Which Korean analyzer shall I use?
Hangul (Korean alphabet) was created in 1443 by King Sejong the Great. Before that, Korean people used Chinese characters but only Yangban, the ruling class people could actually learn and use it and the ordinary people could hardly use it because Chinese language is so different from Korean language and it was too difficult for the ordinary people to spare time to learn.
Hangul is a phonetic alphabet and consists of 24 characters: 14 consonants (ㄱ[g], ㄴ[n], ㄷ[d], ㄹ[l/r], ㅁ[m], ㅂ[b], ㅅ[s], ㅇ[null/ng], ㅈ[j], ㅊ[ch], ㅋ[k], ㅍ[p], ㅌ[t], and ㅎ[h]) and 10 vowels (ㅏ[a], ㅑ[ja], ㅓ[ə], ㅕ[jə], ㅗ[o], ㅛ[jo], ㅜ[u], ㅠ[ju], ㅡ[ɯ], and ㅣ[i]). We can combine them and make 11172 characters (syllables), e.g. ㅎ+ㅏ+ㄴ=한.
A Korean analyzer is required to search Korean documents effectively. Korean is an agglutinative language whereas English is an inflectional language and Chinese is an isolated language. A predicate changes its form according to its ending (e.g., ‘먹다’ and ‘먹고’), and a noun is usually followed by one or more postpositions (e.g., 엘라스틱서치(noun)+를(postposition)). If we query without a Korean analyzer, we can only get a single form of the predicates or nouns. For example, if we query ‘엘라스틱서치’, we don’t get the documents including ‘엘라스틱서치를’. A Korean analyzer analyzes ‘엘라스틱서치를 이용해서 한국어 문서들을 효과적으로 검색하려면 한국어 분석기가 필요합니다’ and extracts tokens such as ‘엘라스틱서치’, ‘를’, ‘이용’, ‘해서’, ‘한국어’, ‘문서’, ‘들’, ‘을’, ‘효과적’, ‘으로’, ‘검색’, ‘하려면’, ‘한국어’, ‘분석기’, ‘가’, ‘필요’, and ‘합니다’. With these tokens, we can query ‘엘라스틱서치’ and get the documents including either ‘엘라스틱서치’ or ‘엘라스틱서치를’.
Currently Elasticsearch has commercial and open source analyzers and provides APIs to implement analyzers. Among them, seunjeon, arirang, and open-korean-text are the widely used open source Korean analyzers. Open-korean-text supports only Elasticsearch 5.x. I installed these three Korean analyzers on Elasticsearch 5.5.0 and measured time and memory consumption during analysis.
seunjeon
- URL: https://bitbucket.org/eunjeon/seunjeon
- Description: A mecab-ko-dic based Korean analyzer running on JVM. It provides Java and Scala interfaces. It includes the dictionary and you don’t need to install mecab-ko-dic separately.
- License: Apache 2.0
arirang
- URL: https://github.com/HowookJeong/elasticsearch-analysis-arirang
- Description: korean analyzer (lucene analyzer kr arirang)
- License: as-is
open-korean-text
- URL: https://github.com/open-korean-text/open-korean-text
- Description: Open-source Korean Text Processor (Official Fork of twitter-korean-text)
- License: Apache 2.0
To see the effect of the JIT compiler, I ran the same test twice when I measure the analysis time. I used ‘time’ (http://man7.org/linux/man-pages/man1/time.1.html) to measure time to analyze a Korean text (see at.sh, ot.sh, and st.sh in the appendix). I ran it once just after starting Elasticsearch, and then ran it again without restarting Elasticsearch.
Fig. 1 Time to analyze a Korean text
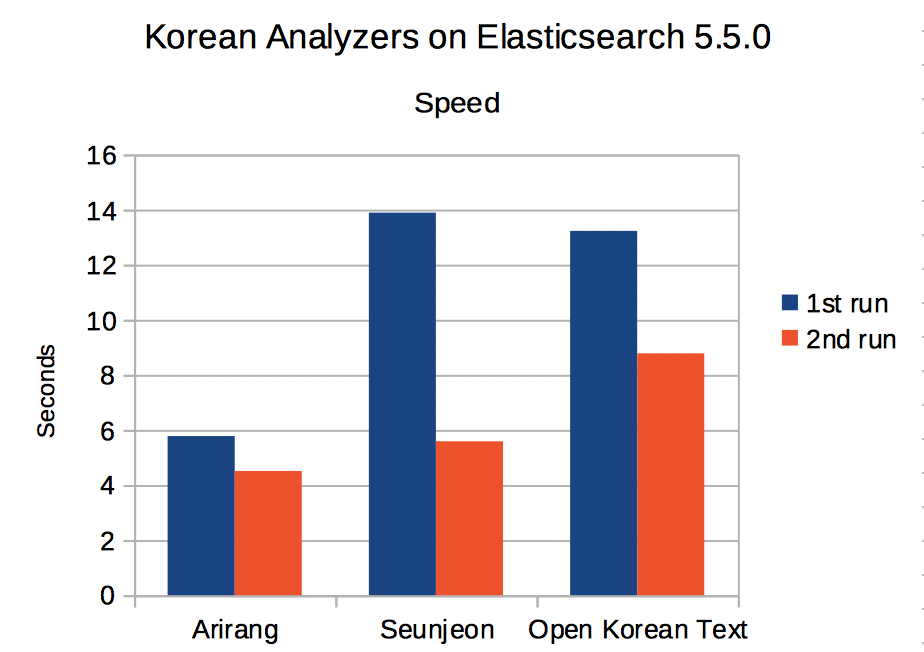
Arirang is the fastest in the both runs, but the 2nd run of seunjeon is much faster than its 1st run. Open-korean-text is similar or a bit slower than seunjeon.
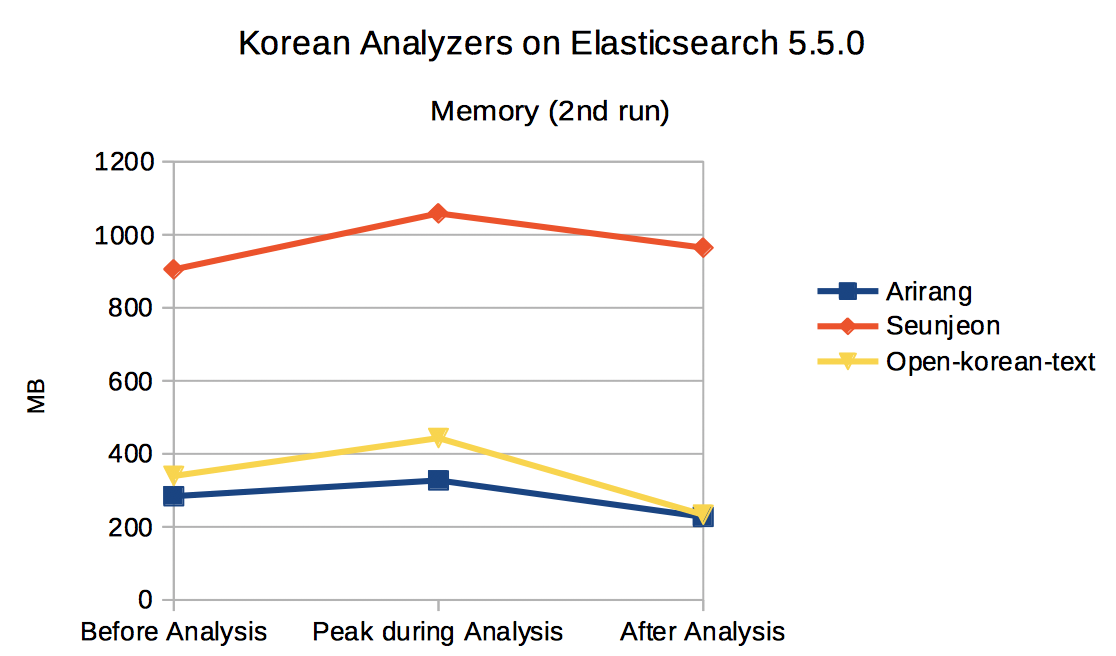
Memory (Java heap) consumption was measured at the three points: just before the analysis, maximum usage during the analysis, and just after the analysis. I used ‘jstat -gc’ (https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html) to measure the memory consumption (see am.sh, om.sh, and sm.sh in the appendix). Again, I ran the same test twice. I ran it once just after starting Elasticsearch, and then ran it again without restarting Elasticsearch.
Arirang showed almost no difference among them, whereas seunjeon showed big increase during the analysis. Open-korean-text showed moderate increase during the analysis but it is mostly released after analysis.
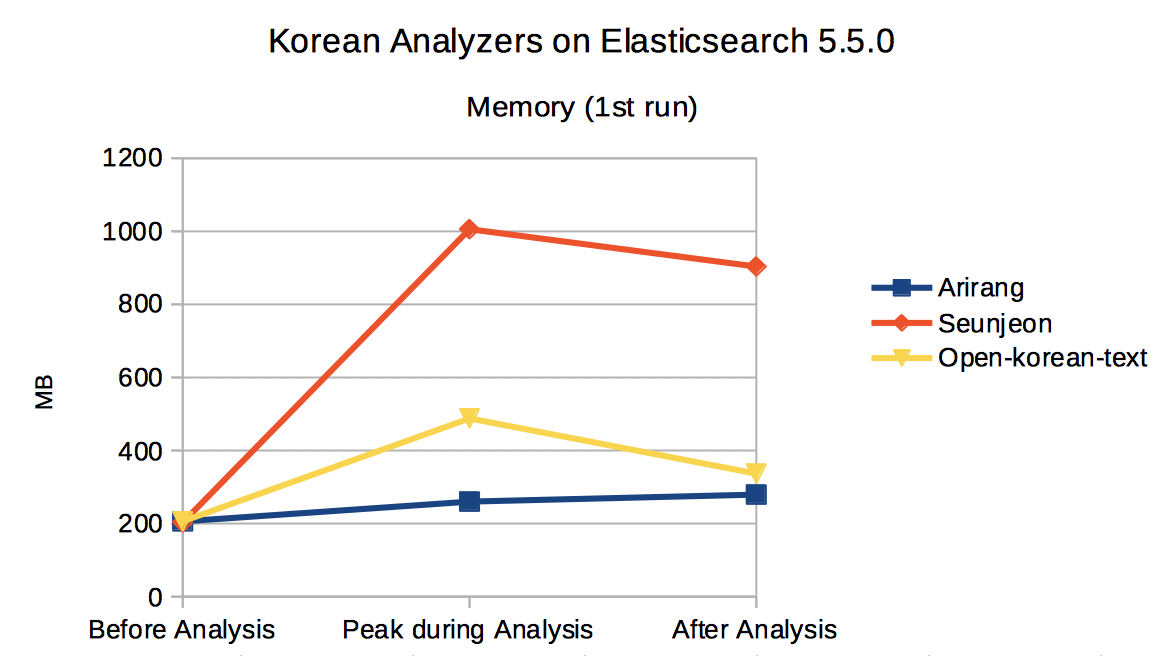
Fig. 2 Memory consumption during Korean text analysis (1st run)
Fig. 3 Memory consumption during Korean text analysis (2st run)
Finally let’s see the analysis results. The original string is the preface King Sejong wrote when he invented Hangul. I used the same string for the time and memory consumption test.
“나라의 말이 중국과 달라 한자와는 서로 맞지 아니할새 이런 까닭으로 어리석은 백성이 이르고자 하는 바 있어도 마침내 제 뜻을 능히 펴지 못할 사람이 많으니라 내 이를 위하여, 가엾게 여겨 새로 스물여덟 자를 만드나니 사람마다 하여금 쉽게 익혀 날마다 씀에 편안케 하고자 할 따름이니라” (translation: Korean language is different from Chinese language. It doesn’t fit in with Chinese characters. Many Korean people have difficulty expressing themselves with Chinese characters. To help them, I invented new 28 characters. I hope people learn and use them easily in daily life.)
Table 1. Analysis results
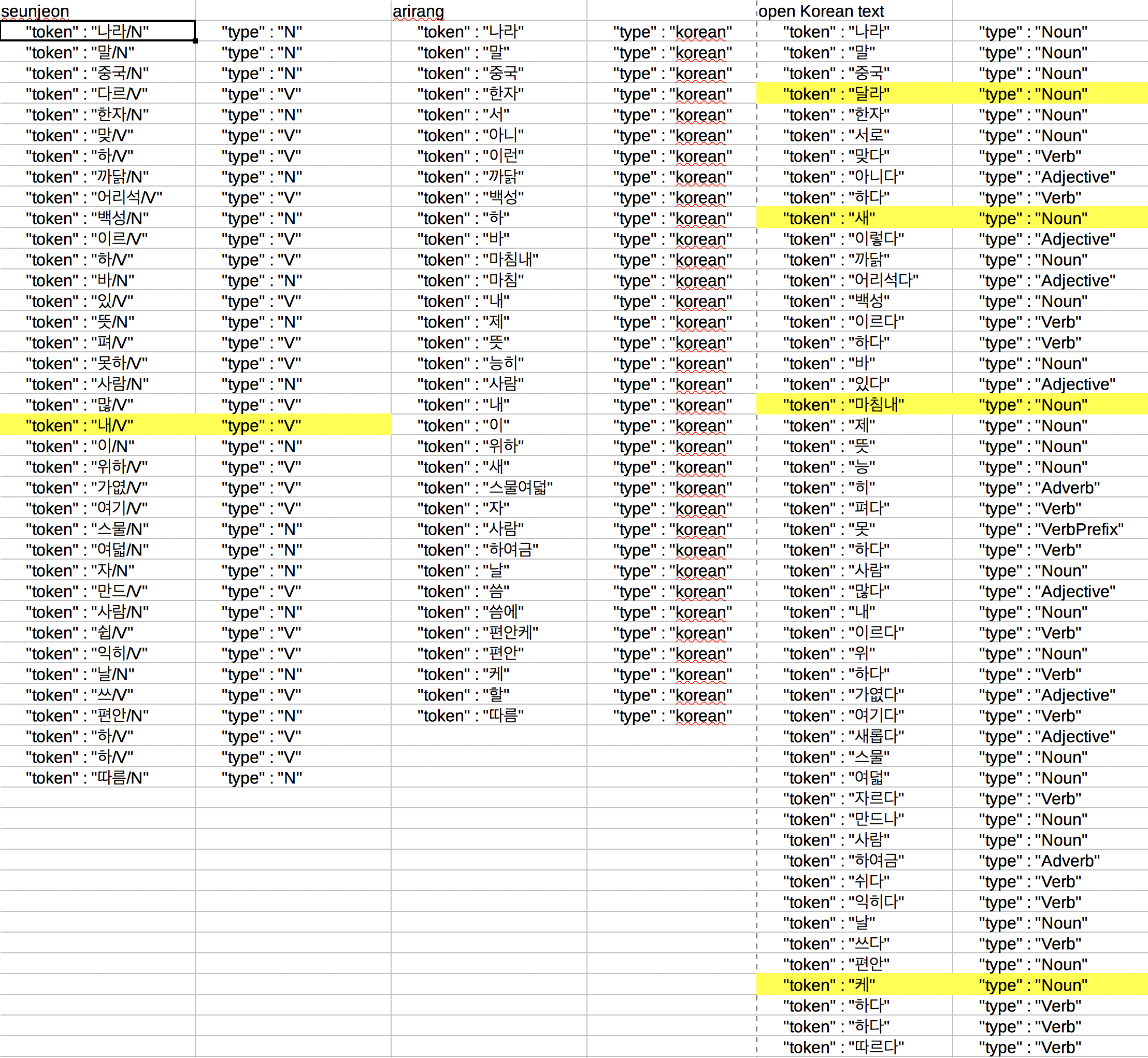
Open-korean-text extracts the most tokens and differentiates adjective and verb but mis-analyzed ‘달라’, ‘새’, ‘마침내’, and ‘케’ as nouns. Seunjeon also mis-analyzed ‘내’ as verb. Arirang doesn’t provide the part of speech information.
By the way, how much portion of the total indexing time does the Korean analyzers take? When I tested with seunjeon, the total indexing time was 29.036 seconds (1st run) and 20.952 seconds (2nd run). The Korean analyzers took 47.83% and 26.67% of the total indexing time respectively. Memory consumption increase was 802 MB during analysis and 853 MB during indexing, which means Korean analyzer takes much part of the total memory consumption during indexing. Analysis time affects indexing time more than search time because in search time, you’ll only analyze short keywords, not the already indexed long text.
Based on this test result, no one Korean analyzer seems to be absolutely superior. Arirang can be a good candidate when speed and memory consumption is important. But you’ll have to use seunjeon or open-korean-text if you need the part of speech information. One thing to remember is that Korean analyzers take considerable amount of time and memory during indexing and the choice of Korean analyzers is very important in your Elasticsearch configuration.
Appendix (scripts.tar.bz2)
- Scripts to measure analysis time of seunjeon, arirang, and open-korean-text (st.sh, at.sh, and ot.sh)
- Scripts to measure memory consumption of seunjeon, arirang, and open-korean-text during analysis (sm.sh, am.sh, and om.sh)
- Scripts to measure indexing time of seunjeon (sit.sh)
- Scripts to measure memory consumption of seunjeon during indexing (sim.sh)