Looking at Content Recommendation Through a Search Lens
Outbrain is the world's leading content discovery platform, bringing personalized, relevant online, mobile and video content to audiences. Outbrain helps publishers engage, monetize and understand their audiences through data, and helps marketers to reach their most relevant audiences.
Outbrain serves over 200 billion personalized content recommendations every month and reaches over 500 million unique monthly visitors from across the globe.
In this article we would like to share how we reduced the problem of recommending content to a user, to a search problem for users' implied interests, and how this enabled us to solve some of our major scale bottlenecks, and to increase the complexity of our online prediction models.
Jungle of Market Rules, Personalization, and Scale
Our content discovery engine finds content that is most likely to be relevant to each user's interests, as manifested in their browsing patterns. In addition to being personalized, Outbrain's recommendations must comply with a long list of market rules and restrictions. For articles that pass all market rules, a ranking function is applied to select the most relevant content for a given user.
One simple example of a market rule is geographic targeting. This rule enables a marketer to target an audience from a specific location, namely to ensure its content is recommended to users from that location only.
Outbrain publishers and marketers have hundreds of possible market rule configurations, and these must be enforced in real time at a 35K/sec throughput of requests on millions of potential content recommendations and at a latency of under 100 milliseconds per request.
While increasing throughput is horizontally scalable and can be achieved by adding more serving machines, inventory size is much more difficult to scale, especially with a growing set of market rules. After several architecture design attempts, we realized that Elasticsearch, being a distributed scalable search platform, can provide us with the solution.
Elasticsearch has three key properties for our serving-stack needs. First, it is able to score documents by their relevance to a query. Second, it is able to filter documents by certain attributes. Finally, it does this efficiently and at scale both in terms of throughput and inventory size.
Therefore, by translating the problem of recommending content to a user into a search problem for users' implied interests, we can base our recommender system on Elasticsearch and handle the aforementioned scale challenges.
Let's now describe how this translation is being done.
Every Potential Recommendation is an Elasticsearch Document
Every article in the inventory of our potential content recommendations is indexed as a separate Elasticsearch document. We index its title, other meta-data, and most importantly, a set of semantic features that will be used to determine its relevance to each potential user.
Those features are generated offline using an NLP-based semantic engine, and include high-level categories, more specific topics, explicit entities appearing in the article, and so forth.


Recommendations and Search: Your user IS the query
The next step after indexing our inventory of potential content recommendations, was to translate users' implied interests to an Elasticsearch query.
Users at Outbrain have 'profiles' that represent their interests. These are generated based on the semantics of the content each user reads.
We can then incorporate user interests into the Elasticsearch query such that all relevant content recommendations are retrieved. Specifically, we generated a 'should' query, so that any document matching at least one clause of the query is eligible to be returned to the user. Documents with more than one match will be scored higher. The 'boost' parameter can be used to specify that not all matches contribute equally to the final score.

Translating Market Rules to Elasticsearch Filters
Translating market rules to Elasticsearch filters seems rather natural, and it is. Every rule needs to be represented both on the document side and the query side.
One simple example is geographic targeting of users. Imagine a New York music scene site that wishes to increase its traffic and opens an Outbrain campaign. On the business side, as it sells tickets to New York shows only, it is not interested in receiving traffic from users outside the US. Implementing this market rule has two main stages. First, a new 'geo' field is indexed for the relevant Elasticsearch documents. Secondly, a new 'terms' filter is added to the user query. This filter is defined on the 'geo' field and its value depends on the origin country of the user.


Interestingly, even this rather simple market rule has a twist. What happens if a marketer is indifferent to user geographic location? In the naive approach, all the articles (Elasticsearch documents) of this marketer would have had an empty value in their 'geo' field. However, in that setting, this document will actually be filtered out as there will be no match between the query (user) 'geo' term filter and the values of the 'geo' field in the document. As a result, this marketer will essentially reach no users at all.
To solve this, we added a wildcard term 'all' both to the index and to the query. This way, a user will receive content recommendations from campaigns that explicitly target the user's location, as well as content that has no geographic targeting specifications.

Incorporating Machine Learned Models
To incorporate more complicated machine learned prediction models into our recommender system, Elasticsearch provides us with its flexible plugin capabilities. To efficiently implement a custom scoring function on our index, we wrap native Java code into a stand-alone jar and deploy it on our Elasticsearch cluster as a registered plugin.
The script_score query clause instructs Elasticsearch to use the custom plugin for scoring potential content recommendations.
We therefore gain high flexibility in terms of our scoring mechanism, while not compromising on efficiency and scalability.
Optimizing the Elasticsearch System for Throughput and Latency
To enable Outbrain's recommendation system to serve millions of requests per minute at under 100 millisecond latency and reasonable HW cost required substantial work. This section shares the more interesting parts of our optimization effort.
System Overview
The recommendation system is made up of two independent services which interact with the Elasticsearch backend. An Indexing Service (writing the inventory) and a Recommendations Service (querying for the best candidates)

Hardware and Size
The machines allocated as data nodes are as follows:
- 2 x Processors of 12 hyperthreaded cores(Intel E5-2630 v2)
- 128 GB RAM.
- 2 x 500G SATA drives for OS(mdadm raid1)
- 2 x 1Gbe NIC in bond
The Elasticsearch system was given 26 physical servers for data nodes and 6 servers for master nodes to be divided into two clusters (indexing/searching).
Our Custom Elasticsearch Plugin
Along with the indexed document data (which is updated every half-hour), our system requires additional, frequently updated (every 2 minutes) document-related data which is used for the purpose of scoring the candidates for recommendation.
In order to keep our read-only index unaffected during the search phase, we implemented an Elasticsearch plugin which supports updates of additional document-related data. Keeping in mind our latency/throughput goal, we chose the off-heap Chronicle Map technology as the backing storage in order to avoid possible GC costs.
Our scoring script uses that off-heap data when evaluating the rank of queried documents.
Optimizing Our System
Our optimization work can be divided into two main effort areas: (1) application level effort, optimizing our index and queries; and (2) system level effort, optimizing the Elasticsearch setup and structure.
Optimizing Index and Queries
Taking advantage of the fact that our index is read-only at search phase, all queries are made to use cachable filters only. This approach proved to be very effective in achieving improved latency.
Working with slow-log queries, we identified the most time consuming query filters and moved all possible filter term parameters to be calculated at indexing time, making them part of our document fields.
To make the index as small as possible, we optimized our field definitions using an elaborate field mappings template (link) allowing for stored-only/indexed-only fields, disabling norms (we do our own scoring) etc.
To gain latency and throughput by having our search requests run on a single segment, we perform a force merge operation before making the index searchable. Note that merging an index into a single segment has to be specified explicitly (we advise to read the documentation here).
Working with a single shard replicated across all nodes (having all our data on every node of the cluster) enabled our queries to run with the "_local" query preference. In this way, the search operation can be completed locally, saving the possible extra network hops to neighboring nodes to complete the search request.
Optimising Elasticsearch Nodes and Clusters
Having a small index (~2GB) made it possible for us to define the data storage on tmpfs, gaining all the advantages of RAM vs. Disk.
Our initial system design was a two-cluster Hot-Cold setup. Indexing all nodes in cluster A while searching on cluster B and flipping once indexing is done.
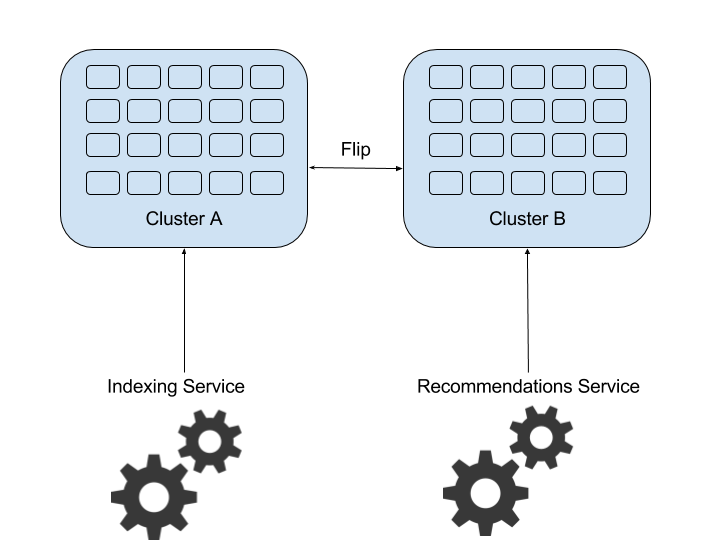
With increased traffic to the recommendation system, we found this approach to be wasteful, since actually only half of the HW capacity was utilized at any given time. We then switched to a different cluster setup with small indexing and large searching clusters.
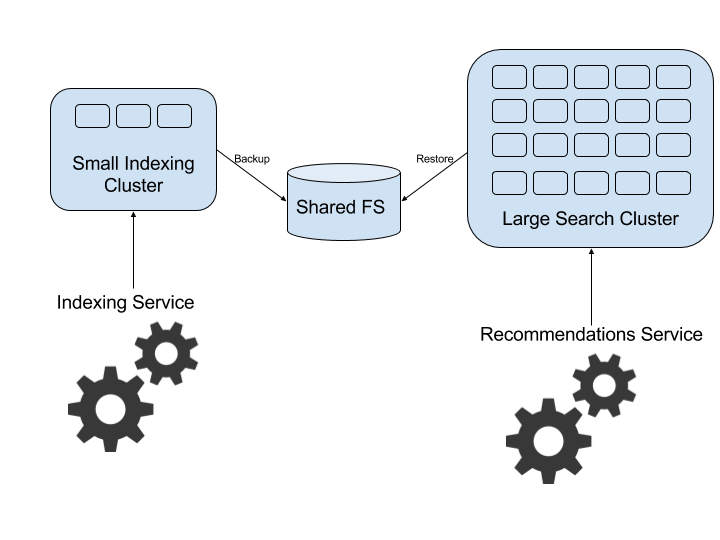
For speed, the indexing is performed on a single, non-replicated shard. When indexing is finished a forceMerge operation is invoked merging all segments into a single one and the newly created index is backed-up to a shared network drive. The backed-up index is then restored on the search cluster and is replicated to all its data nodes and is made searchable.
This design proved to be very effective and practically doubled our system's capacity. Our concern that the restoring process will interfere with the ongoing search proved to be unjustified.
Search Threads and Queue
Starting with the default number of search threads and queue size proved right away inappropriate for our needs and had to be adjusted. Very quickly we experienced a cluster with saturated queues, terrible latency, and total breakdown. Thread limits and queue size dynamic configuration proved to be very useful while looking for the best numbers to fit our needs. From our tests and for our needs (with a search-only cluster and no indexing) we found that the number of search threads is close to the number of available virtual cores on the data nodes.
Two Data Node Instances per Single Physical Server
Following a few optimization phases, we were ready to stress-load our system with traffic to test its throughput limits. To our surprise and puzzlement, no matter how much traffic we loaded, the data nodes did not go much beyond 50% CPU utilization, although the number of search threads was defined as the number of virtual cores (24). Searching for clues, we disabled one of the CPU sockets. As we anticipated, the throughput remained pretty much the same.
Assuming that a single Elasticsearch instance could not gain the full capacity of a two socket processor setup, we decided to install a second Elasticsearch instance on each physical machine. Each node instance limited to its own cpu socket and memory, which was achieved by cpuset(cgroups) command, and by the tmpfs mount option(mpol=local). This change in effect doubled our throughput and made it possible to utilize 80-90% of the servers' processing power.
Summary
Starting with the approach that things would work for us out-of-the-box, we very quickly realized that customization is required to adjust the Elasticsearch system to fit our specific recommendation serving use-case. Following trial and error, we are now able to serve 800,000 req/min at under 100MS on a cluster of 48 data nodes.
This capacity to quickly validate business rules and subsequently match user interests to available content enables us to utilize more complex personalization models, improving the quality and relevance of Outbrain's recommendations. This improves the very core of our business.
We truly hope that this report and the details above will prove to be interesting and useful.
We would also like to thank Andrei Stefan and Honza Kral from Elastic for their help in building our system.
Sonya Liberman - Personalisation Team Lead (Recommendation Group Outbrain)
Baruch Brutman - Infra Team Lead (Recommendation Group Outbrain)
Shahar Fleischman - Production Engineer (Recommendation Group Outbrain)