Beware Steep Decline: Understanding Model Degradation In Machine Learning Models
Editor’s Note: Elastic joined forces with Endgame in October 2019, and has migrated some of the Endgame blog content to elastic.co. See Elastic Security to learn more about our integrated security solutions.
Machine learning (ML) models are often designed to make predictions about future data. However, over time many models’ predictive performance decreases as a given model is tested on new datasets within rapidly evolving environments. This is known as model degradation. Model degradation is especially an issue in information security because malware is always changing and new malware is constantly emerging. By understanding model degradation, we can determine how to optimize a model’s predictive performance.
We explored the effects of model degradation on the Ember (Endgame Malware BEnchmark for Research) benchmark model. The ember dataset was initially created as an open source benchmark dataset for testing the efficacy of different machine learning methods, and consists of over 1.1 million executable files/samples, all of which can also be obtained from VirusTotal. Ember also includes a model trained on that data.
While the ember benchmark model classified files as benign or malicious in the original test set with a greater than 99.91% accuracy, we don’t know how the model’s performance will degrade over time as new files (benign and malicious) are classified against an older model. To address this issue, we trained the model with multiple time bounded training and test sets to determine exactly how the benchmark model degrades over time.
After conducting multiple analyses, we determined that the ember model’s predictive performance degrades over time. This helps us make more informed decisions about when to retrain ember and similar models. It will also inform other researchers working with ML models of the importance of model degradation.
Determining Ember Model Degradation
We trained nine versions of the model with different training sets, one for each month from March - November 2017, using all the files seen before and through that month as our training set. For each of these models, we defined multiple testing sets – each test set consisted of all the files from a given month after the training set. We then evaluated each model’s predictive performance on each of the corresponding testing sets based on its area under the ROC curve (AUC) score (a ratio of the model’s false positive rate to its true positive rate).
We did this twice – once with only files first seen in 2017, and once with all files seen starting from 2006. The overall trends in model performance can be seen below.
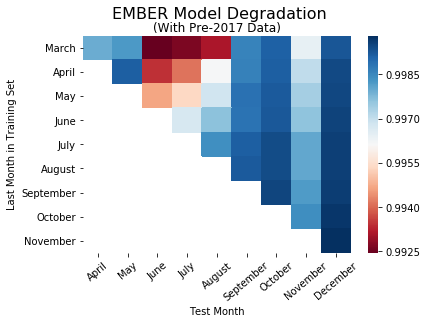
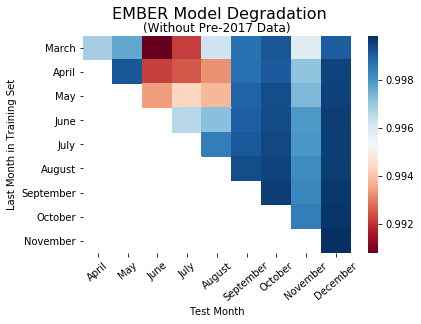
The heatmaps above are colored by AUC, with red indicating low model performance and blue indicating high model performance. The rows in the heat maps show how a given model performs over time; the columns represent how well multiple training models perform on data from a given month.
Our initial plan was to measure the performance of each model in the months following its latest training data (rows). However, for the model trained on files seen through March (first row), there is no continuous pattern of model degradation. The same lack of a trend applies for the models trained on data through the rest of the nine months. Instead, we switched to a different analysis for evaluating performance degradation, holding the test month constant and comparing time gaps to those test months (columns). Looking at the models tested on data from December (last column), model performance decreases as the latest training data in a given model becomes further away from December. This same general trend can be seen for the rest of the test months.
We believed this difference in model performance could result from later models with larger training sets, which makes them more generalizable and leads to more accurate classifications on the testing sets.
Testing with Normalized Training Data
In order to test the hypothesis that larger datasets over time are driving our findings, we decided to observe how the models perform when the training sets for all the models are the same size. To normalize the training sets for each model, we first determined the number of files in the small training set. Then we selected many randomly sampled files from the rest of the training sets. After retraining/retesting all the models on the new training and test, we observed the following trends in model performance:
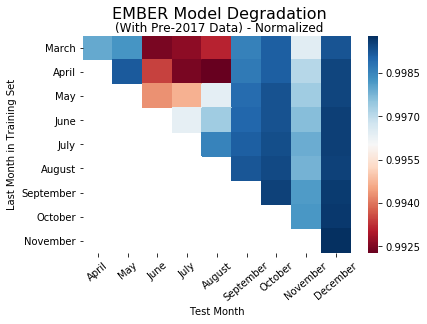
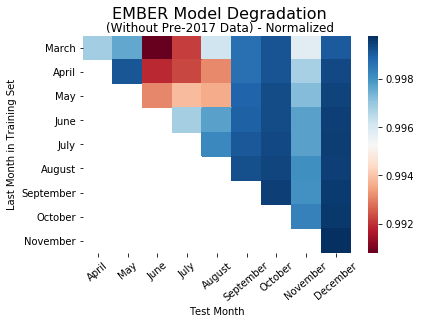
While there are few variations, the heatmaps here are essentially the same as the performance heatmaps without the normalized training sets. This indicates that the size of the training set doesn’t contribute to the difference in model performance between each of the nine models.
Considerations and Possible Improvements
While we were able to determine the model’s performance over time, there are other variables that we need to consider. There is a risk that after retraining the model, the model potentially could classify a file differently than it did before retraining. These factors could decrease the consistency of the model and possibly be a concern for people using ember.
Conclusion
Understanding model degradation is important as it allows us to determine when to retrain a model to maintain model performance. We now better understand the rate of model degradation within the ember benchmark model and we can use this knowledge when making decisions about how often to retrain production MalwareScore TM models.
Beyond malware classification, many ML models are susceptible to model degradation. Thus, any researchers or evaluators in information security using ML models should be aware of the rate of model degradation to continue to optimize model performance.