Save space and money with improved storage efficiency in Elasticsearch 7.10
We're excited to announce that indices created in Elasticsearch 7.10 will be smaller. Bigger isn't always better, and our internal benchmarks reported space reductions up to 10%.
This may not seem like much for small use cases, but it's huge for teams handling (and paying for cloud storage of) petabytes of data. In particular, indices created by our Elastic Observability and Elastic Security solutions are the ones that can stand to see the greatest savings due to the repetitive nature of the data they hold.
Let’s take a look at how this improvement works and explore the Apache Lucene 8.7 update that made this possible.
How stored fields compression works today
Stored fields are the part of the index that stores the _id of the documents as well as their _source. Up until now, stored fields were split into blocks that were compressed independently.
Why are we splitting into blocks? Blocks help keep fast random access to the data. If you want to retrieve a sequence of bytes from stored fields, you only need to decompress blocks that contain one or more bytes of this sequence of bytes. In contrast, if you had compressed all data at once, you would have no choice but to decompress everything at read time, even if you only need a single byte.
Elasticsearch offers two options for compression: index.codec: default instructs Elasticsearch to use blocks of 16kB compressed with LZ4, while index.codec: best_compression instructs Elasticsearch to use blocks of 60kB compressed with DEFLATE.
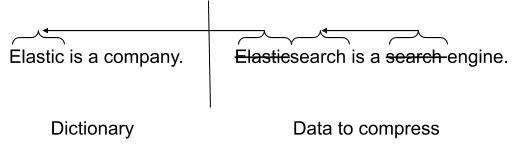
An important component of these two compression algorithms is string deduplication. Whenever finding a string that already occurred earlier in the stream, this string will be replaced with a reference to the previous occurrence of this string. This is actually the only thing that LZ4 does, while DEFLATE combines string deduplication with Huffman coding in order to further compress data.

Upon doing investigations on the space efficiency of indices produced by observability use cases, we noticed that increasing the block size would significantly improve the compression ratio. Unfortunately, bigger block sizes don't come for free as they require decompressing more data at retrieval time, which could slow down the _search experience.
Dictionaries to the rescue
Dictionaries are a way to get the benefits of bigger block sizes without sacrificing retrieval efficiency. The idea is to provide the compression algorithm with a dictionary of data that it can use for string deduplication as well. If there are many duplicate strings between the stream of data you're compressing and the dictionary, you could end up with a much better compression ratio. All you need is to provide the exact same dictionary at decompression time to be able to decompress the data.
As of 7.10, Elasticsearch uses bigger blocks of data, which are themselves split into a dictionary and 10 sub-blocks that are compressed using this dictionary.
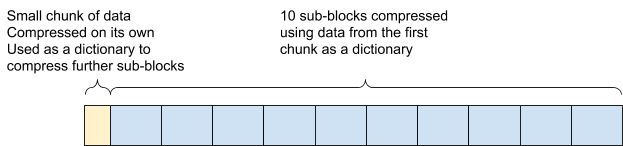
Retrieving a document that is contained in a sub-block requires decompressing the dictionary and the sub-block that contains the document using this dictionary.
index.codec: default now uses dictionaries of 4kB and sub-blocks of 60kB with LZ4 while index.codec: best_compression uses dictionaries of 8kB and sub-blocks of 48kB with DEFLATE. The increase of the block size with the default codec might come as a surprise to you given the above statement that larger block sizes increase retrieval times.
However, our benchmarking suggested that going from 16kB to 60kB significantly improved compression while only slightly impacting retrieval times. Because our tests showed that most users would never notice any sort of slowdown, we made the decision to go with larger blocks.
When is this update most beneficial?
One particularity of observability (data logs, metrics, and traces), and security data (endpoint data, logs) is that the produced documents contain significant metadata about what is being observed, and this metadata tends to vary little across documents. Even if you are monitoring many hosts or endpoints, it's common that many of these systems share common properties such as their operating system. This makes these documents highly compressible, and usage of dictionaries helps remove more duplicate strings as the operating system would no longer be repeated once every 60kB (assuming best_compression), but once every 8+10*48=488kB.
Conclusion
All new indices created in 7.10 will take advantage of this efficiency improvement by default. Any of your existing indices will be automatically updated to use this improvement on their next merge, though this will likely only impact your hot indices.
We encourage you to try it out in your existing deployment, or spin up a free trial of Elasticsearch Service on Elastic Cloud, which always has the latest version of Elasticsearch. We’re looking forward to hearing your feedback, so please let us know what you think on Discuss.