O que é a recuperação de informações?
Definição de recuperação de informações
A recuperação de informações (RI) é um processo que facilita a recuperação eficaz e eficiente de informações relevantes de grandes coleções de dados não estruturados ou semiestruturados. Os sistemas de RI auxiliam na busca, localização e apresentação de informações que correspondam à consulta de busca ou à necessidade de informação do usuário.
Sendo a forma dominante de acesso à informação, a recuperação de informações é utilizada diariamente por bilhões de pessoas que acessam mecanismos de busca. Implantando vários modelos, algoritmos e técnicas cada vez mais avançadas (pense em busca vetorial), os sistemas de recuperação de informações permitem o acesso por busca a uma vasta e crescente variedade de fontes, incluindo documentos, itens dentro de documentos, metadados e bancos de dados de textos, imagens, vídeos e sons.
Uma breve história da recuperação de informações
As raízes da recuperação de informações remontam aos tempos antigos, quando bibliotecas e arquivos foram criados para organizar e armazenar informações, incluindo a indexação e a classificação em ordem alfabética de trabalhos acadêmicos. Por volta de 1800, cartões perfurados eram usados para processar informações e, em 1931, Emanuel Goldberg recebeu a patente do primeiro dispositivo eletromecânico de recuperação de documentos bem-sucedido. Conhecido como “Máquina Estatística”, foi projetado para fazer buscas em dados codificados em filme.
A recuperação de informações começou a tomar a forma do que viria a ser uma disciplina científica em meados do século XX, juntamente com o desenvolvimento dos computadores modernos. Gerard Salton e Hans Peter Luhn foram os pioneiros nos primeiros modelos para recuperação automatizada de documentos. Salton e colegas da Cornell criaram o SMART Information Retrieval System na década de 1960, um marco na área ao qual se atribui o crédito de ter lançado as bases das técnicas modernas e conceitos-chave de RI, incluindo a matriz termo-documento, o modelo de espaço vetorial, o feedback de relevância e a classificação Rocchio.
Na década de 1970, com o surgimento de técnicas de recuperação mais avançadas, modelos probabilísticos e frameworks de processamento vetorial totalmente articulados, o campo avançou significativamente. Com o advento dos mecanismos de busca no final da década de 1990, sistemas e modelos de RI que antes ficavam restritos ao mundo acadêmico, às instituições e às bibliotecas se prestaram a um serviço mais amplo.
Tipos de modelos de recuperação de informações
Diferentes tipos de modelos de recuperação de informações são projetados para enfrentar desafios específicos e estabelecer processos para recuperar informações relevantes. Existem modelos clássicos que constituem as bases do campo, modelos não clássicos que tentam resolver as limitações das abordagens tradicionais e modelos alternativos de RI que vão ainda mais longe, muitas vezes integrando tecnologias avançadas como machine learning e modelos de linguagem. Em um nível geral, os tipos mais comuns de modelos de recuperação de informações são:
Modelo booliano
Um dos modelos de recuperação de informações mais simples e antigos, o modelo booliano é baseado na lógica booliana, que usa operadores como AND, OR e NOT para combinar termos de consulta. Os documentos são representados como conjuntos de termos, e uma consulta é processada para identificar os documentos que correspondem às condições especificadas. Embora seja eficaz para correspondências precisas de consultas, o modelo booliano não consegue classificar documentos com base na relevância ou fornecer correspondências parciais.
Modelo de espaço vetorial
Neste modelo, documentos e consultas são representados como vetores em um espaço multidimensional. Cada dimensão corresponde a um termo único, e o valor em cada dimensão representa a importância e a frequência do termo no documento ou consulta. A similaridade de cosseno entre o vetor de consulta e os vetores de documento é calculada para determinar a relevância dos documentos para a consulta. Desenvolvido em parte para resolver as desvantagens do modelo booliano, o modelo de espaço vetorial consegue fornecer resultados classificados com base em pontuações de relevância e é amplamente utilizado na recuperação de texto.
Modelo probabilístico
Este modelo estima a probabilidade de um documento ser relevante para uma determinada consulta. Ele considera fatores como frequência do termo e tamanho do documento para calcular probabilidades de relevância. É particularmente útil para lidar com grandes quantidades de dados. Por trabalhar com estatísticas ponderadas, o modelo é ideal para fornecer resultados classificados.
Indexação semântica latente (LSI)
A LSI usa decomposição de valor singular (SVD) para capturar as relações semânticas entre termos e documentos. Assim como a busca semântica, a indexação semântica usa intenção e contexto para identificar documentos conceitualmente relacionados, mesmo que eles não compartilhem termos exatos. Esse recurso importante torna a LSI útil para extrair o significado contextual de palavras em um corpo de texto.
Okapi BM25
Uma das variantes mais populares do modelo probabilístico, o BM25 é uma função de classificação da relevância de busca. É usado pelos mecanismos de busca para estimar a relevância de um documento para uma consulta. Ele classifica um conjunto de documentos com base nos termos de consulta que aparecem em cada um deles, independentemente da inter-relação entre os termos dentro de um documento, e consiste em muitas funções de pontuação com diferentes componentes e parâmetros. BM é um acrônimo para “best matching” (melhor correspondência).
Por que a recuperação de informações é importante?
Na Era da Informação, dados são gerados a cada segundo em uma escala que antes era inimaginável. Sem um meio viável de acessar as informações, os dados são praticamente inúteis. Os sistemas de RI garantem que os usuários possam obter as informações relevantes de que necessitam em meio ao crescente ruído da sobrecarga de informações.
A recuperação de informações desempenha um papel vital em quase todos os setores e domínios do mundo moderno, desde o mundo acadêmico e o comércio eletrônico até saúde e defesa. É uma interface homem-máquina que auxilia na tomada de decisões, na pesquisa e na descoberta de conhecimento, tanto em nível empresarial quanto pessoal. Da busca nos nossos computadores localizados à descoberta de notícias do mundo ou da pesquisa genômica à filtragem de spam, a recuperação de informações é fundamental para quase todas as facetas de nossas vidas.
Os mecanismos de busca dependem de modelos de recuperação de informações para fornecer resultados precisos. As plataformas de e-commerce usam modelos de recuperação para recomendar produtos com base nas preferências e no comportamento do usuário. As bibliotecas digitais contam com a ciência da recuperação de informações para ajudar os usuários a fazer pesquisas. Na área da saúde, os sistemas de RI auxiliam na busca em bancos de dados de registros relevantes de pacientes, pesquisas médicas e protocolos de tratamento. E os profissionais jurídicos usam a recuperação de informações para vasculhar grandes volumes de casos judiciais em busca de precedentes.
Como funciona um sistema de recuperação de informações?
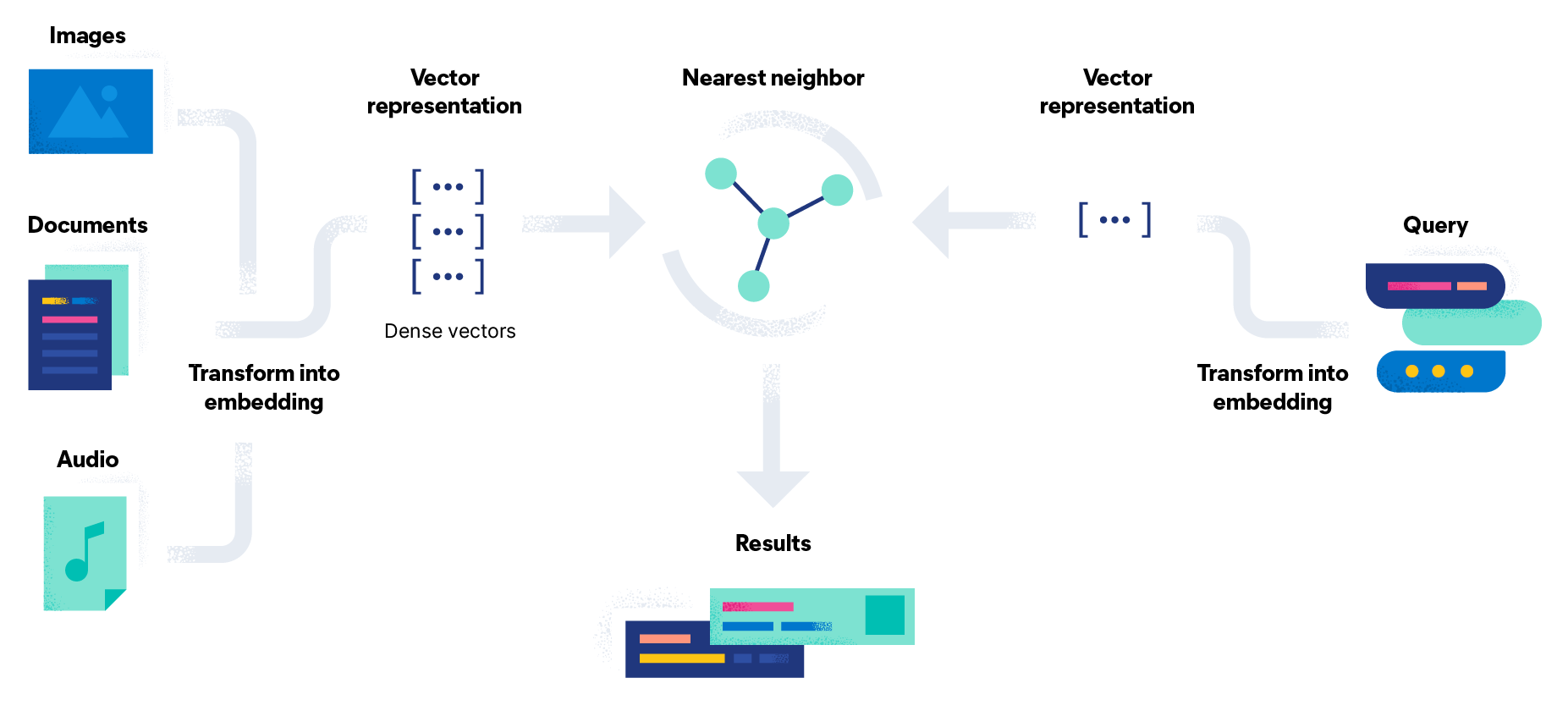
O processo de recuperação de informações normalmente é disparado quando um usuário insere uma consulta formal em um sistema informando suas necessidades de informação. O sistema de RI cria um índice de documentos em uma coleção de conteúdo ou banco de dados de informações. Objetos de dados, incluindo aqueles de documentos de texto, imagens, áudio e vídeos, são processados para extrair termos relevantes e dados alternativos, e estruturas de dados são usadas para armazenar e recuperar essas entidades com eficiência.
Quando um usuário envia uma consulta, o sistema a processa para identificar termos relevantes e determinar sua importância. O sistema então classifica os documentos com base na sua relevância para a consulta. Em muitos casos, modelos e algoritmos de RI são usados para calcular uma pontuação numérica com base na correspondência de cada objeto da coleção ou banco de dados com a consulta. Muitas consultas não serão uma correspondência exata: os documentos mais relevantes são apresentados ao usuário em uma lista classificada. Esses resultados classificados representam uma das principais diferenças entre a busca de recuperação de informações e a busca em banco de dados.
Principais componentes de um sistema de recuperação de informações
Um sistema de recuperação de informações consiste em vários componentes principais:
Coleta de documentos
O conjunto de documentos dos quais o sistema pode recuperar informações.
Componente de indexação
Os dados e documentos de origem são processados para criar um índice, mapeando termos e dados para os documentos que os contêm, geralmente em uma estrutura de dados dedicada e otimizada.
Processador de consultas
O processador de consultas analisa as consultas e palavras-chave do usuário e as prepara para correspondência com as entidades indexadas.
Algoritmo de classificação
O algoritmo de classificação determina a relevância dos documentos para uma consulta e atribui pontuações a eles. O mais comum é o algoritmo de classificação BM25 (Best Match 25), que se destaca por sua abordagem modificada para a frequência dos termos, evitando a saturação excessiva do documento com palavras-chave e termos repetidos.
Interface do usuário
A UI é a tela por meio da qual os usuários interagem com o sistema, enviam consultas e recebem os resultados. Aqui, os resultados podem ser ajustados com base em como atendem à consulta do usuário. Em alguns casos, os mecanismos podem permitir que os usuários forneçam feedback sobre a relevância dos documentos recuperados, o que pode ser usado para melhorar recuperações futuras.
Benefícios da recuperação de informações
Estes são alguns benefícios significativos dos modelos de recuperação de informações:
- Acesso eficiente às informações. Acima de tudo, os sistemas de RI economizam uma quantidade incalculável de tempo e esforço. A recuperação de informações permite que os usuários acessem rapidamente informações relevantes sem buscar manualmente em grandes quantidades de documentos e dados.
- Descoberta de conhecimento. A recuperação de informações é uma ferramenta poderosa que nos permite dar sentido aos dados. Com a RI, os usuários podem identificar tendências, padrões e relações nos dados que podiam não ser aparentes a princípio.
- Personalização. Alguns sistemas de RI podem adaptar os resultados para usuários individuais de forma significativa com base em suas preferências e comportamentos.
- Suporte a decisões. Os profissionais ganham capacitação para tomar decisões informadas com o acesso às informações mais pertinentes quando necessário.
Desafios e limitações da recuperação de informações
Apesar dos avanços significativos, a recuperação de informações nunca foi perfeita. Problemas, desafios e limitações conhecidos permanecem, incluindo:
Ambiguidade. A linguagem natural é inerentemente ambígua, tornando difícil interpretar com precisão as consultas dos usuários. Problemas semelhantes de imprecisão e incerteza podem afetar o processo de indexação e avaliação, particularmente no caso de objetos como imagens e vídeos.
Relevância. A determinação da relevância é algo subjetivo e pode variar de acordo com o contexto e a intenção do usuário. Os critérios usados para determinar o valor e a importância podem ser regidos por um conjunto de padrões gerais imperfeitos que não refletem as necessidades específicas do usuário individual.
Lacunas semânticas. Os sistemas de recuperação podem ter dificuldade para capturar o significado mais profundo do conteúdo devido à lacuna entre a representação textual e a compreensão humana. A falta de clareza nas informações e na expressão dos usuários representa um grande obstáculo para o sucesso da RI. O processamento de linguagem natural avançado baseado em IA busca preencher essas lacunas semânticas e de ambiguidade.
Escalabilidade. À medida que os volumes de dados aumentam, torna-se mais complexo manter a eficiência e a eficácia da recuperação e da indexação, exigindo cada vez mais recursos e capacidade de computação.
Tendências futuras na recuperação de informações
Com os avanços recentes em IA generativa e machine learning, a recuperação de informações como a conhecemos pode estar prestes a sofrer uma mudança transformacional.
Técnicas avançadas de machine learning já estão aprimorando a recuperação, aprendendo com as interações do usuário e adaptando-se às mudanças de contextos, locais e preferências. O processamento de linguagem natural aprimorado e a análise semântica criam uma melhor compreensão das consultas dos usuários e do conteúdo dos documentos. Os sistemas de recuperação também estão evoluindo para lidar de forma mais eficaz com o volume cada vez maior de conteúdo multimídia.
O impacto da IA generativa na recuperação de informações tem potencial para ser revolucionário. Em vez da lista classificada de resultados a que estamos acostumados, que exige a classificação manual por meio de links e documentos existentes para encontrar o que procuramos, receberemos respostas reais às nossas perguntas. O contexto será transferido de pergunta para pergunta, permitindo investigações complexas, conversacionais e em várias etapas, com as barreiras do processamento e da intenção da linguagem humana sendo praticamente eliminadas. Em vez de nós mesmos reunirmos as respostas, os mecanismos de busca farão o trabalho por nós, sintetizando informações em resultados específicos e customizados na forma de conteúdo original que fornece exatamente o que precisamos — e nada que for desnecessário.
Conheça detalhes sobre as tendências da busca técnica em 2024. Assista a este webinar para conhecer práticas recomendadas e metodologias emergentes, e saber como as principais tendências estão influenciando os desenvolvedores em 2024.
Recuperação de informações com o Elasticsearch
A Elastic se dedica a melhorar constantemente os recursos de recuperação de informações disponíveis no Elastic Stack. Nosso mais novo modelo de recuperação, o Elastic Learned Sparse Encoder, amplia a recuperação pronta para uso da Elastic com um modelo de linguagem pré-treinado. E para alcançar uma experiência de um clique, nós o integramos ao novo Elasticsearch Relevance Engine.
O Elasticsearch também tem excelentes recursos de recuperação lexical e ferramentas avançadas para combinar os resultados de diferentes consultas, um conceito conhecido como recuperação híbrida. Também estamos aprimorando os recursos do chatbot com PLN e busca vetorial, lançando modelos de processamento de linguagem natural de terceiros para embeddings de texto e avaliando nosso desempenho usando um subconjunto do BEIR.
Explore mais recursos sobre recuperação de informações
- Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model (Melhorando a recuperação de informações no Elastic Stack: apresentamos o Elastic Learned Sparse Encoder, nosso novo modelo de recuperação)
- Improving information retrieval in the Elastic Stack: Steps to improve search relevance (Melhorando a recuperação de informações no Elastic Stack: etapas para melhorar a relevância da busca)
- Improving information retrieval in the Elastic Stack: Benchmarking passage retrieval (Melhorando a recuperação de informações no Elastic Stack: avaliação comparativa da recuperação de passagens)
- Improving information retrieval in the Elastic Stack: Hybrid retrieval (Melhorando a recuperação de informações no Elastic Stack: recuperação híbrida)
- AI search algorithms explained (Algoritmos de busca com IA explicados)
O que você deve fazer a seguir
Quando você estiver pronto(a)... veja aqui quatro maneiras para ajudar você a aproveitar os insights dos dados da sua empresa:
- Inicie uma avaliação gratuita e veja como a Elastic pode ajudar sua empresa.
- Conheça nossas soluções para ver como a Elasticsearch Platform funciona e elas atenderão às suas necessidades.
- Descubra como fornecer IA generativa na empresa.
- Compartilhe este artigo com alguém que você conhece e que gostaria de lê-lo. Compartilhe por email, LinkedIn, Twitter ou Facebook.