Definição
O que é a busca vetorial?
A busca vetorial aproveita o machine learning (ML) para capturar o significado e o contexto de dados não estruturados, incluindo texto e imagens, transformando-os em uma representação numérica. Frequentemente usada para busca semântica, a busca vetorial encontra dados semelhantes usando algoritmos de vizinho mais próximo aproximado (ANN). Em comparação com a busca tradicional por palavra-chave, a busca vetorial produz resultados mais relevantes e é executada mais rapidamente.

Por que a busca vetorial é importante?
Quantas vezes você já procurou algo, mas não tinha certeza de como se chamava? Você pode saber o que a coisa faz ou ter uma descrição. Mas sem as palavras-chave, só lhe resta ficar procurando.
A busca vetorial supera essa limitação, permitindo que você faça buscas pelo que quer dizer. Ela pode fornecer respostas a consultas rapidamente com base na busca por similaridade. Isso acontece porque o embedding vetorial captura os dados não estruturados que vão além do texto: vídeos, imagens, áudio. Você pode aprimorar a experiência de busca combinando a busca vetorial com filtragem e agregações para otimizar a relevância, implementando uma busca híbrida e combinando-a com a pontuação tradicional.
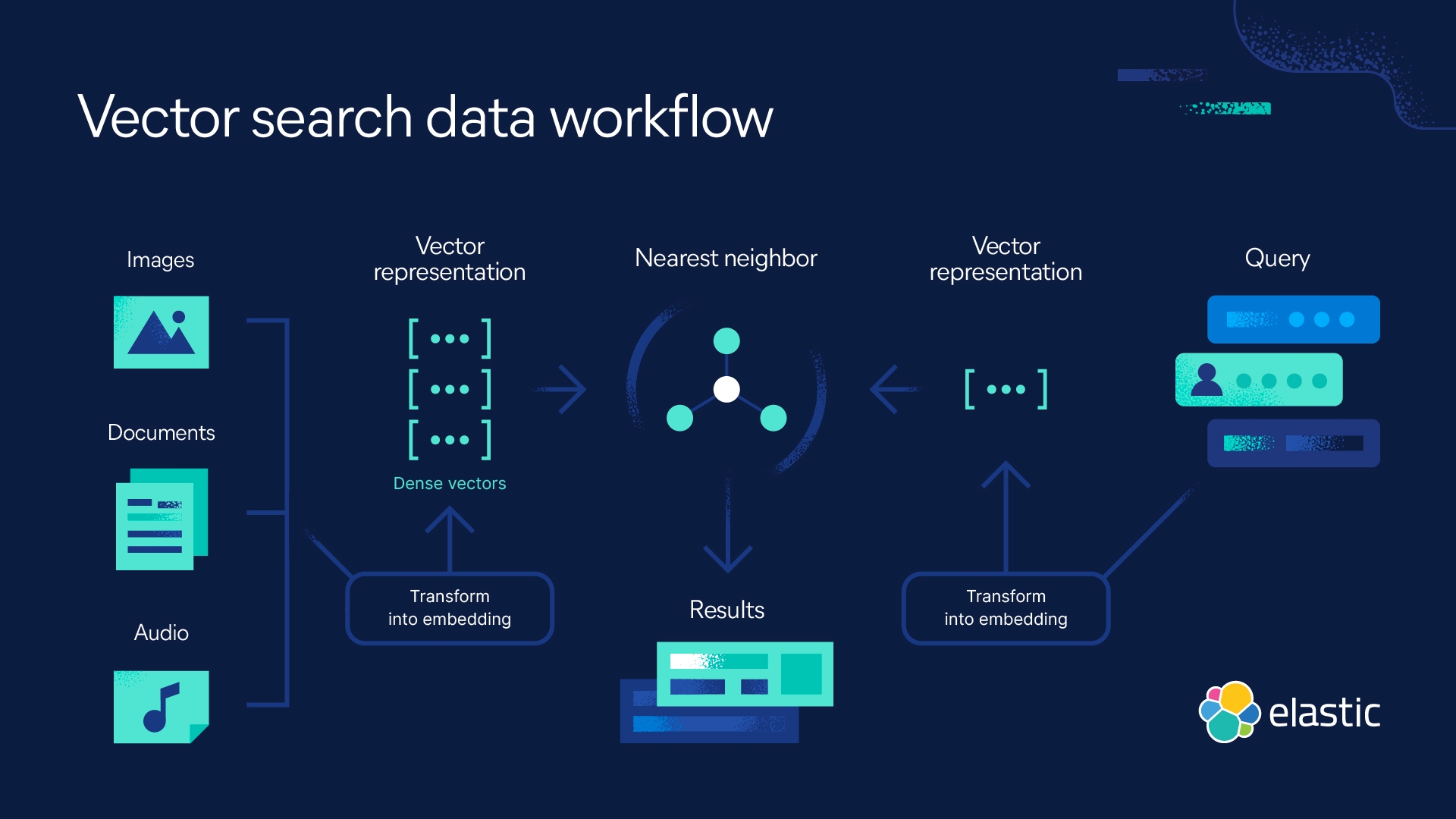
Como funciona um mecanismo de busca vetorial?
Mecanismos de busca vetorial — conhecidos como bancos de dados vetoriais, busca semântica ou busca de cosseno — encontram os vizinhos mais próximos de uma determinada consulta (vetorizada).
Onde a busca tradicional depende de menções de palavras-chave, similaridade lexical e frequência de ocorrências de palavras, os mecanismos de busca vetorial usam distâncias no espaço de embedding para representar a similaridade. Encontrar dados relacionados torna-se uma busca pelos vizinhos mais próximos da sua consulta.
Casos de uso de busca vetorial
A busca vetorial não apenas alimenta a próxima geração de experiências de busca, mas também abre as portas para uma gama de novas possibilidades.
Como começar
Busca vetorial e PLN facilitadas com a Elastic
Você não precisa mover montanhas para implementar a busca vetorial e aplicar modelos de PLN. Com o Elasticsearch Relevance Engine™ (ESRE), você obtém um kit de ferramentas para criar aplicações de busca com IA que podem ser usados com IA generativa e grandes modelos de linguagem (LLMs).
Com o ESRE, você pode criar aplicações de busca inovadoras, gerar embeddings, armazenar e buscar vetores, e implementar a busca semântica com o Learned Sparse Encoder da Elastic. Saiba mais sobre como usar o Elasticsearch como seu banco de dados vetorial ou experimente este curso prático autodirigido para busca vetorial.
