O que é machine learning?
Definição de machine learning
Machine learning (ML) é um ramo da inteligência artificial (IA) que se concentra no uso de dados e algoritmos para imitar a maneira como os humanos aprendem, melhorando gradualmente a precisão ao longo do tempo. Foi definido pela primeira vez na década de 1950 como "o campo de estudo que dá aos computadores a capacidade de aprender sem serem explicitamente programados" por Arthur Samuel, um cientista da computação e inovador em IA.
O machine learning envolve alimentar algoritmos de computador com grandes quantidades de dados para que eles possam aprender a identificar padrões e relacionamentos dentro desse conjunto de dados. Os algoritmos começam então a fazer suas próprias previsões ou tomar decisões com base em suas análises. À medida que os algoritmos recebem novos dados, continuam a refinar suas escolhas e melhorar seu desempenho da mesma forma que uma pessoa melhora em uma atividade com a prática.
Quais são os quatro tipos de machine learning?
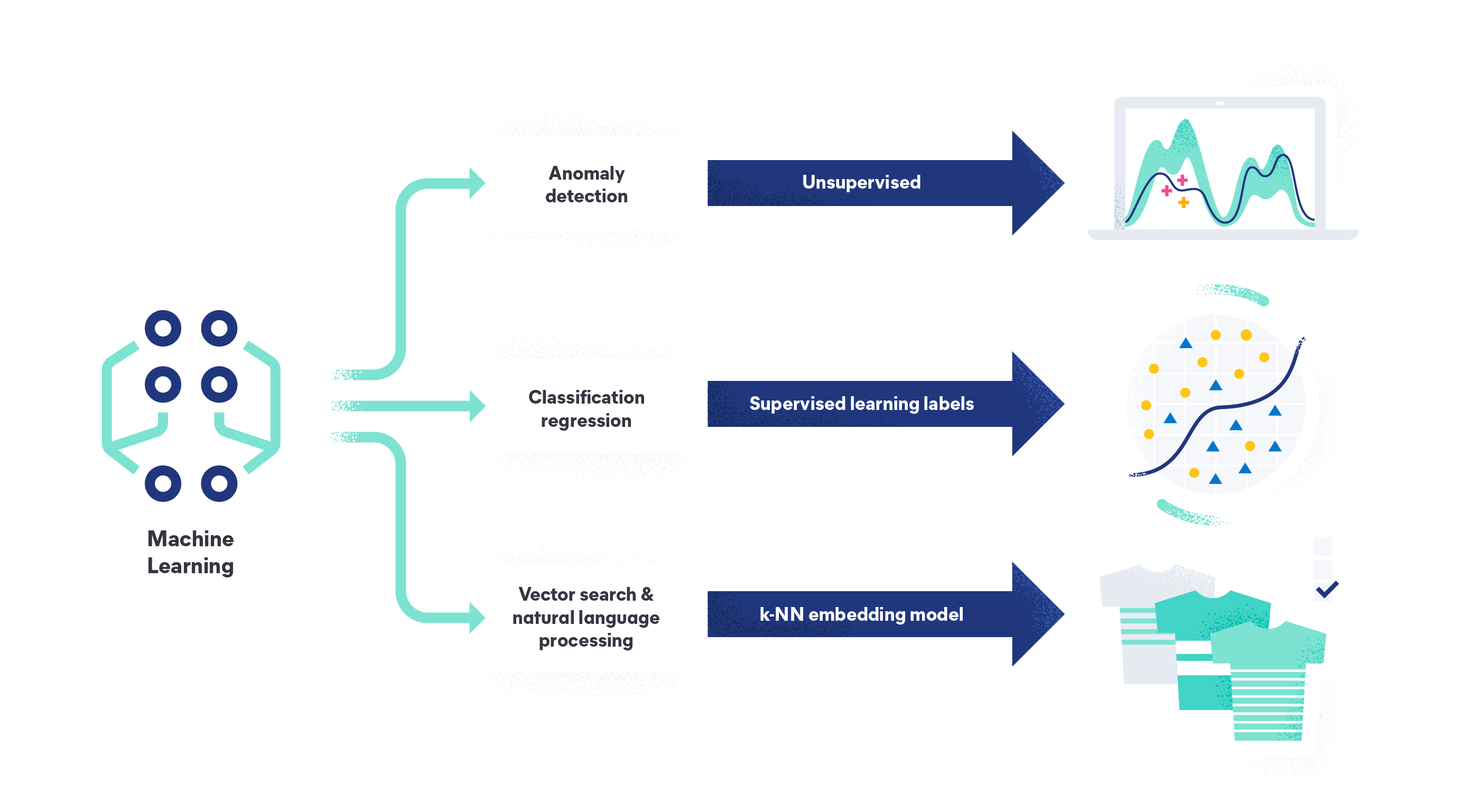
Os quatro tipos de machine learning são: machine learning supervisionado, machine learning não supervisionado, aprendizado semi-supervisionado e aprendizado por reforço.
Machine learning supervisionado é o tipo mais comum de machine learning. Em modelos de aprendizado supervisionado, o algoritmo aprende a partir de conjuntos de dados de treinamento rotulados e melhora sua precisão ao longo do tempo. É projetado para construir um modelo que pode prever corretamente a variável de destino quando recebe novos dados que não viu antes. Um exemplo seria os humanos rotulando e fornecendo imagens de rosas, bem como de outras flores. Então, quando recebesse uma nova imagem não rotulada de uma rosa, o algoritmo seria capaz de identificá-la corretamente.
Machine learning não supervisionado é quando o algoritmo procura padrões em dados que não foram rotulados e não têm variáveis de destino. O objetivo é encontrar padrões e relacionamentos nos dados que os humanos possam ainda não ter identificado, como detectar anomalias em logs, traces e métricas para encontrar problemas no sistema e ameaças à segurança.
Aprendizado semi-supervisionado é um híbrido de machine learning supervisionado e não supervisionado. No aprendizado semi-supervisionado, o algoritmo treina em dados rotulados e não rotulados. Ele primeiro aprende com um pequeno conjunto de dados rotulados a fazer previsões ou tomar decisões com base nas informações disponíveis. Em seguida, usa o conjunto maior de dados não rotulados para refinar suas previsões ou decisões, encontrando padrões e relacionamentos nos dados.
Aprendizado por reforço é quando o algoritmo aprende por tentativa e erro, recebendo feedback na forma de recompensas ou penalidades por suas ações. Alguns exemplos: treinar um agente de IA para jogar um videogame, no qual ele recebe uma recompensa positiva por avançar de nível e uma penalidade por falhar; otimizar uma cadeia de suprimentos, na qual o agente é recompensado por minimizar custos e maximizar a velocidade de entrega; ou sistemas de recomendação, nos quais o agente sugere produtos ou conteúdos e é recompensado por compras e cliques.
Como funciona o machine learning?
O machine learning pode funcionar de diferentes maneiras. Você pode aplicar um modelo de machine learning treinado a novos dados ou pode treinar um novo modelo do zero.
A aplicação de um modelo de machine learning treinado a novos dados geralmente é um processo mais rápido e que consome menos recursos. Em vez de desenvolver parâmetros por meio de treinamento, você usa os parâmetros do modelo para fazer previsões sobre os dados de entrada, um processo chamado de inferência. Você também não precisa avaliar o desempenho, pois ele já foi avaliado durante a fase de treinamento. No entanto, ele exige que você prepare cuidadosamente os dados de entrada para garantir que estejam no mesmo formato dos dados usados para treinar o modelo.
O treinamento de um novo modelo de machine learning envolve as seguintes etapas:
Coleta de dados
Comece escolhendo seus conjuntos de dados. Os dados podem vir de várias fontes, como logs do sistema, métricas e traces. Além de logs e métricas, vários outros tipos de dados de série temporal são importantes no treinamento de machine learning, como:
- Dados do mercado financeiro, como preços de ações, taxas de juros e taxas de câmbio. Esses dados geralmente são usados para criar modelos preditivos para fins de trading e investimento.
- Dados de série temporal de transporte, como volume de tráfego, velocidade e tempo de viagem. Esses dados podem ser usados para otimizar rotas e reduzir o congestionamento do tráfego.
- Dados de uso do produto, como tráfego do site e engajamento em redes sociais. Esses dados podem ajudar as empresas a entender o comportamento do cliente e identificar áreas de melhoria.
Quaisquer que sejam os dados que você usar, eles devem ser relevantes para o problema que você está tentando resolver e devem ser representativos da população sobre a qual você deseja fazer previsões ou tomar decisões.
Pré-processamento de dados
Depois de coletar os dados, você precisa pré-processá-los para torná-los utilizáveis por um algoritmo de machine learning. Às vezes, isso envolve rotular os dados ou atribuir uma categoria ou valor específico a cada ponto de dados em um conjunto de dados, o que permite que um modelo de machine learning aprenda padrões e faça previsões.
Além disso, pode envolver a remoção de valores ausentes, a transformação de dados de série temporal em um formato mais compacto com a aplicação de agregações e o redimensionamento dos dados para garantir que todos os recursos tenham intervalos semelhantes. Ter uma grande quantidade de dados de treinamento rotulados é um requisito para redes neurais profundas, como grandes modelos de linguagem (LLMs). Para os modelos supervisionados clássicos, você não precisa processar tanto.
Seleção de recursos
Algumas abordagens exigem que você selecione os recursos que serão usados pelo modelo. Essencialmente, você deve identificar as variáveis ou os atributos mais relevantes para o problema que está tentando resolver. As correlações são uma maneira básica de identificar os recursos. Para otimizar ainda mais, há métodos de seleção de recursos automatizados disponíveis que são aceitos por muitos frameworks de ML.
Seleção de modelo
Agora que você selecionou os recursos, precisa escolher um modelo de machine learning que seja adequado para o problema que está tentando resolver. Entre as opções, incluem-se os modelos de regressão, as árvores de decisão e as redes neurais. (Veja “Técnicas e algoritmos de machine learning” abaixo.)
Treinamento
Depois de escolher um modelo, você precisa treiná-lo usando os dados coletados e pré-processados. O treinamento é onde o algoritmo aprende a identificar padrões e relacionamentos nos dados e os codifica nos parâmetros do modelo. Para alcançar o desempenho ideal, o treinamento é um processo iterativo. Isso pode incluir o ajuste de hiperparâmetros do modelo e a melhoria do processamento de dados e da seleção de recursos.
Teste
Agora que o modelo foi treinado, você precisa testá-lo em novos dados que ele não viu antes e comparar seu desempenho com outros modelos. Você seleciona o modelo de melhor desempenho e avalia seu desempenho em dados de teste separados. Somente dados não utilizados anteriormente fornecerão uma boa estimativa de como seu modelo pode funcionar depois de implantado.
Implantação do modelo
Quando estiver satisfeito(a) com o desempenho do modelo, você poderá implantá-lo em um ambiente de produção onde ele pode fazer previsões ou tomar decisões em tempo real. Isso pode envolver a integração do modelo com outros sistemas ou aplicações de software. Frameworks de ML integrados a provedores de computação em nuvem conhecidos facilitam bastante a implantação do modelo na nuvem.
Monitoramento e atualização
Após a implantação do modelo, você precisará monitorar seu desempenho e atualizá-lo periodicamente conforme novos dados se tornarem disponíveis ou conforme o problema que você estiver tentando resolver for evoluindo com o tempo. Isso pode significar treinar novamente o modelo com novos dados, ajustar seus parâmetros ou escolher um algoritmo de ML totalmente diferente.
Por que o machine learning é importante?
O machine learning é importante porque aprende a executar tarefas complexas usando exemplos, sem programar algoritmos especializados. Em comparação com as abordagens algorítmicas tradicionais, o machine learning permite que você automatize mais, melhore as experiências do cliente e crie aplicações inovadoras que antes não eram viáveis. Além disso, os modelos de machine learning podem melhorar iterativamente durante o uso! Alguns exemplos:
- Prever tendências para melhorar as decisões de negócios
- Personalizar recomendações que aumentam a receita e a satisfação do cliente
- Automatizar o monitoramento de aplicações complexas e da infraestrutura de TI
- Identificar spam e detectar violações de segurança
Técnicas e algoritmos de machine learning
Existem muitas técnicas e algoritmos de machine learning disponíveis. Sua seleção vai depender do problema que você está tentando resolver e das características dos dados. Aqui está uma rápida visão geral de alguns dos mais comuns: A regressão linear é usada quando o objetivo é prever uma variável contínua.
A regressão linear pressupõe uma relação linear entre as variáveis de entrada e a variável de destino. Um exemplo seria prever preços de casas como uma combinação linear de metragem quadrada, localização, número de dormitórios e outros recursos.
A regressão logística é usada para problemas de classificação binária em que o objetivo é prever um resultado sim/não. A regressão logística estima a probabilidade da variável de destino com base em um modelo linear de variáveis de entrada. Um exemplo seria prever se um pedido de empréstimo será aprovado ou não com base na pontuação de crédito do requerente e outros dados financeiros.
As árvores de decisão seguem um modelo semelhante a uma árvore para mapear decisões para possíveis consequências. Cada decisão (regra) representa um teste de uma variável de entrada, e várias regras podem ser aplicadas sucessivamente seguindo um modelo semelhante a uma árvore. Ele divide os dados em subconjuntos, usando o recurso mais significativo em cada nó da árvore. Por exemplo, as árvores de decisão podem ser usadas para identificar clientes em potencial para uma campanha de marketing com base em seus dados demográficos e interesses.
Florestas aleatórias combinam várias árvores de decisão para melhorar a precisão da previsão. Cada árvore de decisão é treinada em um subconjunto aleatório dos dados de treinamento e em um subconjunto das variáveis de entrada. As florestas aleatórias são mais precisas do que as árvores de decisão individuais e lidam melhor com conjuntos de dados complexos ou dados ausentes, mas podem crescer bastante, exigindo mais memória quando usadas em inferência.
As árvores de decisão com boosting treinam uma sucessão de árvores de decisão, com cada árvore de decisão melhorando a anterior. O procedimento de boosting pega os pontos de dados que foram classificados erroneamente pela iteração anterior da árvore de decisão e treina novamente uma nova árvore de decisão para melhorar a classificação desses pontos que foram classificados incorretamente antes. O popular pacote XGBoost do Python implementa esse algoritmo.
As máquinas de vetores de suporte trabalham para encontrar um hiperplano que melhor separe os pontos de dados de uma classe daqueles de outra classe. Ele faz isso minimizando a “margem” entre as classes. Os vetores de suporte referem-se às poucas observações que identificam a localização do hiperplano separador, que é definido por três pontos. O algoritmo de SVM padrão se aplica apenas à classificação binária. Problemas multiclasse são reduzidos a uma série de problemas binários.
As redes neurais são inspiradas na estrutura e na função do cérebro humano. Elas consistem em camadas interconectadas de nós que podem aprender a reconhecer padrões nos dados ajustando a força das conexões entre eles.
Os algoritmos de cluster são usados para agrupar pontos de dados em clusters com base em sua similaridade. Eles podem ser usados para tarefas como segmentação de clientes e detecção de anomalia. São particularmente úteis para segmentação e processamento de imagens.
Quais são as vantagens do machine learning?
As vantagens do machine learning são inúmeras. Ele pode ajudar a capacitar suas equipes a alcançar um nível superior de desempenho nas seguintes categorias:
- Automação. Tarefas cognitivas que são desafiadoras para os humanos devido à repetitividade ou à dificuldade objetiva podem ser automatizadas com machine learning. Entre os exemplos incluem-se monitoramento de sistemas complexos em rede, identificação de atividades suspeitas em sistemas complexos e previsão de quando o equipamento precisa de manutenção.
- Experiência do cliente. A inteligência fornecida pelos modelos de machine learning pode elevar as experiências do usuário. Para aplicações baseadas em busca, a captura de intenções e preferências permite fornecer resultados mais relevantes e personalizados. Os usuários podem buscar e encontrar o que querem dizer.
- Inovação. O machine learning resolve problemas complexos que não era possível resolver com algoritmos específicos. Por exemplo, buscar dados não estruturados, incluindo imagens ou som; otimizar padrões de tráfego e melhorar os sistemas de transporte público; e diagnosticar condições de saúde.
Saiba como o machine learning eleva a busca a um patamar superior
Casos de uso de machine learning
Aqui estão algumas subcategorias de machine learning e seus casos de uso:
Análise de sentimentos é o processo de uso do processamento de linguagem natural para analisar dados de texto e determinar se o sentimento geral é positivo, negativo ou neutro. É útil para empresas que querem receber o feedback do cliente porque pode analisar uma variedade de fontes de dados (como tweets no Twitter, comentários no Facebook e avaliações de produtos) para avaliar as opiniões dos clientes e os níveis de satisfação.
Detecção de anomalia é o processo de uso de algoritmos para identificar padrões incomuns ou discrepâncias nos dados que podem indicar um problema. A detecção de anomalia é usada para monitorar a infraestrutura de TI, aplicações online e redes, e para identificar atividades que sinalizem uma possível violação de segurança ou possam levar a uma interrupção da rede posteriormente. A detecção de anomalia também é usada para detectar transações bancárias fraudulentas. Saiba mais sobre AIOps.
O reconhecimento de imagem analisa imagens e identifica objetos, rostos ou outras características nas imagens. Tem uma variedade de aplicações além de ferramentas comumente usadas como a busca de imagens do Google. Por exemplo, pode ser usado na agricultura para monitorar a saúde das safras e identificar pragas ou doenças. Carros autônomos, imagens médicas, sistemas de vigilância e jogos de realidade aumentada usam reconhecimento de imagem.
A análise preditiva analisa dados históricos e identifica padrões que podem ser usados para fazer previsões sobre eventos futuros ou tendências. Isso pode ajudar as empresas a otimizar suas operações, prever a demanda ou identificar possíveis riscos ou oportunidades. Entre os exemplos, incluem-se previsões de demanda de produtos, atrasos no tráfego e por quanto tempo os equipamentos de fabricação podem funcionar com segurança.
Saiba mais sobre manutenção preditiva
Quais são as desvantagens do machine learning?
Estas são algumas das desvantagens do machine learning:
- Dependência de dados de treinamento de alta qualidade. Se os dados forem tendenciosos ou incompletos, o modelo também poderá ser tendencioso ou impreciso.
- Custo. Pode haver um alto custo associado ao treinamento dos modelos e ao pré-processamento dos dados. Apesar disso, o custo ainda é menor do que o custo de programar um algoritmo especializado para realizar a mesma tarefa, e provavelmente o resultado não seria tão preciso.
- Falta de explicabilidade. A maioria dos modelos de machine learning, como as redes neurais profundas, carece de transparência quanto à forma como operam. Sendo comumente chamados de modelos de “caixa preta”, torna-se difícil entender como os modelos chegam a suas decisões.
- Expertise. Existem muitos tipos de modelos para escolher. Sem uma equipe de ciência de dados designada, as organizações podem ter dificuldades com o ajuste de hiperparâmetros para obter o desempenho ideal. A complexidade do treinamento, especialmente para transformadores, embedding e grandes modelos de linguagem, também pode ser uma barreira à adoção.
Práticas recomendadas para machine learning
Algumas práticas recomendadas para machine learning:
- Certifique-se de que seus dados estejam limpos, organizados e completos.
- Selecione a abordagem correta que vai ao encontro do seu problema e dos seus dados atuais.
- Use técnicas para evitar o overfitting, no qual o modelo funciona bem nos dados de treinamento, mas mal nos novos dados.
- Avalie o desempenho do seu modelo testando-o em dados não vistos. O desempenho medido durante o desenvolvimento e a otimização do modelo não é um bom indicador de como será seu desempenho em produção.
- Ajuste as configurações do modelo para encontrar o melhor desempenho — conhecido como ajuste de hiperparâmetros.
- Escolha métricas além da precisão do modelo padrão que avaliem o desempenho do modelo no contexto da sua aplicação e do problema de negócios.
- Mantenha registros detalhados para garantir que outras pessoas possam entender e replicar seu trabalho.
- Mantenha seu modelo atualizado para garantir que ele continue a ter um bom desempenho em novos dados.
Comece a trabalhar com o machine learning da Elastic
O machine learning da Elastic herda os benefícios da nossa plataforma Elasticsearch escalável. Você obtém valor imediato com integrações com soluções de observabilidade, segurança e busca que usam modelos que exigem menos treinamento para começar a funcionar. Com a Elastic, você pode obter novos insights para oferecer experiências revolucionárias a seus usuários internos e clientes, tudo com confiabilidade em escala.
Saiba como você pode:
Fazer a ingestão de dados de centenas de fontes e usar as integrações para aplicar machine learning e processamento de linguagem natural onde seus dados residem.
Aplicar o machine learning da maneira que funcionar melhor para você. Obtenha valor imediato com modelos pré-configurados, dependendo do seu caso de uso: modelos pré-configurados para monitoramento automatizado e caça a ameaças; modelos pré-treinados e transformadores para implementar tarefas de PLN como análise de sentimentos ou interação de resposta a perguntas; e o Elastic Learned Sparse Encoder™ para implementar busca semântica com apenas um clique. Ou, se seu caso de uso exigir modelos otimizados e customizados, treine modelos supervisionados usando seus dados. A Elastic oferece flexibilidade para você aplicar a abordagem mais adequada aos seus casos de uso e que corresponda ao seu nível de especialização.
Recursos sobre machine learning
- Machine learning para o Elasticsearch
- Machine learning in the Elastic Stack (Machine learning no Elastic Stack)
- Access third-party ML models and transformers in Elastic (Acessar modelos de ML e transformadores de terceiros no Elastic)
- Eleve a busca a um patamar superior com machine learning
- Aplique machine learning à observabilidade com AIOps
- Increase depth of defense in security with machine learning (Aumente a profundidade da defesa na segurança com machine learning)
Glossário de termos de machine learning
- Inteligência artificial é a capacidade das máquinas executarem tarefas que normalmente requerem inteligência humana, como aprendizado, raciocínio, resolução de problemas e tomada de decisões.
- Redes neurais são um tipo de algoritmo de machine learning que consiste em camadas interconectadas de nós que processam e transmitem informações. São inspiradas na estrutura e na função do cérebro humano.
- Aprendizado profundo é um subcampo das redes neurais que tem muitas camadas, permitindo aprender relacionamentos significativamente mais complexos do que outros algoritmos de machine learning.
- Processamento de linguagem natural (PLN) é um subcampo da IA que se concentra em possibilitar que as máquinas entendam, interpretem e gerem linguagem humana.
- Busca vetorial é um tipo de algoritmo de busca que usa embeddings vetoriais e busca de k vizinhos mais próximos para recuperar informações relevantes de grandes conjuntos de dados.