Monitoreo de Google Cloud con el Elastic Stack y Google Operations
El conjunto Google Operations, anteriormente Stackdriver, es un repositorio central que recibe logs, métricas y rastreos de aplicaciones de los recursos de Google Cloud. Estos recursos pueden incluir el motor de procesamiento, motor de apps, dataflow, dataproc y sus ofertas de SaaS, como BigQuery. Al enviar estos datos a Elastic, obtendrás una vista unificada del rendimiento de los recursos de toda tu infraestructura, desde el cloud hasta las instalaciones.
En este blog, configuraremos un pipeline para transmitir datos desde Google Operations hasta el Elastic Stack para que puedas analizar tus logs de Google Cloud junto con los otros datos de observabilidad. En esta demostración, usaremos el módulo de Google Cloud Filebeat para enviar tus datos de Google Cloud a una prueba gratuita de Elastic Cloud para análisis. Te recomendamos que sigas los pasos.
Flujo de datos de alto nivel
En esta demostración, enviaremos logs de flujo de VPC, firewall y auditoría desde los recursos de Google Cloud hasta Google Cloud Operations. A partir de eso, crearemos colectores y temas Pub/Sub, nos suscribiremos como Filebeat y enviaremos nuestros datos a Elastic Cloud para un análisis más detallado con Elasticsearch y Kibana. En este diagrama se proporciona un flujo de alto nivel que muestra el recorrido de los datos hacia nuestro cluster:
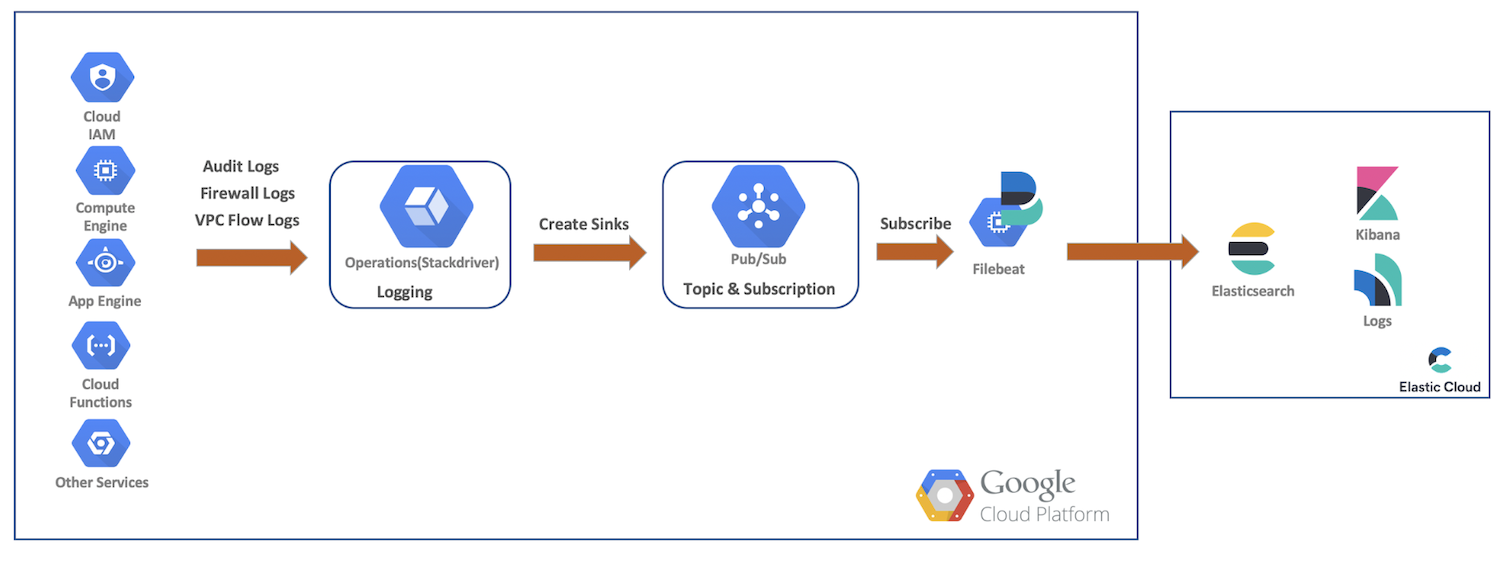
Configuración y ajustes de logging de Google Cloud
Google Cloud proporciona una UI completa para habilitar logs de servicios, mientras que los logs se configuran en sus consolas respectivas. En estos pasos a continuación, habilitaremos múltiples logs, crearemos nuestros colectores y temas, y después configuraremos nuestra cuenta de servicios y credenciales.
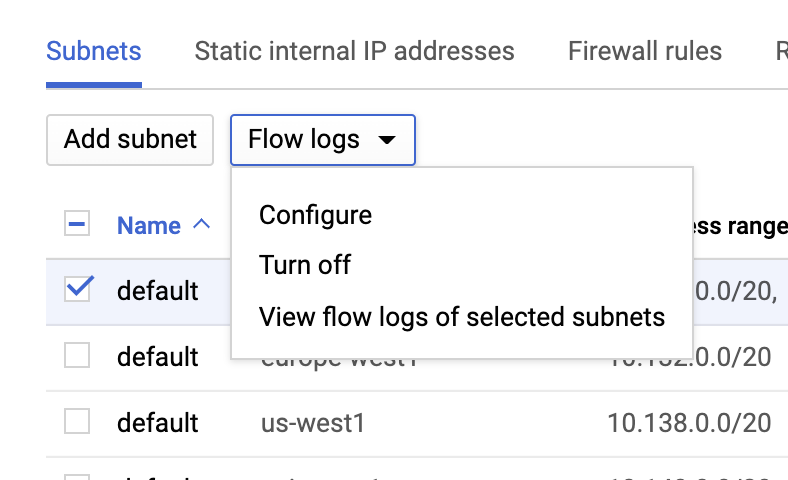
Logs de flujo de VPC
Se pueden habilitar los logs de flujo de VPC desde la página VPC network, seleccionando un VPC y haciendo clic en Configure en la lista desplegable Flow logs:
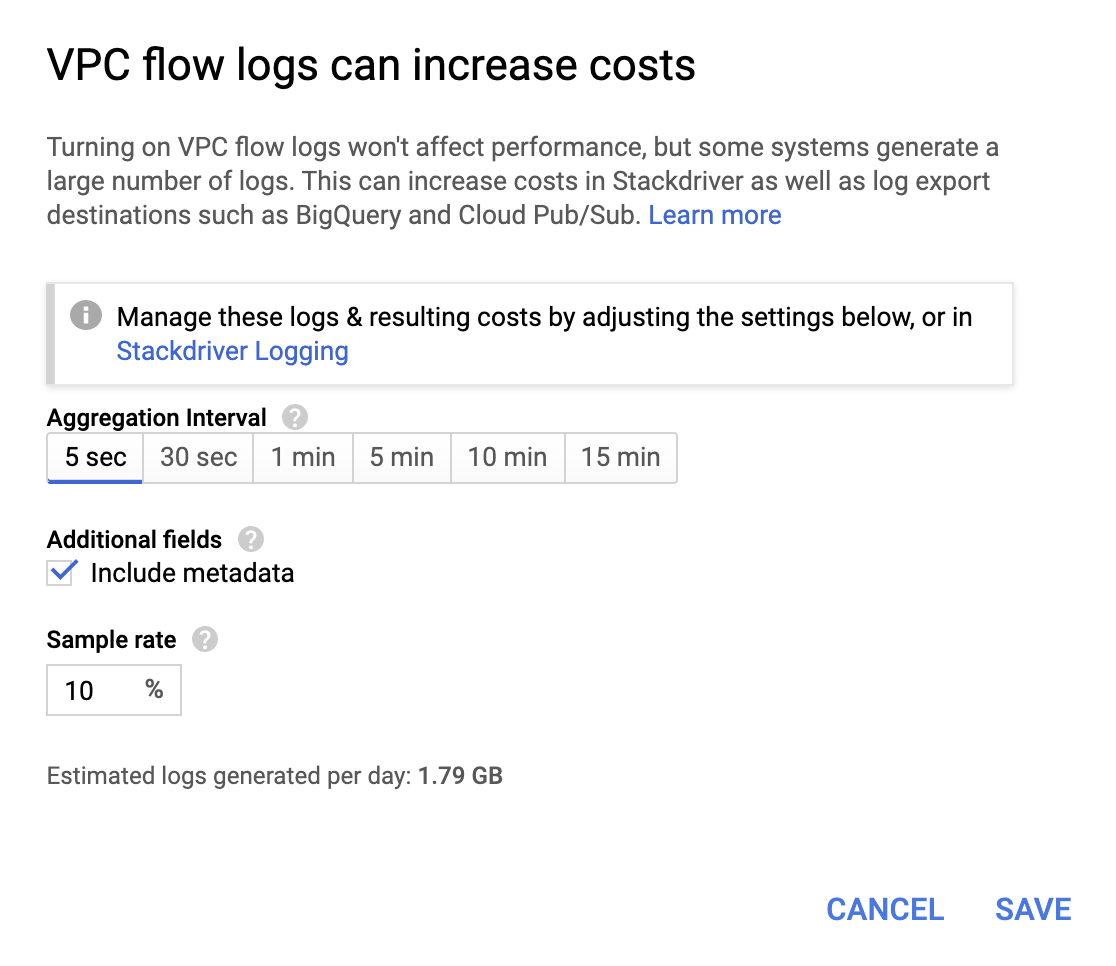
Si bien no son muy costosas, las operaciones incrementan la factura, por lo que debes seleccionar un intervalo de agregación y frecuencia de muestreo según tus requisitos.
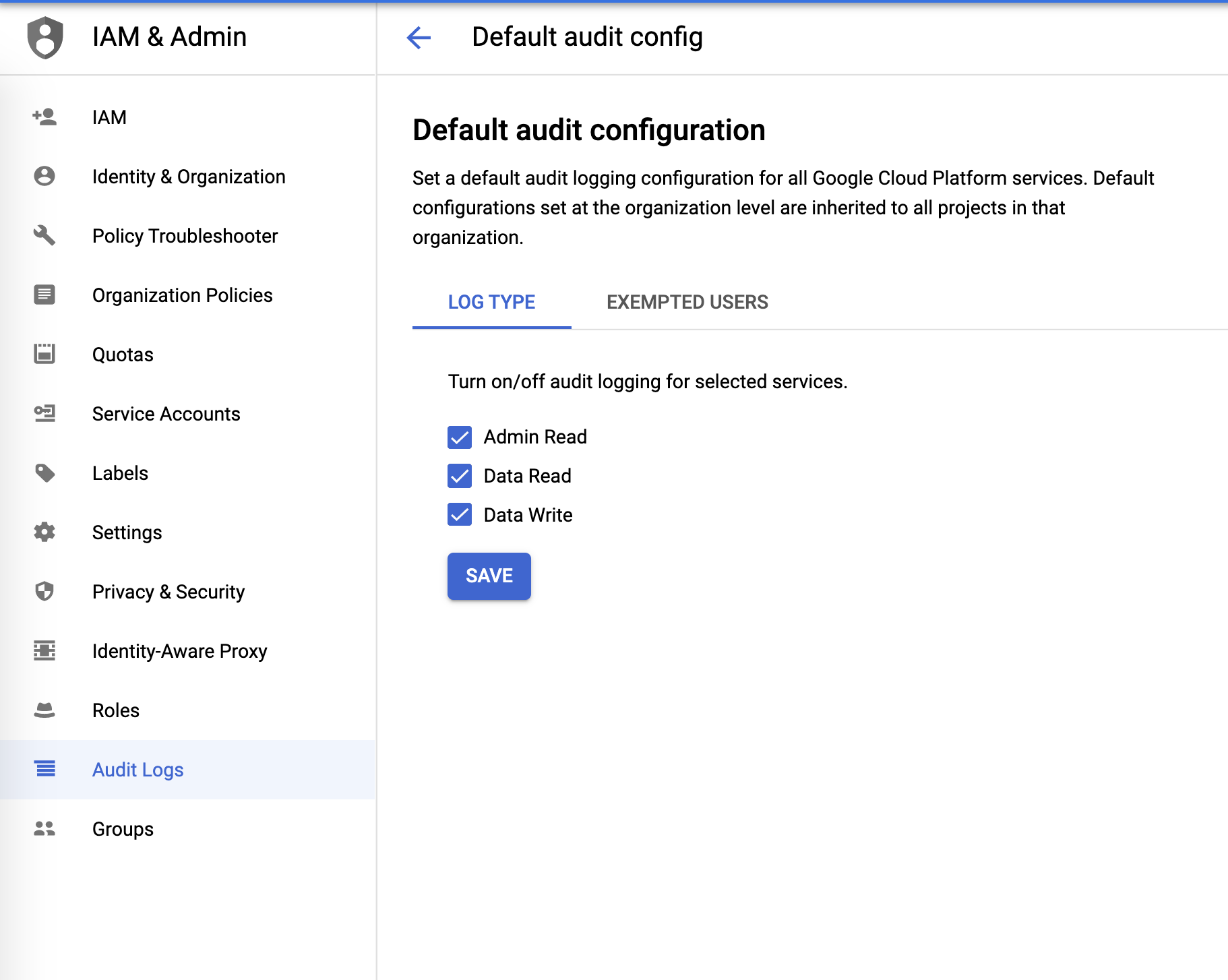
Logs de auditoría
Los logs de auditoría se pueden configurar desde el menú IAM & Admin:
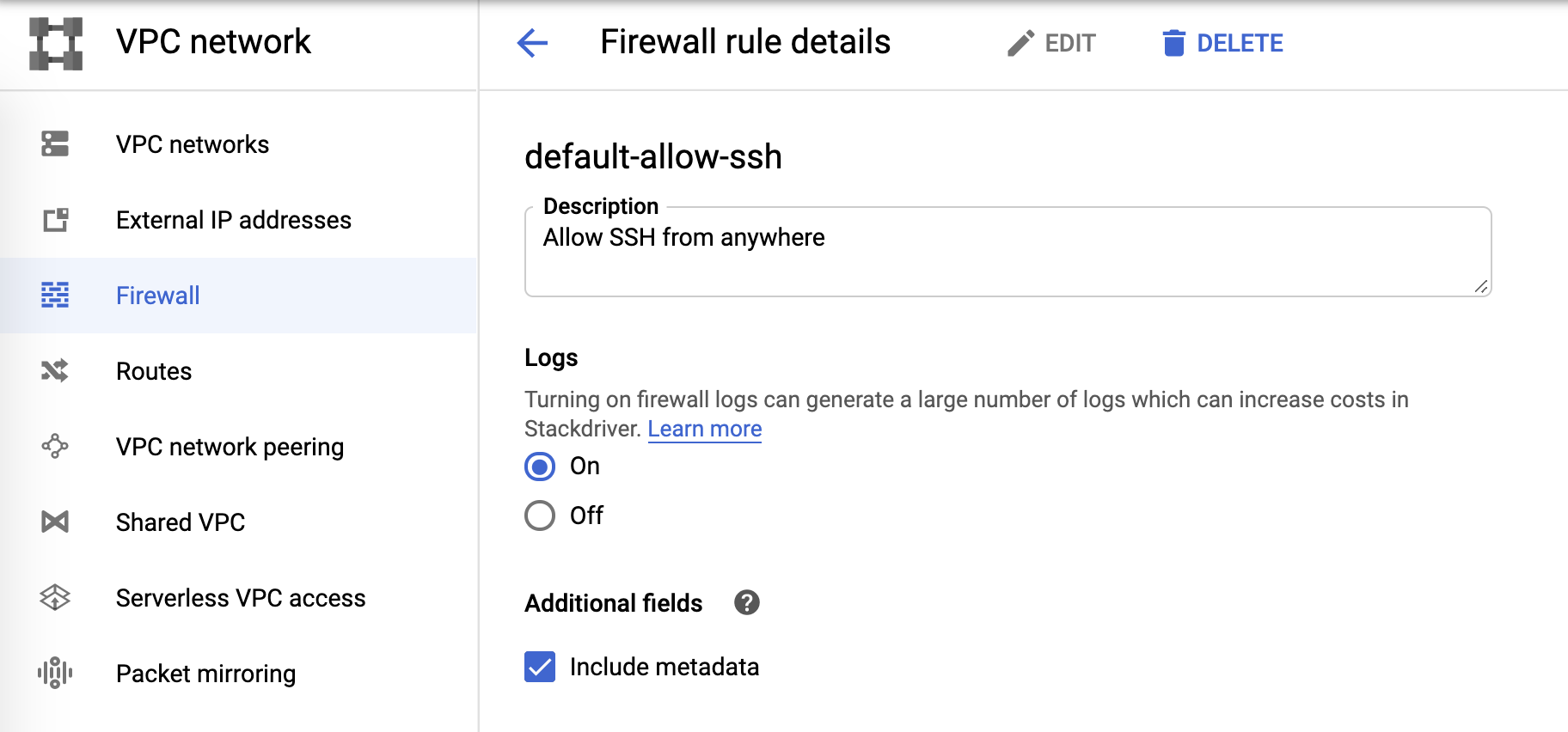
Logs de firewall
Y, por último, los logs de firewall se pueden controlar desde las reglas de firewall:
Colector de logs y Pub/Sub
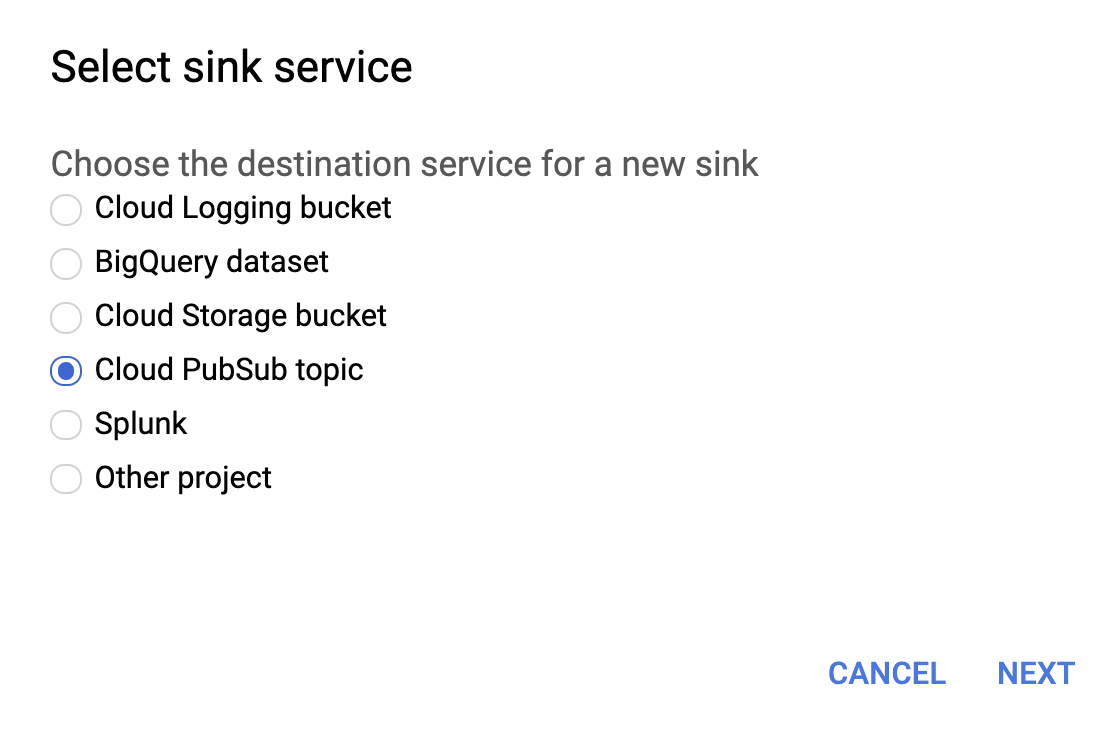
Una vez que hayamos configurado las áreas de logging individuales, podemos crear colectores para cada uno de logs desde Logs Viewer:

Selecciona Cloud PubSub topic para el servicio de colector como se muestra a continuación.
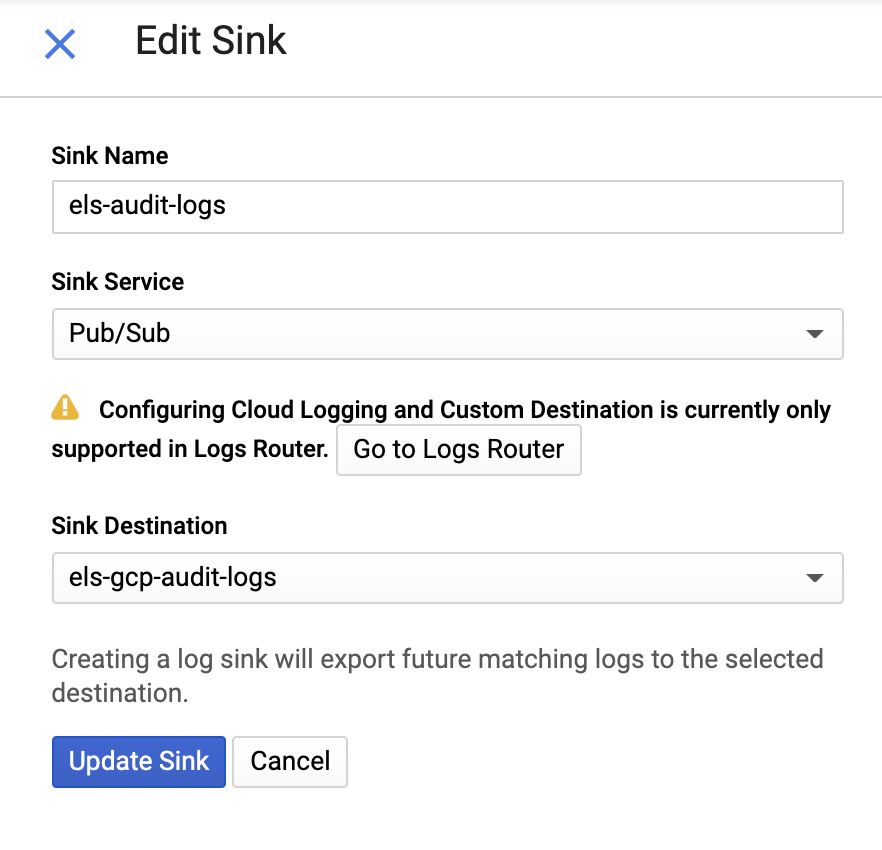
Y después proporciona un nombre para el colector y un tema Pub/Sub; puedes enviarlo a un tema existente o crear uno nuevo:
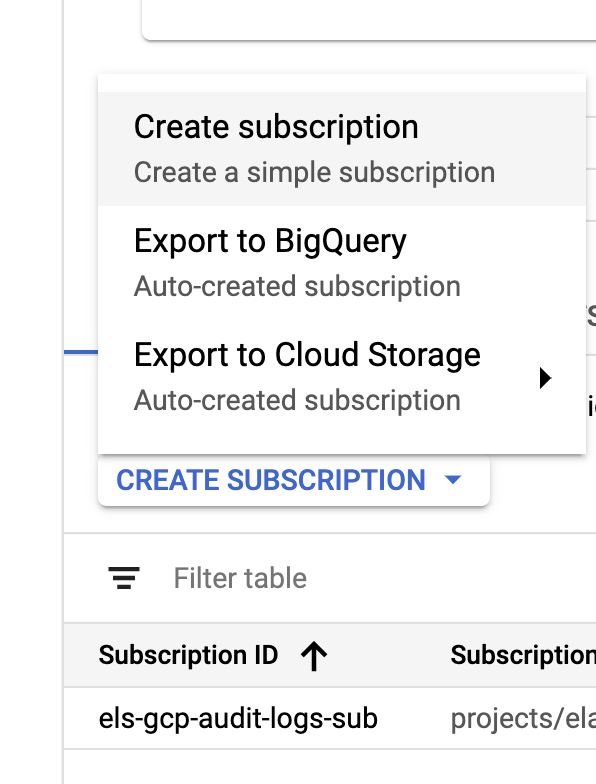
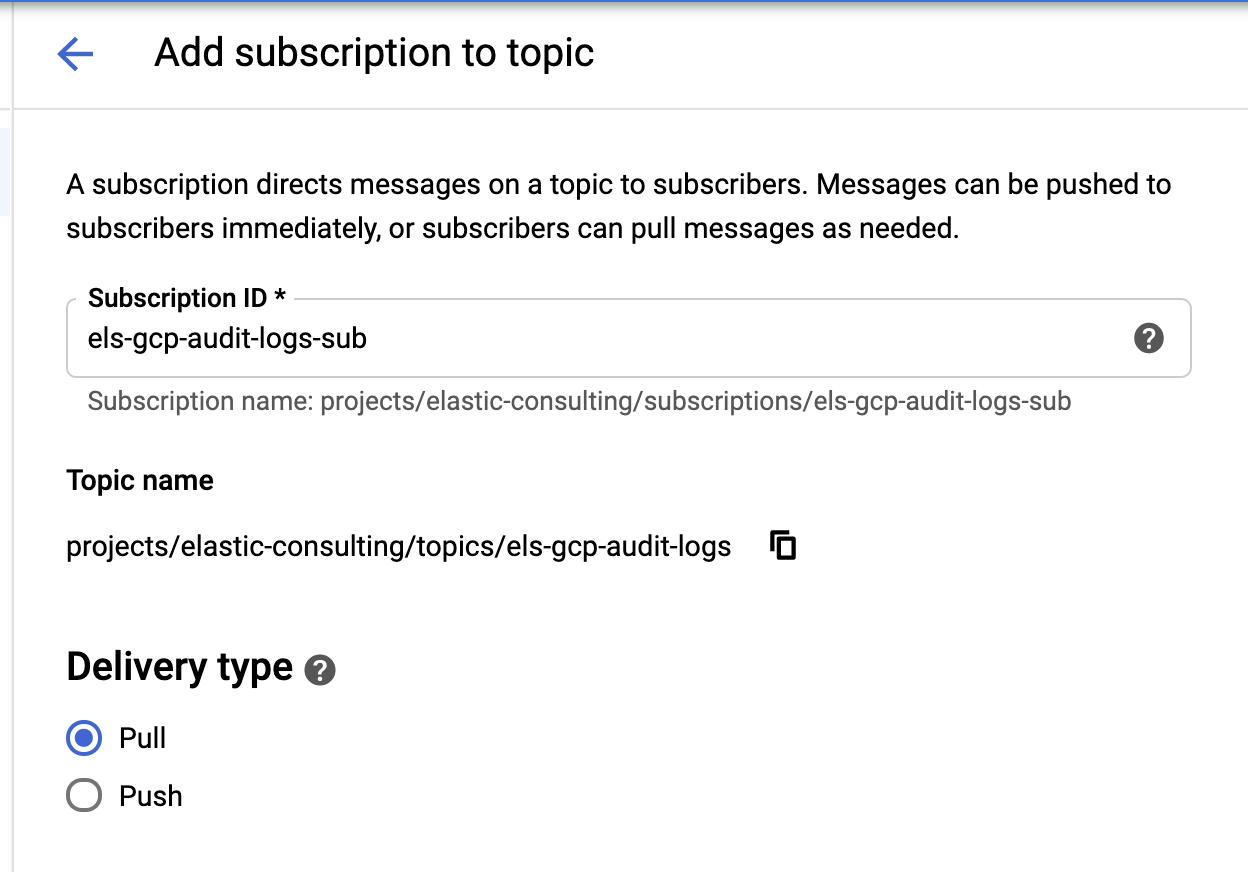
Una vez creados nuestro colector y temas, es hora de crear las suscripciones del tema Pub/Sub:
| 
|
Configura la suscripción según tus requisitos.
Cuenta de servicios y credenciales
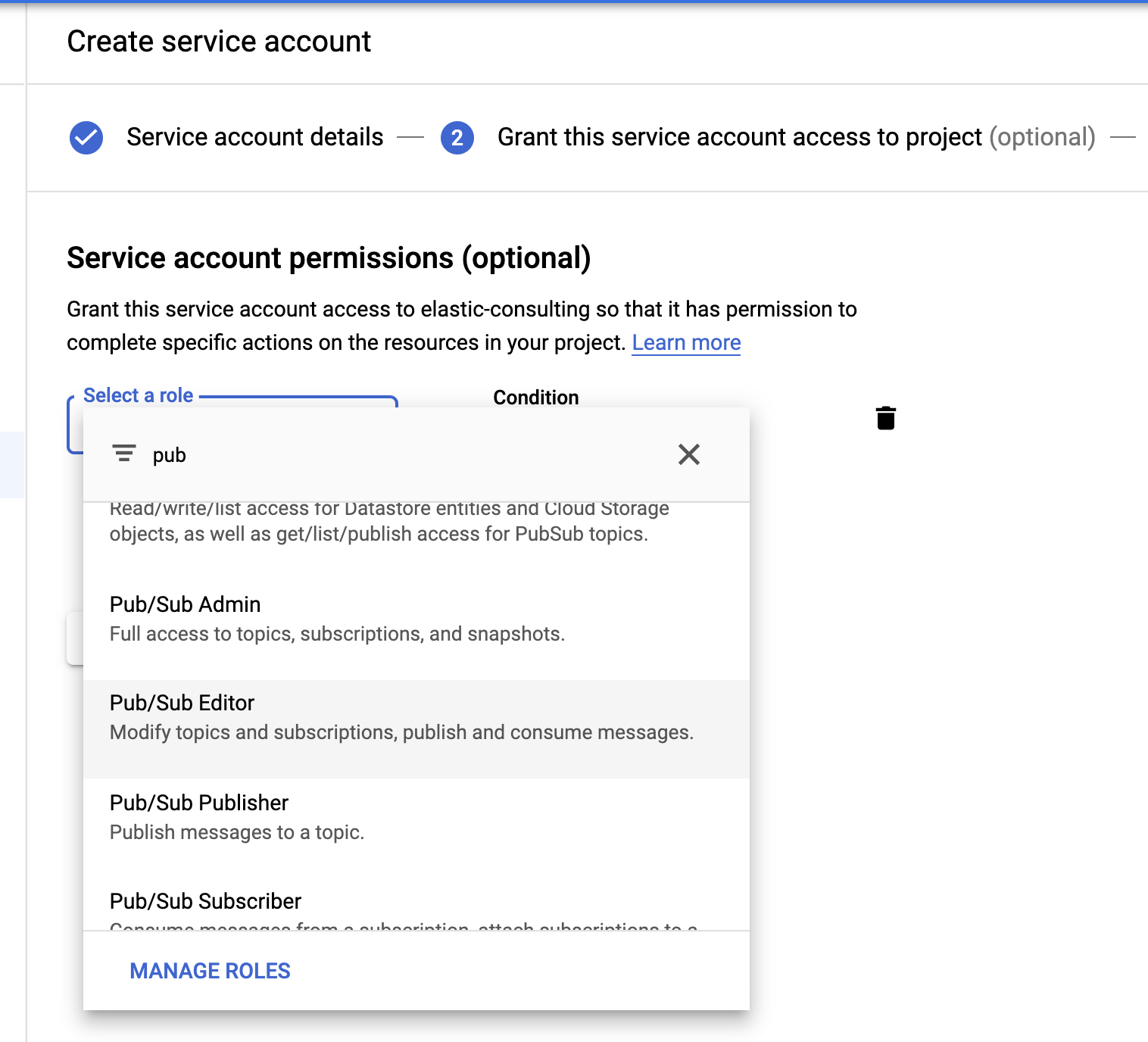
Por último, creemos una cuenta de servicios y un archivo de credenciales.
Selecciona el rol Pub/Sub Editor; la condición es opcional y puede usarse para filtrar los temas.
Una vez creada la cuenta de servicios, generaremos una clave JSON que se cargará al host de Filebeat y se almacenará en el directorio de configuración de Filebeat, /etc/filebeat. Filebeat usará esta clave para autenticarse como la cuenta de servicios.

Ahora, nuestra configuración de Google Cloud está completa.
Instalar y configurar Filebeat
Filebeat se usa para seleccionar los logs y enviarlos a nuestro cluster de Elasticsearch. Usaremos CentOS para este blog, pero se puede instalar Filebeat dependiendo de tu sistema operativo si sigues estos pasos simples en nuestra documentación de Filebeat.
Habilitar el módulo de Google Cloud
Una vez instalado Filebeat, tendremos que habilitar el módulo googlecloud:
filebeat modules enable googlecloud
Copia el archivo de credenciales JSON que creamos antes en /etc/filebeat/, después modifica el archivo /etc/filebeat/modules.d/googlecloud.yml para que coincida con tu configuración de Google Cloud.
Algunas de las configuraciones se hacen por ti; por ejemplo, los tres módulos están enumerados y todas las configuraciones requeridas están ingresadas, solo necesitas actualizar esos valores según tu configuración.
# Módulo: googlecloud
# Documentos: https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# ID de proyecto de Google Cloud.
var.project_id: els-dummy
# Tema de Pub/Sub de Google que contiene logs de flujo de VPC. Se debe configurar Stackdriver
# para usar este tema como colector para logs de flujo de VPC.
var.topic: els-gcp-vpc-flow-logs
# Suscripción de Pub/Sub de Google para el tema. Filebeat creará
# esta suscripción si no existe.
var.subscription_name: els-gcp-vpc-flow-logs-sub
# Archivo de credenciales para la cuenta de servicio con autorización para leer
# de la suscripción.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# ID de proyecto de Google Cloud.
var.project_id: els-dummy
# Tema de Pub/Sub de Google que contiene logs de firewall. Se debe configurar Stackdriver
# para usar este tema como colector para logs de firewall.
var.topic: els-gcp-firewall-logs
# Suscripción de Pub/Sub de Google para el tema. Filebeat creará
# esta suscripción si no existe.
var.subscription_name: els-gcp-firewall-logs-sub
# Archivo de credenciales para la cuenta de servicio con autorización para leer
# de la suscripción.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# ID de proyecto de Google Cloud.
var.project_id: els-dummy
# Tema de Pub/Sub de Google que contiene logs de auditoría. Se debe configurar Stackdriver
# para usar este tema como colector para logs de firewall.
var.topic: els-gcp-audit-logs
# Suscripción de Pub/Sub de Google para el tema. Filebeat creará
# esta suscripción si no existe.
var.subscription_name: els-gcp-audit-logs-sub
# Archivo de credenciales para la cuenta de servicio con autorización para leer
# de la suscripción.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
Por último, configura Filebeat para que se dirija a tus endpoints de Kibana y Elasticsearch.
Puedes configurar setup.dashboards.enabled: true en tu archivo filebeat.yml para cargar un dashboard prediseñado para Google Cloud, conforme a la documentación de endpoint de Kibana y Elasticsearch.
Como comentario adicional, Filebeat ofrece una amplia variedad de módulos con dashboards prediseñados. En este blog solo veremos el módulo de Google Cloud, pero te recomendamos explorar los otros módulos de Filebeat disponibles para ver qué podría resultarte útil.
Iniciar Filebeat
Por último, podemos iniciar Filebeat y agregar el indicador -e para que simplemente registre la salida en la consola:
sudo service filebeat start -e
Exploración de los datos en Kibana
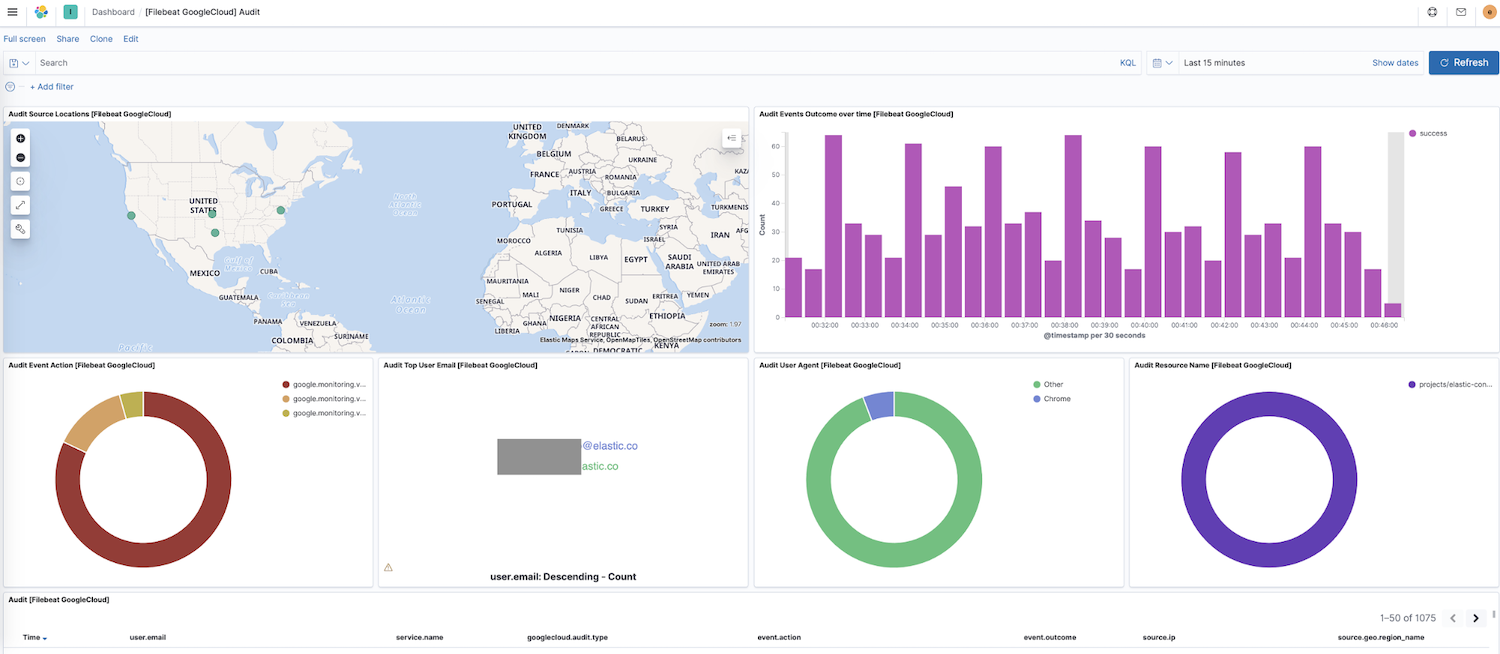
Ahora que Filebeat envía datos a tu cluster, vayamos a Dashboard en el panel de navegación lateral de Kibana; si tienes dashboards para otros módulos, puedes buscar google para encontrar los dashboards de nuestro módulo habilitado recientemente. En este caso, vemos el dashboard "Audit" de Google Cloud.
En este dashboard, verás visualizaciones como un mapa dinámico de las ubicaciones de las fuentes, resultados de eventos con el tiempo, un desglose de las acciones de eventos y más. Explorar tus datos de log es intuitivo gracias a estas visualizaciones prediseñadas e interactivas. Si estás configurando Filebeat por primera vez o estás ejecutando una versión anterior del Elastic Stack (el módulo de Google Cloud se puso a disposición del público en general en la versión 7.7), necesitarás seguir estas instrucciones para cargar los dashboards.
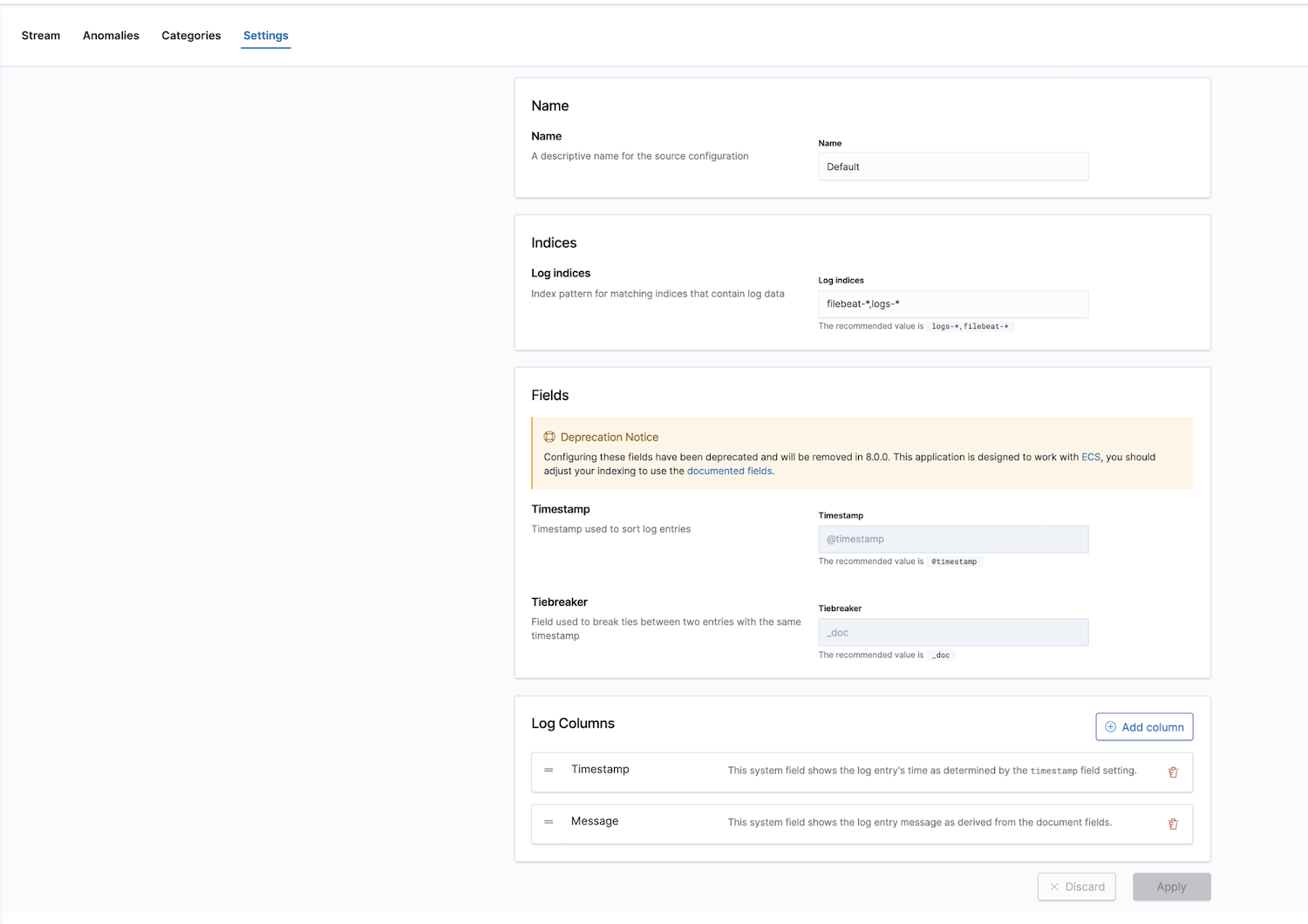
Además, Elastic proporciona una solución de observabilidad con una app de monitoreo de logs. Se pueden configurar los índices de logs; los valores predeterminados son filebeat-* y logs-*.
Después de configurar los patrones de índice correctos en la configuración, puedes explorar los logs en la app Logs, que te permite ver detalles de los logs y, lo más importante, definir trabajos de Machine Learning para comportamiento anómalo, categorizar los datos y crear una alerta.
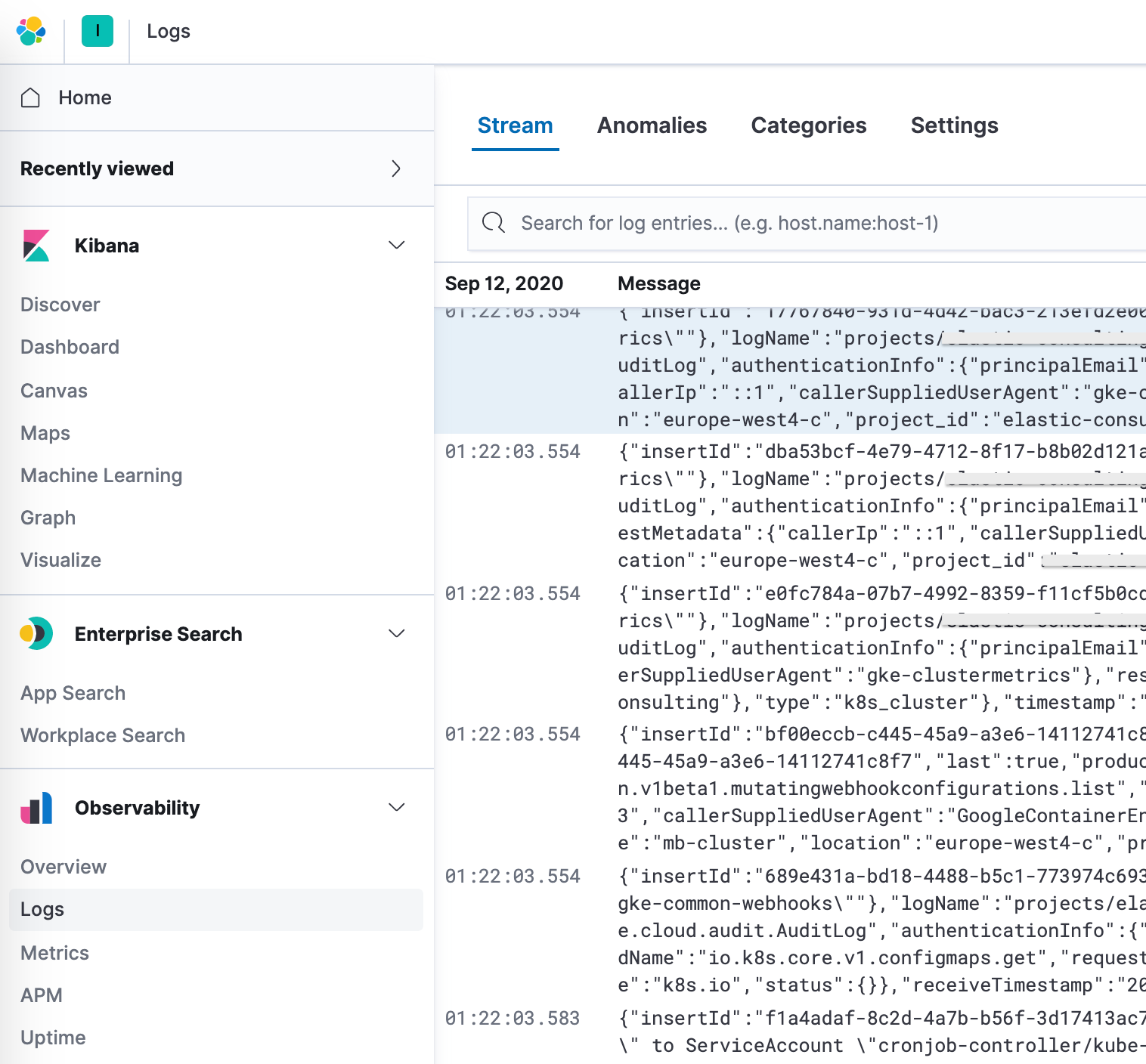
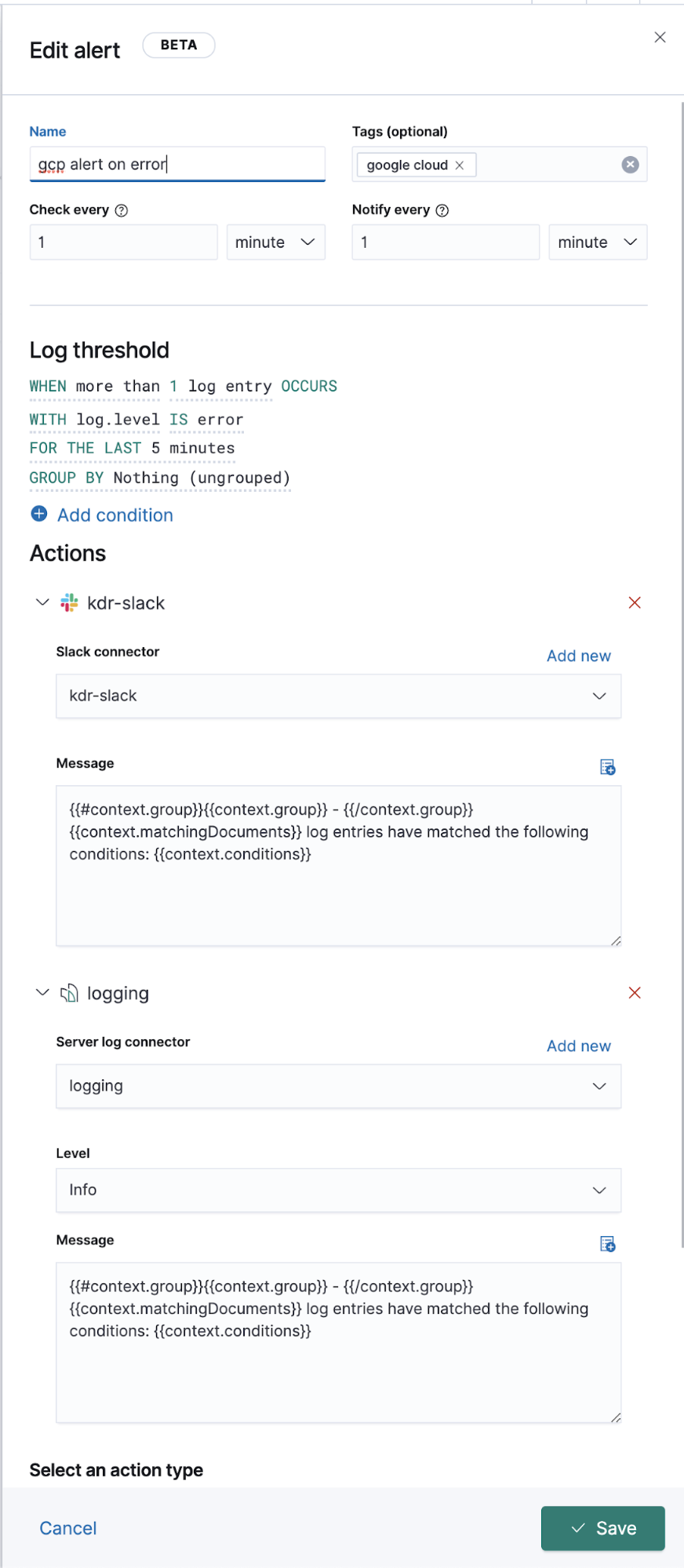
Logging extendido de Google Operations (Stackdriver)
Antes, hablamos sobre cómo enviar logs de operaciones de esos logs que tienen módulos de Filebeat, pero ¿qué sucede con los otros logs sin un módulo de Filebeat dedicado? A continuación, hablaremos sobre cómo enviar esos logs a Elastic también, para verlos junto a los demás datos de logs.
Desde el punto de vista de configuración y ajustes de Google Cloud, todo (incluido el flujo) permanece igual. Creamos un colector, tema, suscripción, sa y clave JSON. La diferencia radica solo en la configuración de Filebeat.
En segundo plano, los módulos se ejecutan en entradas y parseo preconfigurado a nivel de la fuente, y en pipelines de ingesta, en algunos casos. Los módulos de Filebeat simplifican la recopilación, el parseo y la visualización de formatos de logs comunes, pero en algunos casos se requiere parseo adicional para las entradas de Filebeat.
El módulo googlecloud usa la entrada google-pubsub internamente y proporciona algunos pipelines de ingesta específicos del módulo. Soporta logs vpcflow, audit y firewall desde el primer momento.
Configuración
En lugar de usar un módulo de Filebeat, nos suscribiremos a estos temas desde una entrada de Filebeat.
Agrega lo siguiente a tu archivo filebeat.yml:
filebeat.inputs: - type: google-pubsub enabled: true pipeline: gcp-pubsub-parse-message-field tags: ["gcp-pubsub"] project_id: elastic-consulting topic: gcp-gke-container-logs subscription.name: gcp-gke-container-logs-sub credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
En esta entrada especificamos el tema desde el cual extraeremos datos y la suscripción que se usará. También especificamos el archivo de credenciales y un pipeline de ingesta que definiremos a continuación.
Pipelines de ingesta
Un pipeline de ingesta es una definición de una serie de procesadores que se deben ejecutar en el mismo orden en el que se declaran.
Google Cloud Operations almacena logs y cuerpos de mensajes en formato JSON, lo que significa que solo debemos agregar un procesador de JSON en el pipeline para extraer los datos en el campo de mensaje a campos individuales en Elasticsearch.
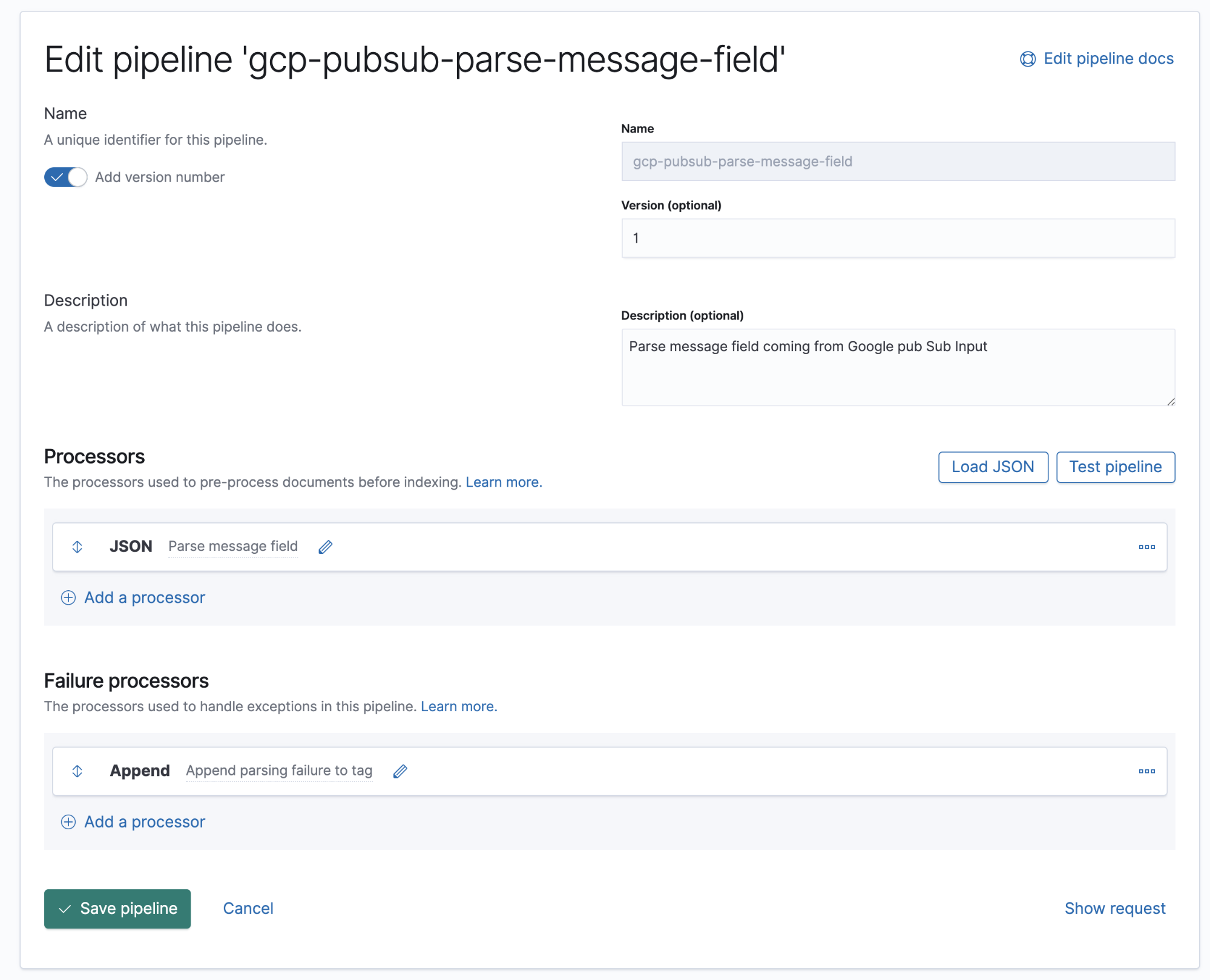
En este pipeline, tenemos un procesador de JSON que obtiene datos del campo message del documento y los extrae a un campo de destino denominado log.
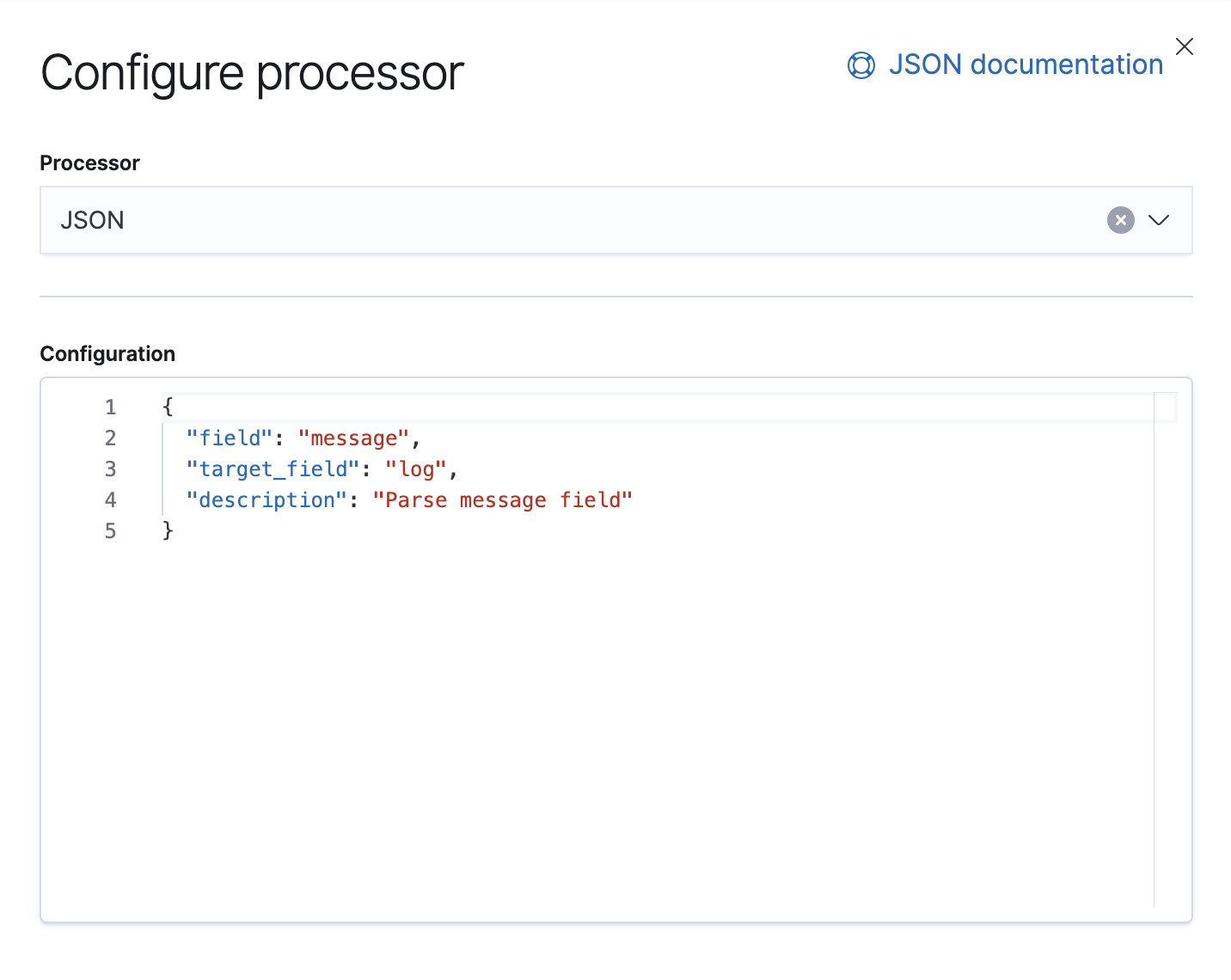
También tenemos un procesador Failure encargado de manejar las excepciones en este pipeline, en cuyo caso solo agregaremos una etiqueta.
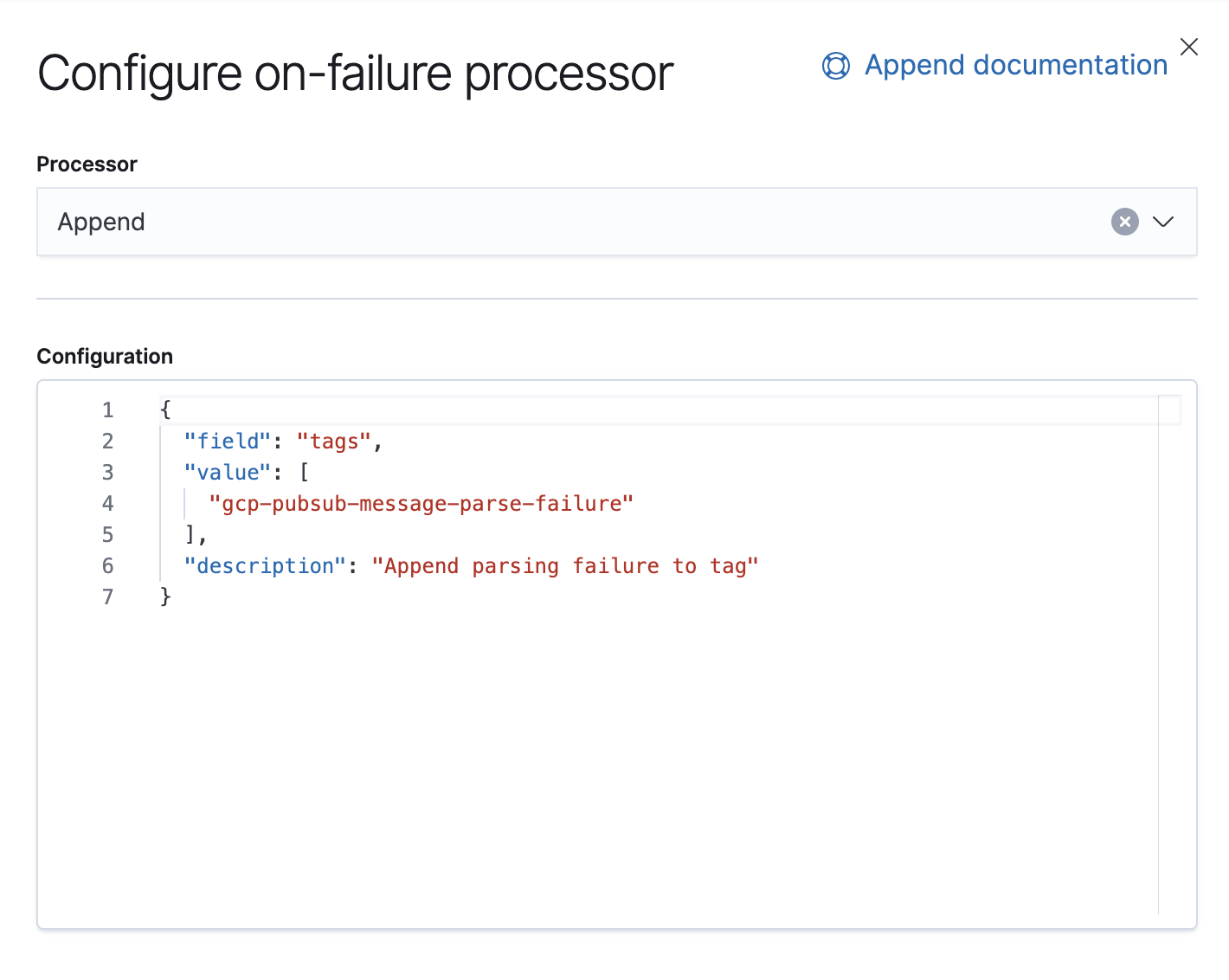
A partir de la versión 7.8, los pipelines de ingesta se pueden desarrollar a partir de una UI en Kibana, desde Stack Management → Ingest Node Pipelines. Si tienes una versión anterior, se pueden usar API. Esta es la API equivalente para este pipeline.
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version": 1,
"description": "Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description": "Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description": "Append parsing failure to tag"
}
}
]
}
Guardaremos este pipeline y, siempre y cuando tengamos este mismo pipeline configurado en la entrada google-pubsub, deberíamos empezar a ver logs parseados en Kibana.
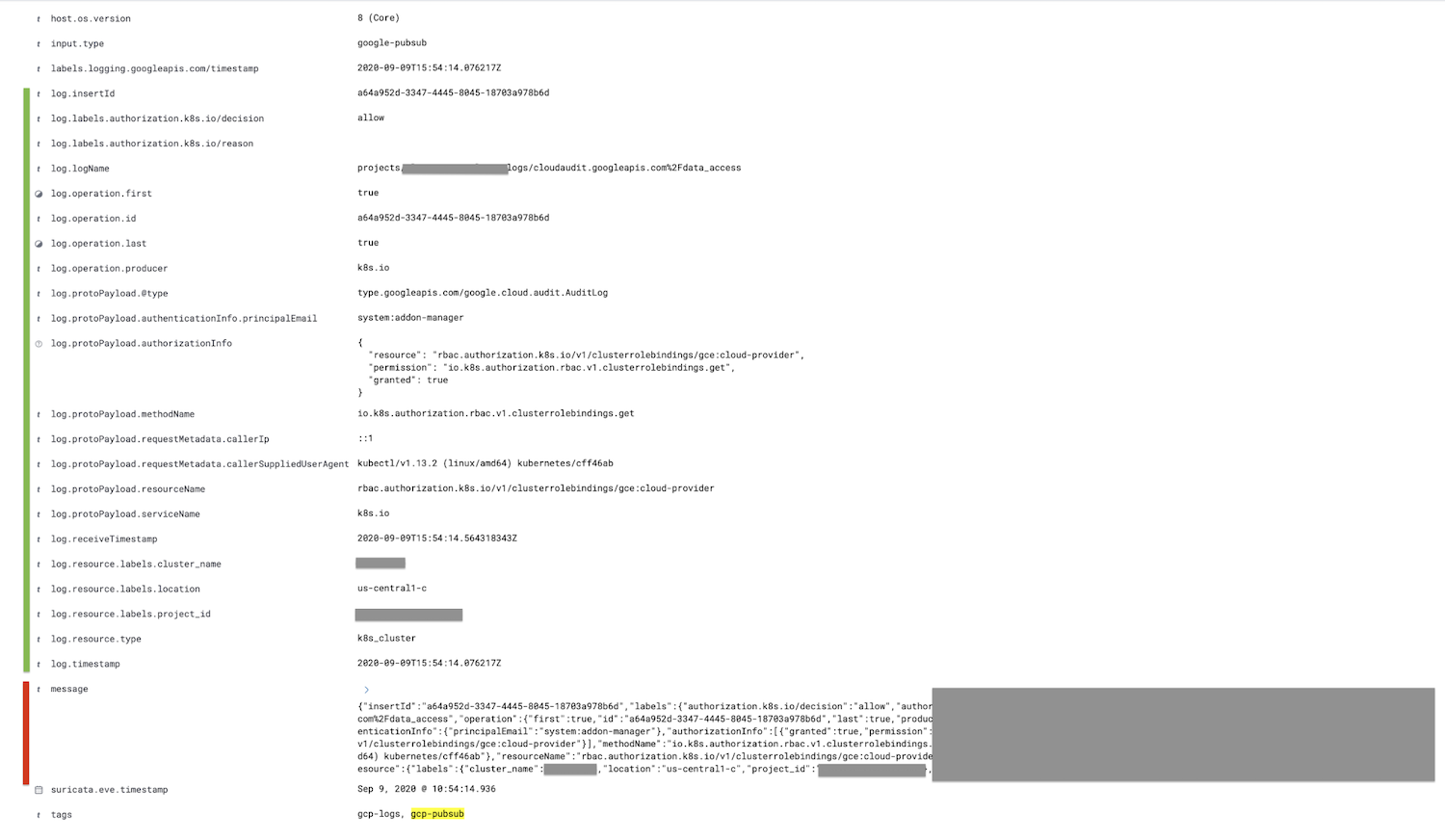
El campo marcado en rojo, el campo de mensaje, se parsea en el campo del log, y todos los campos secundarios se anidan, se muestran en verde.
De manera opcional, se puede eliminar el campo de mensaje después del procesador de JSON en el pipeline de ingesta a través del procesador de eliminación; esto reducirá el tamaño del documento.
Resumen
Eso es todo en este blog, gracias por seguir los pasos. Si tienes preguntas, inicia una conversación en nuestros foros de debate; nos encantaría conocer tu opinión. O encuentra más información sobre logging y observabilidad con Elastic en nuestro webinar a demanda.
Si deseas probar esta demostración, regístrate para una prueba gratuita de Elasticsearch Service en Elastic Cloud o descarga la versión más reciente para gestionarla tú mismo.