Using the Elastic Stack and Graph to Tackle Toxic Content
Editor's Note (August 3, 2021): This post uses deprecated features. Please reference the map custom regions with reverse geocoding documentation for current instructions.
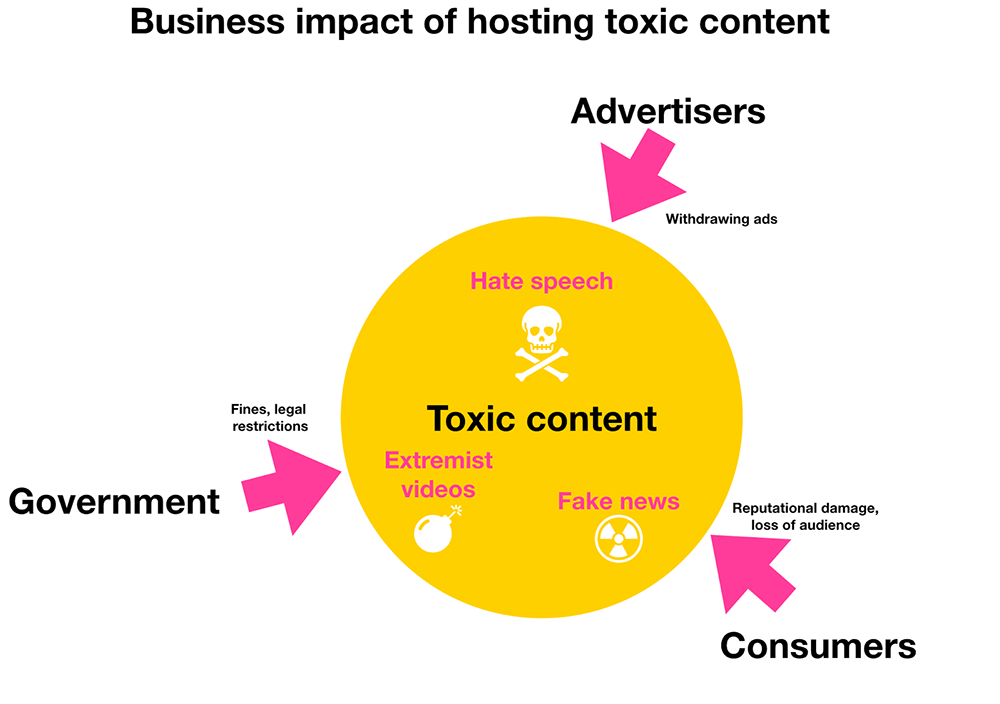
This is a challenging time for media organizations that distribute content they don't author themselves. Increasingly, sites that serve social media, music, or video are paying closer attention to the messages they're delivering.
While free speech is a widely cherished principle, in practice, most commercial organizations exercise some form of content review outlined in their own terms of service. These restrictions on content aren't motivated by an organisation's desire to act as some form of moral arbiter - often the pressures are external.
While search engines have historically helped surface content that's desirable, they can equally be applied to the challenge of identifying content that's undesirable, as we'll see in this post.
Volume of content and the complexity of making judgement calls, however, can make this task more challenging. (Not to mention the issue of balancing false-positives and false-negatives.) There are a couple of approaches (which are not mutually exclusive) to do so:
- Proactive: identify unacceptable content before site users complain
- Reactive: waiting for users to report terms-of-service violations (but can we trust their judgements? More on this later ...)
We'll explore both scenarios using real data and the Elastic Stack.
Proactively identifying content
The good news is you don't necessarily need to adopt complex analysis of your text, audio, or video content to identify candidates for review. We can use the same "people who liked X also like Y…" techniques employed by recommendation algorithms. The difference is we are focusing on users with undesirable tastes rather than desirable ones.
Let's start by looking at some real data (that we've anonymised for this post) in the form of user profiles from a music streaming service where each user profile contains their list of favourite artists. If we start with a single artist name (we'll refer to them here as fictitious "Band X") that's known to be associated with hate speech we can query the user profiles to see which other artists are favoured by these Band X fans. We can walk these connections simply by hitting the "+" button in X-Pack's Graph UI.
First, a word on meaningful relationships
Before we look at any connections, it's important to appreciate that the Graph API that underpins the UI uses some special relevance-ranking logic from our search engine heritage that is not found in typical graph databases. Let's turn this special feature off in the settings to see what problems these significance algorithms help avoid:

With this feature turned off our top suggestions for the interests of Band X fans look like this:
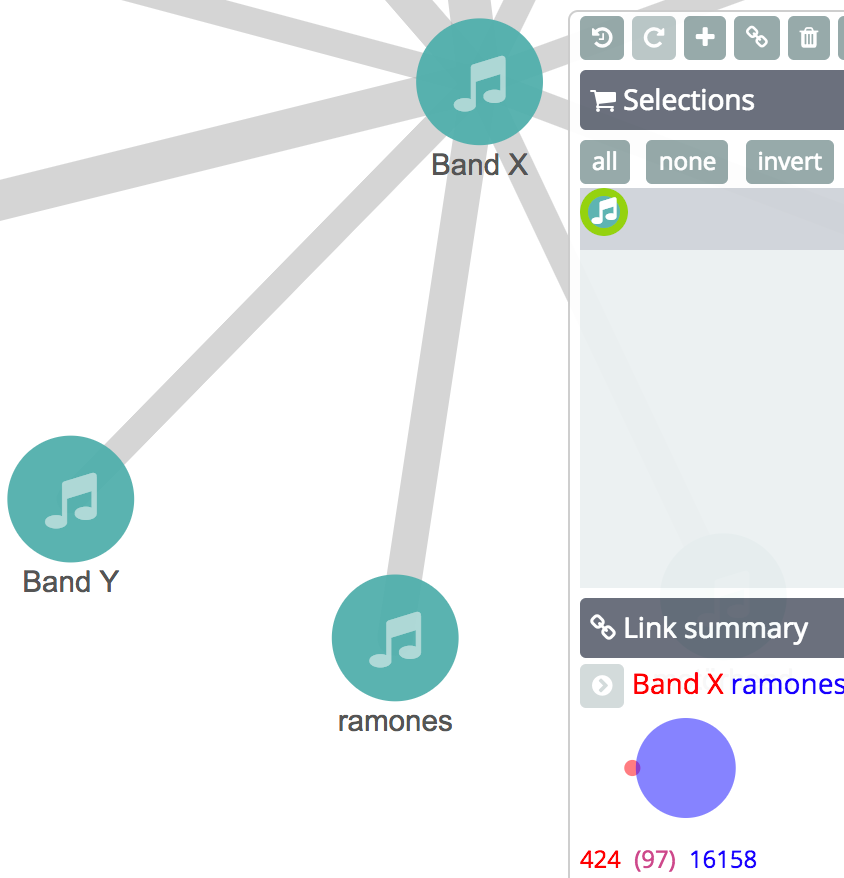
Our resulting graph shows a link between Band X and The Ramones, a popular group not known to be associated with hate speech. When we click on the link between Band X and the "ramones" suggestion, we can drill down into the stats of how many users like Band X and The Ramones using a Venn diagram. There are 97 Band X fans who like The Ramones, and while that may be a large number it is not significant — The Ramones are generally popular (just like The Beatles or Coldplay) and a huge majority of their fans have no interest in hate speech.
The Ramones are not relevant to this content exploration -- they are off-topic -- and should not appear in the top recommendations.
It should be obvious from this example that popularity is not the same thing as significance.
Let's turn the default significance setting back on:

Now when we walk the top connections let's see what significant suggestions we find:
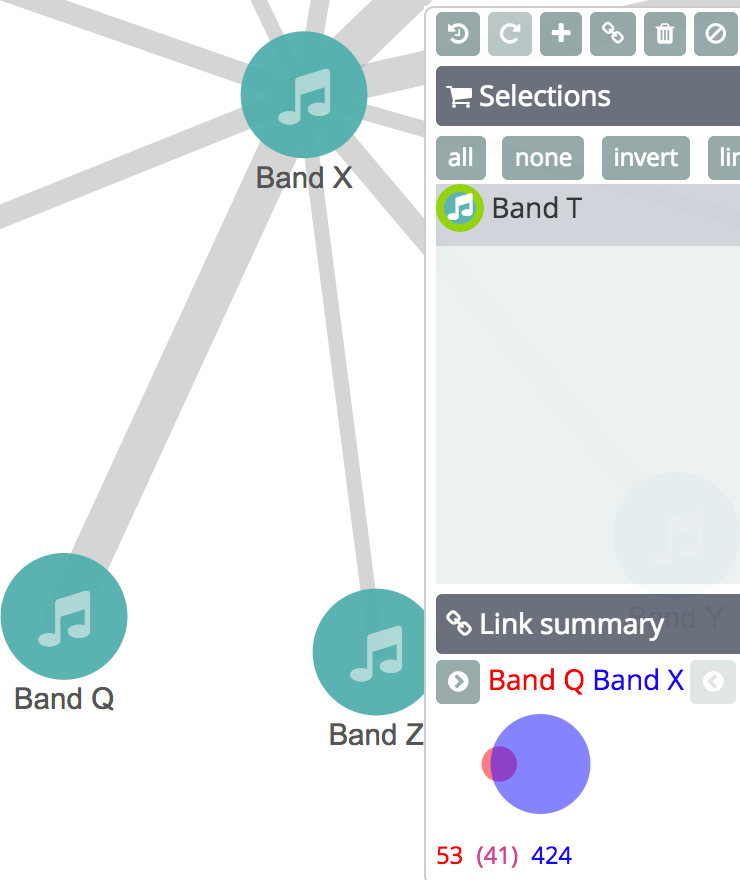
The Ramones are no longer present and instead we find "Band Q". Only 41 of the Band X fans like Band Q — but there are only 53 Band Q fans in total. That's a huge overlap and suggests that the two bands are strongly associated even though they are less popular than The Ramones.
"Band Q" is an anonymised name but you only need to see the real band names from this dataset to know that the significance algorithms are staying on topic while following the connections.
This is the first hop in what could be a multi-step expansion. We started with a single known-bad, not knowing too much about hate content, and discovered some very strong leads. When we hit the "+" button in the UI again we are now asking a much better question: find people who like bands X OR Q OR Y OR Z and widen the net to identify more sources of hate-related content.
Repeat as desired.
This same iterative operation is possible using custom client code, multiple queries, and use of the significant_terms aggregation. As demonstrated in these examples, this is very simple using the Graph UI in X-Pack.
Dealing with outputs
Using these techniques on real data, it is easy to uncover large amounts of questionable content that will need careful human review before blacklisting. That said, simple blacklisting is unlikely to be a scalable business solution due to sheer content volume, the difficulty of reviewing each case fairly, and dealing with appeals. The highest-scoring outputs of the algorithms can be manually reviewed and then blacklisted, but this may just be the tip of an iceberg.
A useful coping mechanism might be to adopt a "greylist" policy for the large numbers of lower-scoring matches that staff don't have time to review. These greylist items could only be discoverable by those users searching specifically for that content but are not promoted or recommended in any "people also like…" type user recommendations, nor are they featured alongside advertisers' messages who may not value the brand association and pull their funding.
Reactive content removal
Media organisations can also choose to rely on their site users to report undesirable content using "report this" type buttons. Sadly, like the content on a site, takedown requests may not be as innocent as the site owner would wish. Groups of like-thinking users or bots can coordinate their requests to try to remove content which they find objectionable, but is not actually in violation of a site's terms of service.
Site owners therefore need to review takedown requests and identify coordinated attempts to censor content. This activity is similar to analyzing review fraud in a marketplace where "shill" bots may be employed to artificially boost the reputation of a seller with positive feedback. However, in this use case, bad actors are trying to flood the review subject with negative feedback. The means of detecting artificial feedback is the same, though: coordinating actors typically share something in common that normal independent actors don't. This might be:
- A common IP address or user agent
- A common "hit list" of items being flagged
- A common phrase used in feedback
- The same time-of-day when logging requests
- The same site join-date.
One-off sharing coincidences between independent actors are to be expected but high numbers of these coincidences between user accounts would indicate collusion.
We can use the X-Pack Graph API to identify the coordinating actors and generate alerts which can be reviewed using the Graph UI. We can index takedown requests using a combination of these terms:
- UserId
- ContentId
- Context fields
- Review date + hour of day
- Ip address
- Town
- MD5 of description text
- Date user joined
Using the Graph API and selections of the above terms as vertices in the graph, it is possible to walk the connections for each ContentId to pull together a summary of the users objecting to that content.
Below is an example of review collusion:
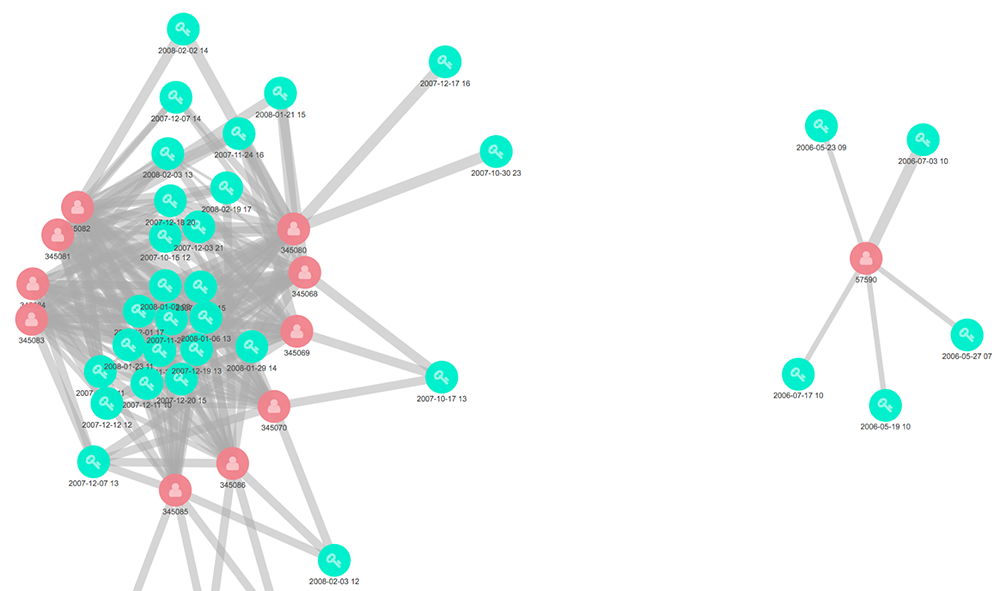
The red vertices are reviewers of a service and the blue vertices are a token that describes some aspect of their reviews (in this case I chose date+hour of review but I could also use IP address, MD5s of review text or join date). The lines show which reviewers are associated with which review aspects. The cluster on the right shows a healthy, normal reviewer — his blue vertices are not shared by many other reviewers. The cluster on the left however shows an extraordinarily high number of coincidences — many reviewers just happening to synchronise their reviewing behaviours on repeated occasions over many months. This is likely a single actor using multiple fake accounts to game the system, and these accounts are candidates for being blocked. Equally, a network showing a healthy gathering of many mature reviewers with no evidence of collusion could score the subject content as a high-confidence takedown judgement and be prioritised for human review or automatically blacklisted given a suitable score threshold.
A detailed example of setting up a review monitoring platform is here:
Summary
Companies can likely expect growing pressure to enforce their terms of service, and audience sizes and advertising revenues will depend on their ability to do so.
We need tools that help staff quickly separate signal from a sea of noise to successfully face the hard challenge of reviewing and managing content. In these examples, we've seen reactive and proactive solutions to dealing with undesirable content using features from X-Pack.
Try it for yourself today and get to grips with your own content: https://www.elastic.co/start