Bringing speedups to top-k queries with many and/or high-frequency terms


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
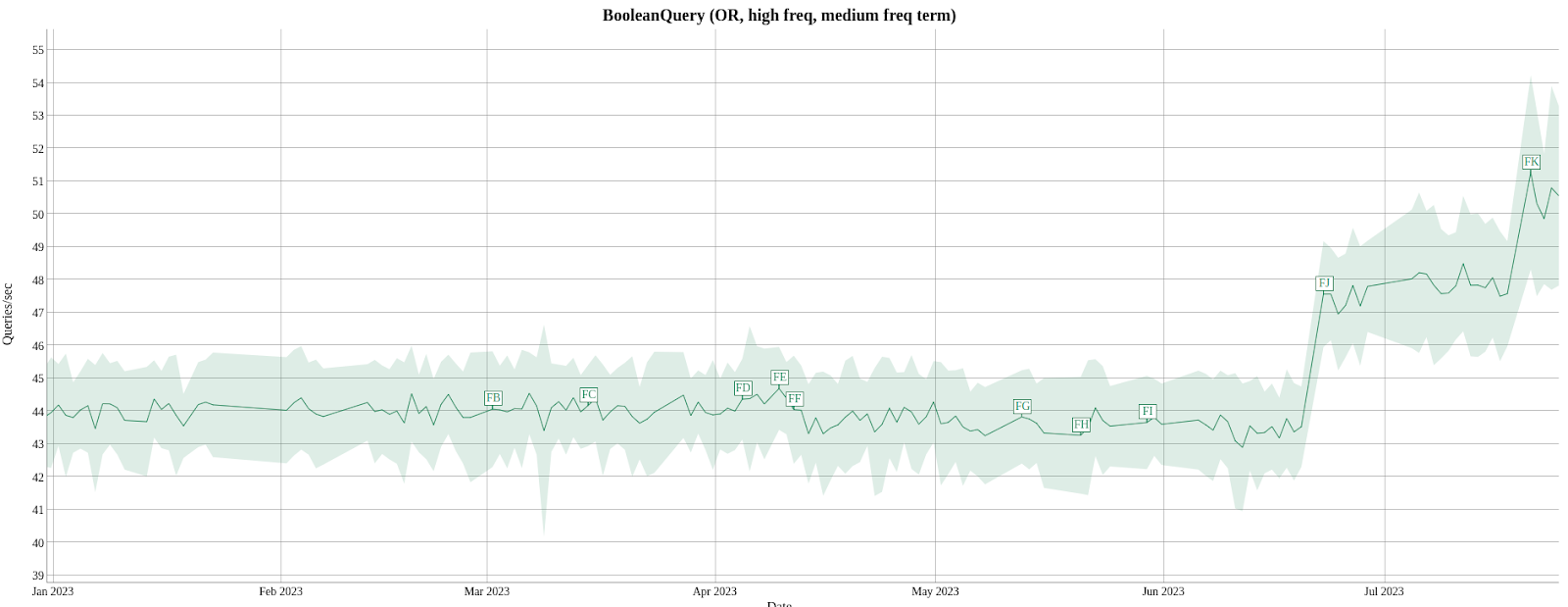
Disjunctive queries (term_1 OR term_2 OR ... OR term_n) are extremely commonly used, thus they are getting a lot of attention when it comes to improving query evaluation efficiency. Apache Lucene has two main optimizations for evaluating disjunctive queries: BS1 on the one hand for exhaustive evaluation, and MAXSCORE and WAND on the other hand to compute top hits. Until recently, these two optimizations were never used together, but this changed in order to improve query performance, especially with many clauses and/or high-frequency clauses. See annotation FK on the chart below taken from Lucene's nightly benchmarks.
What is BS1?
In Apache Lucene, queries are responsible for creating sorted streams of matching doc IDs. Implementing a disjunctive query boils down to taking N input queries that produce sorted streams of doc IDs and combining them into a merged sorted stream of doc IDs. The textbook approach to this problem consists of putting input streams into a min-heap data structure ordered by their current doc ID. This approach has been referred to as BooleanScorer2 (BS2) in Lucene.
While BS2 works nicely, it gets a bit of overhead from having to rebalance the heap every time that it needs to move to the next match. BS1 tries to reduce this overhead by splitting the doc ID space into windows of 2,048 documents. In every window, BS1 iterates through all matching doc IDs, one clause at a time. On every doc ID, it computes the index of this doc ID in the window, sets the corresponding bit in a bitset, and adds the current score to the corresponding index in a double[2048]. Iterating matches within the window, then consists of iterating bits of the bitset and looking up the score at the corresponding index in the double[2048]. This approach often runs faster with queries that have many clauses or high-frequency clauses.
These two approaches have been described in a 1997 paper called "Space Optimizations for Total Ranking" by Doug Cutting, the creator of Lucene. BS2 is called "Parallel Merge" in this paper and described in section 4.1, while BS1 is called "Block Merge" and described in section 4.2. These are arguably more descriptive names than BS1 and BS2. Note that the description of "Block Merge" in the paper is quite different from what it looks like in Lucene today, but the underlying idea is the same.
What are MAXSCORE and WAND?
Can you evaluate fewer hits if all you care about are the top-k matches by score? The answer is yes. And this is what the MAXSCORE and WAND algorithms are about. While these algorithms differ, they are based on the same idea — if you can get a good upper bound of the scores that each clause can produce, then you could use this information to skip hits that have no chance of making it to the top-k hits. See this other blog for more information on this topic.
These algorithms can often return top-k results several times faster compared to exhaustive evaluation. However, there are also cases when they don't work well. A few examples include:
- Disjunctive queries over many terms
- Disjunctive queries over queries that have suboptimal score upper bounds, such as a disjunction of conjunctions like (a AND b) OR (c AND d) wouldn't see as much speedup with MAXSCORE/WAND as disjunctions of term queries
- Wacky weights, often used by learned sparse retrieval models, such as Elastic Learned Sparse EncodeR (ELSER)
A challenge when these optimizations can't really help with skipping hits is that we're still paying for their overhead. This is because both implementations require reordering some data structures on every match — such is the case of BS2 because of the min-heap. For instance, we have some queries produced by ELSER that run up to 5x slower with WAND compared with BS1. This is due to the combination of missing the BS1 optimization, WAND not being successful at actually skipping hits, and the additional per-match overhead that WAND brings because of the reordering of data structures.
MAXSCORE meets BS1
Until recently, BS1 and MAXSCORE/WAND were never used together. BS1 would get used when scores are not needed or exhaustive evaluation is needed. Meanwhile, MAXSCORE or WAND would get used when only top-k hits by descending score are requested.
While looking into the above challenge with regard to the overhead of MAXSCORE and WAND, we noticed that the MAXSCORE algorithm in particular could easily benefit from the same optimization that helped BS1 get faster than BS2. We implemented this idea and evaluated it against both exhaustive evaluation via Lucene's BS1 and existing top-k optimizations via MAXSCORE and WAND:
- 10M-documents data set extracted from the English Wikipedia.
- Disjunctions across 2 to 24 high-frequency terms whose document frequencies range from 400K to 4M documents.
- Queries run in a single thread, and performance is evaluated through the number of queries that can run per second. Higher numbers are better.
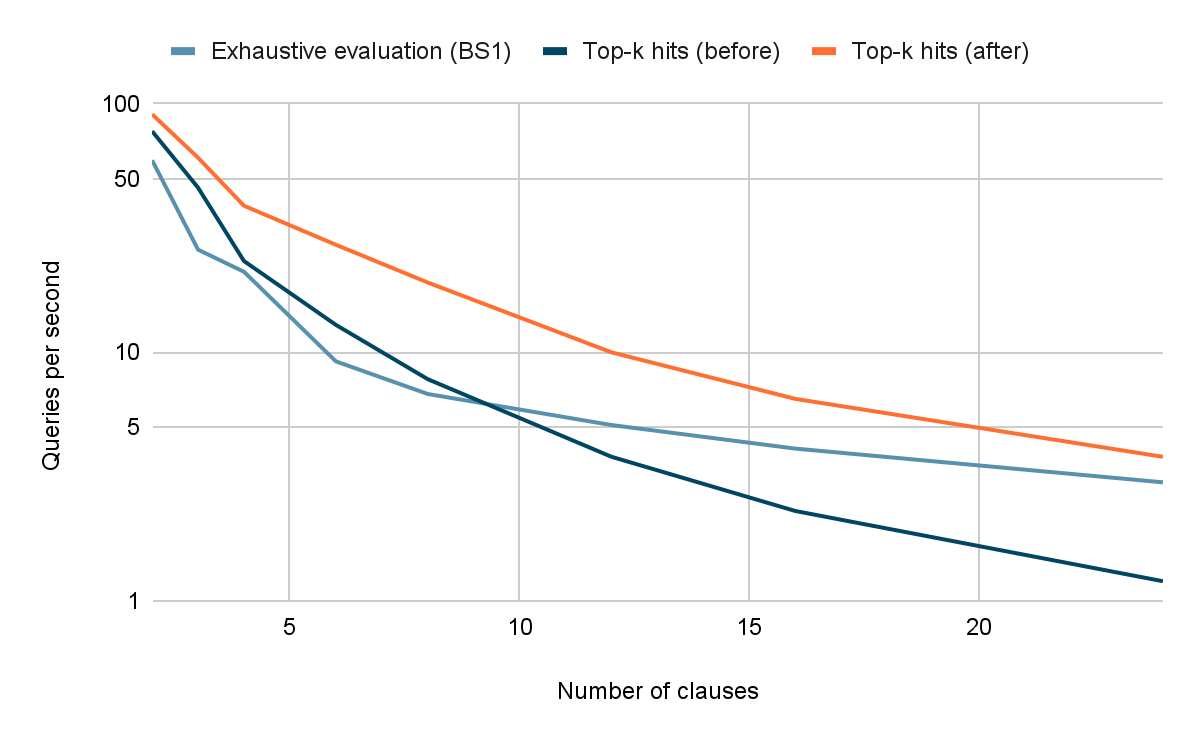
As the above chart shows, it only takes 8 terms before exhaustive evaluation runs faster than top-k optimizations, as the latter could not skip enough hits to compensate for their overhead. Worse, with 24 terms, trying to use top-k optimizations made the query run 2.5x slower compared to exhaustive evaluation.
However, the new evaluation logic for disjunctive queries that combines BS1 with MAXSCORE consistently outperformed both exhaustive evaluation and existing top-k evaluation for this set of queries.
This improvement is expected to ship in Lucene 9.8 and then in Elasticsearch in the near future. Basically, this means that query performance should get better when doing top-k searches over disjunctive queries, especially when:
- there are many clauses,
- and/or some clauses have a high frequency,
- and/or some clauses produce suboptimal score upper bounds.
Thanks for reading this blog — we hope you'll enjoy the query speedups! If you would like to learn more about optimizations for top-k query processing, check out this other blog where we describe how these optimizations were introduced in Elasticsearch 7.0/Lucene 8.0.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print