Improving Response Latency in Elasticsearch with Adaptive Replica Selection
Introduction
In this blog post, I am going to describe a new feature of Elasticsearch called Adaptive Replica Selection (ARS). Before describing what ARS does, I’ll first describe the problem that it tries to solve. Imagine that you have a cluster with three nodes. And across those three nodes, you have a shard and its replicas.
Then imagine that one node starts to experience distress.
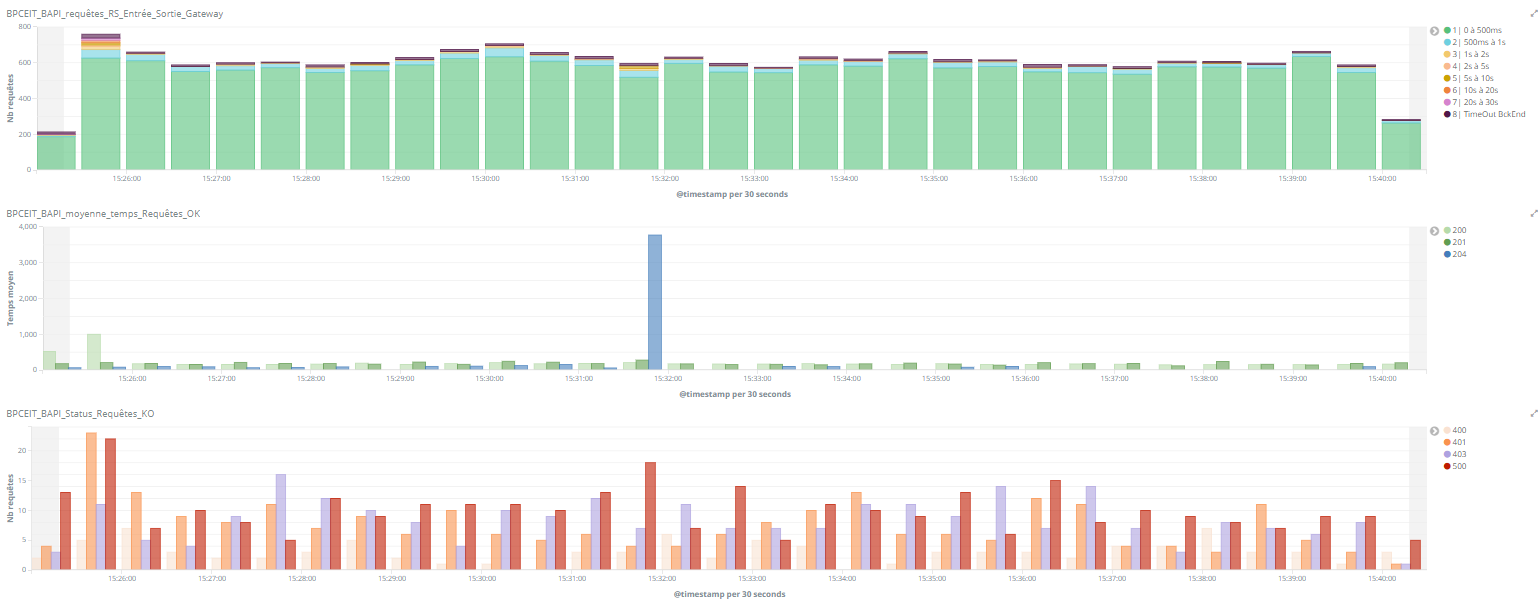
When a search request is received, Elasticsearch first determines which shards need to be queried, and then determines which nodes contain copies of that shard. Once it’s done that, it then sends the request to a single copy of the shard via round-robin selection. So if Elasticsearch sends the request to shard copy 2, we will see degraded performance compared to requests to the other copies:
- shard copy 1: 100ms
- shard copy 2 (degraded): 1350ms
- shard copy 3: 150ms
The degradation of the node with the second copy of the data can be caused by any number of things, like long garbage collection cycles, high disk IO, network saturation, or heterogeneous node types. This causes tail latency of requests to rise, not to mention it frustrates whoever is unlucky enough to be waiting for the query when it’s run against shard copy 2.
So what can be done? We would like Elasticsearch to be smart enough to route requests to the other copies of data until this node has recovered enough to handle more search requests. In Elasticsearch, we call this process of selecting the best available copy of the shard Adaptive Replica Selection.
Adaptive Replica Selection
ARS is an implementation of an academic paper called C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection. Originally, the paper was written for Cassandra, which means we had to adapt some things to fit Elasticsearch due to the differences in behavior between the two.
Our ARS implementation is based on a formula where, for each search request, Elasticsearch ranks each copy of the shard to determine which is likeliest to be the "best" copy to send the request to. Instead of sending requests in a round-robin fashion to each copy of the shard, Elasticsearch selects the "best" copy and routes the request there.
The ARS formula initially seems complex, but let's break it down:
Ψ(s) = R(s) - 1/µ̄(s) + (q̂(s))^3 / µ̄(s)
Where q̂(s) is:
q̂(s) = 1 + (os(s) * n) + q(s)
And looking at the individual pieces:
- os(s) is the number of outstanding search requests to a node
- n is the number of data nodes in the system
- R(s) is the EWMA of the response time (as seen from the node coordinating the search) in milliseconds
- q(s) is the EWMA of the number of events in the search thread pool queue
- µ̄(s) is the EWMA of service time of search events on the data node in milliseconds
Response time is the time measured for a request from the coordinating node, whereas service time is the time measured on the node executing the request (not including any time the request may have spent in the queue). Roughly speaking, this means that as the difference between the response time and service time grows — as well as the number of searches in the queue and the outstanding requests for a node — the higher a score the node will receive (lower scored nodes are considered the “best” ranked). For example, the (q̂(s))^3 part of the formula means that as the number of connections to a data node, and the number of searches in the node’s queue increases, the score will go up in a cubic exponential manner. By factoring in the number of outstanding search requests in the formula, we also make sure that nodes with identical load and response times still distribute requests among shard copies.
Elasticsearch gathers most of these values using a specialized thread pool for search actions on each of the nodes. For each search response, these values are piggybacked on the results back to the coordinating node, which stores them so the node can be ranked for subsequent requests. When the next search request comes in, the node with the lowest score will serve the request. If the node encounters an exception, the node with the next best score serves the search request. Since we don't want loaded nodes to have searches routed away forever, every time a node is not the best ranked node, we slightly adjust the score to make it a better candidate for handling future requests.
Going back to our original example, the selected node for the request would be either shard copy 1 or 3, avoiding the overloaded shard copy 2.
ARS is available in Elasticsearch 6.1 and later, but is turned off by default in all 6.x releases. It can be turned on dynamically by changing the cluster.routing.use_adaptive_replica_selection setting:
PUT /_cluster/settings
{
"transient": {
"cluster.routing.use_adaptive_replica_selection": true
}
}
In Elasticsearch 7.0 and later, ARS will be turned on by default.
Improvements with ARS
How much do we expect this to help? We ran benchmarks with Rally for many scenarios, both with and without simulating load on one of the nodes containing a copy of the data. In our case, we used a single coordinating node connected to a cluster of five nodes, searching an index with five primary shards each with a single replica. In each benchmark, the search requests were sent as quickly as possible from 100 Rally connections.
Non-loaded case:
| Metric | No ARS | ARS | Change % |
| Median Throughput (queries/s) | 95.7866 | 98.537 | 2.8 |
| Median latency (ms) | 1003.29 | 970.15 | -3.3 |
| 90th percentile latency (ms) | 1339.69 | 1326.79 | -0.9 |
| 99th percentile latency (ms) | 1648.34 | 1648.8 | 0.027 |
The non-loaded case makes sense in a system where none of the nodes are under undue stress (high GCs, disk issues, etc). We expected throughput and latency to remain largely the same, which it did. Since a coordinating node is being used for queries, we avoided hotspots from a node having to coordinate any of the search responses.
Single node under load:
| Metric | No ARS | ARS | Change % |
| Median Throughput (queries/s) | 41.1558 | 87.8231 | 113.4 |
| Median latency (ms) | 411.721 | 1007.22 | 144.6 |
| 90th percentile latency (ms) | 5215.34 | 1839.46 | -64.7 |
| 99th percentile latency (ms) | 6181.48 | 2433.55 | -60.6 |
In this scenario we simulated load on a node by using the stress command with the parameters stress -i 8 -c 8 -m 8 -d 8 (which runs stress with 8 CPU workers, 8 IO workers, 8 memory workers, and 8 hard drive workers). With ARS there is a large improvement in throughput for the loaded case, as well as a trade-off of 50th percentile latency for a large improvement in 90th and 99th percentile latency. So we were able to route around the degraded node quite well. The 50th percentile latency increase is expected since instead of requests having a "luck-of-the-draw" for whether they go to an unstressed or stressed node, they now avoid the stressed node, slightly increasing load for the unstressed nodes (and thus latency).
Single replica, round-robin requests:
| Metric | No ARS | ARS | Change % |
| Median Throughput (queries/s) | 89.6289 | 95.9452 | 7.0 |
| 50th percentile latency (ms) | 1088.81 | 1013.61 | -6.9 |
| 90th percentile latency (ms) | 1706.07 | 1423.83 | -16.5 |
| 99th percentile latency (ms) | 2481.1 | 1783.73 | -28.1 |
Finally we tested without a coordinating node, sending the requests in a round-robin manner to each node in the cluster without any stress induced. An improvement can be seen in both throughput and latency. So even if the cluster is experiencing even load, ARS can still improve throughput and latency.
Conclusion
As you can see, we expect Adaptive Replica Selection to help in many situations. ARS allows the coordinating node to be aware of the load on the data nodes and allows it to choose the best shard copies for executing a search, improving search throughput as well as latency. If you are using Elasticsearch 6.1 or later, please try it out and let us know any feedback you have!