Monitoreo de infraestructura para eficiencia de alta cardinalidad a escala
Elastic te brinda una observabilidad completa en tu infraestructura, identifica anomalías, investiga las causas raíz y automatiza la remediación, todo impulsado por IA, para que puedas planificar la capacidad y resolver problemas con mayor rapidez. El almacenamiento en columnas mantiene el rendimiento alto y los costos bajos.



Totalmente equipado con IA, en todos los lugares donde ya trabajas
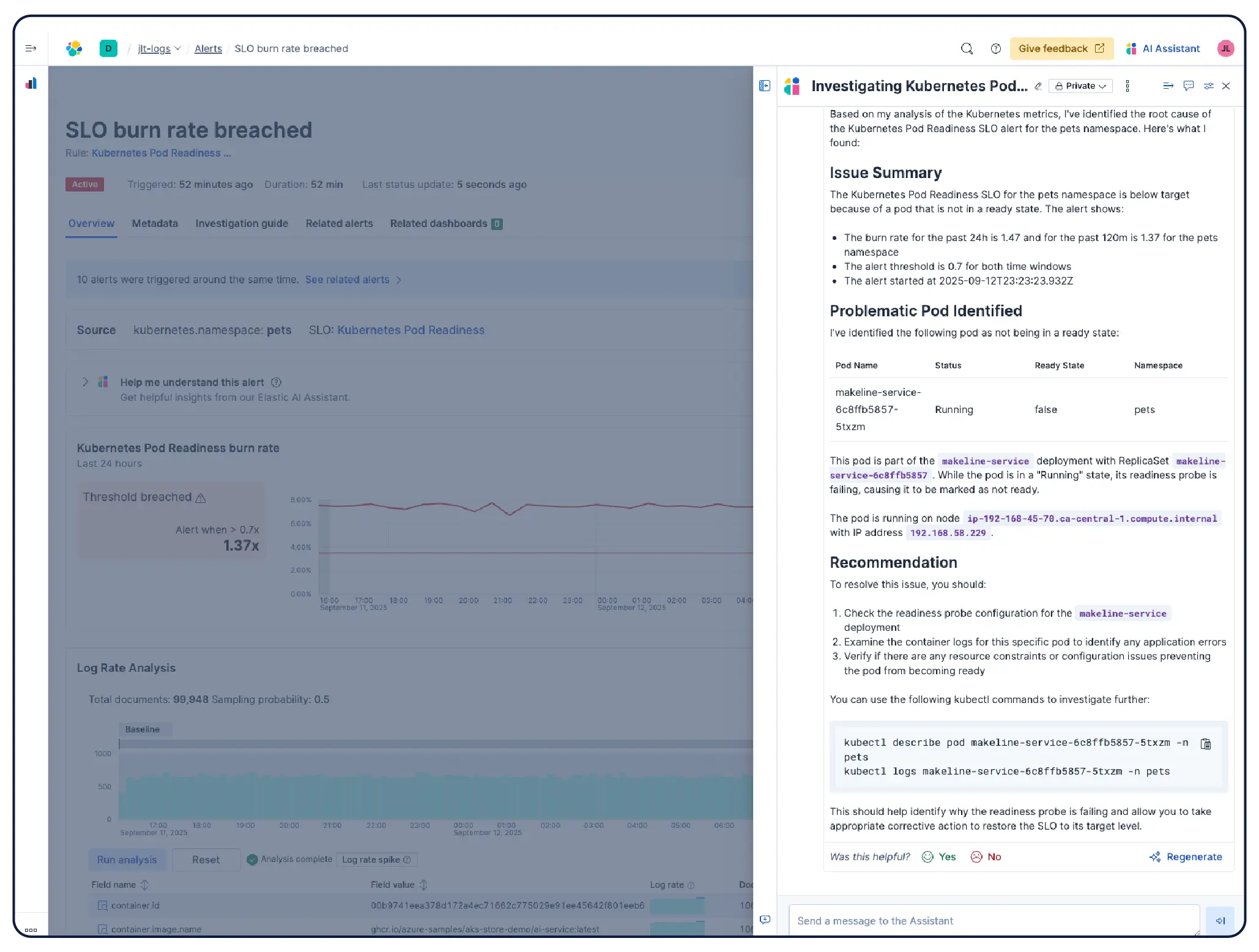
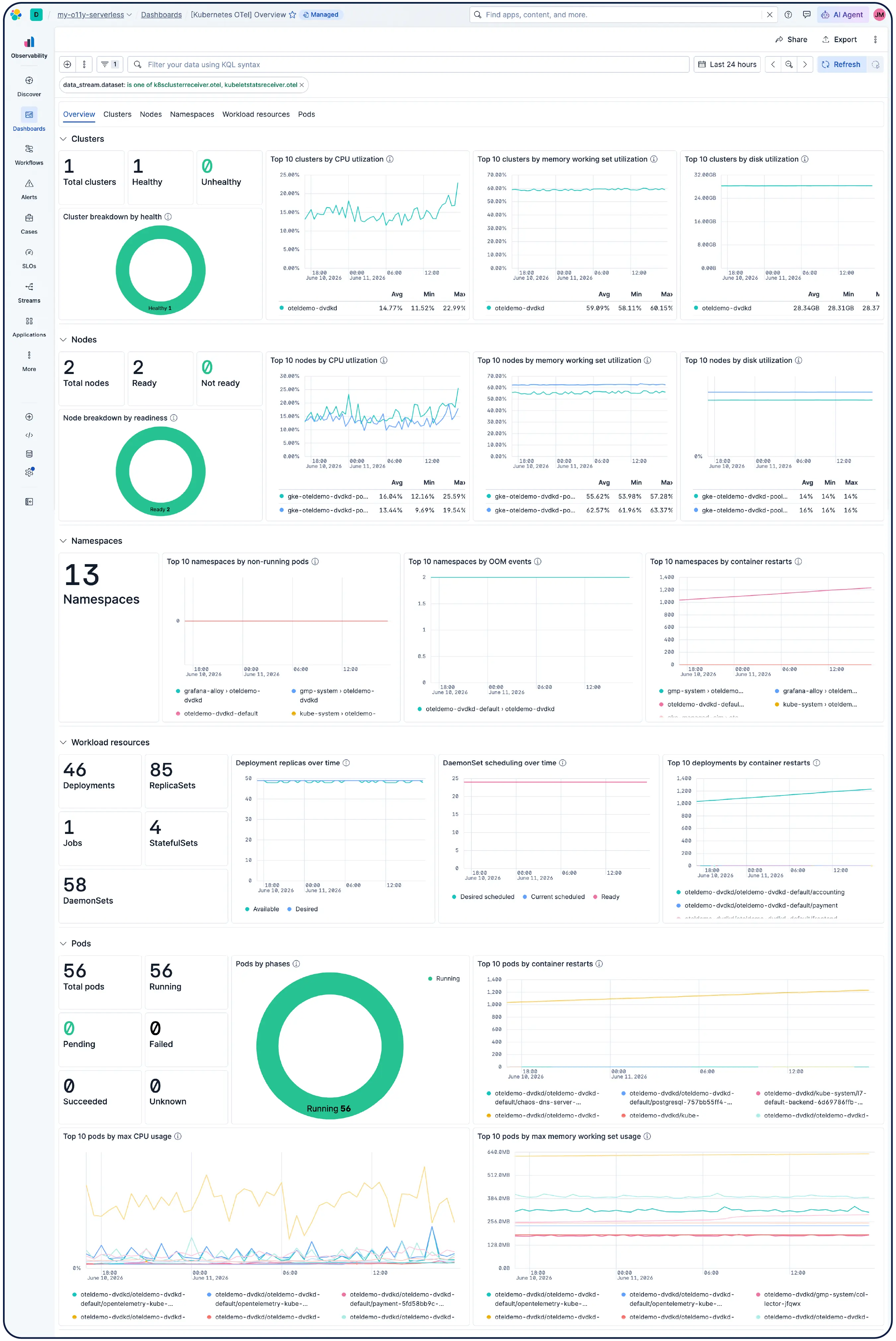
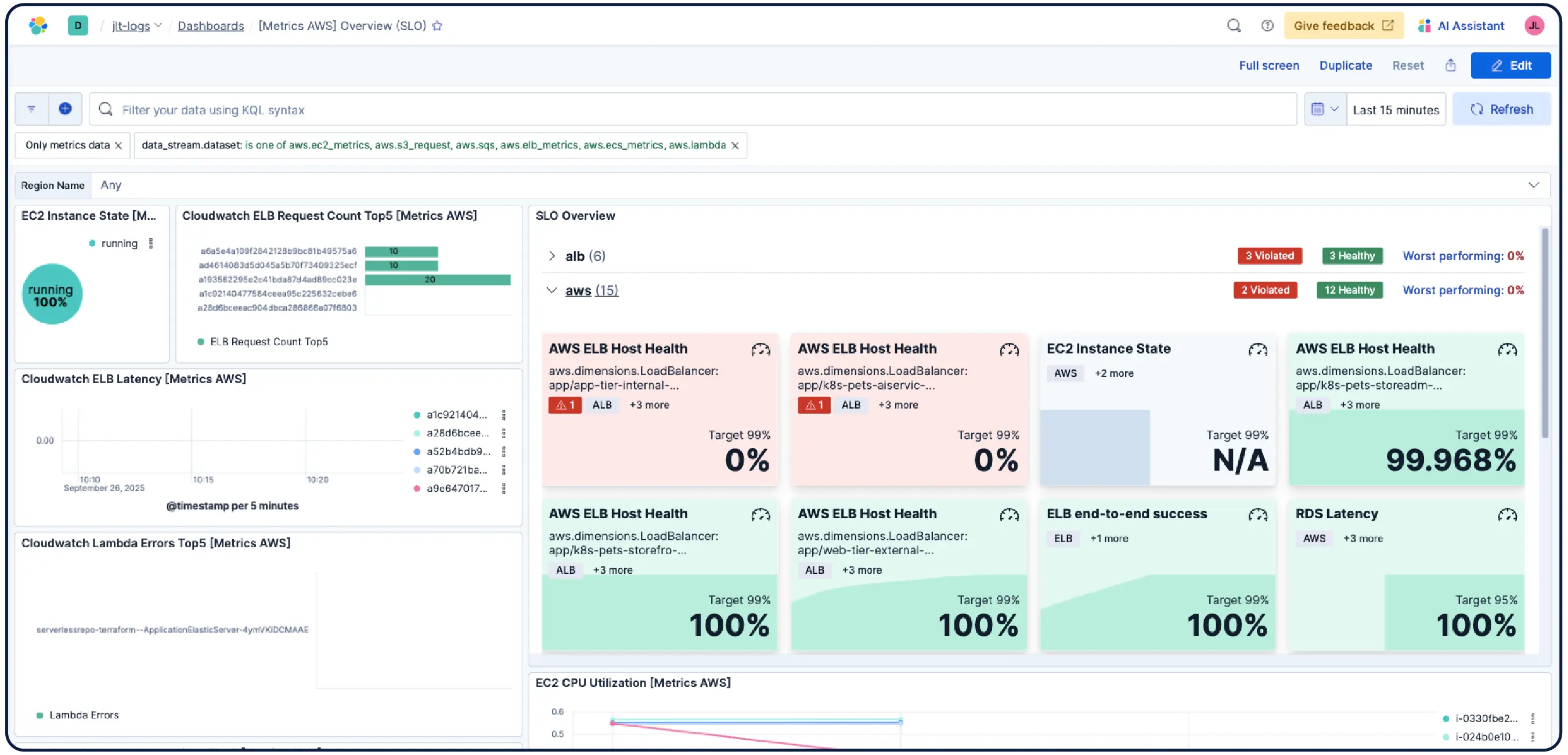
Obtén una configuración funcional lista para usar en el momento en que te conectes. El monitoreo de Kubernetes de Elastic se completa con tableros preconfigurados, alertas, SLO y trabajos de machine learning incluidos, así como habilidades de agente y una aplicación MCP para el monitoreo de salud, la detección de anomalías, investigaciones de incidentes y remediación.

La mejor eficiencia en su clase
Obtén visibilidad completa de la infraestructura y análisis de logs detallados sin comprometer el rendimiento ni perder datos. El motor de métricas columnares de Elasticsearch supera a otros en la velocidad de ingesta, el almacenamiento y la consulta a cualquier escala.
Descubre cómo hemos rediseñado Elasticsearch para convertirlo en un almacén de datos de métricas en formato columnar líder. Consulta los benchmarks.
INDEPENDIENTE DEL ESQUEMA
Un almacén de datos con todos los formatos, sin cambiar de contexto
La mayoría de las plataformas de monitoreo de infraestructura normalizan todo en un solo esquema o te obligan a navegar por varios back ends y lenguajes de búsqueda. Nosotros no. Ya sea que nos envíes OpenTelemetry, Prometheus, Beats o cualquier otro formato, Elasticsearch almacena cada uno de forma nativa en un almacén de datos unificado y lo consulta tal como está. Sin capa de traducción, sin pérdida de información y sin investigaciones manuales ineficientes.
Enfoca tu infraestructura
Ya sea que estés ejecutando clústeres de Kubernetes, máquinas virtuales, cloud o servidores locales, nuestras más de 550 integraciones prediseñadas, agentes ligeros y recopiladores sin agentes para AWS, Azure y GCP hacen que la ingesta sea más fácil.
Busca, filtra, agrega y visualiza datos en Discover. Almacena las sesiones en paneles, configura alertas y ejecuta consultas ES|QL sobre cualquier dato para un análisis unificado. Filtra por cualquier métrica en cualquier dimensión y ejecuta PromQL directamente en Kibana.
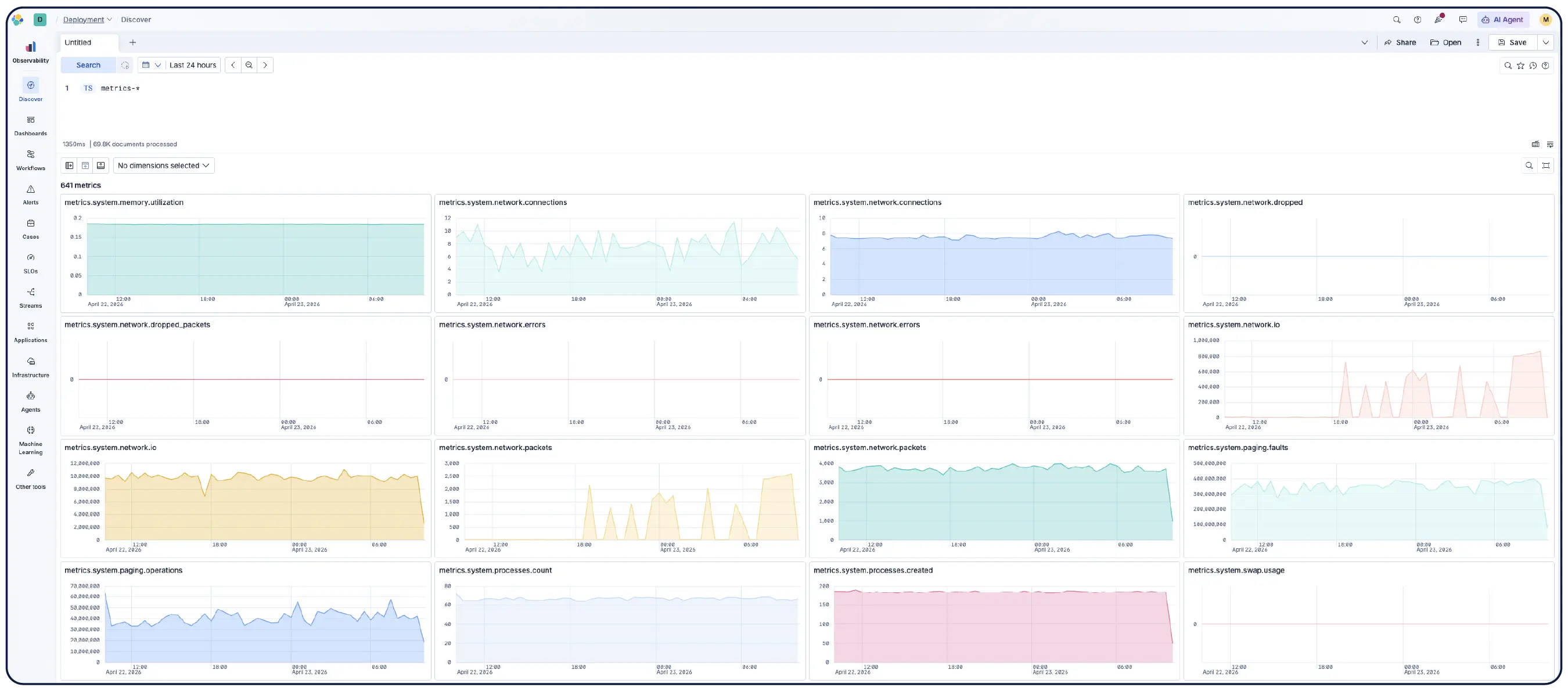
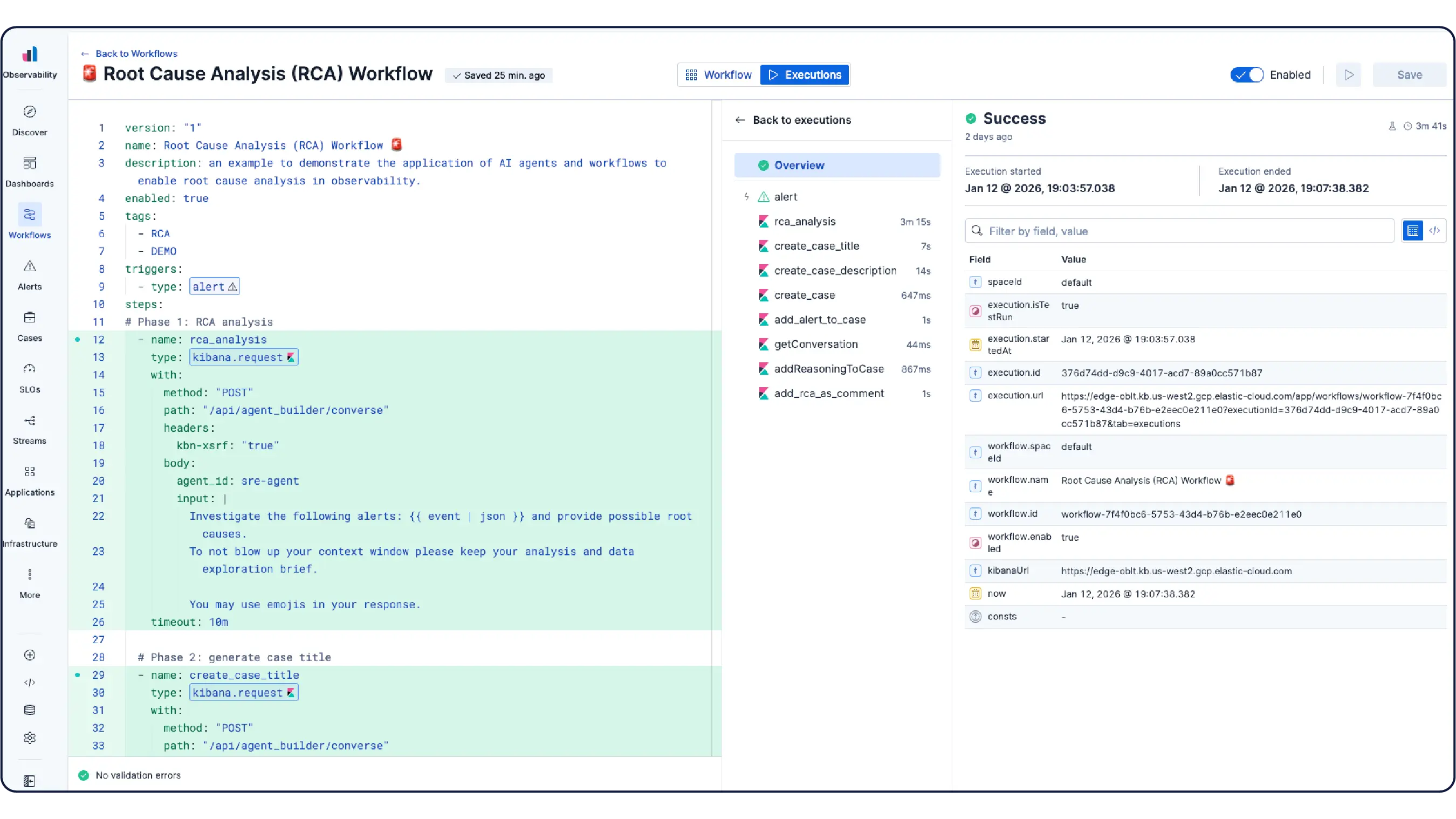
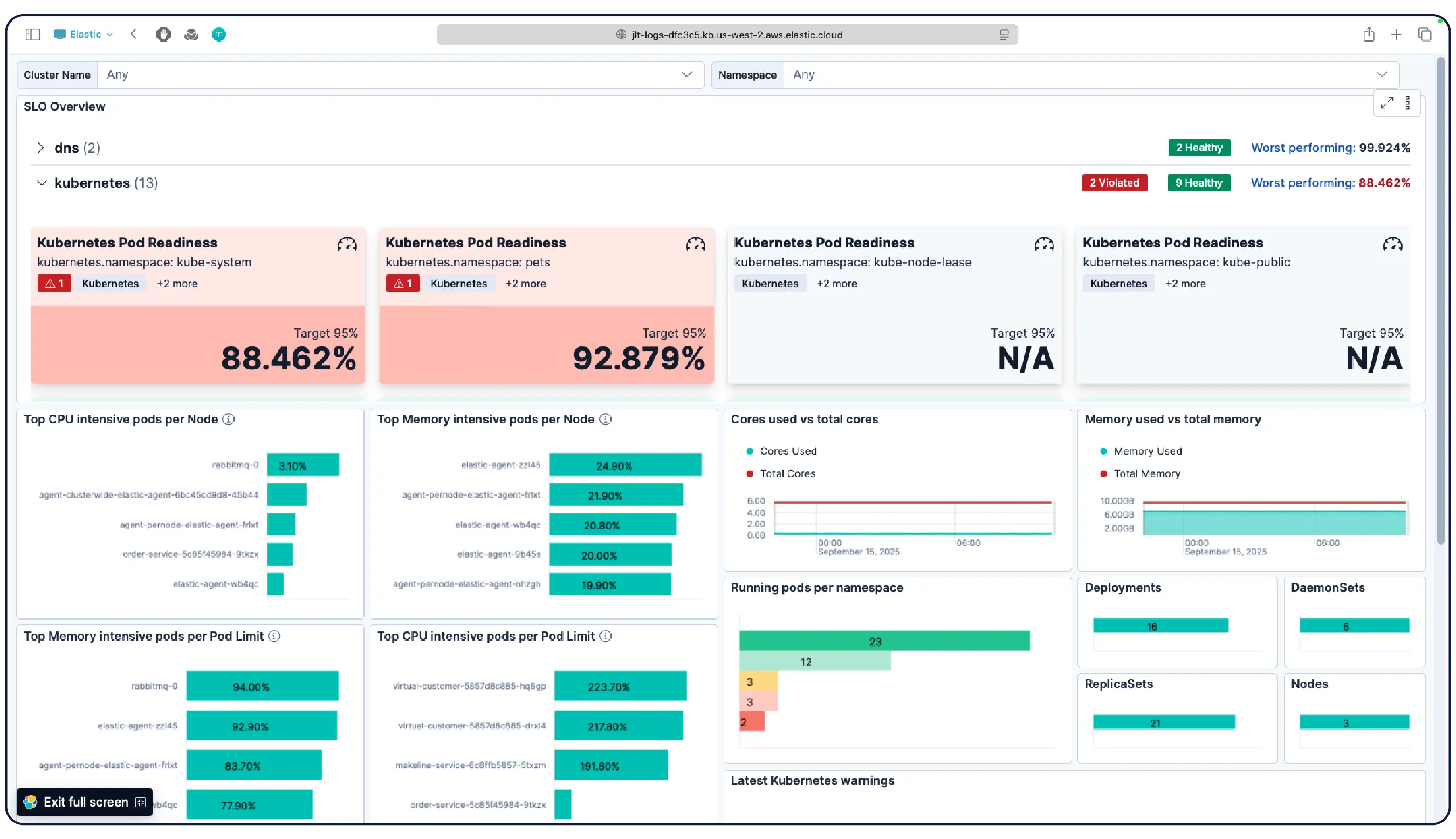
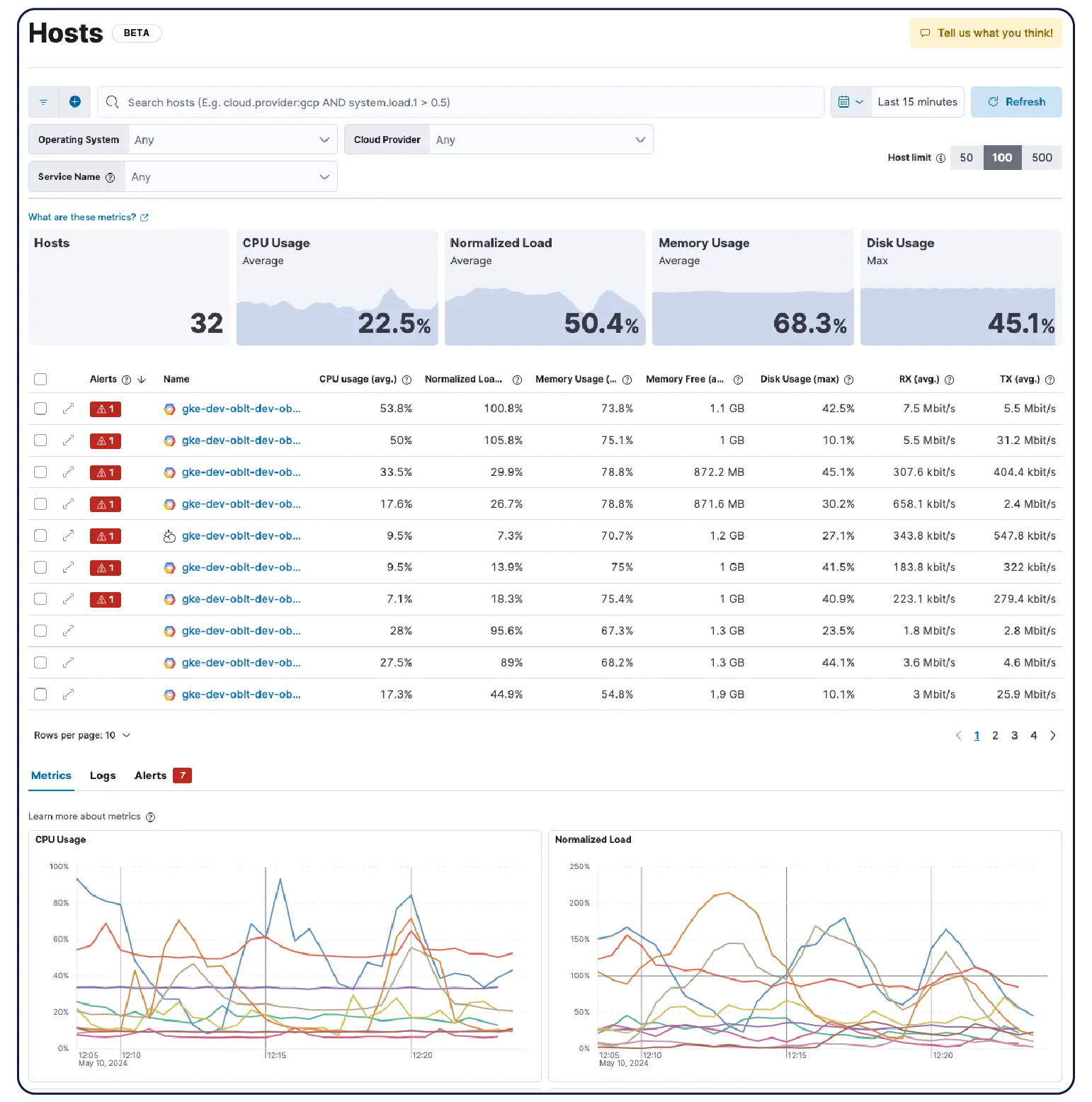
Descubre por qué empresas como la tuya eligen Elastic Observability
Cliente destacado

Comcast ingiere 400 terabytes de datos a diario con Elastic para monitorear los servicios y acelerar el análisis de causa raíz, lo que garantiza una experiencia de cliente de primer nivel.
Cliente destacado

Zooplus usa Elastic para monitorear 2500 microservicios, 20 000 contenedores, 600 cuentas de AWS con 70 servicios de AWS y 40 clústeres de Kubernetes.
Cliente destacado

Informatica redujo costos y el MTTR al migrar toda su carga de trabajo de registro en logs a Elastic para más de 100 aplicaciones y más de 300 clusters de Kubernetes.
Únete al chat
Conéctate a la comunidad global de Elastic y participa en conversaciones abiertas y colaborativas.


.jpg)

Preguntas frecuentes
¿Qué es el monitoreo de infraestructura?
¿Qué es el monitoreo de infraestructura?
El monitoreo de infraestructura rastrea la salud y el rendimiento de los sistemas en los que se ejecutan tus aplicaciones, servidores web, contenedores, instancias en cloud, dispositivos de red, cachés, colas, bases de datos, almacenamiento y más. Recopila métricas como el uso de CPU, el consumo de memoria, la E/S de disco y los reinicios de pods para que los equipos puedan detectar la saturación de recursos, identificar fallas antes de que se agraven y comprender cómo las condiciones de la infraestructura afectan el comportamiento de la aplicación. El monitoreo eficaz de la infraestructura correlaciona esas métricas con los logs y los rastros, para que los ingenieros puedan pasar de "este host está sobrecargado" a la causa raíz sin cambiar de herramientas.
¿Cómo supervisa Elastic la infraestructura?
¿Cómo supervisa Elastic la infraestructura?
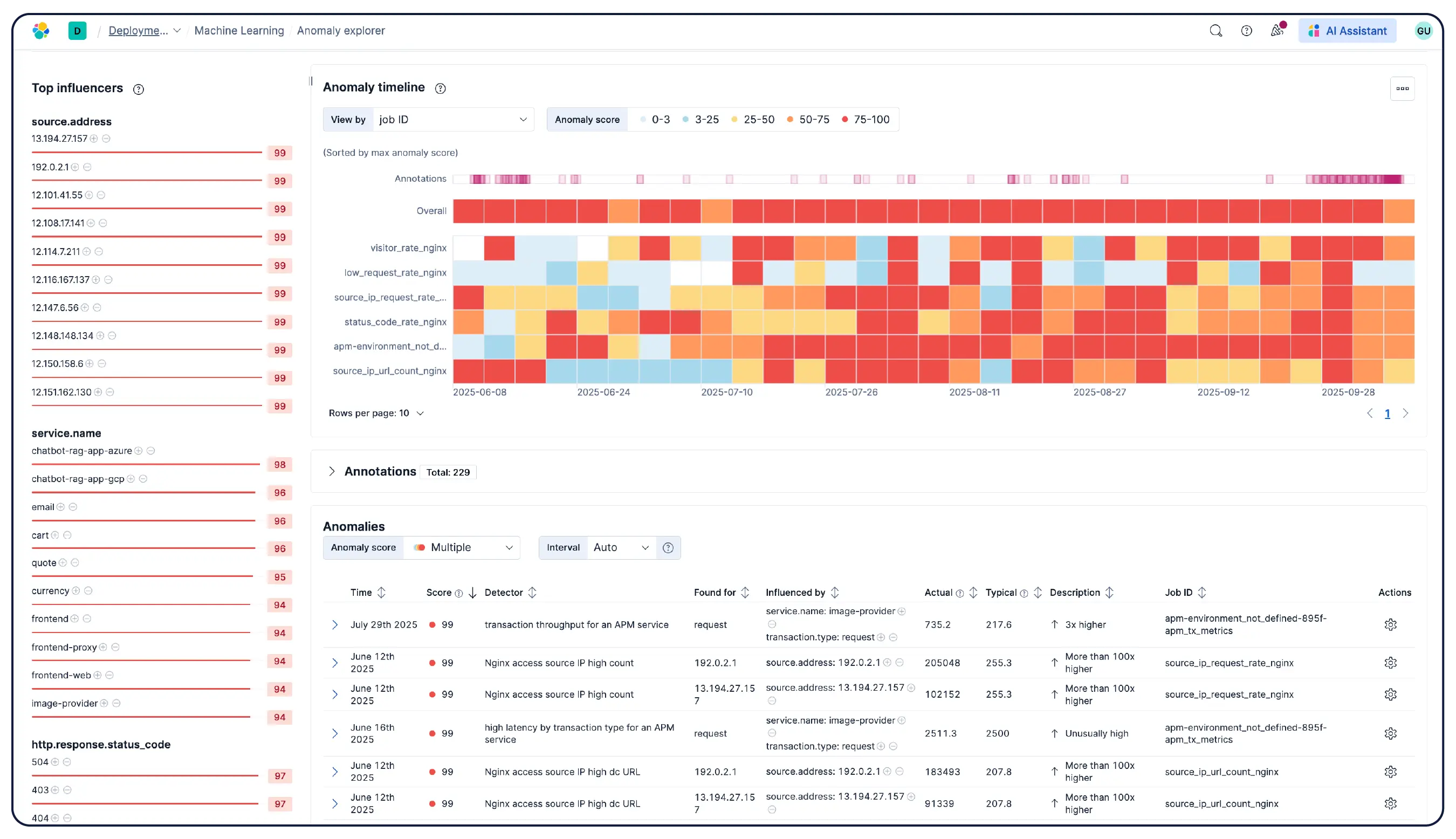
Elastic Observability recopila métricas, logs y rastros de hosts, contenedores, servicios en el cloud y clústeres de Kubernetes y los correlaciona en Elasticsearch para que los equipos puedan investigar a través de señales en un solo lugar. Elastic proporciona visibilidad en el cloud, entornos locales, Kubernetes, serverless y hosts con + de 550 integraciones listas para usar y soporte nativo de OpenTelemetry. Elastic Agent maneja la recopilación de forma centralizada a través de Fleet y no requiere una configuración de agente por host. La detección de anomalías basada en machine learning muestra automáticamente patrones de utilización inusuales y, dado que las métricas de infraestructura coexisten con rastros y logs de aplicaciones, los ingenieros pueden pasar directamente de una alerta al contexto correlacionado sin salir de la platforma.
¿El soporte de Elastic admite la supervisión de Kubernetes?
¿El soporte de Elastic admite la supervisión de Kubernetes?
Sí. Elastic Observability está diseñado para monitorear entornos Kubernetes, incluidos los clústeres administrados en EKS, AKS y GKE, y los clústeres autoadministrados. Elastic descubre automáticamente los cambios en las cargas de trabajo dinámicas de Kubernetes y supervisa los servicios y componentes dondequiera que se ejecuten, con enriquecimiento de metadatos en la ingesta para que puedas filtrar, rastrear e identificar atributos comunes en todo tu sistema. A medida que los pods se inician y detienen, Elastic mantiene el ritmo sin una reconfiguración manual. La utilización de recursos del clúster, los logs a nivel de pod, los rastros de aplicaciones y las métricas de infraestructura se recopilan de un solo despliegue y se correlacionan en Kibana, con detección de anomalías y categorización de logs para detectar problemas que no sabías que debías buscar.
¿Qué formatos de datos admite Elastic?
¿Qué formatos de datos admite Elastic?
Elastic Observability se basa en estándares abiertos. Ingiere de forma nativa el Protocolo OpenTelemetry (OTLP), logs, métricas y rastros, sin conversión de esquema ni traducción propietaria. EDOT, las Distribuciones de Elastic de OpenTelemetry, te proporciona un ecosistema OTel-nativo listo para la producción: instala el Colector EDOT, habilita la instrumentación automática con SDKs de lenguaje y tus datos fluyen hacia Elasticsearch con el esquema OTel intacto. Las métricas de Prometheus y PromQL son compatibles de forma nativa, y + de 450 integraciones de un clic cubren proveedores de cloud, bases de datos, colas de mensajes, dispositivos de red y marcos de trabajo de aplicaciones. Elastic Agent y Beats manejan formatos de logs estructurados y no estructurados de prácticamente todas las fuentes comunes.
¿Cómo reduce Elastic los costos de monitoreo de infraestructura?
¿Cómo reduce Elastic los costos de monitoreo de infraestructura?
Elastic aborda el costo de la observabilidad tanto en las capas de almacenamiento como en las de arquitectura. El modo de índice logsdb puede reducir las necesidades de almacenamiento de logs hasta en un 65 % al optimizar el ordenamiento de datos, eliminar la duplicación con Synthetics _source y mejorar la compresión. Para las métricas, el flujo de datos temporales (TSDS) utilizan almacenamiento columnar y códecs específicos de series temporales, delta de deltas, codificado run-length, codificado XOR para reducir el espacio en disco de las métricas hasta en un 70 % en integraciones como Kubernetes, AWS y Nginx. Para los equipos en Elastic Cloud Serverless, el almacenamiento de objetos nativo de la cloud es el sistema de registro, por lo que todos los datos se almacenan con la economía del almacenamiento de objetos sin necesidad de niveles ni planificación de capacidad.
¿Cómo se compara el precio de las métricas de Elastic con el de la competencia?
¿Cómo se compara el precio de las métricas de Elastic con el de la competencia?
Elastic Observability utiliza precios basados en el consumo, sin tarifas por host ni facturación por pico de uso. La tarifa por host de Datadog factura los eventos de autoescalado al recuento máximo de nodos durante todo el mes, no el uso promedio. Las métricas personalizadas tienen un costo adicional y pueden representar hasta el 52 % de la factura promedio. El modelo de Elastic representa los trabajos efímeros y los entornos de Prometheus de alta cardinalidad que no generan sorpresas al final del mes.