Integre a busca com IA em suas aplicações
O Elasticsearch Relevance Engine™ (ESRE) foi projetado para alimentar aplicações de busca baseadas em inteligência artificial. Use o ESRE para aplicar busca semântica com relevância superior pronta para uso (sem adaptação de domínio), integrar com grandes modelos de linguagem (LLMs) externos, implementar busca híbrida e usar modelos transformadores de terceiros ou os seus próprios.

Veja como é fácil começar a configurar o Elasticsearch Relevance Engine.
Assista ao vídeo de início rápidoCrie aplicações avançadas baseadas em RAG usando ESRE.
Inscreva-se no treinamentoUse dados privados internos como contexto com as funcionalidades de modelos de IA generativa para fornecer respostas confiáveis e atualizadas para as consultas dos usuários.
Assista ao vídeoIA para todos os desenvolvedores
Aprimore a busca com IA
Ofereça funcionalidades avançadas de relevância para IA em sua aplicação com ESRE independentemente do seu nível de experiência. O ESRE tem um conjunto de recursos para ajudar você a começar ou aperfeiçoar sua experiência com AI. Você tem a flexibilidade e o controle para implantar apps de busca com machine learning e IA generativa da forma que achar melhor.



Elasticsearch Relevance Engine
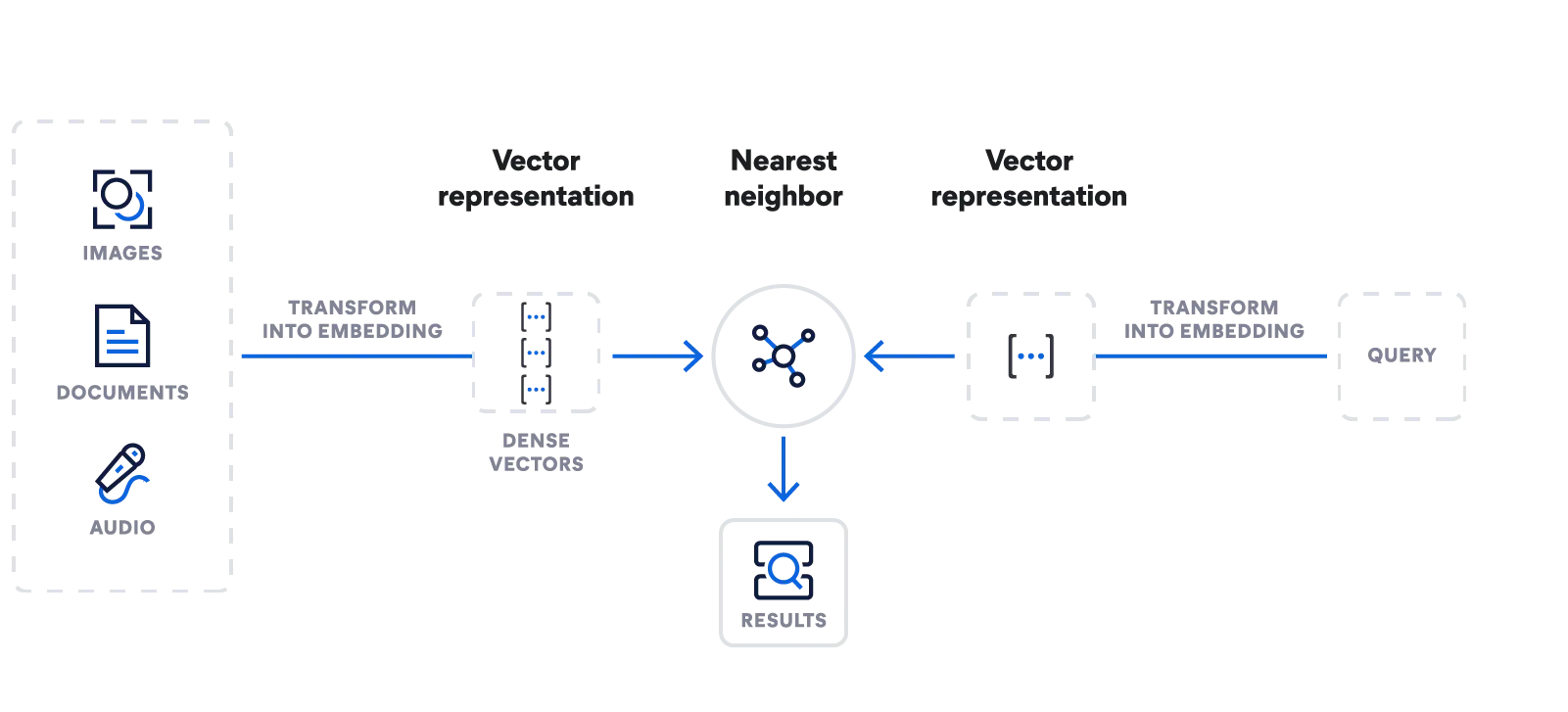
Elasticsearch - Gerador multifuncional de busca vetorial
Gere embeddings. Armazene, busque e gerencie vetores. Aproveite a busca semântica com o modelo de machine learning Learned Sparse Encoder da Elastic. Faça a ingestão de todos os tipos de dados. Integre com grandes modelos de linguagem em rápida evolução.
Amostras de código
Comece a criar a busca vetorial
Use uma única API para importar um modelo de embedding, gerar embeddings e escrever consultas de busca em escala usando a busca de vizinho mais próximo aproximado.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--cloud-id $CLOUD_ID \
-u <username> -p <password> \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--startFrequently asked questions
What is Elasticsearch Relevance Engine?
What is Elasticsearch Relevance Engine?
Elasticsearch Relevance Engine is a set of features that help developers build AI search applications and includes:
- Industry leading advanced relevance ranking features, including traditional keyword search with BM25, a foundation of relevant, hybrid search for all domains.
- Full vector database capabilities – including the ability to create embeddings, in addition to storage and retrieval of vectors.
- Elastic Learned Sparse Encoder – our new machine learning model for semantic search across a range of domains Hybrid ranking (RRF) for pairing vector and textual search capabilities for optimal search relevance across a variety of domains.
- Support to integrate 3rd-party transformer models such as OpenAI GPT-3 and 4 via APIs
- A full suite of data ingestion tools such as database connectors, 3rd-party data integrations, web crawler, and APIs to create custom connectors
- Developer tools to build search applications across all types of data: text, images, time-series, geo, multimedia, and more.
What can I build with Elasticsearch Relevance Engine?
What can I build with Elasticsearch Relevance Engine?
Elasticsearch is a leading search technology for websites (like ecommerce product and discovery) and internal information (such as customer success knowledge bases and enterprise search). With ESRE, we're providing a toolkit to build AI powered search experiences. Enable users to express their queries in natural language, in the form of a question or a description of the kind of information they seek. Combine this natural language capability with Generative AI to further enhance these models’ abilities with context from your own, private or proprietary data.
Are Elasticsearch and Elasticsearch Relevance Engine the same thing?
Are Elasticsearch and Elasticsearch Relevance Engine the same thing?
Yes, capabilities included with Elasticsearch Relevance Engine are designed and integrated at the _search api within Elasticsearch. Developers can use the Elastic API or familiar tools, such as Kibana, to interact with capabilities that make up Elasticsearch Relevance Engine together with Elasticsearch for a seamless experience..
What is Elastic Learned Sparse Encoder?
What is Elastic Learned Sparse Encoder?
Elastic Learned Sparse Encoder is a model built by Elastic for high relevance semantic search across a variety of domains. Currently, an English-only machine learning model, it captures the relationships between meanings and words for information retrieval. Interested in benchmark tests with our new retrieval model? Read this blog to learn more.
What is a transformer, and is Elastic Learned Sparse Encoder a transformer model?
What is a transformer, and is Elastic Learned Sparse Encoder a transformer model?
A transformer is a deep neural network architecture which serves as the basis for LLMs. Transformers consist of various components and can be composed of encoders, decoders and many “deep” neural network layers with many millions (or even billions) of parameters. They are typically trained on very large corpora of text like data on the Internet, and can be fine-tuned to perform a variety of NLP tasks. Our new retrieval model uses a transformer architecture but consists only of an encoder designed specifically for semantic search across a wide variety of domains.
How do I get started with Elasticsearch Relevance Engine? Do I need to purchase Elasticsearch Relevance Engine separately?
How do I get started with Elasticsearch Relevance Engine? Do I need to purchase Elasticsearch Relevance Engine separately?
All of Elasticsearch Relevance Engine’s capabilities come with Elastic Enterprise Search Platinum and Enterprise plans, as part of the 8.8 release. You can easily get started with embeddings and vector search, and try out the retrieval model model. Check out a demo of Elastic Learned Sparse Encoder's capabilities. If you have an Elasticsearch license, Elasticsearch Relevance Engine is included as part of your purchase.