Grok processor
The Grok processor parses unstructured log messages using a set of predefined patterns to match the log messages and extract the fields. The grok processor is powerful and can parse a wide variety of log formats.
You can provide multiple patterns to the grok processor. The grok processor tries to match the log message against each pattern in the order they are provided. If a pattern matches, it extracts the fields and the remaining patterns won't be used.
If a pattern doesn't match, the grok processor tries the next pattern. If no patterns match, the Grok processor will fail and you can troubleshoot the issue. Instead of writing grok patterns, you can have Streams generate patterns for you. Refer to generate patterns for more information.
To improve pipeline performance, start with the most common patterns first, then add more specific patterns. This reduces the number times the grok processor has to run.
To parse a log message with a grok processor:
- Set the Source Field to the field you want to search for grok matches.
- Set the patterns you want to use in the Grok patterns field. Refer to the example pattern for more information on patterns.
This functionality uses the Elasticsearch Grok processor internally, but you configure it in Streamlang. Streamlang doesn’t always have 1:1 parity with the ingest processor options and behavior. Refer to Processor limitations and inconsistencies.
Grok patterns are defined in the following format:
{
"MY_DATE": "%{YEAR}-%{MONTHNUM}-%{MONTHDAY}"
}
Where MY_DATE is the name of the pattern.
The previous pattern can then be used in the processor.
%{MY_DATE:date}
This feature requires a Generative AI connector.
Instead of writing the Grok patterns by hand, you can select Generate Patterns to have AI generate them for you.
Generated patterns work best on semi-structured data. For very custom logs with a lot of text, creating patterns manually generally creates more accurate results.
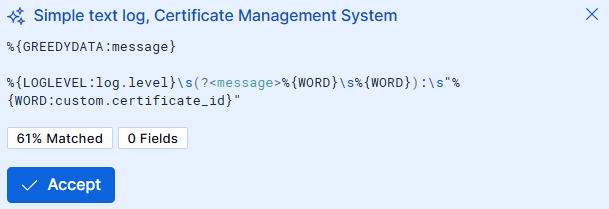
To add a generated grok pattern:
- Select Create → Create processor.
- Select Grok from the Processor menu.
- Select Generate pattern.
- Select Accept to add a generated pattern to the list of patterns used by the grok processor.
Streams groups the samples from the Data preview table into categories of similar messages. For each category, Streams generates suggestions by sending samples to the LLM. Suggestions are then shown in the UI.
This can incur additional costs, depending on the LLM connector you are using. Typically a single iteration uses between 1000 and 5000 tokens depending on the number of identified categories and the length of the messages.
In YAML mode, configure the grok processor using the following parameters. For the complete Streamlang syntax, refer to the Streamlang reference.
| Parameter | Type | Required | Description |
|---|---|---|---|
from |
string | Yes | Source field to parse. |
patterns |
string[] | Yes | One or more grok patterns, tried in order. |
pattern_definitions |
object | No | Custom pattern definitions as key-value pairs. |
ignore_missing |
boolean | No | When true, skip this processor if the source field is missing. |
- action: grok
from: body.message
patterns:
- "%{IP:attributes.client_ip} %{WORD:attributes.method} %{URIPATHPARAM:attributes.path}"
pattern_definitions:
MY_PATTERN: "%{YEAR}-%{MONTHNUM}-%{MONTHDAY}"