinar otros tipos de datos operativos, como logs y rastreos, con métricas. En nuestro blog sobre observabilidad en el Elastic Stack, hablamos sobre una creciente cantidad de casos de uso en los que los usuarios que adoptaron el Elastic Stack para logs también comenzaron a introducir métricas, rastreos y datos de tiempo de actividad en Elasticsearch. Y no es de extrañar; Elasticsearch trata a todos estos tipos de datos como cualquier otro índice y te permite agregar, correlacionar, analizar y visualizar todos tus datos operativos de la manera en que desees. Las características como data rollup en Elastic posibilitan el almacenamiento de series temporales históricas por una fracción del costo de almacenamiento de datos sin procesar.
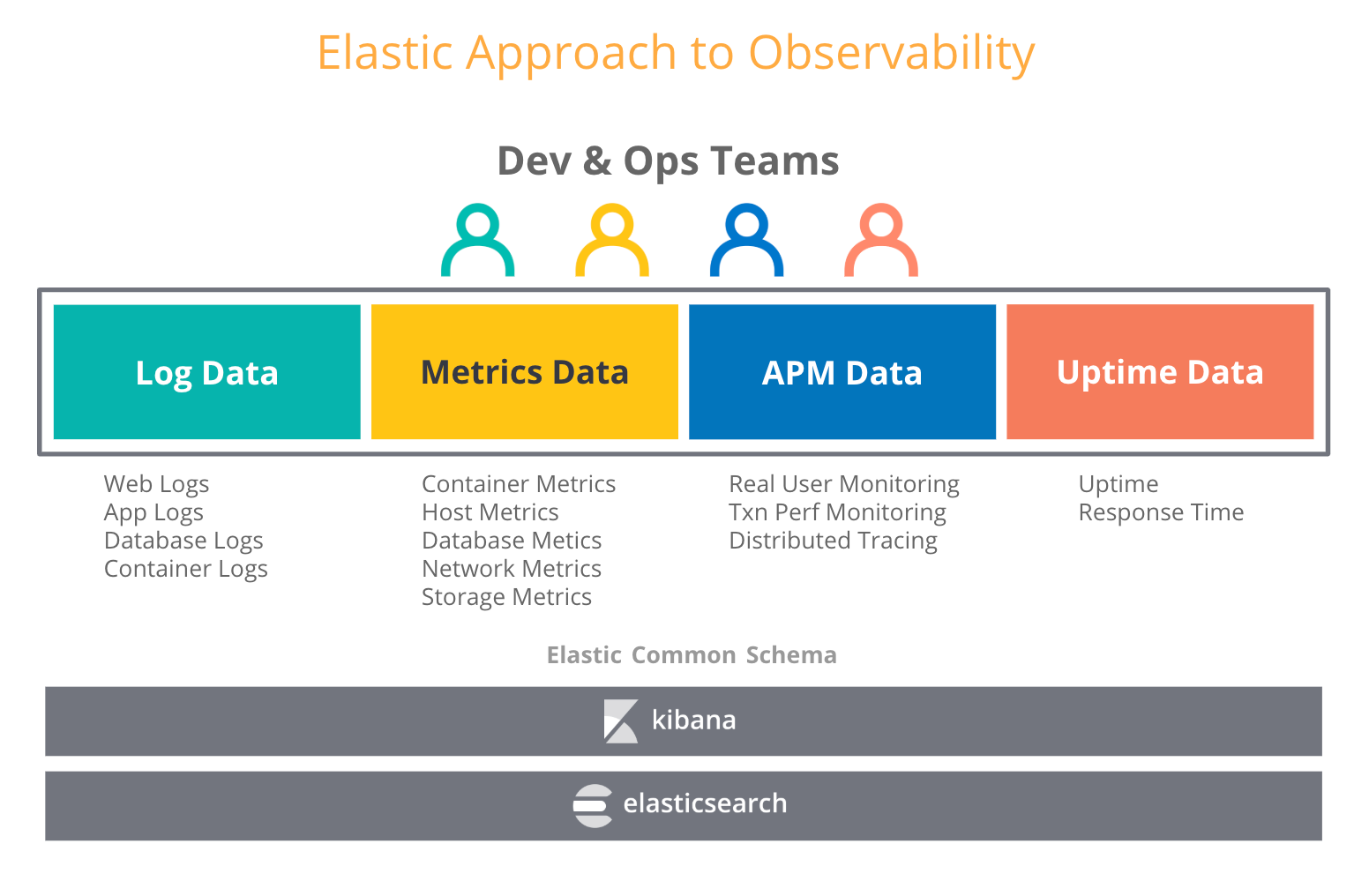
¿Qué significa esto para elegir un almacenamiento a largo plazo para Prometheus? Puedes elegir un almacén de métricas dedicado para lograr tasas de retención más prolongadas para tus métricas de Prometheus y potencialmente crear otro silo. O puedes combinar lo mejor de dos mundos gracias al Elastic Stack: ejecutar Prometheus al límite y retener las métricas por el tiempo que desees junto con tus otros datos operativos en un despliegue escalable y centralizado de Elasticsearch. Eso significa almacenamiento a largo plazo y mayor observabilidad.
Vista global centralizada de datos de Prometheus
En una configuración de producción, probablemente administres varios clusters de Kubernetes. Cada cluster se ejecuta en una o más instancias de Prometheus que pueden ver el estado de nodos, pods, servicios y endpoints. ¿Falta algo?
Una instancia de Prometheus puede cubrir un subconjunto de recursos en tu entorno. Si deseas hacer una pregunta que requiera la búsqueda de métricas de varios clusters, no hay una manera directa de hacerlo con Prometheus.

Usar Elastic como almacenamiento centralizado puede ayudarte a consolidar los datos de cientos de instancias de Prometheus y lograr una visión global de los datos que provienen de todos los recursos. El módulo de Prometheus para Metricbeat puede extraer métricas automáticamente de instancias de Prometheus, puertos de inserción, exportadores y prácticamente cualquier otro servicio que admita el formato de exposición de Prometheus. Lo mejor es que no necesitas cambiar nada en tu entorno de producción, es una experiencia plug-and-play.
Dimensiones de alta cardinalidad
¿Por qué importa la "alta cardinalidad"? Te permite agregar contexto arbitrario a las métricas como etiquetas. En la mayoría de los casos, deseas retener estos metadatos, dado que pueden ser muy útiles al depurar tus servicios. Todas estas ID de rastreo, ID de solicitud, ID de contenedor, números de versión, etcétera, siempre te contarán más sobre qué está sucediendo en tus sistemas.

Las TSDB son buenas para tratar con dimensiones de baja cardinalidad. La supuesta eficiencia de almacenamiento que tienen las TSDB especializadas sobre Elasticsearch depende en gran medida de dimensiones de baja cardinalidad. La documentación de Prometheus desalienta enfáticamente los datos de alta cardinalidad:
PRECAUCIÓN: Recuerda que cada combinación única de pares de etiquetas de valor clave representa una nueva serie temporal que puede aumentar dramáticamente la cantidad de datos almacenados. No uses etiquetas para almacenar dimensiones con alta cardinalidad (muchos valores de etiqueta diferentes), como ID de usuarios, direcciones de correo electrónico u otros conjuntos de datos ilimitados.
¿Es realmente un buen consejo? En un entorno distribuido, la depuración es una tarea muy compleja. Anteriormente, con los monolitos, la depuración era un proceso directo paso a paso por el código de aplicación. Se podía identificar fácilmente el módulo monolítico causante del problema observando algunos dashboards. Ya no es así. El software de infraestructura se encuentra en medio de un cambio de paradigma. Contenedores, orquestadores, microservicios, mallas de servicios, tecnologías sin servidores, lambdas; todas son tecnologías increíblemente prometedoras que cambian la forma en que creamos y operamos software. En consecuencia, aumenta la distribución, y la depuración puede compararse con el trabajo de un detective para encontrar en qué parte del sistema está el código con el problema.
La alta disponibilidad no es un problema para Elastic. Nada debería restringir a los usuarios para agregar contexto relevante a sus datos. Gracias a sus capacidades de indexación, Elasticsearch puede permitir a los usuarios hacer anotaciones en las métricas como deseen, con cualquier metadato que pueda ayudar a encontrar factores contribuyentes para identificar la causa raíz en el menor tiempo posible.
Seguridad. En todas partes.
Algo que esperamos de las buenas herramientas es que, como mínimo, no introduzcan riesgos de seguridad en nuestros entornos. Dos elementos esenciales para la seguridad de cualquier despliegue distribuido son la comunicación encriptada y el control de acceso.
Al momento de escribir este blog, Alertmanager (el servidor de Prometheus) y los exportadores oficiales no soportan la encripción TLS de los endpoints HTTP. Para desplegar estos componentes de forma segura, deberás usar un proxy reverso como nginx y aplicar encripción TLS en la capa del proxy. Cualquier control de acceso basado en roles (RBAC) sobre las métricas también debería manejarse de forma externa y no a través del servidor Prometheus en sí. La buena noticia es que TLS y RBAC no son un problema si ejecutas Prometheus en un cluster de Kubernetes, ya que este proporciona ambos. En todos los demás casos (por ejemplo, ejecutar cientos de servidores Prometheus en despliegues híbridos o distribuidos geográficamente) abordar estas cuestiones de seguridad con herramientas de terceros no es una tarea trivial.
En Elastic, nos tomamos estos riesgos muy en serio y hacemos de la seguridad una parte integral de nuestro stack. Las opciones de seguridad básicas son parte de nuestra distribución predeterminada de forma gratuita, y Elasticsearch proporciona varias maneras de asegurar el acceso a tus datos en un cluster y de encriptar el tráfico entre el cluster y los agentes de datos. Además de RBAC, Elasticsearch soporta el mecanismo afinado de control de acceso basado en atributos (ABAC), que te permite restringir el acceso a los documentos en búsquedas y agregaciones. Con los ajustes de configuración SSL en Metricbeat, puedes asegurarte de que tus datos operativos viajen seguros independientemente de qué tan grandes y distribuidos sean tus entornos.
Transmisión de métricas de Prometheus a Elasticsearch
Ahora ya puedes comenzar a transmitir métricas de Prometheus a Elasticsearch con Metricbeat. Con el módulo de Prometheus puedes extraer métricas de los servidores Prometheus, exportadores o puertos de inserción de varias maneras:
- Si ya estás ejecutando el servidor Prometheus y te gustaría buscar directamente en estas métricas, puedes comenzar por conectarte al servidor Prometheus y recuperar las métricas ya recopiladas con el endpoint
/metricso la API de federación de Prometheus.
- Si no tienes un servidor Prometheus o no te interesa extraer tus exportadores y puertos de inserción en paralelo con varias herramientas, puedes conectarte a ellos directamente.

Ejecuta Metricbeat lo más cerca posible de tu servidor Prometheus. Puedes elegir la configuración que mejor se adapte a tus necesidades de nuestro blog de Prometheus y estándares abiertos.
Vigilar el estado de tus servidores Prometheus
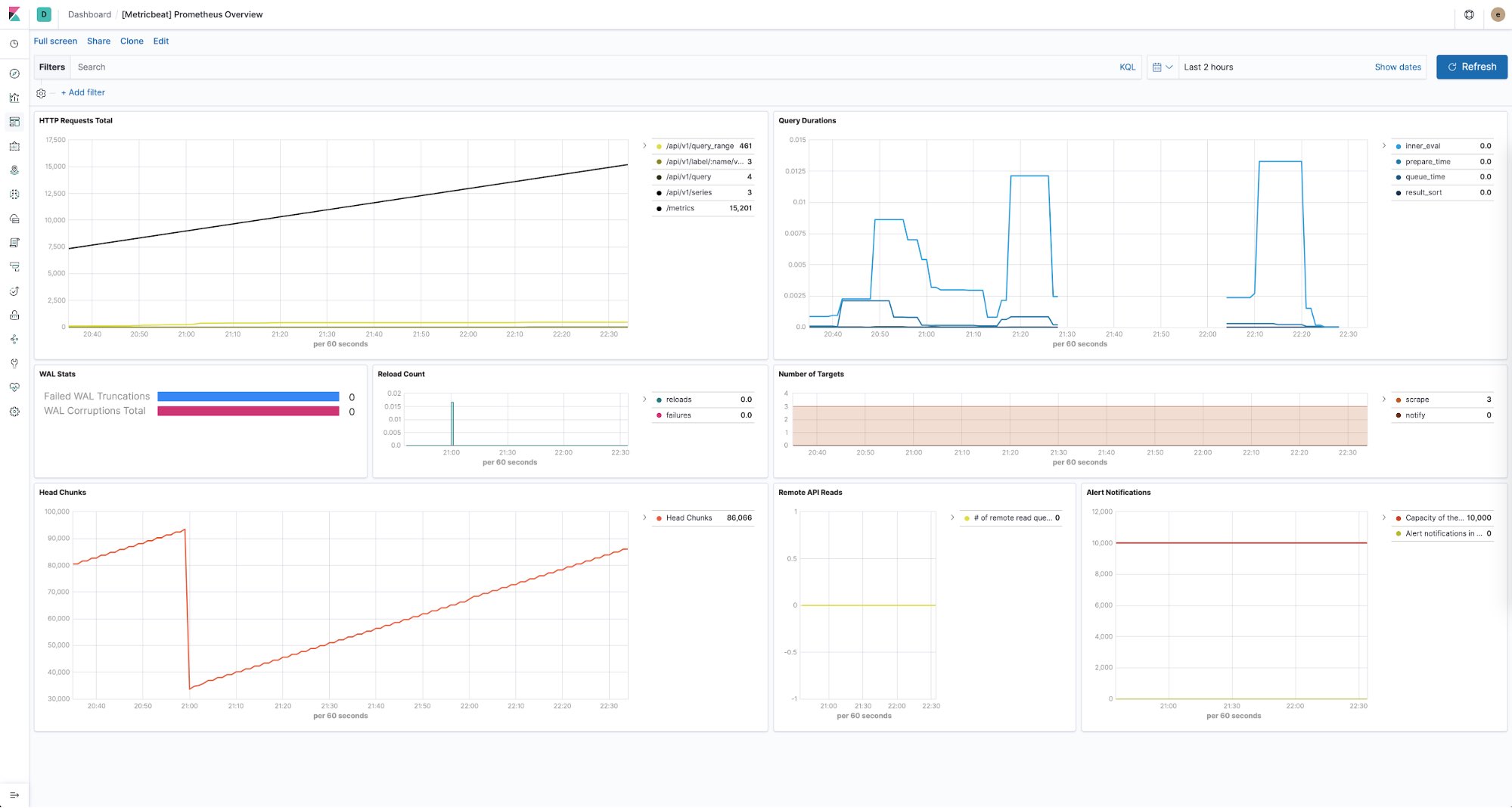
El Elastic Stack también te proporciona una manera de mantenerte al tanto del estado de todas tus instancias de Prometheus. Puedes usar Metricbeat para recopilar y almacenar métricas de rendimiento de cada servidor Prometheus en tus entornos. Con dashboards predefinidos listos para usar, puedes ver con facilidad información como la cantidad de solicitudes HTTP por endpoint, la duración de las búsquedas, la cantidad de objetivos detectados y mucho más.
Considerándolo todo
A fin de cuentas, el objetivo es que tú, tu equipo y toda tu organización tengan éxito. Todas las herramientas deberían entenderse como un medio para un fin. Cada equipo debería tener la libertad de elegir lo que lo ayude a lograr todo su potencial. Cuando se trata de derribar silos operativos, creemos que el Elastic Stack puede ayudarte a crear la mejor plataforma de observabilidad en la que todos en tu organización puedan acceder de forma segura a datos operativos, interactuar con ellos y volver a ser un equipo.
Puedes aprender más sobre cómo trabajamos con datos temporales en nuestra página web sobre métricas de Elastic. Prueba transmitir tus métricas a Elasticsearch Service; es la forma más fácil y rápida de comenzar. Si tienes preguntas, no dudes en consultarnos en nuestros foros de debate.