Leveraging Elasticsearch for a 1,000% performance boost
Voxpopme is one of the world’s leading video insight platforms. Born in 2013, the company was founded on the simple premise that video is the most powerful way to give hundreds and thousands of people a voice simultaneously. Our unique software ingests consumer-recorded video and long-format content (e.g focus groups) from a variety of survey partners and provides valuable marketing data in the form of graphs, browsable themes and customisable showreels.
Since our launch, we’ve spent four years optimising and automating the insight that can be gained through video to remove the barriers blocking real connections between brands and customers. To enhance client experience, we use the latest NLP tools from IBM Watson to identify and aggregate the sentiment of survey respondents and have an exclusive partnership with Affectiva to analyse facial emotions. In 2017, we included Elasticsearch in our arsenal of tools to deliver the best possible experience to our clients.
Outgrowing our legacy infrastructure
At Voxpopme our technology stack has undergone a significant change over the last twelve months. In 2017, our platform processed half a million video surveys — as many as the previous four years combined — with that figure set to double in 2018. We ran into scaling issues, which was a nice problem to have, but a problem all the same.
The issues arose from our legacy system, which was comprised of a monolithic PHP application that interacted with a number of different databases for core functionality. The logic behind this original separation of data was initially sound:
- The majority of our data was stored in a MySQL database. This covered users, individual video responses and the like — structured relational data that linked together with foreign keys and would be created, read, updated and deleted with a RESTful API;
- Client data was stored in a MongoDB cluster, which we accepted in whatever form it was provided to us. This allowed users to tag, annotate, and filter their videos using their own terminology;
- We stored the transcripts of our respondents’ videos in a small Elasticsearch cluster, which we used for full-text lookups.
For a long time, this approach worked very well, but there was one obvious problem.
Computational power is neither free nor infinite
A search on our platform can be incredibly simple or very complex. In the simpler instances we allow users to search by the primary key of a video response — this is easy and involves only a simple query to the indexed MySQL database.
But what about queries where a user may want to filter by an indexed integer, some of their own free-form data and also to narrow the results to all respondents who mention a particular topic? For instance:
Find all records where the response date is between the first and last day of June, where the respondent’s household income is within the $100-125k bracket and they have mentioned the phrase ‘too expensive’.
This was our approach:
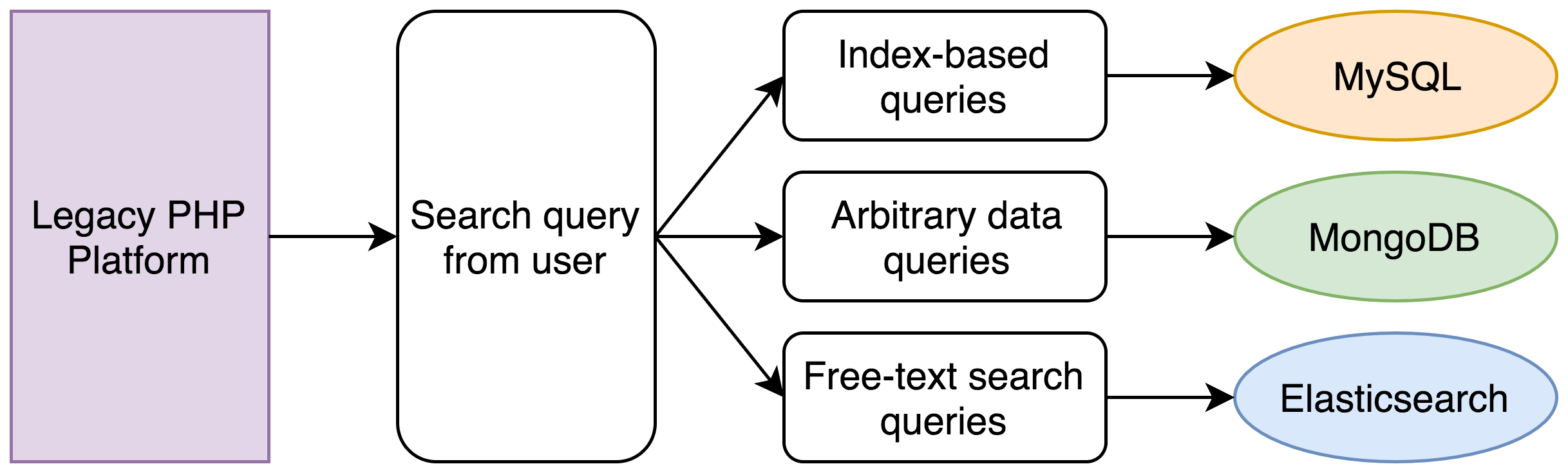
Under our legacy system the following things would have to occur:
- A MySQL query would find all records within the date range;
- A MongoDB query would find all records within the income range (income is just an example; clients often store completely arbitrary information with us);
- An Elasticsearch query would find all records with a matching phrase in the transcript;
- An intersection of the IDs from the three sets of records would be calculated;
- A new set of MySQL and MongoDB queries would be run to get the full dataset for each record;
- The records would be sorted and paginated.
A simple set of search criteria could easily involve five separate database queries. Originally this would have been a sub-second operation, but five years worth of data and the fact that PHP is single-threaded meant that the database queries would have to be carried out one after another and could easily take up to 30 seconds.
It was a model that got us to market quickly and served us well for a number of years, but not one that scaled gracefully. When we noticed the experience of our users begin to decline, we decided that it was time to rewrite the search mechanism.
We already had some experience with Elasticsearch from our existing stack, so engaged in talks with an Elastic sales manager to discuss the problems we faced while carrying out complex searches across a range of data that resides in multiple locations. Finding the right solution was critical — our product centres around quickly and efficiently displaying and performing calculations on our data; to have bottlenecks in retrieving the data would be unacceptable.
We also considered extending our existing MongoDB cluster, but after a brief telephone consultation with Elastic, the development team decided that the only solution that allowed us to easily store, search and manipulate data (i.e. aggregations) was Elasticsearch.
Our first impressions
The Elasticsearch cluster we had been using for text search was a version 1.5 cluster from Compose.io. As we have invested heavily in AWS for the rest of our infrastructure, we initially opted for Amazon Elasticsearch Service running a version 5.x cluster.
Our new model involved holding all of a record’s disparate data within a single Elasticsearch document, using nested values with known keys for our clients’ trickier free-form data. Any user search could then be handled by a single Elasticsearch query.
Within a week we had a basic proof of concept loaded with a few thousand documents, and our first impressions of running queries in Kibana were good enough that we were happy to press ahead with a full rewrite of our back-end search mechanism.
This was our new approach:
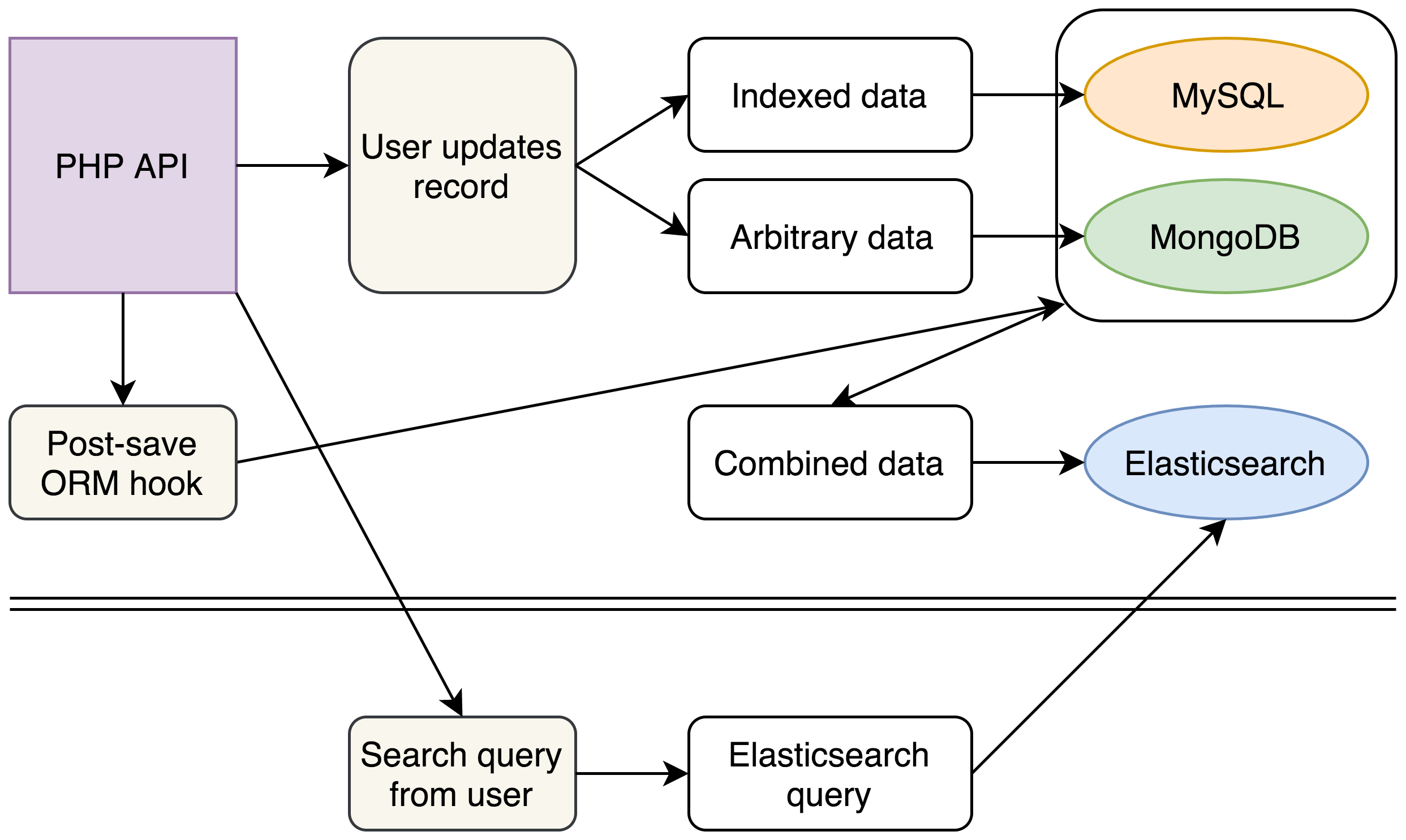
(For now our legacy databases remain unchanged, but with the introduction of our new Elasticsearch cluster for complex searching we are able to make plans to completely remove MongoDB from our stack)
With our new stack we continued to write to MySQL and MongoDB as before. However, each write would also trigger an event that gathered and flattened all of our data from its various sources into a single JSON document that was inserted into Elasticsearch.
On the back end we wrote a new search mechanism that constructed complex Elasticsearch queries from our users’ existing search requests and entirely removed the legacy code that queried MySQL and MongoDB. Querying a single Elasticsearch cluster allowed us to obtain the same data in a fraction of the time.
Additional gains came from the structure of our Elasticsearch documents. Our API returns JSON documents, so we were able to structure our Elasticsearch documents to exactly match our existing API output, saving further seconds that had previously been spent combining and restructuring the data that came out of MySQL and MongoDB.
To the various stakeholders within the business, we were able to report a preliminary performance increase of 1,000% for key parts of our platform.
This isn’t the provider you’re looking for
After promising everyone a 1,000% performance boost, the next step was to index all of our data and hope that the numbers held up under pressure.
With all of our data indexed the AWS cluster, unfortunately, did not cope well.
If we were simply indexing the data once and then querying it many times, there might not have been any issues. But our model hinged on combining and reindexing the data whenever it was updated in MySQL or MongoDB. This could be thousands of times during the period when it was most likely to be searched.
We found that performance took a hit and query times sometimes fell to seconds. This had the adverse effect of potentially locking up our PHP application, which in turn could keep MySQL connections open, and in a terrible domino effect our entire stack could become unresponsive.
We were experiencing these issues around the time Elastic{ON} came to London, so took the opportunity to speak with an Elastic representative at the AMA booth about cluster sizes and the issues we were experiencing. We mentioned that our best-case query times were around 40ms and were advised that using Elastic’s own Elastic Cloud service instead of AWS could yield response times closer to 1ms with the default settings.
The availability of X-Pack on Elastic Cloud was a huge benefit for us as we only had limited logging and graphing systems in place at the time. As X-Pack is missing in AWS’s Elasticsearch offering, we decided to spin up an Elastic Cloud cluster for some side-by-side tests — if it performed at least as well as the AWS cluster we knew we would switch for the other benefits alone.
The Elastic Cloud UI was very clean and easy to use. During indexing we needed to scale up as we added more workers to process the data and were impressed with how easy it was to manage the cluster: just move a slider left or right and click ‘Update’.
Once our data was successfully indexed in the new cluster, we were able to execute complex queries as quickly as 2ms with little-to-no locking up (we have since optimised things even further to eliminate locking altogether). While a few milliseconds here and there aren’t usually perceptible to the end user, for the techies amongst us it was pleasing to see that latency slashed to 5% of its previous level.
Getting the most from our data
But we didn’t want to be old school and just use Elasticsearch as a user-facing search engine. Many success story we have heard about the technology seems to be focused on logging, and we quickly found that we were no exception.
We set up a separate logging cluster to ingest the logs from our Kubernetes pods and now enjoy clearer visibility of our servers’ health that simply wasn’t available to us before, and can react to issues far quicker.
We have also been able to offer something similar to users of our platform. Using aggregations we have been able to provide our users with a graphical way of visualising their data. This in itself was a great addition to our platform and came about purely as a side-effect of having our data in Elasticsearch.
Over the last few months, we have tweaked and refined our processes, and are seeing a greater performance from our Elasticsearch clusters every week. These increases in performance have included large memory gains by moving fields that require fielddata out of our primary cluster and into a smaller cluster that is accessed less frequently (our baseline memory pressure is now 25%, down from 75%). We have also optimised our code to write new data in bulk, rather than on-demand, which has made the cluster far more responsive during peak times.
Looking to the future, we have plans to utilise Elasticsearch heavily for analysing the internal data that we hold as a company. Having proved itself as a core part of our client-facing product, we have already begun to experiment with storing our own data in Elasticsearch indices and intend to use the Elastic Stack to gain insights into our operational efficiencies as a company.
 David Maidment is a Senior Software Engineer at Voxpopme, specialising in future-proofing the platform's codebase as the company undergoes exponential growth.
David Maidment is a Senior Software Engineer at Voxpopme, specialising in future-proofing the platform's codebase as the company undergoes exponential growth.
 Andy Barraclough is a co-founder and the CTO of Voxpopme, focusing on managing the technical team and coordinating the long-term vision of the company.
Andy Barraclough is a co-founder and the CTO of Voxpopme, focusing on managing the technical team and coordinating the long-term vision of the company.