On-demand webinar
The Hotel NERSC Data Collect: Where Data Checks In, But Never Checks Out
Hosted by:

Thomas Davis
Project Lead
NERSC

Cary Whitney
Computer Scientist
NERSC
Overview
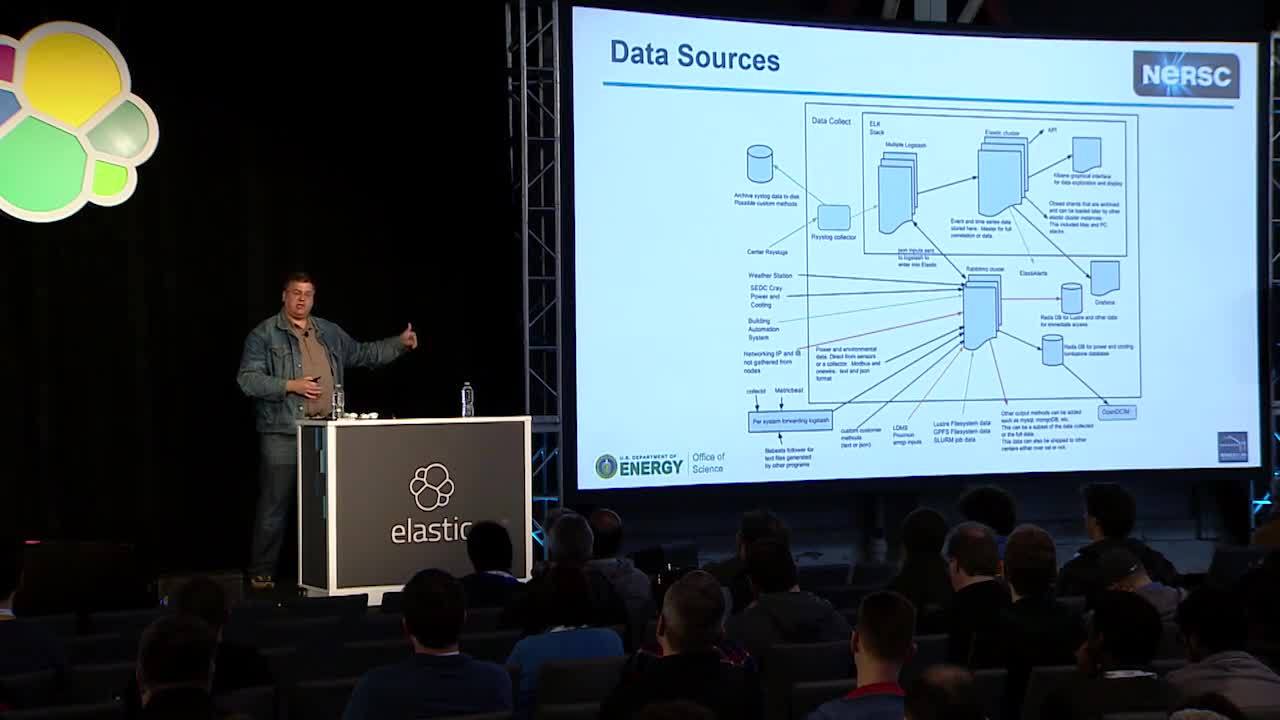
The NERSC data collect system is designed to provide access to 30TB of logs and time-series data generated by the supercomputers at Berkeley Lab. This talk will cover the life of an index inside the cluster, from initial tagging, node routing, snapshot/restore, use of aliases to combine indexes, and archiving on high disk capacity nodes using generic hardware. Additionally, Thomas and Cary will highlight several aspects of using Elasticsearch as a large, long term data storage engine, including index allocation tagging, use of index aliases, Curator and scripts to generate snapshots, long term archiving of these snapshots, and restoration.
View next
On-demand webinar
Elasticライブウェビナー:Elasticで構築する次世代自律型ワークフロー -Agent Builderによるエージェント開発とWorkflowsによる統合管理-