Monitoreo a escala de Kubernetes
Obtén visibilidad en tiempo real de tu ecosistema Kubernetes en entornos EKS, GKE, AKS, entornos locales y aislados. Elastic combina el monitoreo de Kubernetes con el análisis de log más completo del sector y el motor de métricas más rápido, lo que aporta una observabilidad integral basada en IA, escalable y de diseño abierto.

Monitoreo de Kubernetes en todos los lugares donde ya trabajas
Paneles, alertas, SLOs, trabajos de ML, habilidades de agentes para investigaciones y remediación lideradas por IA, y una app MCP, lista en cuanto te conectes. Los agentes de IA identifican anomalías, investigan incidentes y automatizan la remediación para que puedas planificar la capacidad y resolver problemas más rápido.

Rendimiento de alta cardinalidad a una fracción del costo
Elastic Observability elimina las dos razones por las que los SRE buscan una mejor solución de monitoreo de infraestructura: la factura métrica personalizada de Datadog y el trabajo de correlación manual que fuerza la pila fragmentada de Grafana durante cada incidente. Debido a que somos OpenTelemetryprimero y nativos de Prometheus, puedes mantener tus flujos de trabajo favoritos sin sacrificar el rendimiento o la retención.




Monitoreo de Kubernetes en acción
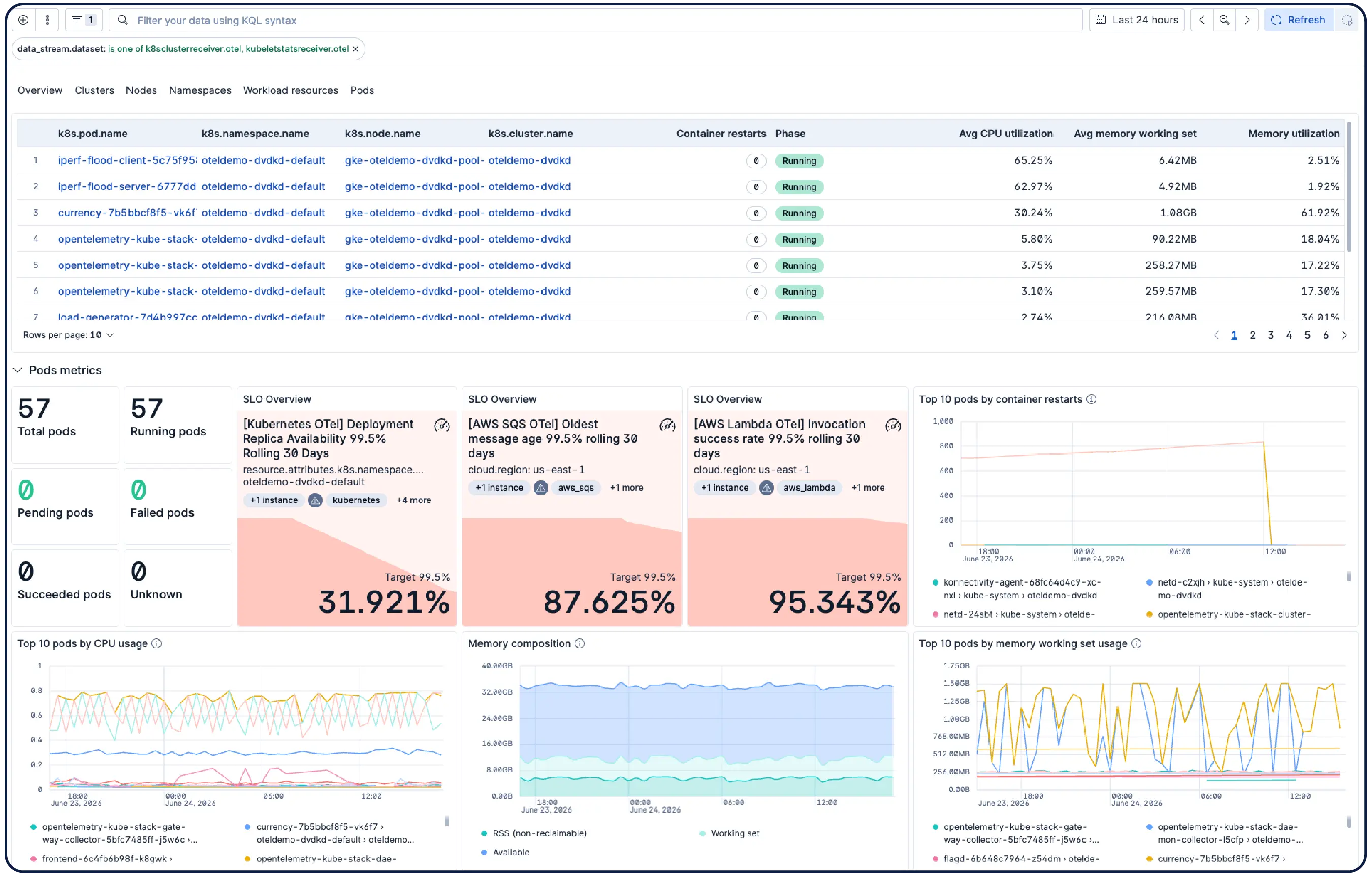
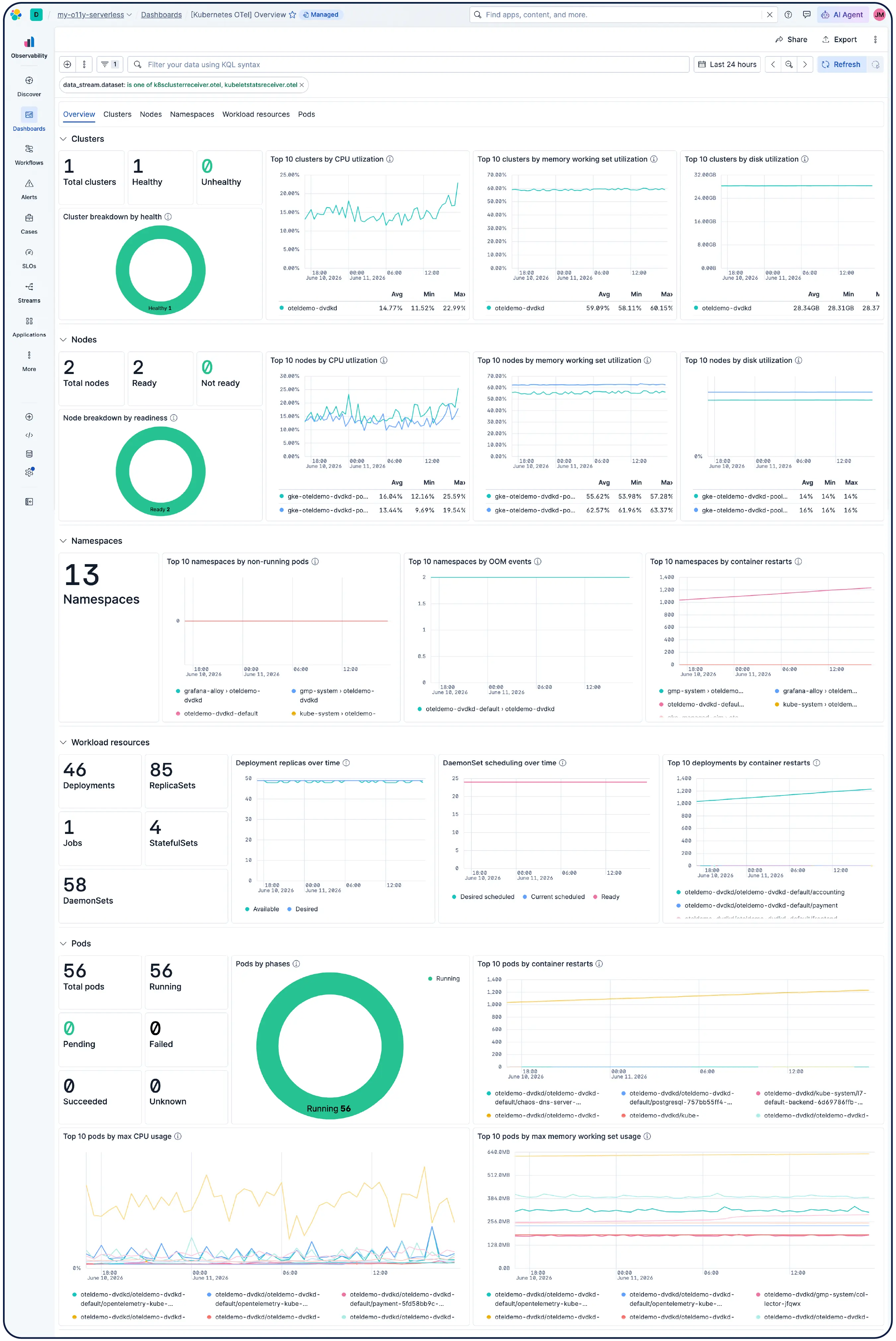
Monitorea tu infraestructura a escala. Las investigaciones lideradas por IA correlacionan señales entre aplicaciones, Kubernetes y capas de nubes para aflorar la causa raíz y sugerir remediación, sin necesidad de excavar manualmente.
Elastic crea automáticamente un modelo que se actualiza de forma constante a partir de tu entorno de Kubernetes: nodos, pods, servicios y dependencias. Da seguimiento a los objetivos de nivel de servicio (SLO) y a los presupuestos de error, y usa la IA basada en agentes para ir del síntoma a la causa raíz sin tener que revisar todos los paneles de control.
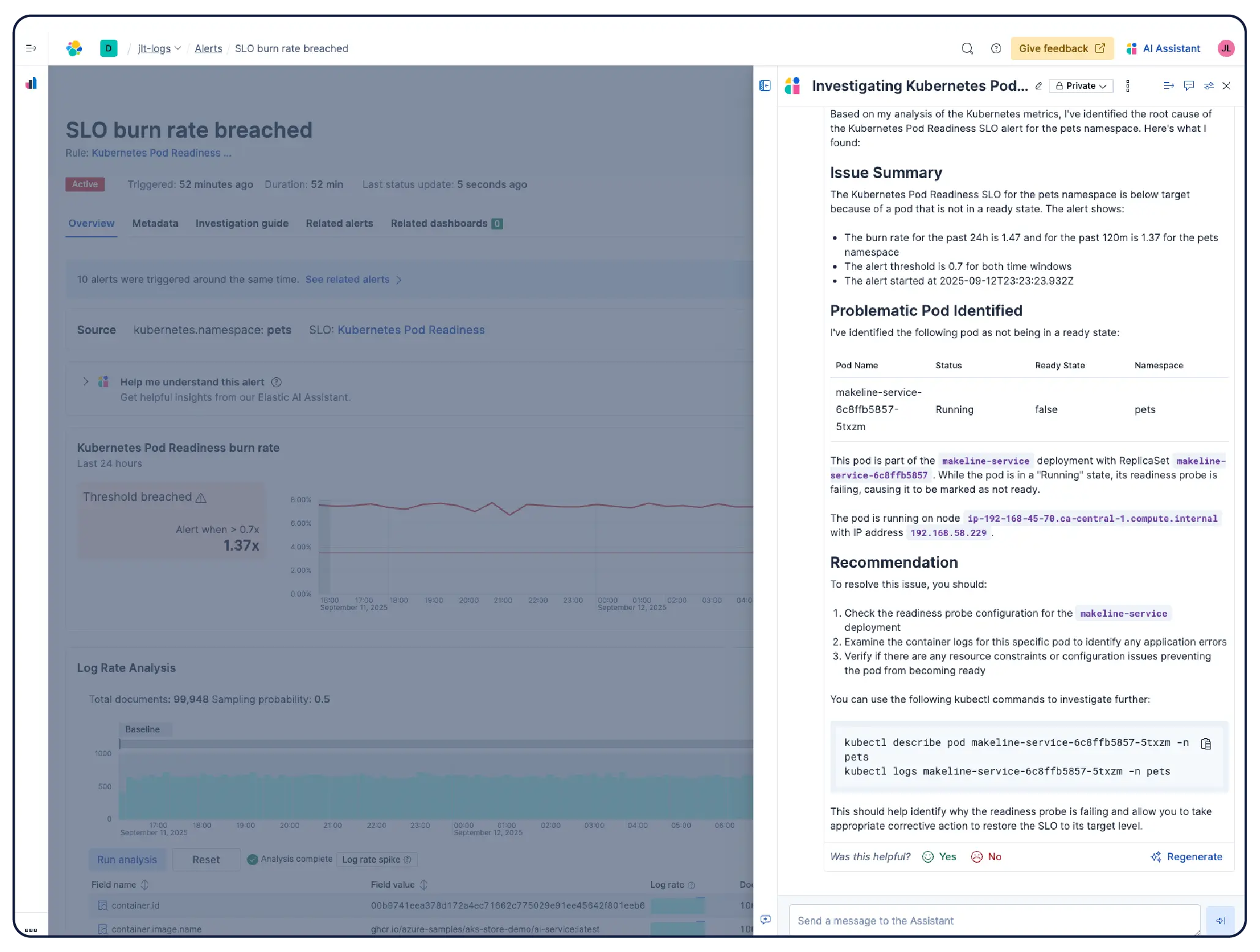
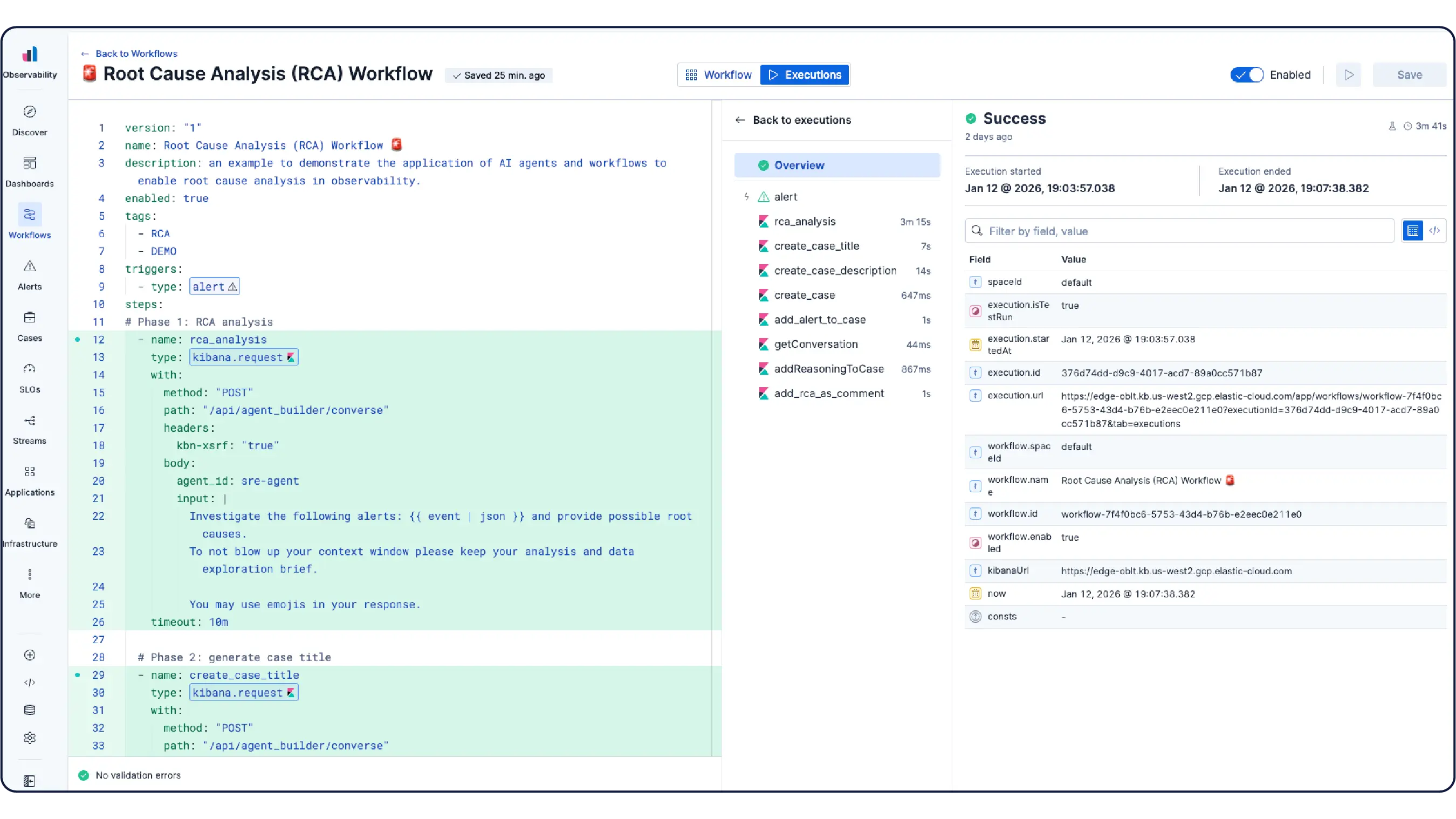
Escala con Kubernetes sin complicaciones
Otras plataformas de monitoreo te hacen elegir entre los datos que necesitas y el costo que puedes pagar. Elastic te ofrece ambas cosas. Obtén visibilidad completa en cada capa de tu clúster de Kubernetes, nodos, el plano de control y las cargas de trabajo, sin la sobrecarga operativa ni compensaciones.
Elastic
Otros proveedores
Precios predecibles con retención a largo plazo en resolución completa: sin penalizaciones por cardinalidad, sin rollup forzados.
La facturación por host es estándar. Cada evento de escalado automático se factura con el número máximo de nodos durante todo el mes, no el uso promedio.
El almacenamiento en columnas en el disco significa que no hay límite de cardinalidad en memoria. Escala a Kubernetes de alta cardinalidad y entornos en el cloud sin límites OOM.
El indexado en memoria significa que los picos de cardinalidad alcanzan los límites de facturación o rendimiento exactamente en el momento equivocado.
Búsqueda de texto en todos los logs de pod y nodos. Encuentra cualquier texto en cualquier log, a cualquier escala. No se requieren etiquetas predefinidas.
La mayoría de los proveedores solo indexan las etiquetas de log. Si no definiste la etiqueta antes del incidente, no podrás realizar una búsqueda de ella.
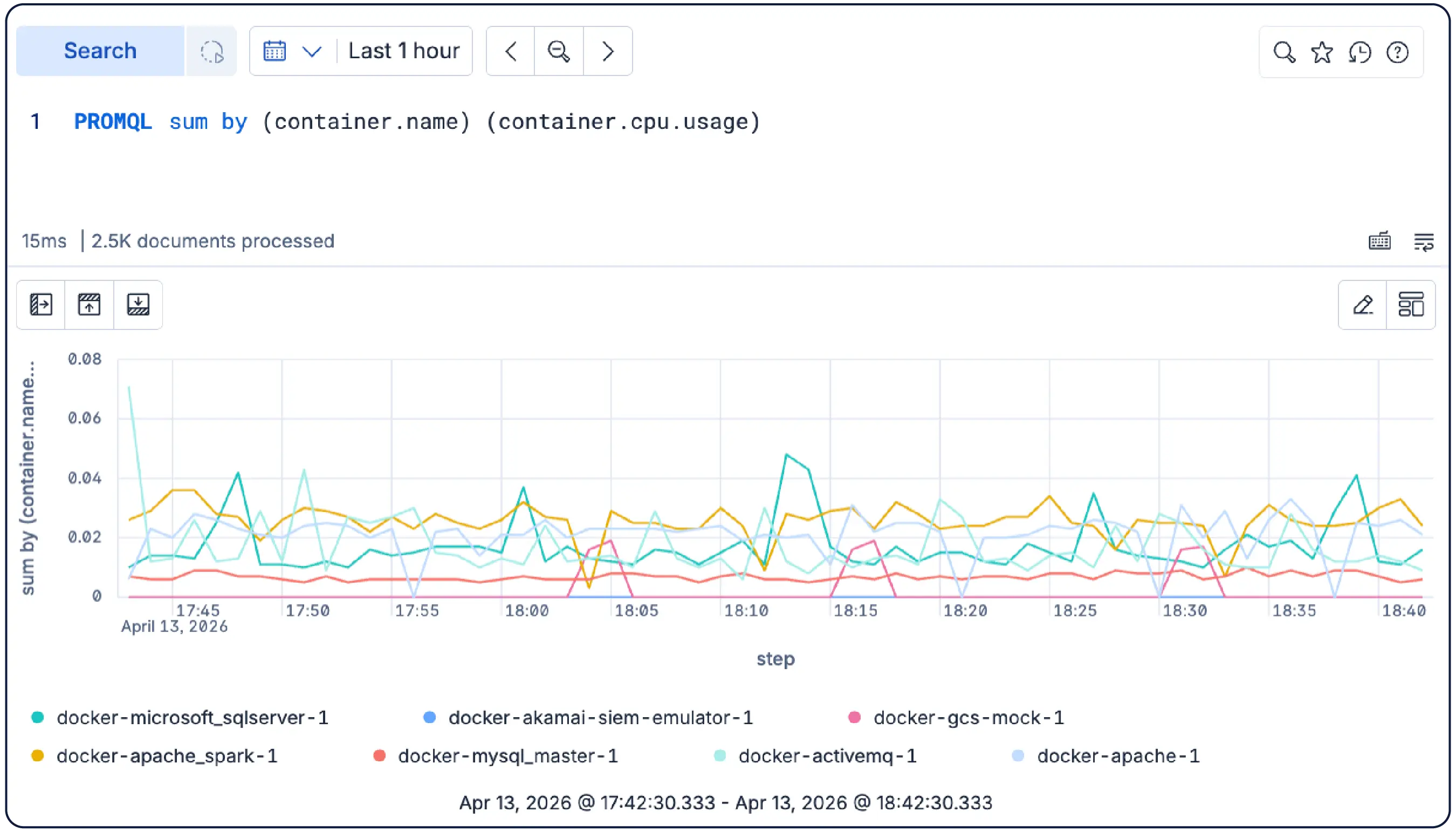
ES|QL consulta registros, métricas y trazas en una sola sentencia. Correlaciona un pico en la CPU del pod con la línea de log que lo causó, sin cambiar de herramientas o idiomas.
Tener lenguajes de búsqueda separados por tipo de señal, uno para log, otro para métricas y otro para trazas, significa cambiar de contexto en el momento exacto en que no puedes permitírtelo.
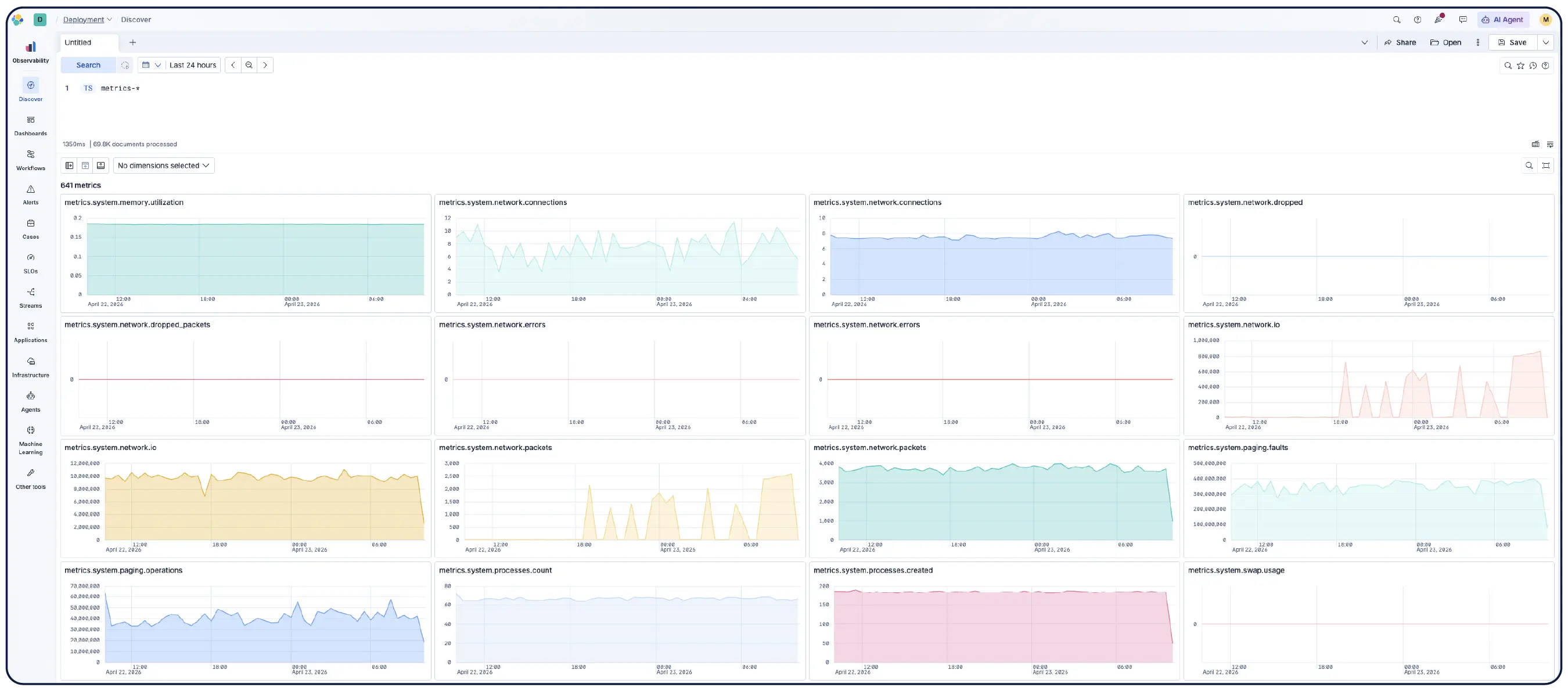
Los log, métricas y trazas tienen ingesta nativa en formato OpenTelemetry. Mantén tu instrumentación actual o usa la distribución totalmente integrada de Elastic para obtener soporte de nivel de producción.
La instrumentación de OTel se enruta a través de back ends propietarios o se factura como métricas personalizadas por encima de una asignación base, lo que penaliza el estándar abierto que tu equipo ya adoptó.
Más de 100 trabajos de ML se ejecutan de forma automática sobre la métrica de Kubernetes y los logs. Es fácil de usar para principiantes y totalmente personalizable para expertos.
La detección de anomalías requiere configuración manual del monitor o se limita a patrones predefinidos.
Elastic Cloud, autogestionado o híbrido , EKS, GKE, AKS, local, aislado. Una plataforma donde se ejecuten tus clústeres.
Muchos proveedores solo ofrecen software como servicio (SaaS). Si tus clústeres se ejecutan de forma local o en un entorno regulado, no tienes opciones antes de empezar la evaluación.
Esquema neutral, open source y construido sobre estándares abiertos , OTel-first, nativo de Prometheus, compatible con PromQL. Almacena tus datos en tu formato preferido y realiza búsquedas tal como están. Sin traducción, sin dependencia.
Los agentes propietarios y los back ends son la norma. Cambiar de proveedor implica volver a configurar todo tu entorno.
La IA analiza tus métricas, logs y trazas para identificar rápidamente las causas raíz y guiar la remediación: no se requiere análisis manual en el dashboard.
La IA suele operar a través de back ends fragmentados en lugar de un almacén de datos unificado de alto rendimiento, lo que limita lo que puede correlacionar y la rapidez con la que puede actuar.
Descubre por qué empresas como la tuya eligen Elastic Observability
Cliente destacado

Comcast ingiere 400 terabytes de datos a diario con Elastic para monitorear los servicios y acelerar el análisis de causa raíz, lo que garantiza una experiencia de cliente de primer nivel.
Cliente destacado

Zooplus usa Elastic para monitorear 2500 microservicios, 20 000 contenedores, 600 cuentas de AWS con 70 servicios de AWS y 40 clústeres de Kubernetes.
Cliente destacado

Informatica redujo costos y el MTTR al migrar toda su carga de trabajo de registro en logs a Elastic para más de 100 aplicaciones y más de 300 clusters de Kubernetes.
Únete al chat
Conéctate a la comunidad global de Elastic y participa en conversaciones abiertas y colaborativas.


.jpg)

Preguntas frecuentes
¿Qué es el monitoreo de Kubernetes?
¿Qué es el monitoreo de Kubernetes?
El monitoreo de Kubernetes realiza un seguimiento del estado y el rendimiento de tu clúster, como nodos, pods, espacios de nombres y las cargas de trabajo que se ejecutan en ellos, mediante métricas, logs y rastros. Cuando algo falla, necesitas encontrar la causa raíz rápidamente en un entorno dinámico y efímero donde los servicios aparecen y desaparecen constantemente.
¿Qué distribuciones de Kubernetes son compatibles con Elastic?
¿Qué distribuciones de Kubernetes son compatibles con Elastic?
Elastic admite KS, AKS, GKE y clústeres autoadministrados con autodescubrimiento dinámico en todos ellos.
¿Por qué la integración de monitoreo de Elastic Kubernetes viene incluida con tantos elementos?
¿Por qué la integración de monitoreo de Elastic Kubernetes viene incluida con tantos elementos?
Porque la parte más difícil del monitoreo de Kubernetes no es conectar tu clúster, sino las horas dedicadas a construir dashboards, escribir reglas de alerta, configurar trabajos de ML y mantener todo a medida que cambia tu clúster. Elastic envía todo eso con la integración, así que estás monitorizando desde el primer día, no desde el último.
¿Cómo ayuda el agente de IA a gestionar los incidentes de Kubernetes?
¿Cómo ayuda el agente de IA a gestionar los incidentes de Kubernetes?
En lugar de correlacionar manualmente los dashboards entre pods, servicios y capas de cloud, los agentes de IA de Elastic analizan automáticamente tu telemetría para investigar problemas, aclarar la causa raíz y ejecutar remediaciones a partir de los modelos de ML y el contexto de tus libros de operaciones y bases de conocimiento.
¿Cómo maneja Elastic las métricas de Kubernetes de alta cardinalidad?
¿Cómo maneja Elastic las métricas de Kubernetes de alta cardinalidad?
Elastic gestiona las métricas de Kubernetes de alta cardinalidad a través de su arquitectura de flujo de datos de series temporales (TSDS), que emplea almacenamiento columnar en disco en lugar de un índice invertido en memoria. A diferencia de los backends basados en Prometheus que sufren OOM cuando la cardinalidad de las etiquetas en pods y espacios de nombres aumenta, Elastic no impone un límite de cardinalidad en memoria. La ingesta de métricas se realiza de forma nativa mediante una escritura remota de Prometheus u OpenTelemetry sin conversión de esquema, y la reducción automática de muestreo controla los costos de almacenamiento a largo plazo, sin sacrificar la precisión de la consulta.
¿Elastic es compatible con kube-state-metrics?
¿Elastic es compatible con kube-state-metrics?
El recolector nativo de OpenTelemetry de Elastic maneja las métricas de estado de Kubernetes de forma inmediata, por lo que no se requieren kube-state-metrics.
¿Cómo se comparan los precios de monitoreo de Kubernetes de Elastic con los de la competencia?
¿Cómo se comparan los precios de monitoreo de Kubernetes de Elastic con los de la competencia?
Elastic Observability utiliza precios basados en el consumo, sin tarifas por host ni facturación por pico de uso. La tarifa por host de Datadog factura los eventos de autoescalado al recuento máximo de nodos durante todo el mes, no el uso promedio. Las métricas personalizadas tienen un costo adicional y pueden representar hasta el 52 % de la factura promedio. El modelo de Elastic representa los trabajos efímeros y los entornos de Prometheus de alta cardinalidad que no generan sorpresas al final del mes.
¿Cómo se ve la migración desde Datadog o Grafana?
¿Cómo se ve la migración desde Datadog o Grafana?
La migración es sencilla gracias a nuestra herramienta de migración (actualmente en vista previa tecnológica), que convierte automáticamente tus paneles de control y reglas de alerta. El soporte nativo de PromQL y OTel significa que tu arquitectura de ingesta existente se conserva. La mayoría de los equipos están completamente operativos al día siguiente.
¿El monitoreo de Elastic Kubernetes incluye seguridad?
¿El monitoreo de Elastic Kubernetes incluye seguridad?
Sí. La integración de Kubernetes Security Posture Management (KSPM) de Elastic evalúa la configuración de tu clúster según las directrices de CIS Benchmarks y genera resultados con instrucciones de remediación paso a paso. Soporta EKS y clústeres autogestionados, evalúa automáticamente cada cuatro horas y está disponible para todos los usuarios de Elastic Cloud, por lo que la misma plataforma que monitorea tu rendimiento también revisa tu postura de seguridad. Además, la integración de Elastic Defend for Containers (D4C) proporciona protección en tiempo de ejecución nativa en la nube para entornos Kubernetes, que utiliza eBPF para monitorear la actividad de procesos y archivos dentro de contenedores en ejecución.