O que é RAG (geração aumentada de recuperação)?
Definição de geração aumentada de recuperação (RAG)
A geração aumentada de recuperação (RAG) é uma técnica que complementa a geração de texto com informações de fontes de dados privadas ou proprietárias. Ela combina um modelo de recuperação, que foi projetado para pesquisar grandes conjuntos de dados ou bases de conhecimento, com um modelo de geração, como um grande modelo de linguagem (LLM), que recebe essas informações e gera uma resposta de texto legível.
A geração aumentada de recuperação pode melhorar a relevância de uma experiência de busca, acrescentando contexto por meio de fontes de dados adicionais e complementando a base de conhecimento original de um LLM com base no treinamento. Com isso, o resultado do grande modelo de linguagem é aprimorado, sem que seja necessário treinar novamente o modelo. As fontes de informações adicionais podem variar de novas informações na internet, sobre as quais o LLM não foi treinado, a contextos comerciais proprietários ou documentos internos confidenciais pertencentes a empresas.
A RAG é valiosa para tarefas como resposta a perguntas e geração de conteúdo, pois permite que os sistemas de IA generativa usem fontes de informações externas para produzir respostas mais precisas e conscientes quanto ao contexto. Ela implementa métodos de recuperação de busca (geralmente busca semântica ou busca híbrida) para responder à intenção do usuário e fornecer resultados mais relevantes.
Conheça a geração aumentada de recuperação (RAG) a fundo e saiba como essa abordagem pode vincular seus dados proprietários em tempo real a modelos de IA generativa para proporcionar melhores experiências ao usuário final e mais precisão.
Mas o que é recuperação de informações?
Recuperação de informações (RI) refere-se ao processo de busca e extração de informações relevantes de uma fonte de conhecimento ou conjunto de dados. É muito semelhante a usar um mecanismo de busca para procurar informações na internet. Você insere uma consulta e o sistema recupera e apresenta documentos ou páginas da Web com maior probabilidade de conter as informações que você está procurando.
A recuperação de informações envolve técnicas para indexação e busca eficientes em grandes conjuntos de dados; isso facilita o acesso das pessoas às informações específicas de que precisam em um grande conjunto de dados disponíveis. Além dos mecanismos de busca na Web, os sistemas de RI são usados com frequência em bibliotecas digitais, sistemas de gerenciamento de documentos e várias aplicações de acesso a informações.
A evolução dos modelos de linguagem de IA
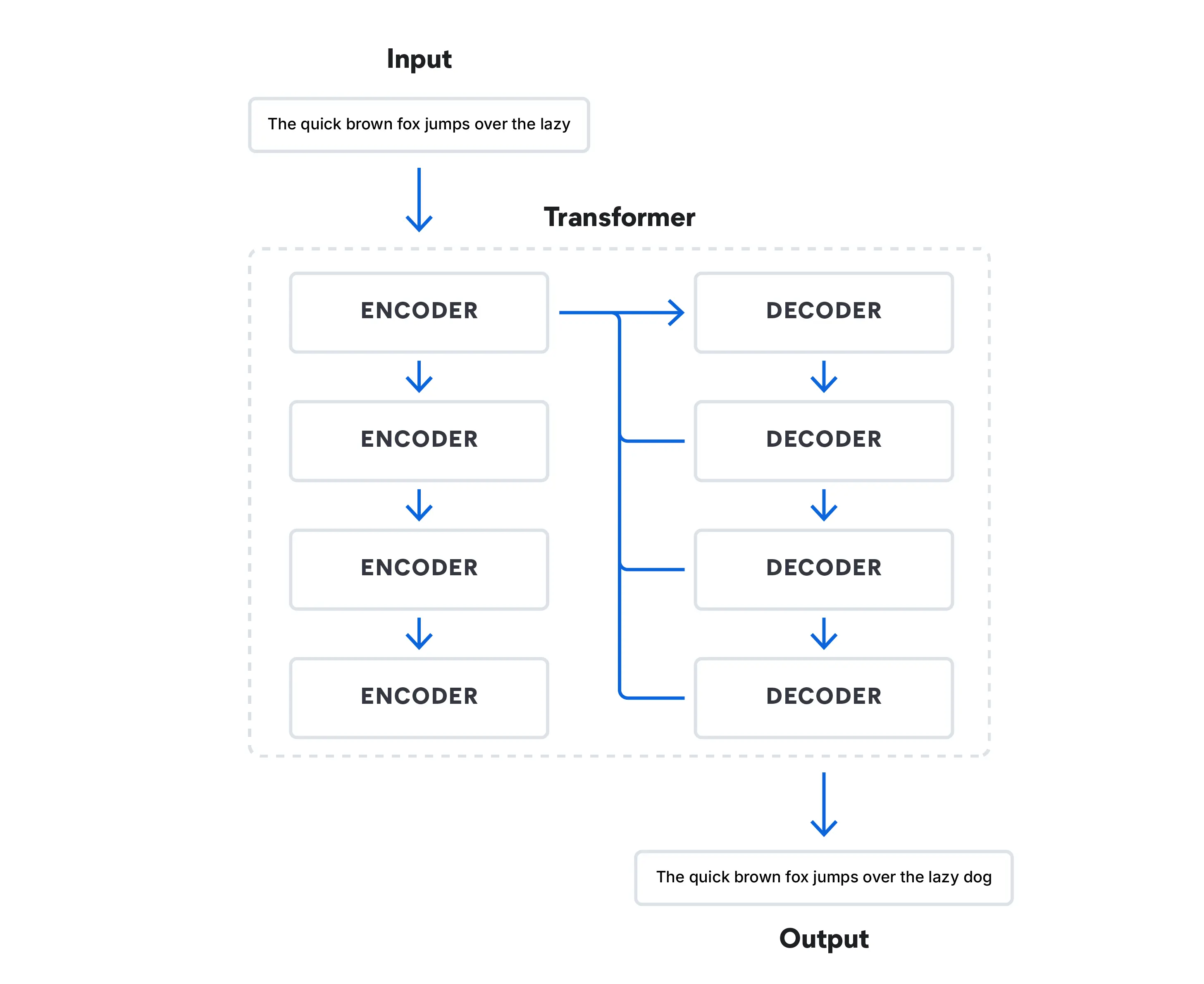
Os modelos de linguagem de IA evoluíram significativamente ao longo dos anos:
- Nas décadas de 1950 e 1960, o campo estava em sua fase inicial, com sistemas elementares baseados em regras que tinham compreensão limitada da linguagem.
- As décadas de 1970 e 1980 introduziram sistemas especialistas: eles codificavam o conhecimento humano para a solução de problemas, mas tinham recursos linguísticos muito limitados.
- A década de 1990 testemunhou o surgimento de métodos estatísticos, que usavam abordagens baseadas em dados para tarefas linguísticas.
- Na década de 2000, surgiram técnicas de machine learning, como máquinas vetoriais de suporte (que categorizavam diferentes tipos de dados de texto em um espaço de alta dimensão), embora o aprendizado profundo ainda estivesse em seus estágios iniciais.
- A década de 2010 representou uma grande mudança no aprendizado profundo. A arquitetura transformadora mudou o processamento de linguagem natural com o uso de mecanismos de atenção, o que permitiu que o modelo se concentrasse em diferentes partes de uma sequência de entrada ao processá-la.
Atualmente, os modelos transformadores processam dados com a simulação da fala humana, prevendo qual palavra vem a seguir em uma sequência de palavras. Esses modelos revolucionaram o campo e levaram ao surgimento de LLMs, como o BERT (Bidirectional Encoder Representations from Transformers) do Google.
Estamos vendo uma combinação de modelos pré-treinados em massa e modelos especializados projetados para tarefas específicas. Modelos como a RAG continuam a ganhar força, ampliando o escopo dos modelos de linguagem de IA generativa para além dos limites do treinamento padrão. Em 2022, a OpenAI introduziu o ChatGPT, que é, sem dúvida, o LLM mais conhecido que se baseia na arquitetura transformadora. Seus concorrentes são modelos de fundação baseada em chat, como o Google Bard e o Bing Chat da Microsoft. O LLaMa 2 da Meta, que não é um chatbot para o consumidor, mas um LLM open source, está disponível gratuitamente para pesquisadores que estão familiarizados com o funcionamento dos LLMs.
Relacionado: Escolhendo um LLM: o guia de primeiros passos de 2024 para LLMs open source
Como funciona o RAG?
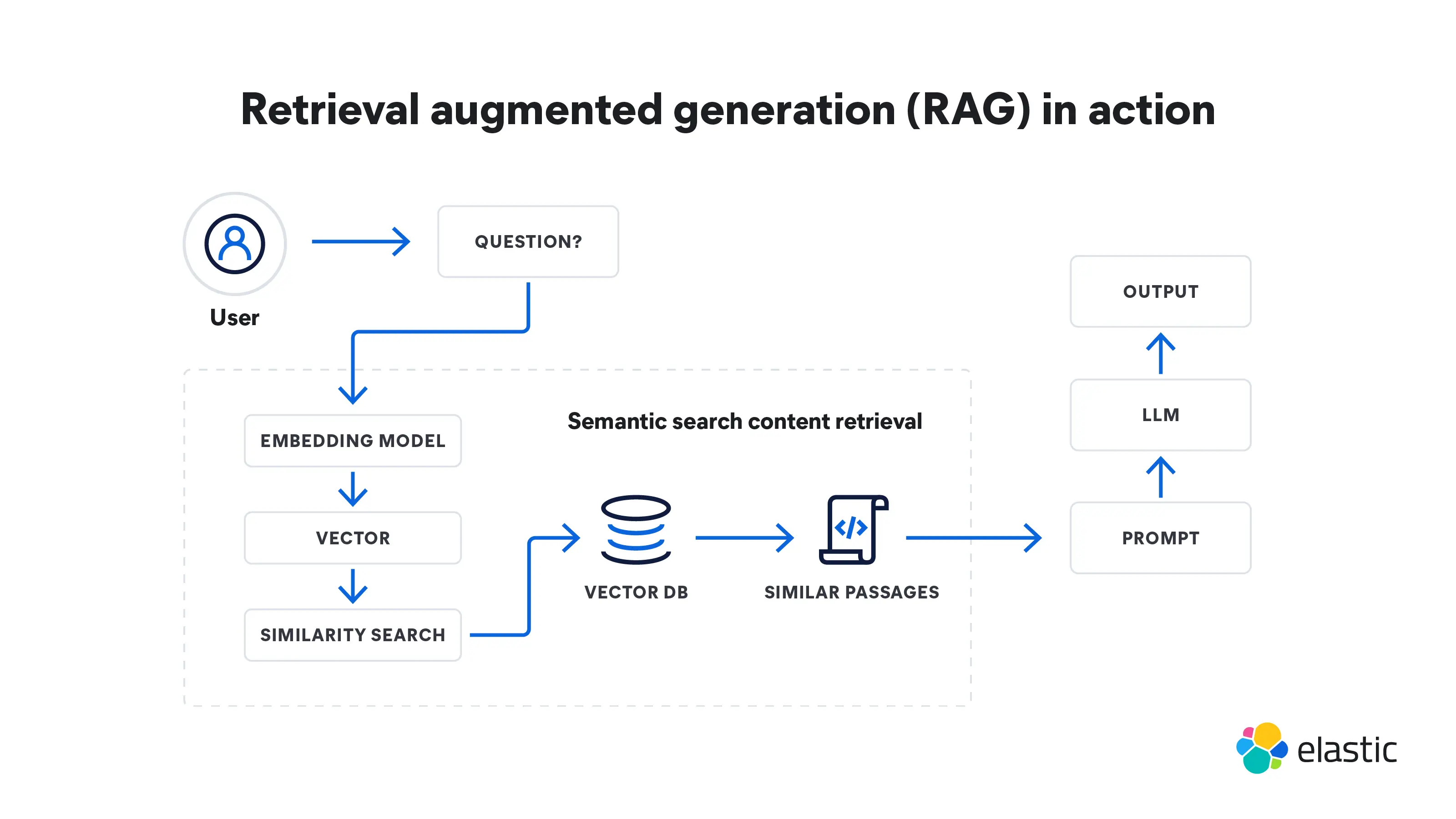
A geração aumentada de recuperação é um processo de várias etapas que começa com a recuperação e depois leva à geração. Ela funciona assim:
Recuperação
- A RAG começa com uma consulta de entrada. Pode ser a pergunta de um usuário ou qualquer parte do texto que exija uma resposta detalhada.
- Um modelo de recuperação obtém informações pertinentes de bases de conhecimento, bancos de dados ou fontes externas, podendo usar várias fontes ao mesmo tempo. O local onde o modelo faz a busca depende do que a consulta de entrada está pedindo. Essas informações recuperadas agora servem como fonte de referência para todos os fatos e contextos de que o modelo precisa.
- As informações recuperadas são convertidas em vetores em um espaço de alta dimensão. Esses vetores de conhecimento são armazenados em um banco de dados de vetores.
- O modelo de recuperação classifica as informações recuperadas com base em sua relevância para a consulta de entrada. Os documentos ou as passagens com as pontuações mais altas são selecionados para processamento posterior.
Geração
- Em seguida, um modelo de geração, como um LLM, usa as informações recuperadas para gerar respostas de texto.
- O texto gerado pode passar por etapas adicionais de pós-processamento para garantir que esteja gramaticalmente correto e coerente.
- Essas respostas são, em geral, mais precisas e fazem mais sentido no contexto porque foram moldadas pelas informações suplementares fornecidas pelo modelo de recuperação. Essa capacidade é especialmente importante em domínios especializados em que os dados públicos da internet são insuficientes.
Benefícios do RAG
A geração aumentada de recuperação apresenta várias vantagens em relação aos modelos de linguagem que funcionam isoladamente. Aqui estão algumas maneiras pelas quais o modelo melhorou a geração de texto e as respostas:
- A RAG garante que o seu modelo possa acessar os fatos mais recentes e atualizados e as informações relevantes, pois ele consegue atualizar regularmente suas referências externas. Dessa forma, as respostas geradas incorporam as informações mais recentes que podem ser relevantes para o usuário responsável pela consultaonsulta. Você também pode implementar segurança em nível do documento para controlar o acesso aos dados em um fluxo de dados e restringir as permissões de segurança a documentos específicos.
- A RAG é uma opção mais econômica, pois requer menos computação e armazenamento, o que significa que você não precisa ter seu próprio LLM ou gastar tempo e dinheiro para ajustar seu modelo.
- Uma coisa é afirmar que fornece precisão, outra é comprovar esse valor. A RAG pode citar suas fontes externas e fornecê-las ao usuário para respaldar suas respostas. Se desejar, o usuário poderá avaliar as fontes para confirmar se a resposta recebida é precisa.
- Embora os chatbots com LLM possam criar respostas mais personalizadas do que as respostas anteriores com script, a RAG consegue personalizar ainda mais suas respostas. Isso ocorre porque ela tem a capacidade de usar métodos de recuperação de busca (geralmente busca semântica) para fazer referência a uma série de pontos informados pelo contexto ao sintetizar sua resposta por meio da avaliação da intenção.
- Quando confrontado com uma consulta complexa para a qual não foi treinado, um LLM pode, às vezes, "alucinar", fornecendo uma resposta imprecisa. Ao fundamentar suas respostas com referências adicionais de fontes de dados relevantes, a RAG pode responder com mais precisão a questionamentos ambíguos.
- Os modelos da RAG são versáteis e podem ser aplicados a uma ampla gama de tarefas de processamento de linguagem natural, incluindo sistemas de diálogo, geração de conteúdo e recuperação de informações.
- A polarização pode ser um problema em qualquer IA criada pelo homem. Ao se basear em fontes externas aprovadas, a RAG pode ajudar a diminuir a parcialidade em suas respostas.
Geração aumentada de recuperação X ajuste fino
A geração aumentada de recuperação e o ajuste fino são duas abordagens diferentes para o treinamento de modelos de linguagem de IA. Enquanto a RAG combina a recuperação de uma ampla gama de conhecimentos externos com a geração de texto, o ajuste fino se concentra em uma faixa estreita de dados para fins distintos.
No ajuste fino, um modelo pré-treinado é aperfeiçoado com base em dados especializados para adaptá-lo a um subconjunto de tarefas. Esse processo envolve a modificação dos pesos e parâmetros do modelo com base no novo conjunto de dados, permitindo que ele aprenda padrões específicos da tarefa e, ao mesmo tempo, retenha o conhecimento de seu pré-treinamento inicial.
O ajuste fino pode ser usado para todos os tipos de IA. Um exemplo básico é aprender a reconhecer gatinhos no contexto de identificação de fotos de gatos na Internet. Nos modelos baseados em idiomas, o ajuste fino pode ajudar em aspectos como classificação de texto, análise de sentimentos e reconhecimento de entidades nomeadas, além da geração de texto. No entanto, esse processo pode ser extremamente demorado e caro. A RAG acelera o processo e consolida esses custos com menos necessidades de computação e armazenamento.
Por ter acesso a recursos externos, a RAG é particularmente útil quando uma tarefa exige a incorporação de informações dinâmicas ou em tempo real da Web ou das bases de conhecimento da empresa para gerar respostas informadas. O ajuste fino possui diferentes pontos fortes: se a tarefa em questão estiver bem definida e o objetivo for otimizar o desempenho apenas nessa tarefa, o ajuste fino pode ser muito eficiente. Ambas as técnicas têm a vantagem de não precisar treinar um LLM do zero para cada tarefa.
Desafios e limitações da geração aumentada de recuperação
Embora a RAG ofereça vantagens significativas, ela também enfrenta vários desafios e limitações:
- A RAG depende de conhecimento externo. Ela pode produzir resultados imprecisos se as informações recuperadas estiverem incorretas.
- O componente de recuperação da RAG envolve a busca em grandes bases de conhecimento ou na Web, o que pode ser caro e demorado do ponto de vista computacional, embora ainda seja mais rápido e menos dispendioso do que o ajuste fino.
- A integração perfeita dos componentes de recuperação e geração exige um projeto e uma otimização cuidadosos, o que pode levar a possíveis dificuldades no treinamento e na implantação.
- A recuperação de informações de fontes externas pode gerar preocupações com a privacidade ao lidar com dados confidenciais. O cumprimento dos requisitos de privacidade e conformidade também pode limitar as fontes que a RAG pode acessar. No entanto, isso pode ser resolvido pelo acesso em nível de documento, no qual você pode conceder acesso e permissões de segurança a funções específicas.
- A RAG é baseada na precisão dos fatos. Ela pode ter dificuldades para gerar conteúdo imaginativo ou fictício, o que limita seu uso na geração de conteúdo criativo.
Perspectivas futuras da geração aumentada de recuperação
As próximas perspectivas da geração aumentada de recuperação se concentram em tornar a tecnologia RAG mais eficiente e adaptável a várias aplicações. Veja algumas delas:
Personalização
Os modelos de RAG continuarão a incorporar o conhecimento específico do usuário. Isso permitirá que eles forneçam respostas ainda mais personalizadas, especialmente em aplicações como recomendações de conteúdo e assistentes virtuais.
Comportamento personalizável
Além da personalização, os próprios usuários também podem ter mais controle sobre como os modelos de RAG se comportam e respondem para ajudá-los a obter os resultados que procuram.
Escalabilidade
Os modelos RAG serão capazes de lidar com volumes ainda maiores de dados e interações de usuários do que conseguem atualmente.
Modelos híbridos
A integração do RAG com outras técnicas de IA (ex. aprendizado por reforço) permitirá a criação de sistemas ainda mais versáteis e sensíveis ao contexto, capazes de lidar com vários tipos de dados e tarefas simultaneamente.
Implantação em tempo real e baixa latência
À medida que os modelos de RAG avançam em sua velocidade de recuperação e tempo de resposta, eles serão mais utilizados em aplicações que exigem respostas rápidas (como chatbots e assistentes virtuais).
Conheça detalhes sobre as tendências da busca técnica em 2024. Assista a este webinar para conhecer práticas recomendadas e metodologias emergentes, e saber como as principais tendências estão influenciando os desenvolvedores em 2024.
Geração aumentada de recuperação com o Elasticsearch
Com o Elasticsearch, você pode criar uma busca habilitada para RAG para seu app de IA generativa, website, clientes ou experiências de funcionários. O Elasticsearch fornece um kit de ferramentas abrangente que permite a você:
- Armazenar e buscar dados proprietários e outras bases de conhecimento externas com o objetivo de extrair contexto
- Gerar resultados de busca altamente relevantes com base em seus dados usando uma variedade de métodos: busca textual, vetorial, híbrida ou semântica
- Criar respostas mais precisas e experiências envolventes para seus usuários
Saiba como o Elasticsearch pode melhorar a IA generativa para sua empresa
Explore mais recursos sobre RAG
- Explore o AI Playground
- Vá além do básico do RAG
- Elasticsearch – o mecanismo de busca mais relevante para RAG
- Escolhendo um LLM: O guia de primeiros passos de 2024 para LLMs open source
- AI search algorithms explained (Algoritmos de busca com IA explicados)
- Como criar um chatbot: o que os desenvolvedores devem e não devem fazer em um mundo voltado para a IA
- Tendências técnicas de 2024: como as tecnologias de busca e IA generativa estão evoluindo
- Crie protótipos e faça a integração com LLMs mais rapidamente
- Banco de dados vetorial mais baixado do mundo — Elasticsearch
- Desmistificando o ChatGPT: diferentes métodos para construir uma busca com IA
- Retrieval vs. poison — Fighting AI supply chain attacks (Recuperação x veneno: combatendo ataques à cadeia de suprimentos com IA