Search for Things (not Strings) with the Annotated Text Plugin
In Elasticsearch 6.5, we added a new field type plugin: mapper annotated text.
The limitations of “plain” text
The text field type is familiar to most users of Elasticsearch. It is what we use to index content like the text of this document. Elasticsearch breaks a large free-text string into multiple smaller tokens (each token typically representing a single word). The tokens are then organized in an index so that we can efficiently search for these entities.
There are a few problems with search using unstructured text:
- Many subjects are multiple words, e.g “John F. Kennedy”, but are indexed as independent tokens
johnfandkennedy. Searchers looking for John F Kennedy would have to use phrase queries to ensure the tokens are grouped so you don’t just match everyone called John. - Single words often relate to many subjects e.g “JFK” in a document could refer to the airport, the president or a movie. Searchers for the president would potentially mistakenly match the airport.
- A subject may have multiple aliases e.g. JFK or John F. Kennedy. A searcher would have to use OR expressions to match all of the aliases.
These problems can be overcome if we search for “things, not strings” (aka Entity Oriented Search). This approach requires that the subjects of interest in text are tagged with unique IDs.
What is “annotated” text?
As internet users, we are already quite familiar with the use of annotations. This document contains several of them in the form of hyperlinks. In each case, the hyperlink was used to enrich selected words used in the plain text with a link to the definitive article on the subject they reference. Annotation values don’t have to be URLs, but any form of string that uniquely identifies a referenced subject is typically the goal.
Elasticsearch has a new field type specifically for holding annotated text and it is defined in your index mapping using the “annotated_text” field type:
"mappings": {
"_doc": {
"properties": {
"my_rich_text_field": {
"type": "annotated_text",
"analyzer": "my_analyzer"
}
}
}
}
Note that, like text fields, you can use an arbitrary choice of analyzer to tokenize the plain-text values as you wish, but any special annotation values are indexed untreated by your choice of analyzer.
The content of annotated text fields uses a Markdown-like syntax to add annotation values to selected sections of text e.g.
"my_rich_text_field" : "Today [elastic](Elastic+Inc.) announced"
In the above example, the potentially ambiguous text “elastic” has been enriched with an annotation for the full entity name “Elastic Inc.”. Note that annotation values must be URL-encoded so the space character in the name has been replaced with “+”. This value is decoded before insertion into the index (but not lowercased or subjected to any other form of analysis). The annotation is injected into the token stream at the same token position and character offset as the text to which it is anchored. We can see the results of this using the _analyze API:
POST my_index/_analyze
{
"field": "my_rich_text_field",
"text": "Today [elastic](Elastic+Inc.) announced"
}
The tokens produced are as follows:
{
"tokens": [
{
"token": "today",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "Elastic Inc.",
"start_offset": 6,
"end_offset": 13,
"type": "annotation",
"position": 1
},
{
"token": "elastic",
"start_offset": 6,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "announced",
"start_offset": 14,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 2
}
]
}
Note that the “Elastic Inc.” token appears at exactly the same position and offset as the word “elastic” to which it was anchored. In this respect it behaves like a synonym, but unlike synonyms, we aren’t employing a one-size-fits-all rule that says all uses of the word “elastic” must also be tagged as “Elastic Inc.”. An annotation is more focused, limiting the scope to this particular use of the word “elastic” in this particular document and sentence. A document that talks about “elastic waistbands” would not be similarly tagged.
We aren’t limited to tagging text with a single annotation token - we can inject multiple tokens at the same position using a “&” character to separate values (in the same way URL parameters are separated):
Today [elastic](Elastic+Inc.&Search_Company) announced
How can I use annotated text?
Great question. Now that you have structured information woven into your unstructured text this opens up some interesting possibilities. You’re now in the position to search for “things not strings”. By this we mean that regardless of the word strings used in the original text (and any ambiguities, aliases or typos that may entail) you can now search the text using unambiguous, normalized IDs for your subject of interest. Precision is increased because our search for elastic the company does not match documents talking about elastic waistbands and recall is increased because we also find those documents where the authors insisted on calling the company “elasticsearch”.
Because we store position information of annotation tokens, we can:
- Highlight the text to show exactly where your subject was mentioned.
- Use positional queries, e.g. find documents where a “Search_Company” was mentioned next to the text “announced” or “released”.
Let’s look at examples of these in action:
Demo application: Highlighting things not strings
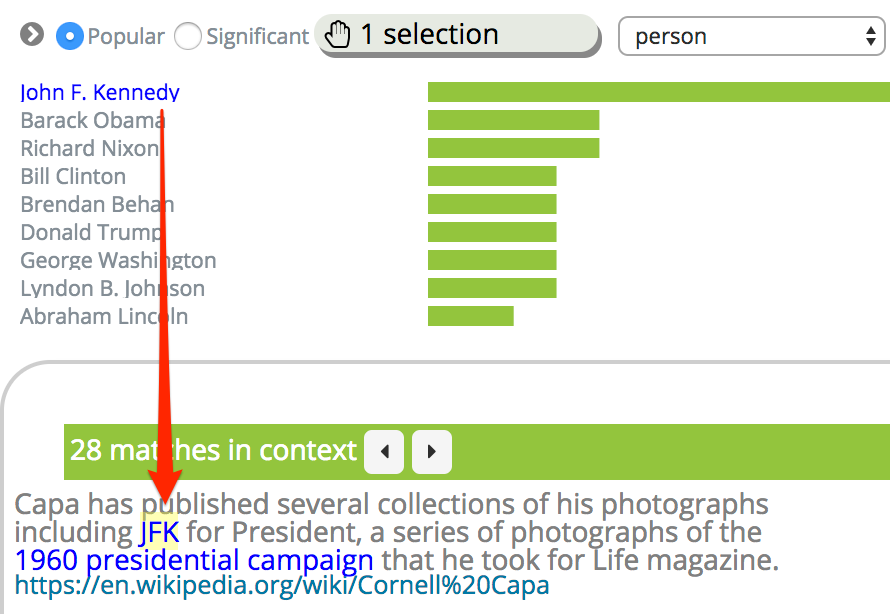
In this example application we are looking at Wikipedia content. The user is shown a bar chart from a structured keyword field “person” which holds just the IDs of articles about people. The user has clicked on the “John F. Kennedy” term to preview examples of where this value is used in the text of articles. Note that the highlighted text snippet is the string “JFK” but because it was annotated with the id “John F. Kennedy” it matches the search and is highlighted in yellow. This is a good example of what it means to “match the thing not the string”.
Let’s break down how this example application works under the covers. The relevant section of the mapping for this index looks like this:
{
"wikipediaannotated": {
"mappings": {
"_doc": {
"properties": {
"person": {
"type": "keyword",
},
"text": {
"type": "annotated_text"
}
}
}
}
}
}
The relevant parts of the example document look like this:
{
"person": ["Cornell Capa", "John F. Kennedy"],
"text": "...including [JFK](John%20F.%20Kennedy) for ..."
}
Note that the client application has ensured the annotation tokens used in the “text” field are URL-encoded and included in the structured field “person”.
When the user clicks on the bar chart the application runs the following query:
{
"query": {
"term": {"person": "John F. Kennedy"}
},
"highlight": {
"fragment_size": 200,
"require_field_match": false,
"type": "annotated",
"fields": { "text": {} }
}
}
Note that:
- The highlighter used must be of type annotated.
- The require_field_match parameter must be set to false so that our search term strictly targeting the
personfield can be relaxed to highlight tokens found in thetextfield.
The highlighter response looks like this:
"highlight": {
"text": [".. including [JFK](_hit_term=John+F.+Kennedy&John+F.+Kennedy) for..."]
}
Note that the result includes a combination of the original annotations and search matches. The annotated highlighter doesn’t use <em>...</em> HTML style markup used by other highlighters but reuses the [..](..) Markdown syntax to highlight search hits.
The example application chooses to display annotations with blue text and any search matches (which are prefixed with a “_hit_term=” annotation) are coloured with a yellow background.
Demo application: Finding things near strings
The previous demo example illustrates finding examples of structured entities in the text and showing some of the textual context around where they were mentioned. This context may pique our interest, so we can take examples of the free-text words (“photographs of”) and look for any annotation values that tag politicians near these words. The resulting Wikipedia matches might look like this:
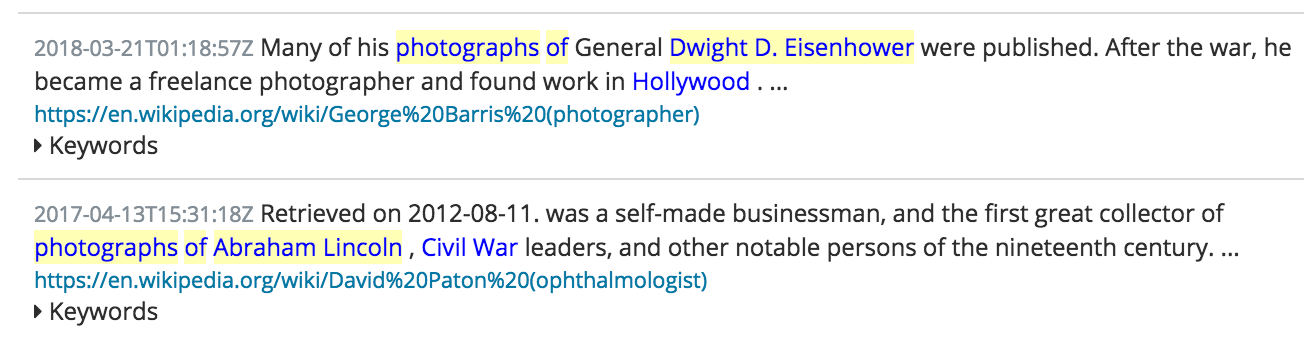
There’s two parts to making this work:
- Fixing the index to tag mentions of politicians
- Writing the query to find mentions of photographs of politicians
Indexing multi-value annotations
Annotations don’t have to be restricted to injecting one value. The annotations in our example text include two pieces of information:
- The specific wikipedia ID of an entity (eg “Abraham Lincoln”)
- The wikipedia’s entity’s more general entity type (“OfficeHolder”) originally obtained from the DBPedia ontology
In my dataset, all elected politicians are tagged with the “OfficeHolder” type from DBPedia so this can be used in queries or highlighting.
Here’s how an entity ID and its DBPedia type are encoded in this index:
{
"text": "..after [JFK](John%20F.%20Kennedy&OfficeHolder)..."
}
Note the use of the “&” character to inject both the “John F. Kennedy” and “OfficeHolder” annotations.
Running the proximity query
You may be familiar with writing “phrase” queries using the Lucene query_string syntax. This is a simple way to ensure matches are on words near each other by enclosing the words in quotes e.g
"John Smith"
Unfortunately we can’t use this query syntax to run our example query because:
- It would try and lower-case the annotation value “OfficeHolder” and
- It won’t let us search for photograph OR photographs
We’ll need to use the more sophisticated “span” query syntax which looks like this:
{
"span_near": {
"slop": 1,
"in_order": true,
"clauses": [
{"span_term": {"text": {"value": "photographs"}}},
{"span_term": {"text": {"value": "of"}},
{"span_term": {"text": {"value": "OfficeHolder"}}}
]
}
}
Great, where can I get hold of annotated data?
Broadly speaking there’s two sources of this type of data:
- Human annotated content e.g. Wikipedia articles
- Machine-annotated content e.g outputs of NER (Named Entity Recognition) software
Working with Wikipedia
The examples used in this blog were based on the human-authored Wikipedia content. The original content is XML format and using a Wikimedia parser it is possible to extract the hyperlink URLs and use them as annotation values around the text they cover. The DBPedia ontology can be used to add further annotations, e.g that the Wikipedia article with the ID “John F. Kennedy” is of the types “OfficeHolder” and “Person”. Each document that includes an annotation link to JFK can therefore have these links enriched with this extra type information. Once you have unique IDs like this it is possible to pull in all sorts of linked information.
Build an editor to assist annotation
Organisations like the ICIJ (the journalists behind Panama Papers) spend long hours manually resolving entities e.g. people or company names found in leaked documents. It’s not hard to imagine building a GUI that supports the following tasks:
- Use the mouse to select what looks like a person name mentioned in plain text (OpenNLP tools could assist by suggesting name candidates)
- Run a free-text search for this string e.g. “John Smith” on your resolved entities store (possibly using a “more like this” style query on some context around the name)
- Review the highlighted entity matches and select the most likely entity id (e.g. entity #5323464) or create a new one if this looks like a new person name.
- Tag the plain text with an annotation of the chosen entity ID and update the document.
Working with Named Entity Recognition tools
Commercial NER tools such as Rosette or open source tools like OpenNLP can identify named entities like people, organisations and places in plain text. With some client-side coding these APIs can be used to create the specific annotated text format used in Elasticsearch.
It’s important to note that some entity extraction tools only spot “entity references” — they can guess that a section of text is referring to a person’s name e.g. “John Smith” but they don’t resolve the entity reference to determine exactly which of many potential real-world John Smiths this might be. Entity linking is the attempt to provide a unique ID for an entity reference, overcoming:
- ambiguity (same name, different people), or
- aliases (same person, different names).
When adding annotations to text it’s important that your annotation values do not clash with regular strings that might exist in the text or your searches will have some irrelevant matches.
If your entities are people names then the fact names contain whitespace to separate first and last names and use uppercase for the first characters means they are unlikely to clash with any text tokens produced by the standard Analyzers. However, if your annotation is a single word lowercased e.g. the company “elastic” then there is a potential for mismatch.
Prefixing the annotation value with a type string and a character that is stripped by the text analysis pipeline is one way to ensure there is no overlap e.g prefer “company: elastic” rather than just “elastic”.
Conclusion
We’re pretty excited to see how this feature will be used, so go try it out. Let us know what cool new user interfaces you build or annotated datasets that work well. We’re keen to get some feedback on the discuss forums.