Space Saving Improvements in Elasticsearch 6.0
Elasticsearch 6.0 ships with two great improvements to help minimize index storage size. The best part about the improvements is they will require no special configuration changes or re-architectures, and in most cases will only require a simple upgrade and a newly created index. To illustrate the improvements, we’ll use Metricbeat, a lightweight tool for ingesting metrics into Elasticsearch.
After running Metricbeat for several days on both Elasticsearch 5.6 and Elasticsearch 6.0 (6.0 beta2), index sizes were 41.5% smaller for the Metricbeat workload on Elasticsearch 6.0:
Elasticsearch 5.6
GET _cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open metricbeat-2017.09.16 0b46voluSDmzfwCdYmYvZg 5 1 1694709 0 508.6mb 508.6mb yellow open metricbeat-2017.09.17 UKrTuwevS3urZkjeU8GFhg 5 1 1694385 0 500.7mb 500.7mb yellow open metricbeat-2017.09.18 dxFeMlabR_anYZ_C6BBq4A 5 1 1696223 0 512.7mb 512.7mb
Total storage size over 3 days: 1.522gb
Elasticsearch 6.0
GET _cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open metricbeat-2017.09.16 7IK6c1bfSQCaFAp1i3axUQ 5 1 1696571 0 299.1mb 299.1mb yellow open metricbeat-2017.09.17 CcBCgLdfRESXH0UaGV6YCA 5 1 1695385 0 295.4mb 295.4mb yellow open metricbeat-2017.09.18 sZfCXx8ZReGzLIsjSFO4hA 5 1 1697063 0 296.1mb 296.1mb
Total storage size over 3 days: 890.6mb (41.5% improvement in storage space from Elasticsearch 5.6)
The test above used Metricbeat with the System module.
Deprecated _all field
The “_all” field was deprecated in Elasticsearch 6.0, this is the first part in the explanation for the storage space savings we’re seeing. If you’re unfamiliar with the “_all” field, it’s a special field used to concatenate all values together, making it easy to search everything. The “_all” field made it easy to get started with Elasticsearch, however, the “_all” field uses a lot of additional storage space (especially as values are duplicated).
PUT /user_profiles/profile/1
{
"userid" : "john123",
"first": "John",
"middle": "James",
"last": "Smith",
"city": "Alamo",
"state": "California"
}
The “_all” field for the document above now contains the terms [ “john123”, “john”, “james”, “smith”, “alamo”, “california” ].
Using the “_all” field, it was easy to search across all fields, however, we’re now duplicating a lot of values, and using more storage space:
GET /user_profiles/_search
{
"query": {
"match": {
"_all": "john123 john james smith alamo california"
}
}
}
With the deprecation of the “_all” field in Elasticsearch 6.0, we save space on indexing duplicate data. And if “_all” field functionality is still needed, the copy_to parameter should still be used in the index mapping.
We ran a follow-up test to look at the effects of disabling “_all” in relational to the storage improvements we saw. When isolated, the deprecation of “_all” accounted for almost 40% of our index saving improvements (the other 60% was due to the sparse field improvements we’ll visit next).
Sparse Field Improvements
Elasticsearch 6.0 includes Lucene 7.0, which has a major storage benefit in how sparsely populated fields are stored (LUCENE-7407). Metricbeat, used in our test above, happens to use a lot of sparsely populated fields.
If you recall, doc values (the columnar data store in Elasticsearch) have allowed us to escape the limitations of JVM heap size to support scalable analytics on larger amounts of data. Doc values are a very good fit for dense values, where every document has a value for every field. But they have been a poor fit for sparse values (many fields, with few documents having a value for each field), where the matrix structure ends up wasting a lot of space.
If you’re unsure of what a sparsely populate field is, it’s a field that contains a value for a small percentage of documents. For instance, if we go back to our user profile example, the “middle”, “city”, and “state” fields may only be present in a few of the documents:
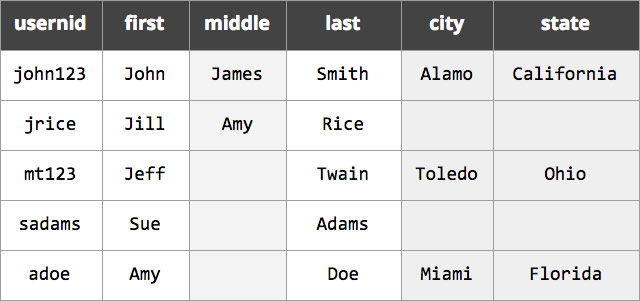
Internally, Lucene 7.0 (which ships with Elasticsearch 6.0) retrieves data within doc values as an iterator, which allows for more efficient data storage behind the scenes (especially for sparsely populated values):
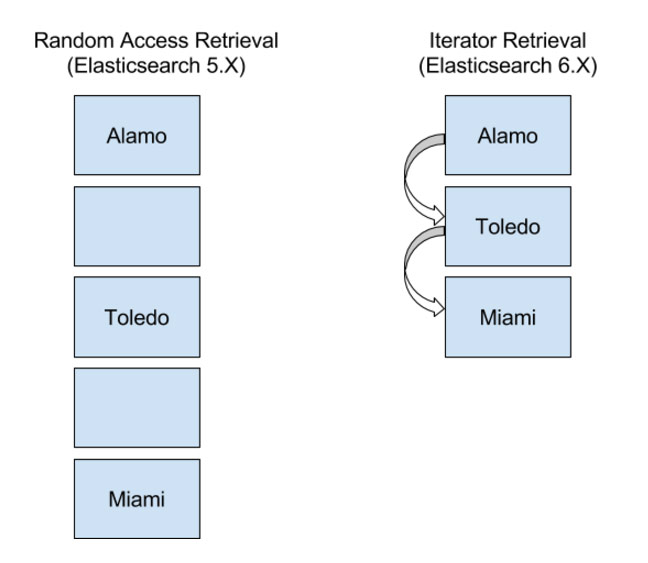
As you can see from the diagram above, with random access retrieval for doc values (present in Elasticsearch versions prior to 6.0), blank/empty values must be maintained (and extra storage space used). The iterator based approach does not need to store the empty/blank values, and the extra storage space used by the random access method can be reclaimed.
In addition to storage improvements, the iterator-based retrieval method for sparsely populated fields has a number of performance improvements, including indexing speed. Sparse fields should still be avoided when they can be, as dense fields are the most efficient. More details can be found in LUCENE-7253.
Both of these space saving improvements are present in Elasticsearch 6.0. We hope you’ll be happy with the new improvements, and look forward to hearing your feedback! If you want to try out Elasticsearch 6.0 for yourself, to determine any index storage size improvements, download 6.0.0-beta2 and become a pioneer!