Monitoreo de infraestructura y microservicios con Elastic Observability
Las tendencias en el espacio de infraestructura y software han cambiado la forma en que creamos y ejecutamos software. Como resultado, comenzamos a tratar nuestra infraestructura como código, lo que nos ha ayudado a bajar los costos y lanzar nuestros productos al mercado con más rapidez. Estas arquitecturas nuevas también nos dan la posibilidad de probar más rápido el software en despliegues similares a la producción y, en general, de ofrecer despliegues más estables y reproducibles. Sin embargo, la otra cara de estas mejoras es la mayor complejidad de nuestros entornos, especialmente en relación con el monitoreo efectivo de infraestructuras nuevas.
En este blog, hablaremos sobre “lo indispensable” para monitorear tu pila de aplicaciones completa, incluidas las aplicaciones personalizadas, los servicios y la infraestructura en la que se ejecutan. También mostraremos cómo la solución Elastic Observability y el Elastic Stack pueden ayudar a satisfacer esas necesidades y a crear la plataforma de monitoreo definitiva para aumentar la observabilidad y reducir el tiempo de inactividad. Cuando estés listo, puedes iniciar una prueba gratuita en Elastic Cloud o descargar la versión más reciente de nuestro sitio web para comenzar.
Arquitecturas que evolucionan: El viaje hacia los contenedores y microservicios
¿Cómo llegamos aquí? El espacio del software de infraestructura está evolucionando muy rápido. Desde la perspectiva de hardware, pasamos de máquinas físicas a usar varias herramientas de virtualización (o hipervisores) y después vimos el surgimiento de las infraestructuras de cloud público que nos abrieron paso para terciarizar el mantenimiento y provisionamiento de parte de los servidores y las redes, lo que nos ayudó a reducir el tiempo de creación de valor. Aún recuerdo cuando debíamos esperar durante semanas para que se provisionara un servidor nuevo y poder ponernos a trabajar en nuestros proyectos. Quizá algunos todavía lo hacen, pero ese problema ya está resuelto. En la actualidad son las plataformas de contenedores (orquestadores de contenedores como Docker y Kubernetes) las que se están convirtiendo en las preferidas de muchas organizaciones. Por supuesto, muchas de esas mismas organizaciones también usan la virtualización en hosts de metal expuesto.
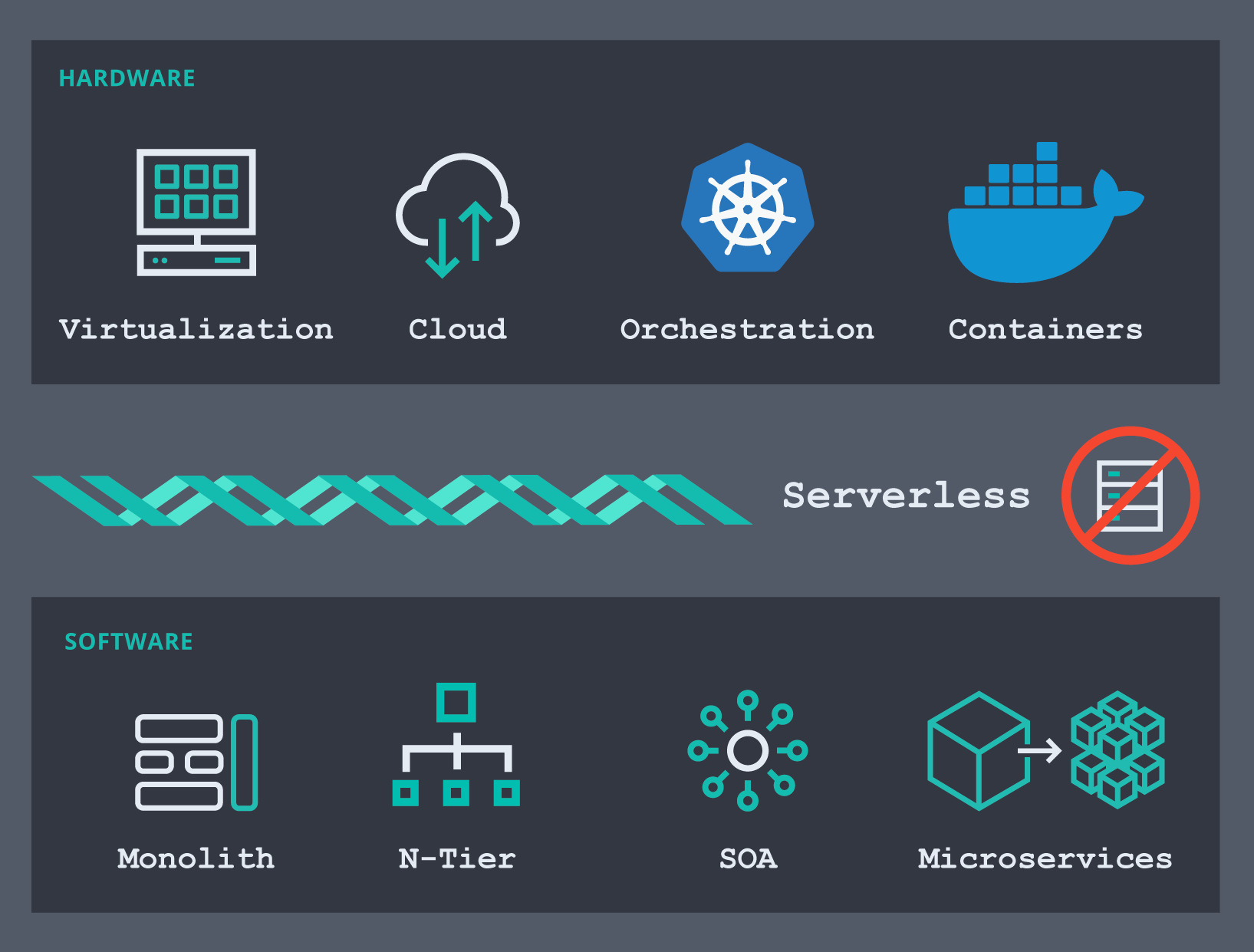
Del lado del software en esta línea de tiempo, pasamos de crear monolitos a desacoplarlos en varias capas (presentación, aplicación, datos, etc.). Después, las arquitecturas orientadas al servicio (SOA) se convirtieron en el patrón de diseño dominante y, a su vez, evolucionaron de diferentes formas: servicios web, arquitecturas impulsadas por eventos y, por supuesto, el tipo más reciente, microservicios. Hoy, si quieres crear una aplicación nueva, probablemente se basará en microservicios que se ejecutan en pods en Kubernetes, en alguna parte en el cloud. Es probable que actualmente tu organización tenga una o más iniciativas para derribar los antiguos monolitos, convertirlos en microservicios y usar un orquestador para desplegarlos.
En consecuencia, nuestras pilas ahora tienen más componentes para monitorear y nuestras herramientas de monitoreo deben hacer un seguimiento de las aplicaciones que se mueven constantemente con los contenedores que aparecen y desaparecen a gran velocidad. El monitoreo de entornos modernos creó la necesidad de un enfoque completamente nuevo.
Monitoreo de infraestructura: Requisitos para complejidades modernas
Cuando hablamos de los entornos de despliegue actuales, debemos considerar varios elementos. Está la infraestructura sobre la que se ejecuta todo, ya sean centros de datos en las instalaciones, infraestructura de cloud público o una combinación híbrida. Cualquier entorno típico actual tiene una capa de orquestación (por ejemplo, Kubernetes) que automatiza el despliegue y escalado de las aplicaciones. Están los elementos sobre o en los que se ejecutan las apps, como contenedores, VM o metal expuesto. Cuando desarrollamos aplicaciones, introducimos dependencias en sistemas de terceros, como servicios externos, bases de datos o componentes escritos por otros equipos de la organización. Y, por supuesto, las aplicaciones en sí; tanto los componentes internos como la experiencia del usuario final.
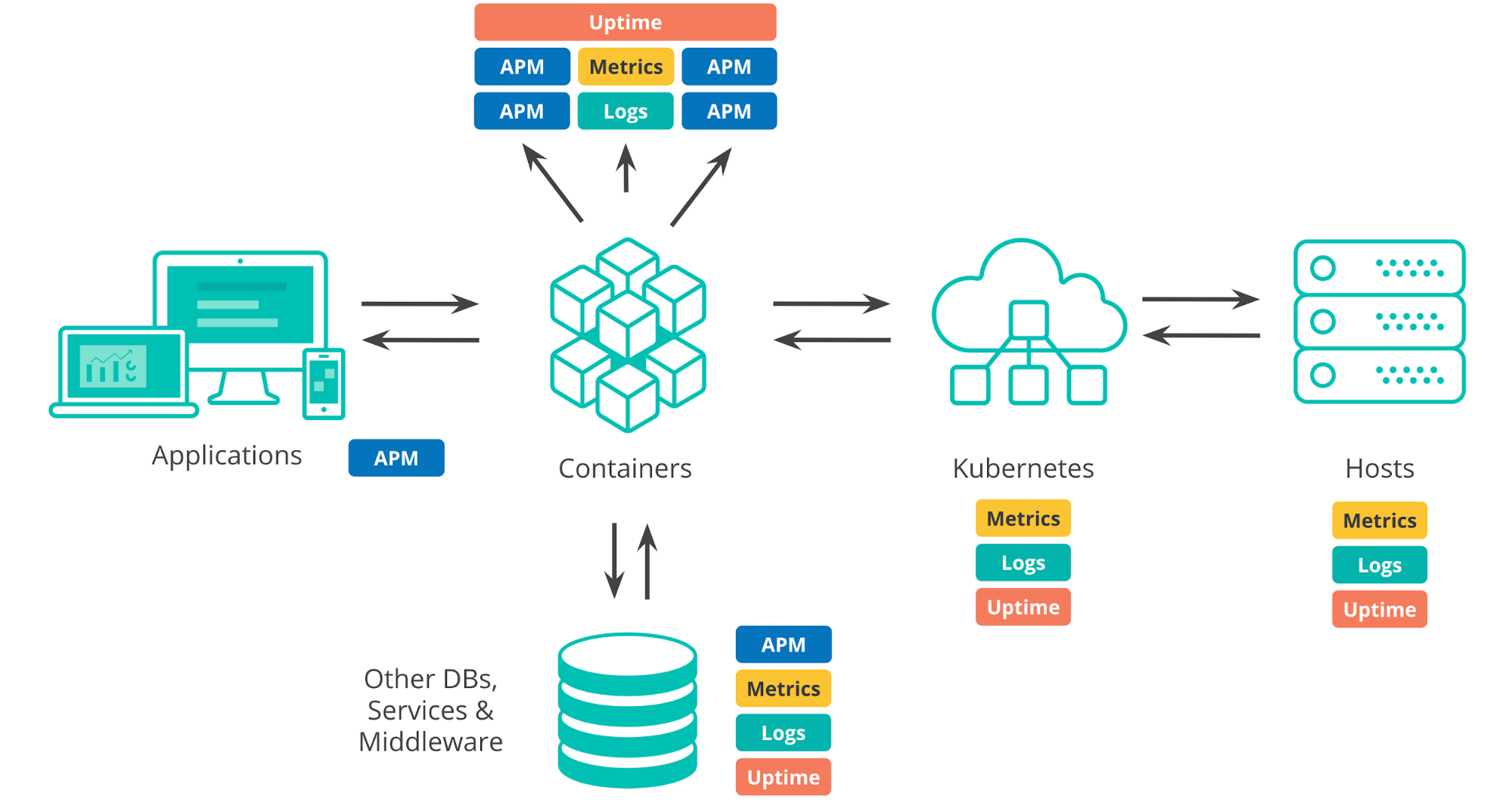
Para asegurarnos de que nuestras aplicaciones se ejecuten como deberían, debemos monitorear todos estos componentes diferentes, y todos generan muchos datos de monitoreo, no solo logs y métricas, sino también datos de APM y tiempo de actividad.
Para obtener visibilidad completa de dichos despliegues, esperamos que una solución de monitoreo:
- Soporte la pila completa de aplicaciones e infraestructura, desde los hosts hasta las aplicaciones.
- Ingeste con facilidad datos de distintas fuentes, como VM, contenedores, orquestadores, plataformas cloud, bases de datos y más (por lo general se caracteriza por las integraciones con otros sistemas que proporciona una solución de monitoreo).
- Maneje los despliegues cada vez más dinámicos a medida que los entornos pasan a contenedores y, al mismo tiempo, las partes de nuestra infraestructura tradicional más antigua.
- Nos brinde formas poderosas de interactuar con estos datos operativos y cree vistas optimizadas para todos en la organización, desde los equipos de DevOps hasta los propietarios de productos y empresas.
- Nos informe cuando algo anda mal. Las alertas son uno de los bloques fundamentales de cualquier solución de monitoreo y deberían cubrir por completo cualquier infraestructura.
- Proporcione almacenamiento confiable y a largo plazo de logs y métricas para análisis históricos o requisitos regulatorios. Esta solución de almacenamiento también debe proporcionar la capacidad de manejar el ciclo de vida de los datos con tasas de retención y granularidad completamente controlables.
- Sea adecuada para la observabilidad de las aplicaciones y la infraestructura completa. La mayoría de las herramientas de monitoreo suelen especializarse en un tipo de datos: muchas bases de datos temporales (TSDB) populares solo trabajan con métricas. Pero cualquier entorno de despliegue típico produce todo tipo de datos: logs, métricas, datos de APM y disponibilidad. Estos flujos de datos proporcionan diferentes perspectivas sobre el rendimiento de nuestros entornos, entonces ¿por qué tratar estos datos por separado y mantener herramientas diferentes con distintas curvas de aprendizaje, modelos de licencias o niveles de servicio?
- Ten todo lo anterior en una sola solución de monitoreo.
| Esta lista puede reducirse a dos requisitos fundamentales: una solución de monitoreo de infraestructura debe poder obtener datos operativos de todas partes de la infraestructura y debe hacerlos procesables. |
El Elastic Stack (ELK Stack) para monitoreo de infraestructuras
La evolución continua y el mayor poder de monitoreo necesarios para observar de forma efectiva las infraestructuras actuales requieren una solución rápida, escalable y flexible. Veamos cómo Elastic aborda estos requisitos.
Ingesta de logs y métricas
Elastic proporciona integraciones para ingestar datos de logs y métricas de cientos de plataformas y servicios. Estas integraciones no solo brindan una forma fácil de agregar fuentes nuevas de datos, sino que también se envían con activos listos para usar como dashboards, varias visualizaciones y pipelines prediseñados que, por ejemplo, pueden extraer campos específicos de los logs. Elastic proporciona Metricbeat y Filebeat para enviar datos de logs y métricas al Elastic Stack. Todas las integraciones que se soportan en Metricbeat y Filebeat tienen instrucciones fáciles de seguir directamente en Kibana.
A medida que te expandes a otras áreas de la observabilidad (y quizá la seguridad), te encontrarás con incluso más agentes. Configurar y gestionar una flota de agentes puede volverse complicado, en especial en entornos de empresas grandes; necesitarás gestionar despliegues de agentes, actualizar archivos de configuración y gestionar los datos (algo que muchos equipos ya hacen en la actualidad). Queríamos mejorar eso. En la versión 7.8 presentamos dos componentes nuevos: Agente de Elastic y Fleet que proporcionan una importante mejora en el envío de datos operativos a Elastic.
- El Agente de Elastic es un agente único para recopilar logs, métricas y otros tipos de datos. Es mucho más fácil de instalar y gestionar que mantener de forma manual integraciones discretas.
- Fleet es una app nueva de Kibana que te ayuda con dos cosas: habilitar rápidamente integraciones para plataformas y servicios que elijas, y gestionar de forma centralizada una flota completa de Agentes de Elastic.
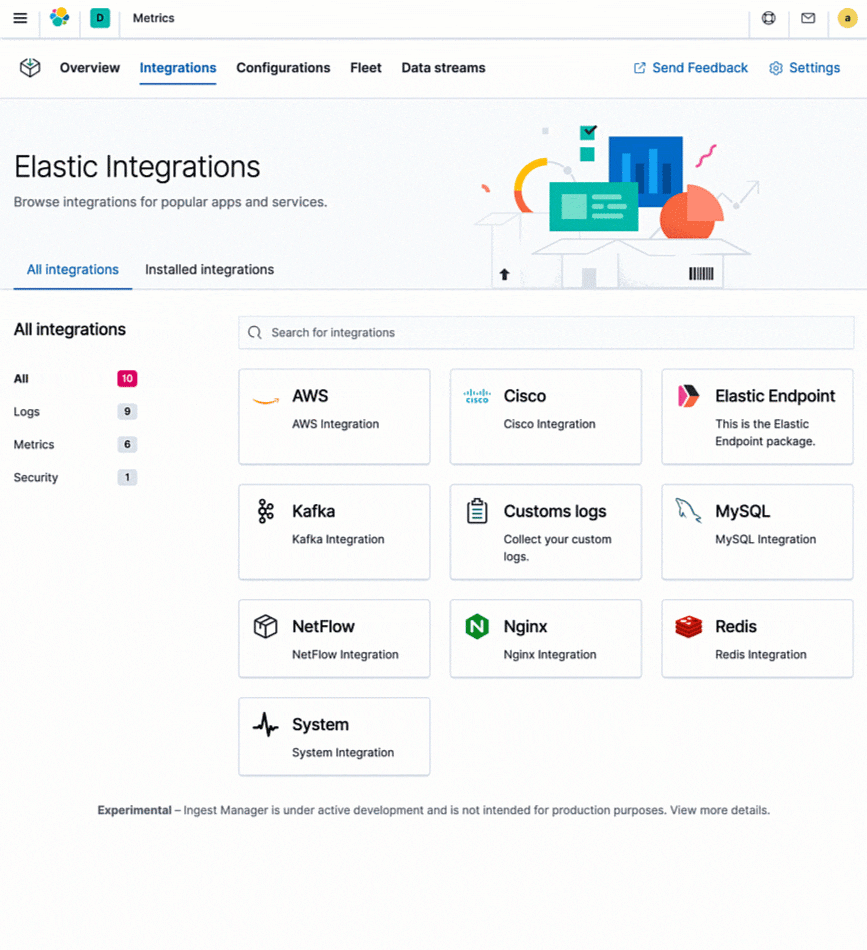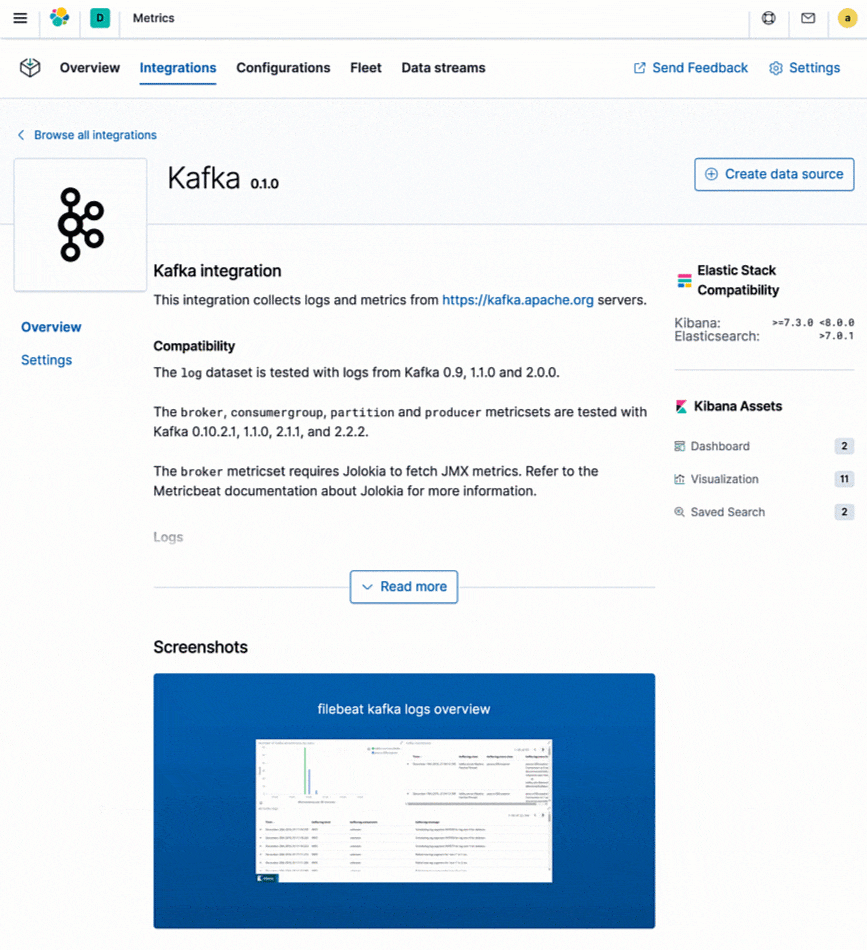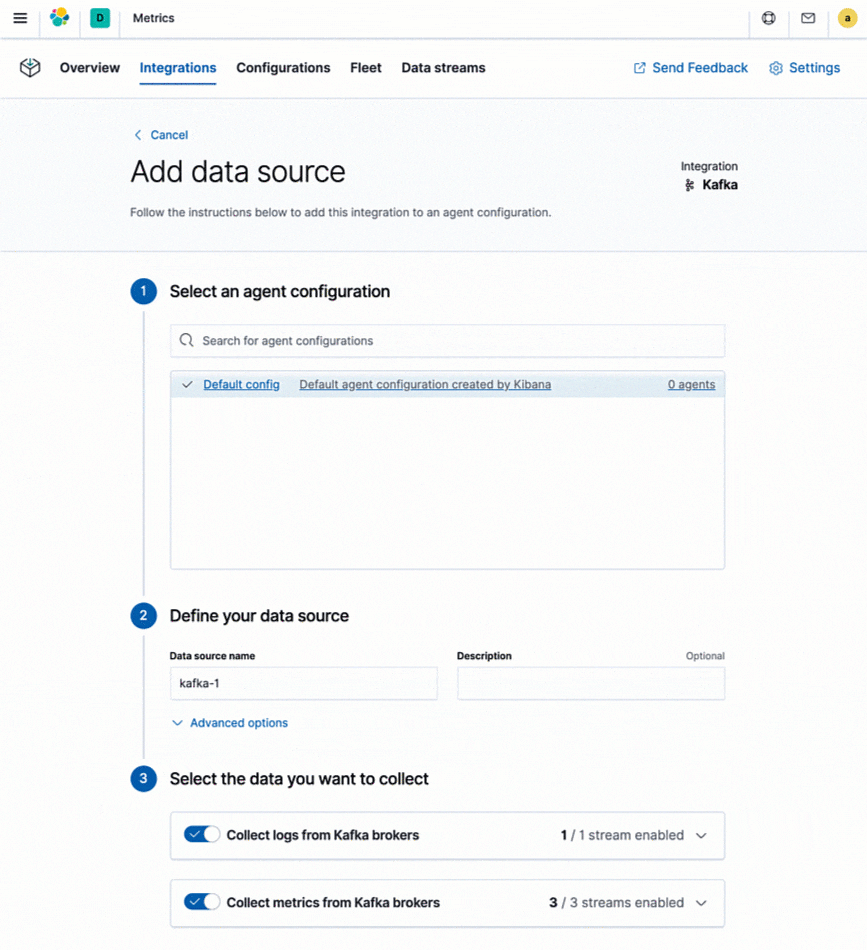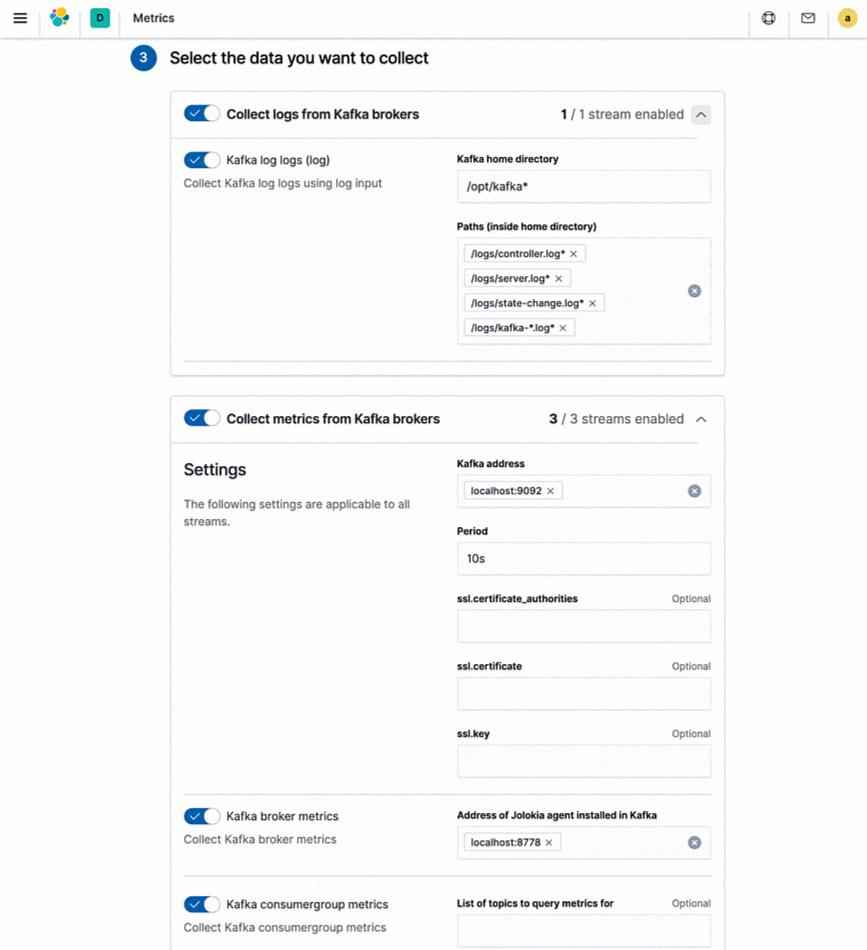
¿Y tus herramientas de monitoreo existentes? Si usas servicios de monitoreo del cloud nativos como Stackdriver, Azure Monitor o herramientas como Prometheus o statsd, y decides consolidar tus métricas con logs y otros datos, Elastic también proporciona integraciones dedicadas para estas herramientas de monitoreo de alto nivel, lo que te permite retener tu instrumentación existente (por ejemplo, exportadores de Prometheus) e incluso almacenar tus métricas junto con otros datos operativos para una mejor observabilidad.
Antes mencionamos que el cambio a despliegues en contenedores requiere replantearnos la forma en que monitoreamos nuestros sistemas en general. Esto es particularmente cierto para las herramientas de monitoreo tradicionales diseñadas para tratar con hosts físicos o máquinas virtuales e infraestructuras estáticas. En el mundo de los contenedores, este enfoque ya no es suficiente porque todo está en constante movimiento, los contenedores aumentan y disminuyen, los servicios se despliegan con más frecuencia y sus direcciones IP son inestables y no confiables; situaciones para las que muchas herramientas de monitoreo no están diseñadas. Cuando ejecutamos nuestras aplicaciones en contenedores, se vuelven efectivamente blancos móviles para un sistema de monitoreo y crean la necesidad de autodetectar cambios en estos entornos, como nuevos servicios desplegados, instancias escaladas o actualizaciones. La buena noticia es que tanto Metricbeat como Filebeat tienen capacidades de autodescubrimiento que pueden hacer un seguimiento de tus despliegues, detectar cualquier cambio y adaptar la configuración para monitorear los servicios cuando comienzan a ejecutarse.
Todos los datos recopilados con las integraciones de Elastic cumplen con Elastic Common Schema (ECS), que se usa como referencia en todas las soluciones de Elastic Observability y Security. ¿En qué difiere ECS de otros modelos de datos disponibles? ECS está optimizado intencionalmente para su uso en Elasticsearch. Es open source y se creó con contribuciones de nuestra comunidad global. Y desde el inicio tomó en cuenta una amplia variedad de casos de uso, como logs y métricas de infraestructura, APM, seguridad y muchos más. Piensa en ECS como un tejido conectivo que se usa en todas las soluciones de Elastic para correlacionar, visualizar y también analizar los diferentes flujos de datos de forma unificada.
ECS no solo se usa en Elastic; vemos que cada vez más empresas adoptan ECS y lo enriquecen con sus propios esquemas específicos del dominio para sus casos de uso. Algunas organizaciones incluso usan ECS como el modelo de datos común en sus proyectos entre equipos. Es excelente ver estos ejemplos en los que se usan las soluciones de Elastic para derribar los silos organizativos y unir a los equipos.
Almacenamiento de logs y métricas
En lo que respecta al almacenamiento de datos, Elasticsearch probablemente sea más conocido como un sistema de almacenamiento de logs. No es sorprendente: el logging fue prácticamente el primer caso de uso de Elasticsearch. Pero con el tiempo hemos visto a muchos usuarios almacenar sus datos temporales junto con los logs, lo cual tiene sentido. Si almacenas los logs de las aplicaciones e infraestructura, ¿por qué no almacenar también métricas que te indiquen cuándo observar los logs?
Desde un principio comenzamos a invertir en Elasticsearch como almacén de datos temporales para permitir tales casos de uso con la presentación de un almacén de columnas. Después incorporamos el marco de trabajo de agregaciones, que permite el agrupamiento y la filtración según diferentes dimensiones de métricas. Para mejorar nuestra capacidad de manejar datos geográficos y numéricos, presentamos árboles de BKD además de una variedad de otras características para gestionar de forma eficiente datos temporales; características como data rollups que te permiten reducir la granularidad de datos históricos (es decir, disminución de la muestra) y gestión de ciclo de vida de indexación que te permite controlar diferentes períodos de retención para diferentes fases de datos, como caliente, tibio, frío y eliminar.
Cómo hacer que los datos de monitoreo sean procesables
Visualizaciones
Supongamos que la ingesta está funcionando y los logs y las métricas ahora se transmiten a Elastic. Lo primero que debemos hacer es ver estos datos de forma significativa. Algunas herramientas de monitoreo le dejan al usuario la parte de crear o buscar visualizaciones de datos, pero creemos que las vistas son esenciales, por lo que Elastic proporciona dashboards y visualizaciones prediseñados con cada integración soportada. Esto significa que tan pronto como comiences a recopilar logs o métricas, puedes abrir rápidamente un dashboard y ver lo que sucede con tus sistemas y servicios en un instante.
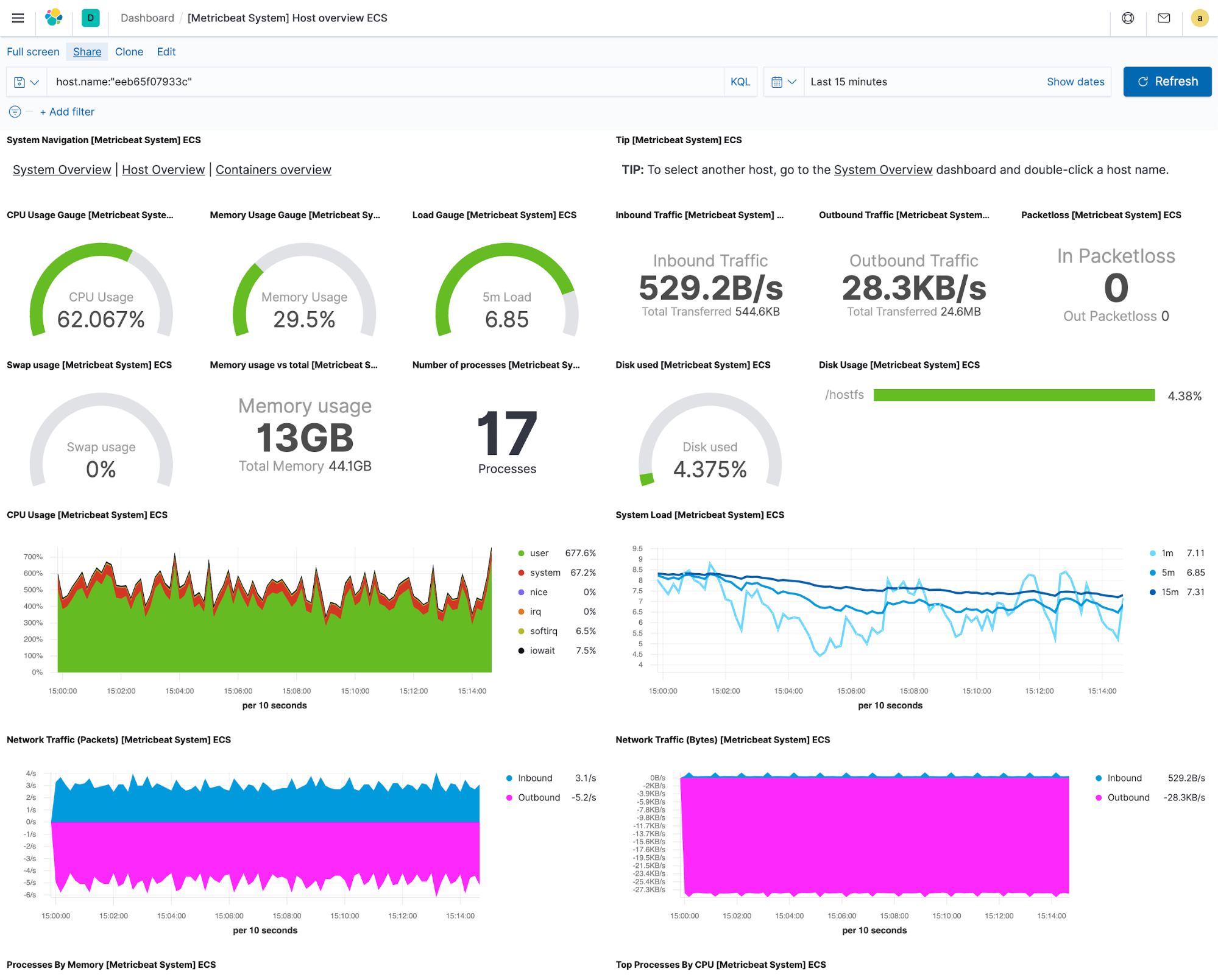
Todas las visualizaciones que conforman el dashboard predefinido son reutilizables, lo que significa que puedes elegir por conveniencia las que consideras particularmente útiles y crear dashboards customizados para tus necesidades específicas, mezclando y combinando a partir de varias integraciones para obtener respuestas a las preguntas que tú tienes. Además, puedes crear listas desplegables personalizadas para filtrar o desgloses para navegar de un dashboard a otro sin perder el contexto, lo que resulta bastante bueno porque realmente te ayuda a optimizar tus flujos de trabajo de solución de problemas.
Además de dashboards y visualizaciones, Elastic proporciona apps curadas para logs, métricas y disponibilidad, todas las cuales están diseñadas para aumentar la visibilidad de tu infraestructura.
La app Metrics te da la capacidad de ver toda tu infraestructura en un lugar. No importa si tienes centros de datos distribuidos geográficamente, si ejecutas Kubernetes en varios clouds o si tienes una configuración en la que se incluye todo. Proporciona un único panel para todos tus recursos en el que puedes agruparlos por proveedores de infraestructura, zonas geográficas o prácticamente cualquier campo de etiquetas personalizadas que puedas estar usando para distinguir entre tus entornos de organización y producción. A partir de esta vista, puedes ver métricas más detalladas y revisar logs, rendimiento de las aplicaciones o información de tiempo de actividad de cualquier recurso. Lo que lo hace posible es el hecho de que Elastic se usa como único almacén de datos de todos los datos operativos, esto nos permite crear vistas curadas, vincularlas entre sí para una navegación más simple y hacer que el monitoreo de infraestructura sea una experiencia más optimizada.
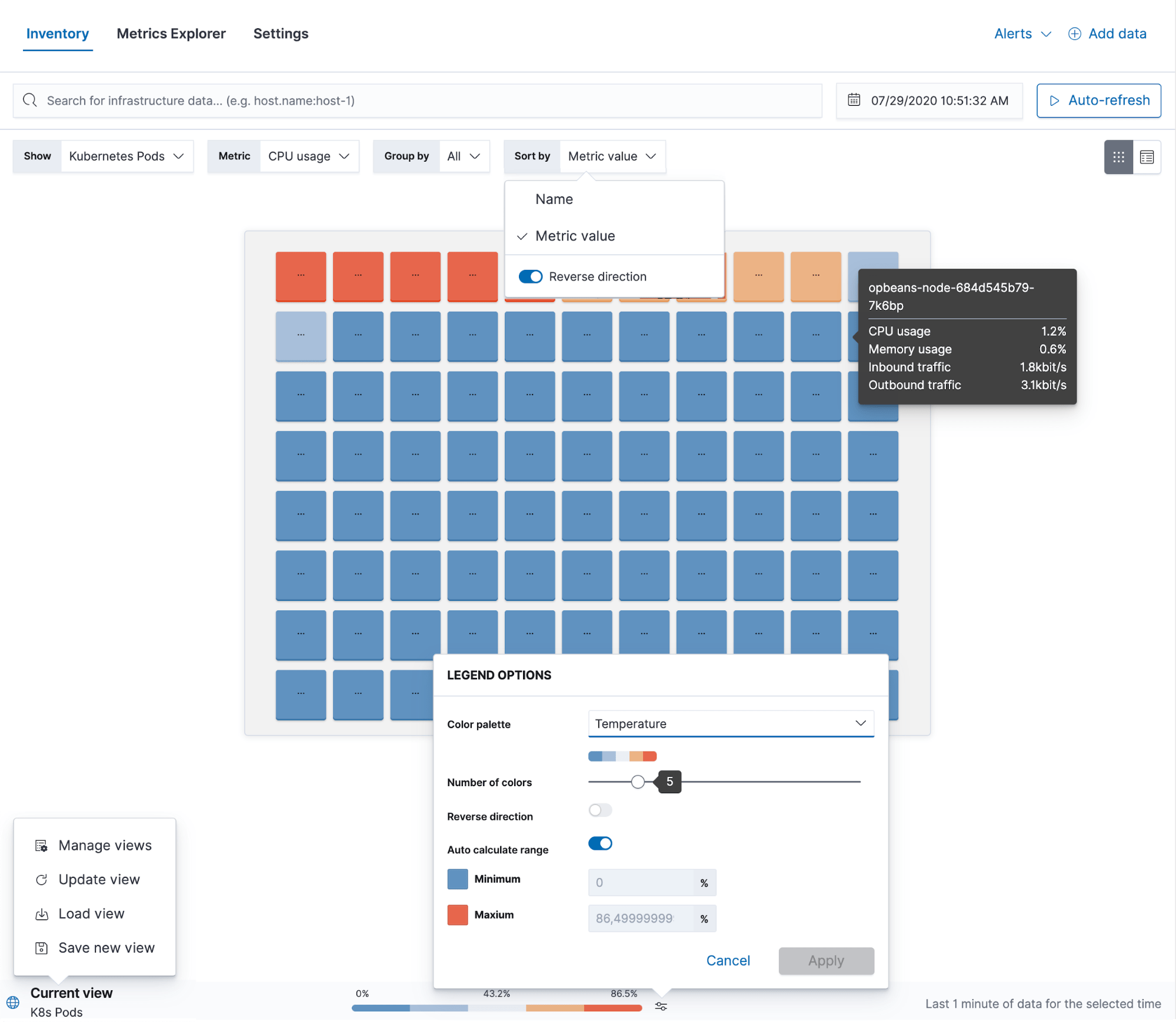
La app Metrics también proporciona Metrics Explorer, que es útil para resolver problemas gracias a que te permite superponer diferentes métricas para ver si hay alguna correlación entre ellas. Desde aquí también puedes crear visualizaciones nuevas o alertas de umbral.
La app Logs es básicamente un tail -f para toda tu infraestructura; consolida todos los flujos de logs y muestra logs en tiempo real e históricos en una vista. Detrás de escena, los logs se correlacionan con métricas, lo que hace que sea mucho más sencillo seguir el rastro mientras se investigan los problemas. En esta app, puedes ver los detalles de cada línea de log y también lo que sucedió antes y después de que se escribiera la línea. Y como cualquier otra app de observabilidad en Kibana, va más allá de únicamente las vistas de solo lectura y te permite analizar y actuar sobre aquello que sea sospechoso con el poder de las alertas y Machine Learning.
Alertas
Las alertas son uno de los bloques fundamentales para básicamente todos los casos de uso de monitoreo porque ayudan a detectar y responder a cualquier problema en toda la infraestructura. Gracias al marco de trabajo de alertas nuevo en Elastic, ahora proporcionamos varios tipos de alertas optimizadas para distintos flujos de datos.
- Las alertas de Metrics se pueden configurar fácilmente para cualquier tipo de despliegue, ya sea físico o en contenedores, lo que significa que estas alertas pueden cubrir automáticamente recursos creados recientemente. Los filtros te permiten controlar las partes de tu infraestructura que una alerta debería cubrir. También puedes configurar una alerta una vez y hacer que se divida automáticamente según el campo que prefieras, como emitir una alerta para cada host, emitir una alerta para cada disco en cada host.
- Las alertas de logs están optimizadas para datos de log y te permiten crear alertas basadas en campos que coinciden con una frase o basadas en la frecuencia con la que se registra un campo determinado.
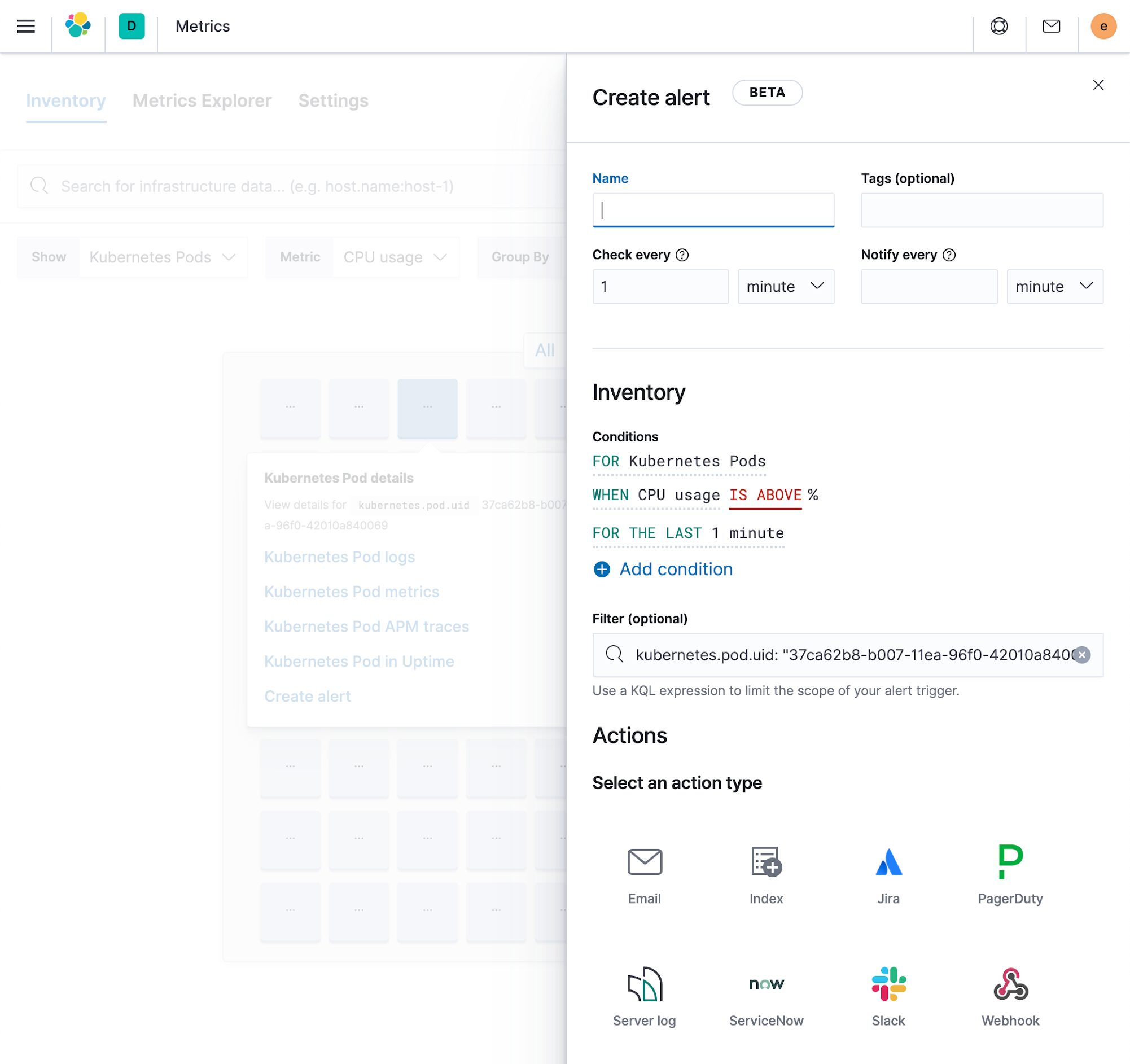
Todas las alertas se pueden crear y gestionar desde un lugar central en Kibana, pero también están incrustadas en las apps respectivas, lo que las hace muy fáciles de usar en las operaciones cotidianas.
Machine Learning y detección de anomalías
Actualmente las infraestructuras producen muchos datos operativos que aumentan todo el tiempo, por lo que resulta prácticamente imposible analizar de forma manual los diferentes flujos de datos. De hecho, esto se está convirtiendo en un serio inconveniente para las organizaciones que buscan formas de automatizar la detección de problemas. Por lo tanto, una parte importante de una solución de monitoreo moderna es la capacidad de detectar automáticamente cualquier comportamiento anormal en entornos de despliegue antes de que haya sucedido algo malo.
La buena noticia es que una vez que tus datos operativos están en Elasticsearch, están listos para el análisis. Los trabajos de Machine Learning predefinidos para la detección de anomalías ya están optimizados para logs y métricas, y están integrados con las apps de Kibana en las que los necesitas. Por ejemplo, pueden detectar automáticamente si hay cualquier anomalía a través de la tasa a la que se generan los logs de infraestructura o encontrar patrones y agrupar automáticamente tus logs en categorías.
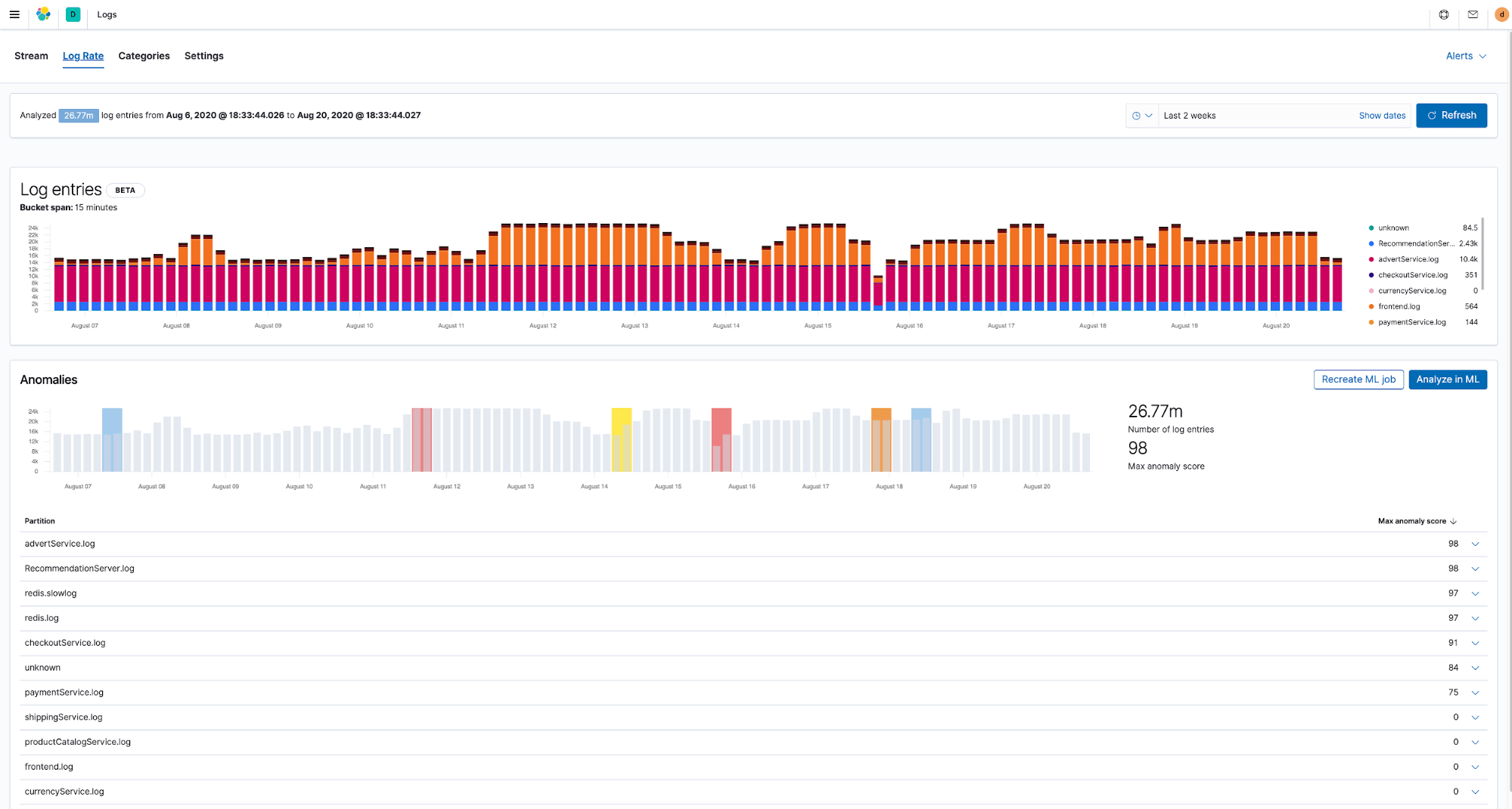
Las capacidades de Machine Learning de Elastic no se limitan a la detección de anomalías. Puedes usar otros algoritmos como clasificación, detección de valores atípicos y más en una amplia variedad de casos de uso que involucran datos de infraestructura.
Multiplicación del valor con el Elastic Stack
Como todo es solo otro índice en Elastic, puedes usar cualquier característica de Elastic con tus datos de monitoreo. Con diferentes visualizaciones en Kibana, puedes crear vistas que sean significativas para todos en tu organización, como dashboards flexibles y densos creados con Lens y TSVB (anteriormente, generador visual de series temporales, una herramienta poderosa para crear visualizaciones de histogramas y métricas anotables) que tus equipos de ingeniería encuentran valiosos o infografías en vivo con Canvas que traducen datos complejos en tendencias valiosas para los propietarios de las empresas.
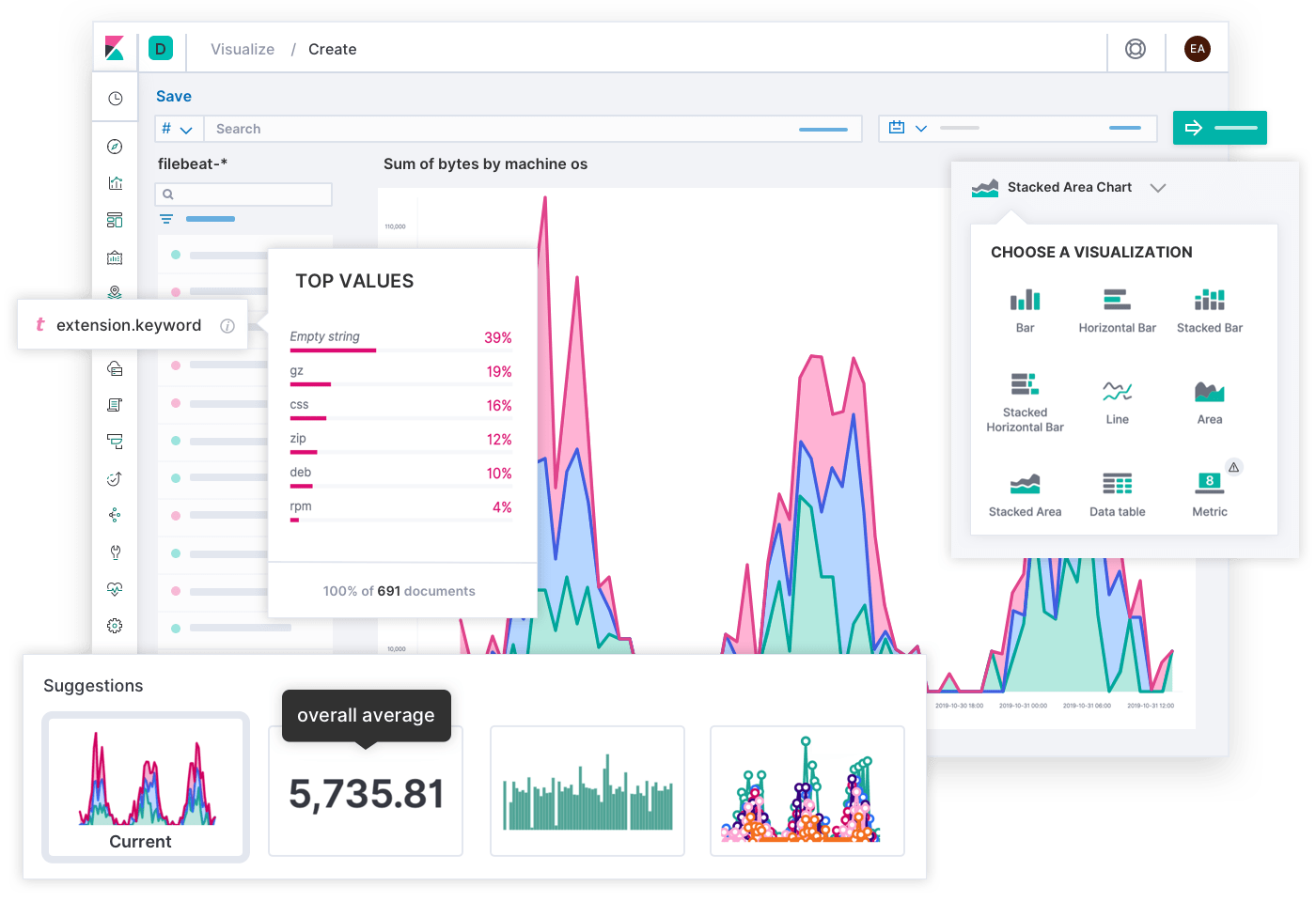
Se puede acceder a todo lo que almacenas en Elastic desde la UI o API con un lenguaje de búsqueda que te resulte familiar, como SQL o PromQL. PromQL se está popularizando, y gracias a nuestra integración con Prometheus, puedes escribir resultados de tus búsquedas de PromQL en Elastic. Esto resulta particularmente útil si no deseas almacenar métricas sin procesar y solo te interesan los datos ya procesados.
También puedes combinar tu monitoreo de infraestructura con seguridad. La línea entre la observabilidad y seguridad está desapareciendo porque, básicamente, los mismos datos que usamos para el monitoreo de infraestructuras también son relevantes para asegurarlas. La solución Elastic Security, al igual que Observability, se desarrolló a partir del Elastic Stack y te permite detectar y prevenir de forma fácil amenazas de seguridad en tus infraestructuras.
Conclusión
En este blog enumeramos las necesidades de soluciones de monitoreo modernas y mostramos cómo Elastic puede satisfacerlas. La solución Elastic Observability y el Elastic Stack pueden ayudarte a crear la plataforma de monitoreo definitiva en la que tú y tus equipos puedan ingestar de forma segura todos los datos operativos, interactuar con ellos y tener éxito.
Pero no te fíes de nuestra palabra, pruébalo tú mismo. Activa un cluster en una prueba gratuita de Elastic Cloud o descarga la versión más reciente de nuestro sitio web y después cuéntanos tu opinión.