Observabilidad con el Elastic Stack
En mi función como director de productos de observabilidad en Elastic, obtengo algunas reacciones diferentes cuando uso el término “observabilidad”. La reacción más común sigue siendo la siguiente pregunta: “¿Qué es la “observabilidad”?” Pero también escucho cada vez más cosas como: “Acabamos de lanzar una “iniciativa de observabilidad”, pero aún estamos intentando entender cómo hacerlo exactamente”. Y, por último, algunas organizaciones con las que ya hemos tenido la suerte de trabajar consideran la “observabilidad” como una parte fundamental de la manera en que diseñan y crean productos y servicios.
Dado que el término aún está ganando terreno, me pareció que sería útil desmitificar cómo percibimos la “observabilidad” en Elastic, lo que aprendimos de nuestros clientes que estimulan el pensamiento y cómo pensamos en ella desde la perspectiva del producto a medida que elaboramos nuestro stack para casos de uso operativos.
¿Qué es la “observabilidad”?
Definitivamente no inventamos el término “observabilidad”. Comenzamos a escucharlo de los usuarios, principalmente de aquellos en la comunidad de ingeniería de confiabilidad de sitios (SRE). Varias fuentes rastrean el origen de este término a las organizaciones de SRE de gigantes de Silicon Valley como Twitter. Y a pesar de que el fundamental libro SRE de Google no menciona el término, establece muchos de los principios asociados actualmente con la “observabilidad”.
La “observabilidad” no es algo que un proveedor entrega en una caja, es un atributo de un sistema que creas, similar a la facilidad de uso, la alta disponibilidad y la estabilidad. El objetivo de diseñar y crear un sistema “observable” es asegurarse de que cuando se ejecute en producción, los operadores responsables de este puedan detectar comportamientos no deseados (p. ej., tiempo de inactividad del servicio, errores, respuestas lentas) y tengan información procesable para localizar la causa raíz de manera eficaz (p. ej., logs de eventos detallados, información granular de uso de recursos y rastreos de aplicaciones). Los desafíos comunes que hacen que las organizaciones no logren estos objetivos aparentemente obvios incluyen no recopilar suficiente información, recopilar demasiada información (pero no hacerla procesable), y fragmentar el acceso a dicha información.
El primer aspecto, la detección de comportamientos no deseados, generalmente comienza con la configuración de indicadores de nivel de servicio (SLI) y objetivos de nivel de servicio (SLO). Estas son medidas internas de éxito por las cuales se juzga a los sistemas de producción en las organizaciones orientadas a la observabilidad. Si existe una obligación contractual de cumplir estos objetivos, un SLI/SLO también puede traducirse en acuerdos de nivel de servicio (SLA). El ejemplo más común de un SLI es el tiempo de actividad del sistema, para el cual se puede establecer un SLO de 99.9999 %. El tiempo de actividad del sistema también es el SLA más común expuesto a clientes externos. Sin embargo, los SLI/SLO internamente pueden ser mucho más granulares, y el monitoreo y la alerta sobre estos factores más importantes del comportamiento del sistema de producción son la base de cualquier iniciativa de observabilidad. Este aspecto de la observabilidad también se conoce con el término “monitoreo”.
El segundo aspecto, proporcionar a los operadores información granular para depurar problemas de producción de manera rápida y eficiente, es un área en la que vemos mucho movimiento e innovación. Se habla bastante sobre los “tres pilares de la observabilidad”: métricas, logs y rastreos de aplicaciones. También se reconoce que la simple recopilación de todos estos datos granulares mediante una amalgama de herramientas no es necesariamente procesable y, a menudo, no es rentable.
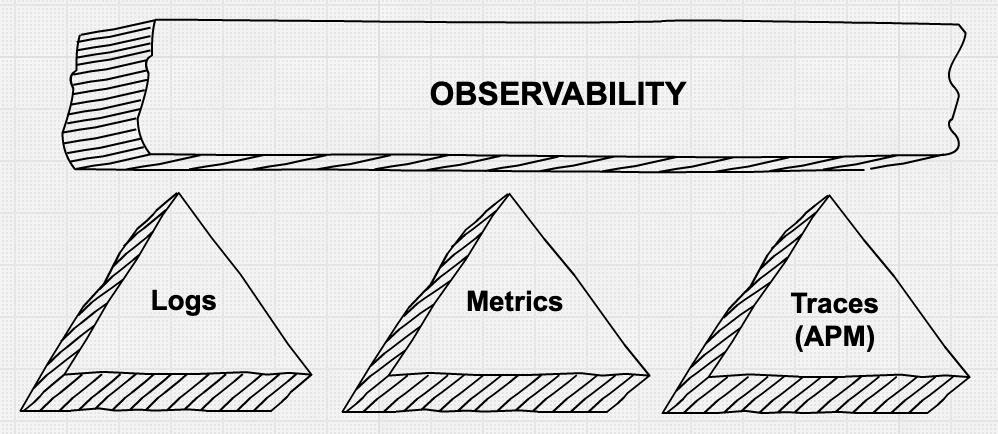
Los “pilares” de la observabilidad
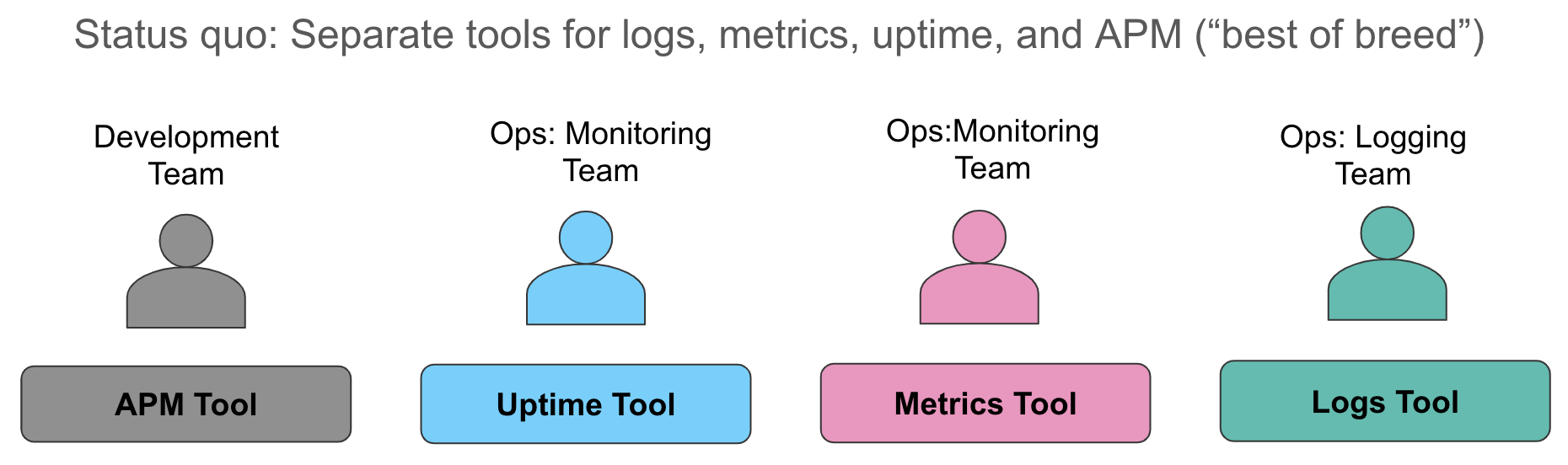
Examinemos estos aspectos de la recopilación de datos con más detalle. El estado actual que normalmente encontramos hoy en día es recopilar métricas en un sistema (generalmente una base de datos temporales o un servicio SaaS para el monitoreo de recursos), recopilar logs en un segundo sistema (como es de esperar, a menudo el ELK Stack en nuestras conversaciones) y usar una tercera herramienta para instrumentar aplicaciones a fin de proporcionar un rastreado a nivel de solicitud. Cuando se dispara una alerta, lo que indica una vulneración en un nivel de servicio, los operadores se lanzan locamente a sus sistemas y realizan la mejor integración repetitiva que pueden hacer: mirar las métricas en una ventana del navegador, correlacionarlas manualmente con los logs en otra ventana, y extraer los rastreos (si es relevante) en una tercera ventana.
Este enfoque tiene varias desventajas. En primer lugar, la correlación manual de diferentes fuentes de datos que cuentan la misma historia desperdicia tiempo valioso durante la degradación o interrupción del servicio. En segundo lugar, los costos operativos de mantener tres almacenes de datos operativos diferentes son altos: costos de licencias, personal separado para los administradores de herramientas operativas dispares, capacidades de aprendizaje automático inconsistentes en cada almacén de datos, “espacio vacío” para pensar en diferentes semánticas para las alertas, etc.; cada una de las organizaciones con las que hablo tienen dificultades con todos estos desafíos.
Se reconoce cada vez más lo importante que es tener toda esta información en un solo almacén operativo con la capacidad de correlacionar automáticamente estos datos en una interfaz de usuario intuitiva. El nirvana para los usuarios con los que hablamos es exponer a sus operadores a cada dato relevante para el servicio al que están brindando soporte de manera unificada, ya sea una línea de log emitida por la aplicación, los datos de rastreo resultantes de la instrumentación o el uso de recursos representado por métricas en una serie temporal. Los requisitos que escuchamos enfatizan el acceso uniforme ad hoc a estos datos, independientemente de la fuente, desde la búsqueda y el filtrado hasta las agregaciones y las visualizaciones. Comenzar con métricas y desglosar logs y rastreos en unos pocos clics sin cambiar el contexto acelera las investigaciones. Del mismo modo, la extracción de valores numéricos de logs estructurados se parece sorprendentemente a las métricas y la visualización de ambos lado a lado tiene un gran valor desde una perspectiva operativa.
Como se mencionó anteriormente, la simple recopilación de los datos puede generar demasiada información en el disco y una falta de suficiente inteligencia procesable cuando ocurre un incidente. De manera creciente, existe la expectativa de que el sistema que recopila datos operativos proporcione la detección automática de eventos, rastreos y anomalías “interesantes” en los patrones de series temporales. Esto ayuda a los operadores que investigan un problema a concentrarse más rápidamente en la causa raíz. Estas capacidades de detección de anomalías a veces se conocen como el “cuarto pilar de la observabilidad”. Detectar anomalías en los datos de tiempo de actividad, el uso de recursos y los patrones de logs, así como los rastreos más relevantes, es un requisito emergente que los equipos de observabilidad proponen.
Observabilidad… ¿y el ELK Stack?
Entonces, ¿qué tiene que ver la observabilidad con el Elastic Stack (o el ELK Stack, como se lo denomina cariñosamente en algunos entornos)?
Al ELK Stack se lo conoce ampliamente como la manera de centralizar en la práctica los logs de los sistemas operativos. Se parte de la base de que Elasticsearch (un “motor de búsqueda”) es un buen lugar para colocar logs basados en texto con el fin de realizar búsquedas de texto libre. Y, de hecho, la simple búsqueda de logs basados en texto para la palabra “error” o el filtrado de logs en función de un conjunto de etiquetas conocidas es extremadamente potente y es a menudo donde la mayoría de los usuarios comienzan.
Sin embargo, como sabe la mayoría de los usuarios del ELK Stack, Elasticsearch como almacén de datos ofrece mucho más que un índice invertido para una búsqueda eficiente de texto completo y capacidades de filtrado simples. También contiene un almacén basado en columnas y optimizado para almacenar series temporales numéricas densas y operar en estas. Este almacén se usa para almacenar datos de estructura extraídos de logs parseados, tanto de texto como numéricos. De hecho, el caso de uso de la conversión de logs a métricas fue lo que inicialmente nos llevó a optimizar Elasticsearch para un almacenamiento y una recuperación de números eficientes.
Con el tiempo, los usuarios comenzaron a colocar las series temporales numéricas directamente en Elasticsearch, en reemplazo de las bases de datos temporales. Impulsado por esta necesidad, Elastic introdujo recientemente Metricbeat para la recopilación automatizada de métricas, el concepto de elementos consolidados automáticos y otras funciones específicas de las métricas, tanto en el almacén de datos como en la UI. Como resultado, cada vez más usuarios que han adoptado el ELK Stack para los logs también han comenzado a colocar datos de métricas, como el uso de recursos, en el Elastic Stack. Además de los ahorros operativos ya mencionados anteriormente, una razón atractiva para hacer esto fue la falta de restricciones que Elasticsearch coloca en la cardinalidad de los campos elegibles para agregaciones numéricas (una queja común planteada al analizar muchas bases de datos temporales existentes).
Al igual que las métricas, los datos de tiempo de actividad han sido un tipo de datos muy valioso junto con los logs, de modo que representan una fuente importante de alertas de SLO/SLI de un monitor activo. Los datos de tiempo de actividad pueden proporcionar información sobre la degradación de los servicios, las API y los sitios web, muchas veces antes de que los usuarios sientan el impacto. La ventaja es que los datos de tiempo de actividad son pequeños en términos de requisitos de almacenamiento, por lo que son de gran valor y tienen un costo adicional muy bajo.
En el último año, Elastic también introdujo Elastic APM, que agregó capacidades de rastreado de aplicaciones y rastreado distribuido al stack. Esta fue una evolución natural para nosotros, ya que varios proyectos de código abierto y destacados proveedores de APM ya estaban usando Elasticsearch para almacenar y buscar datos de rastreo. El estado actual de las herramientas de APM tradicionales consiste en mantener los datos de rastreo de APM separados de los logs y las métricas, lo que perpetúa los silos de datos operativos. Elastic APM ofrece un conjunto de agentes para recopilar datos de rastreo a partir de lenguajes y marcos de trabajo compatibles, además de ser compatible con OpenTracing, y estos datos de rastreo se correlacionan automáticamente con las métricas y los logs.
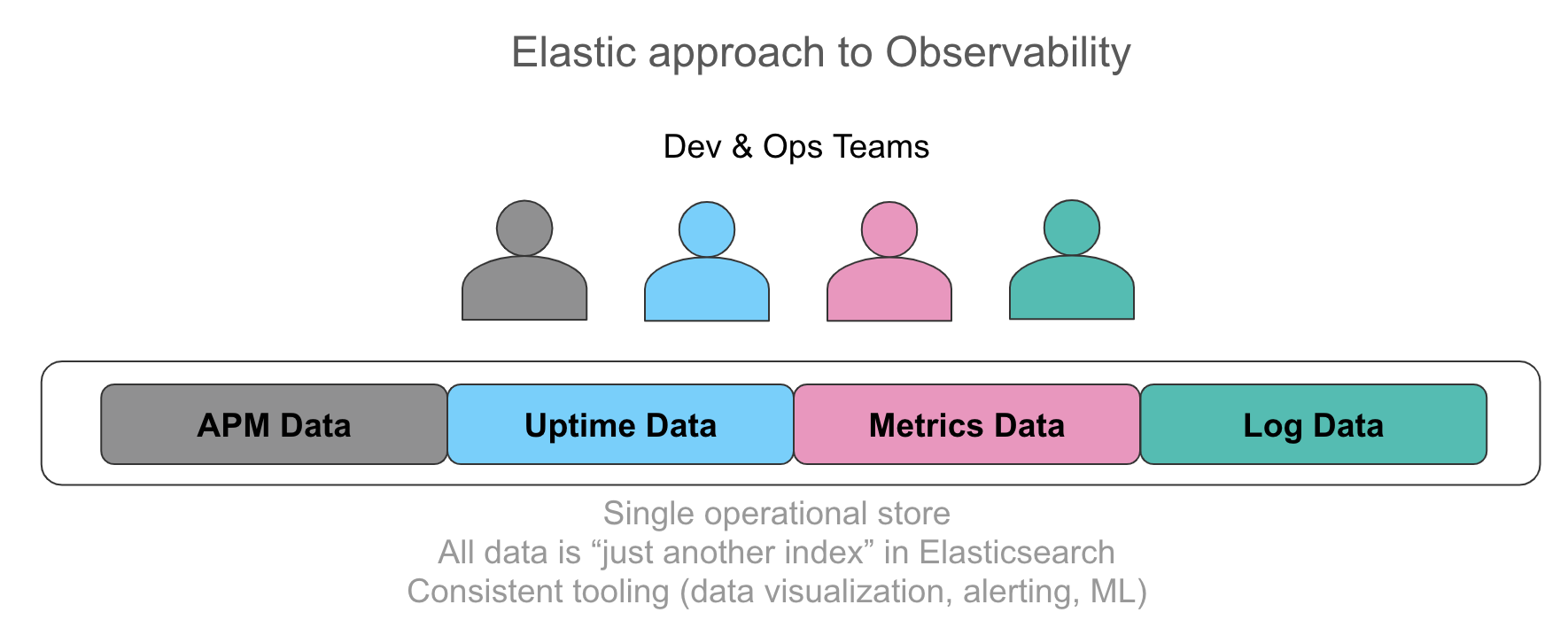
Un hilo común en todas estas entradas de datos es que cada una de ellas es solo otro índice en Elasticsearch. No hay restricciones en las agregaciones que se ejecutan en todos estos datos, cómo se visualizan en Kibana y cómo se aplican las alertas y el aprendizaje automático a cada fuente de datos. Para ver esto en acción, mira este video.
Kubernetes observables y el Elastic Stack
Una comunidad en la cual el concepto de observabilidad es un tema de conversación muy activo es el conjunto de usuarios que adoptan Kubernetes para la orquestación de contenedores. Estos usuarios “nativos en la nube”, un término popularizado por la Cloud Native Computing Foundation (o CNCF), enfrentan desafíos únicos. Se enfrentan a una centralización masiva de aplicaciones y servicios creados o migrados a una plataforma de orquestación de contenedores impulsada por Kubernetes, junto con la tendencia a dividir las aplicaciones monolíticas en “microservicios”. Las herramientas y los métodos que funcionaban antes para proporcionar la visibilidad necesaria en las aplicaciones que se ejecutan sobre esta infraestructura ya no funcionan.
La observabilidad de Kubernetes merece una publicación aparte, por lo que, por ahora, te remitiré al seminario web Kubernetes observables y al blog Rastreado distribuido con Elastic APM para obtener más información.
¿Qué sigue?
En una publicación como esta, parece apropiado proporcionarle al lector algunos recursos para explorar.
Para obtener más información sobre las mejores prácticas de observabilidad, recomiendo comenzar con el libro SRE de Google mencionado anteriormente. Los blogs de compañías cuyo sustento depende del funcionamiento impecable de sus aplicaciones primordiales en la producción también suelen dar mucho para pensar. Por ejemplo, creo que esta publicación reciente de la ingeniería de Salesforce es una guía práctica y pragmática para mejorar iterativamente el estado de observabilidad.
Para probar las capacidades del Elastic Stack para tus iniciativas de observación, activa la última versión de nuestro Stack en el Elasticsearch Serviceen la Elastic Cloud (un gran entorno para realizar pruebas, incluso si en última instancia despliegas la gestión automática), o descarga e instala los componentes del Elastic Stack localmente. Asegúrate de probar las nuevas interfaces de usuario de logs, infraestructura monitoreo, APM y tiempo de actividad (próximamente en la versión 6.7) en Kibana, diseñadas específicamente para flujos de trabajo de observabilidad comunes. Y no dudes en enviarnos preguntas en los foros de debate, ¡estamos para ayudarte!