This year in Apache Lucene - 2019
As another year is coming to an end, let's take time to look at what happened in Lucene land in 2019.
Active community
There are not that many projects that are 20+ years old and still as dynamic as Apache Lucene. In 2019:
- 7 community members were made committers
- 4 committers became Project Management Committee (PMC) members
- 9 new versions were released, including a major version: 8.0
In particular, we are glad to report that two Elasticians became PMC members this year, Ignacio Vera and Nick Knize. Congratulations, Ignacio and Nick!
One metric that has especially improved over the last few years is the number of unique authors in the git log:
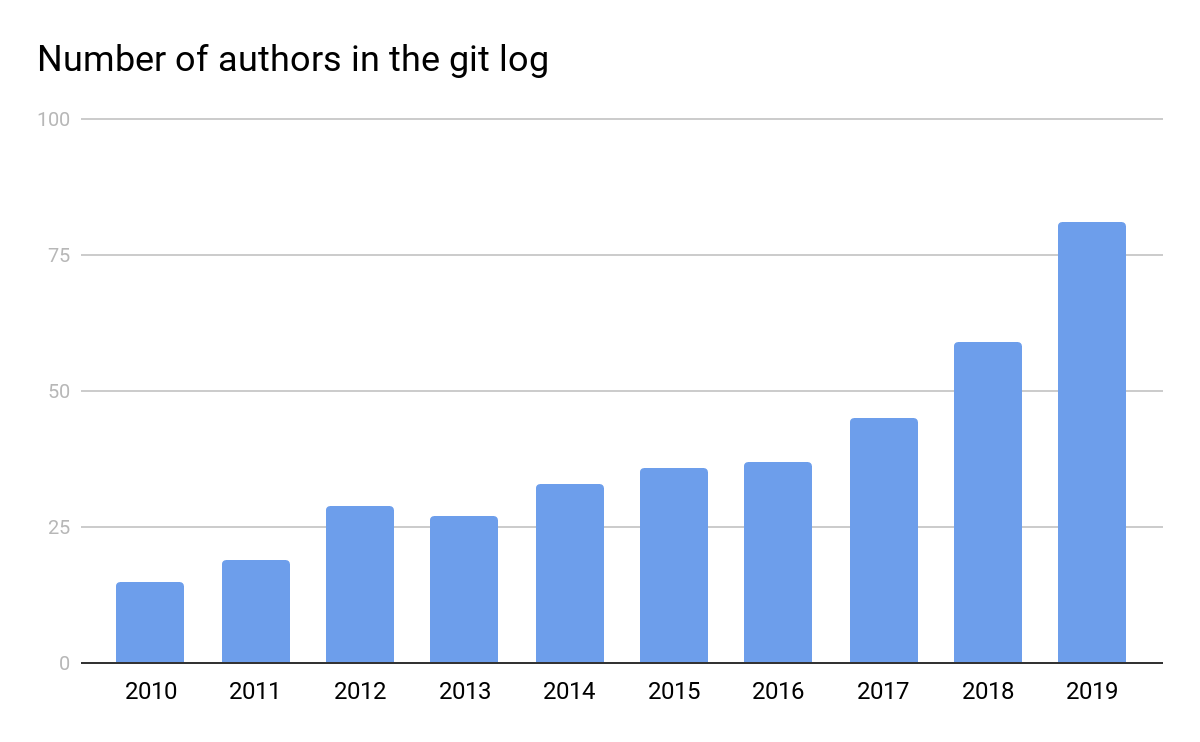
To be fair, part of this increase is due to the migration of Lucene's repository from Subversion to Git in 2016, which made it easier to preserve the name of the author of a contribution. Before that, contributions would always be attributed to the committer who merged the contribution in the git log, and the contributor would only be mentioned in the changelog. But there have also been efforts to make contributing to Lucene easier. While contributions used to require creating patches manually and attaching them to a JIRA issue, it is now also possible to open a pull request on Github, which any committer can merge by just clicking on a button. This simpler process, which also looks much more similar to a majority of open-source projects, certainly helps attract new contributors.
Many new features and improvements
Block-Max WAND
Robert Muir, Jim Ferenczi and I worked on adding support for Block-Max WAND to Lucene, which was Lucene 8.0's main release highlight. Block-Max WAND is a retrieval technique that allows to retrieve the top hits of a disjunction (bool query that only has should clauses) without visiting all matches. This technique can make some queries hundreds of times faster with the only downside that the hit count is not computed.
It was released alongside a new FeatureField, which allows to incorporate static scoring signals into the final score while still taking advantage of Block-Max WAND. For instance, one could index a pagerank as a FeatureField and could use this field to compute scores as bm25_relevance + log(pagerank). FeatureField is exposed in Elasticsearch via the rank_feature and rank_features fields.
Luke has become a Lucene module
The Luke tool is well known from Lucene users: it allows you to introspect the content of an index. For instance Luke can be used to list the content of the terms dictionary. One major challenge for Luke users was that versions were lagging a bit behind, so if you upgraded to a recent version of Lucene soon after its release, there might be a couple weeks until a new version of Luke was released for that version. But thanks to Tomoko Uchida and Uwe Schindler, Luke is now a Lucene module, which gets released alongside every new Lucene version and can be used right away.
Lucene got a new "monitor" module
Alan Woodward and his former colleagues at FlaxSearch decided to donate Luwak, a framework that helps find all queries that would match a document, like Elasticsearch's percolator. It has been incorporated into Lucene as module called "monitor".
Much faster indexing of multi-dimensional points
Constructing a BKD tree requires recursively partitioning a set of multi-dimensional points around the median value of the dimension that has the widest span of values. Computing the median value used to sort values offline with a merge sort. Ignacio Vera optimized it by taking inspiration from the radix sort algorithm in order to more efficiently compute the median value. This translated into significant indexing speedup for geo points, range fields and geo shapes. See annotations AE, AF and AG on the nightly geo benchmarks.
Increased efficiency
Sometimes there are small improvements that give a lot of value when combined together. This year again, Lucene received a number of neat optimizations:
- Mike Sokolov and Bruno Roustant helped improve the efficiency of FST lookups on dense nodes by indexing outgoing labels using a bitset instead of performing a binary search.
- Ankit Jain introduced the ability to read FSTs directly from disk, which can be especially useful as the terms index is an FST and usually drives the memory usage of Lucene indices.
- Jack Conradson did a similar change for BKD trees, which helps save even more memory.
- I worked on a change to how postings are encoded so that the decoding logic gets auto-vectorized.
Thanks for following along for the last 12 months, and let's wish Lucene another great year in 2020!