Como fazer a ingestão de dados no Elasticsearch Service
O Elasticsearch é onipresente para análise e busca de dados. Os desenvolvedores e as comunidades aproveitam o Elasticsearch para os mais diversos casos de uso, desde busca de aplicações e busca de websites até logging, monitoramento de infraestrutura, APM e análise de dados de segurança. Agora existem soluções gratuitas para esses casos de uso, mas em primeiro lugar os desenvolvedores precisam alimentar seus dados no Elasticsearch.
Este artigo descreve algumas das maneiras mais comuns de fazer a ingestão de dados no Elasticsearch Service. Uma delas é um cluster que esteja hospedado no Elastic Cloud ou em sua variante de hospedagem no local, o Elastic Cloud Enterprise. Nosso foco são esses serviços, mas a ingestão de dados em um cluster do Elasticsearch autogerenciado tem praticamente a mesma aparência. A única mudança é a maneira de abordar o cluster.
Antes de nos aprofundarmos nos detalhes técnicos, se você tiver dúvidas ou problemas enquanto acompanha este artigo, consulte discuss.elastic.co. Uma comunidade dinâmica provavelmente conseguirá tirar suas dúvidas.
Agora, prepare-se para se aprofundar na ingestão de dados usando os métodos a seguir:
- Elastic Beats
- Logstash
- Clientes de linguagem
- Kibana Dev Tools
Ingestão de dados no Elasticsearch Service
O Elasticsearch fornece uma API RESTful flexível para comunicação com aplicações clientes. Dessa maneira, as chamadas REST são usadas para fazer a ingestão de dados, executar busca e análise de dados, bem como gerenciar o cluster e os respectivos índices. Em segundo plano, todos os métodos descritos dependem dessa API para fazer a ingestão de dados no Elasticsearch.
Para o restante deste artigo, pressupomos que você já criou seu cluster do Elasticsearch Service. Se ainda não fez isso, inscreva-se para obter uma avaliação grátis no Elastic Cloud. Depois de criar um cluster, você receberá um Cloud ID e uma senha para a conta elastic superuser. O Cloud ID tem o formato nome_do_cluster:ZXVy...Q2Zg==. Ele codifica a URL do cluster e, como veremos, simplifica a ingestão de dados nele.
Elastic Beats
Os Elastic Beats são um conjunto de agentes leves que permitem enviar dados de maneira conveniente ao Elasticsearch Service. Sendo leves, os Beats não geram tanto impacto no tempo de execução e assim podem executar e coletar dados nos dispositivos com recursos limitados de hardware, como dispositivos de IoT, dispositivos de borda ou dispositivos incorporados. Os Beats são perfeitos para coletar dados quando não há recursos disponíveis para executar coletores de dados com uso intenso de recursos. Esse tipo de coleta de dados em todos os dispositivos conectados em rede permite detectar rapidamente, por exemplo, problemas sistêmicos e incidentes de segurança, bem como reagir a eles.
Logicamente os Beats não precisam ser usados apenas em sistemas com restrição de recursos. Eles também podem ser usados em sistemas com mais recursos de hardware disponíveis.
O esquadrão dos Beats: visão geral
Os Beats são fornecidos em diversas modalidades para coletar diferentes tipos de dados:
- O Filebeat permite ler, pré-processar e enviar dados de fontes que vêm em forma de arquivos. Apesar de a maioria dos usuários usar o Filebeat para ler arquivos de log, há suporte para qualquer formato de arquivo não binário. O Filebeat também oferece suporte para inúmeras outras fontes de dados, incluindo TCP/UDP, containers, Redis e Syslog. Um monte de módulos facilita a coleta e a análise dos formatos de log para aplicações comuns como Apache, MySQL e Kafka.
- O Metricbeat coleta e pré-processa metrics de sistema e serviço. As metrics de sistema incluem informações sobre processos em execução, além de números de utilização de CPU, memória, disco e rede. Estão disponíveis módulos para coletar dados de muitos serviços diferentes, incluindo Kafka, Palo Alto Networks, Redis e muitos outros.
- O Packetbeat coleta e pré-processa dados de rede em tempo real, permitindo assim o monitoramento de aplicações, além de análise de dados de performance de rede e segurança. Entre outros, o Packetbeat oferece suporte para os seguintes protocolos: DHCP, DNS, HTTP, MongoDB, NFS e TLS.
- O Winlogbeat permite a captura de logs de eventos de sistemas operacionais Windows, incluindo eventos de aplicação, de hardware, de segurança e de sistema. As amplas informações disponíveis no log de eventos do Windows são de grande interesse para muitos casos de uso.
- O Auditbeat detecta alterações ocorridas em arquivos cruciais e coleta eventos do Linux Audit Framework. Diferentes módulos facilitam sua implantação, que é usada principalmente em casos de uso de análise de dados de segurança.
- O Heartbeat usa sondagem para monitorar a disponibilidade dos sistemas e serviços. Portanto, o Heartbeat é útil em inúmeros cenários, como monitoramento de infraestrutura e análise de dados de segurança. Há suporte para os protocolos ICMP, TCP e HTTP.
- O Functionbeat coleta logs e metrics de um ambiente sem servidor como o AWS Lambda.
Depois de você decidir qual desses Beats usará em seu cenário específico, começar vai ser fácil, conforme descrito na seção a seguir.
Introdução aos Beats
Nesta seção, pegamos o Metricbeat como exemplo de como começar com os Beats. As etapas necessárias para os outros Beats são bem parecidas. Consulte também a documentação e siga as etapas para o seu Beat e sistema operacional específicos.
- Faça o download e a instalação do Beat desejado. Existem inúmeras maneiras de instalar os Beats, mas a maioria dos usuários opta por usar os repositórios fornecidos pela Elastic para o gerenciador de pacotes do sistema operacional (DEB/RPM) ou simplesmente fazer o download e a descompactação dos pacotes tgz/zip fornecidos.
- Configure o Beat e habilite todos os módulos desejados.
- Por exemplo, para coletar metrics sobre containers do Docker executados no sistema, habilite o módulo do Docker com
sudo metricbeat modules enable dockerse você instalou usando o gerenciador de pacotes. Se em vez disso você descompactou o pacote tgz/zip, use/metricbeat modules enable docker. - O Cloud ID é uma maneira conveniente de especificar o Elasticsearch Service ao qual os dados coletados são enviados. Adicione o Cloud ID e as informações de autenticação ao arquivo de configuração do Metricbeat (metricbeat.yml):
cloud.id: cluster_name:ZXVy...Q2Zg==
cloud.auth: "elastic:YOUR_PASSWORD"
- Conforme mencionado anteriormente,
cloud.idfoi fornecido a você depois da criação do seu cluster.cloud.authé uma concatenação separada por ponto e vírgula de um nome de usuário e senha que receberam privilégios suficientes no cluster do Elasticsearch. - Para começar rapidamente, use a conta elastic superuser e a senha que foi fornecida após a criação do cluster. Você pode localizar o arquivo de configuração no diretório
/etc/metricbeatse instalou usando o gerenciador de pacotes ou no diretório descompactado se usou o pacote tgz/zip.
- Carregue os dashboards pré-criados no Kibana. A maioria dos Beats e seus módulos é fornecida com dashboards do Kibana predefinidos. Carregue eles no Kibana com
sudo metricbeat setupse instalou usando o gerenciador de pacotes; ou com./metricbeat setupno diretório descompactado se usou o pacote tgz/zip.
- Execute o Beat. Use
sudo systemctl start metricbeatse instalou usando o gerenciador de pacotes em um sistema Linux baseado em systemd; ou use./metricbeat -ese instalou usando o pacote tgz/zip.
Se tudo funcionar conforme esperado, os dados agora começarão a fluir para o Elasticsearch Service.
Explore esses dashboards pré-criados
Acesse o Kibana no Elasticsearch Service para inspecionar os dados:
- No Kibana Discover, selecione o padrão de índice
metricbeat-*para poder ver os documentos individuais que passaram por ingestão. - A guia Kibana Infrastructure permite inspecionar o sistema e as metrics do Docker de modo mais visual mostrando diferentes gráficos sobre utilização dos recursos do sistema (CPU, memória e rede).
- No Kibana Dashboards, selecione todos os dashboards com prefixo [Metricbeat System] para analisar seus dados de maneira interativa.
Logstash
O Logstash é uma ferramenta avançada e flexível para ler, processar e enviar dados de qualquer tipo. O Logstash fornece inúmeros recursos que não estão disponíveis no momento ou que são muito caros para executar com os Beats, como o enriquecimento de documentos executando consultas com base em fontes de dados externas. Entretanto, essa funcionalidade e flexibilidade do Logstash têm um preço. Além disso, os requisitos de hardware para o Logstash são significativamente mais altos do que para os Beats. Dessa maneira, o Logstash geralmente não deve ser implantado em dispositivos com poucos recursos. Portanto, o Logstash é usado como alternativa aos Beats, para o caso de a funcionalidade deles ser insuficiente para um caso de uso específico.
Um padrão de arquitetura comum é combinar os Beats e o Logstash: use os Beats para coletar dados e use o Logstash para executar qualquer processamento de dados que os Beats não sejam capazes de fazer.
Visão geral do Logstash
O Logstash funciona executando pipelines de processamento de eventos em que cada pipeline consiste em pelo menos um destes elementos:
- As entradas leem a partir das fontes de dados. Muitas fontes de dados têm suporte oficial, incluindo arquivos, http, imap, jdbc, kafka, syslog, tcp e udp.
- Os filtros processam e enriquecem os dados de várias maneiras. Em muitos casos, as linhas de log não estruturadas precisam ser analisadas em um formato mais estruturado. Assim, o Logstash fornece, entre outros, filtros para analisar CSV, JSON, pares de chave/valor, dados não estruturados limitados e dados não estruturados com base em expressões regulares (filtros grok). O Logstash também fornece filtros para enriquecer dados executando consultas de DNS, adicionando geoinformações sobre endereços IP ou executando consultas com base em um dicionário personalizado ou um índice do Elasticsearch. Filtros adicionais permitem transformações diversas dos dados, por exemplo, para renomear, remover, copiar campos de dados e valores (filtro mutate).
- As saídas gravam os dados analisados e enriquecidos em data sinks e são a etapa final do pipeline de processamento do Logstash. Muitos plugins de saída estão disponíveis, mas nosso foco neste artigo é a ingestão para o Elasticsearch Service usando a saída elasticsearch.
Amostra de pipeline do Logstash
Não existem dois casos de uso iguais. Assim, é provável que você terá de desenvolver pipelines do Logstash que se adaptem às suas entradas de dados e requisitos muito específicos.
Apresentamos uma amostra de pipeline do Logstash que:
- Lê o feed RSS dos Elastic Blogs
- Executa algum pré-processamento leve dos dados copiando/renomeando campos e removendo caracteres especiais e marcas HTML
- Faz ingestão de documento no Elaticsearch
As etapas são estas:
- Instale o Logstash com o gerenciador de pacotes ou fazendo o download e a descompactação do arquivo tgz/zip.
- Instale o plugin de entrada rss do Logstash, que permite ler fontes de dados RSS:
./bin/logstash-plugin install logstash-input-rss - Copie a seguinte definição de pipeline do Logstash para um novo arquivo, como ~/elastic-rss.conf:
input {
rss {
url => "/blog/feed"
interval => 120
}
}
filter {
mutate {
rename => [ "message", "blog_html" ]
copy => { "blog_html" => "blog_text" }
copy => { "published" => "@timestamp" }
}
mutate {
gsub => [
"blog_text", "<.*?>", "",
"blog_text", "[\n\t]", " "
]
remove_field => [ "published", "author" ]
}
}
output {
stdout {
codec => dots
}
elasticsearch {
hosts => [ "https://<your-elsaticsearch-url>" ]
index => "elastic_blog"
user => "elastic"
password => "<your-elasticsearch-password>"
}
}
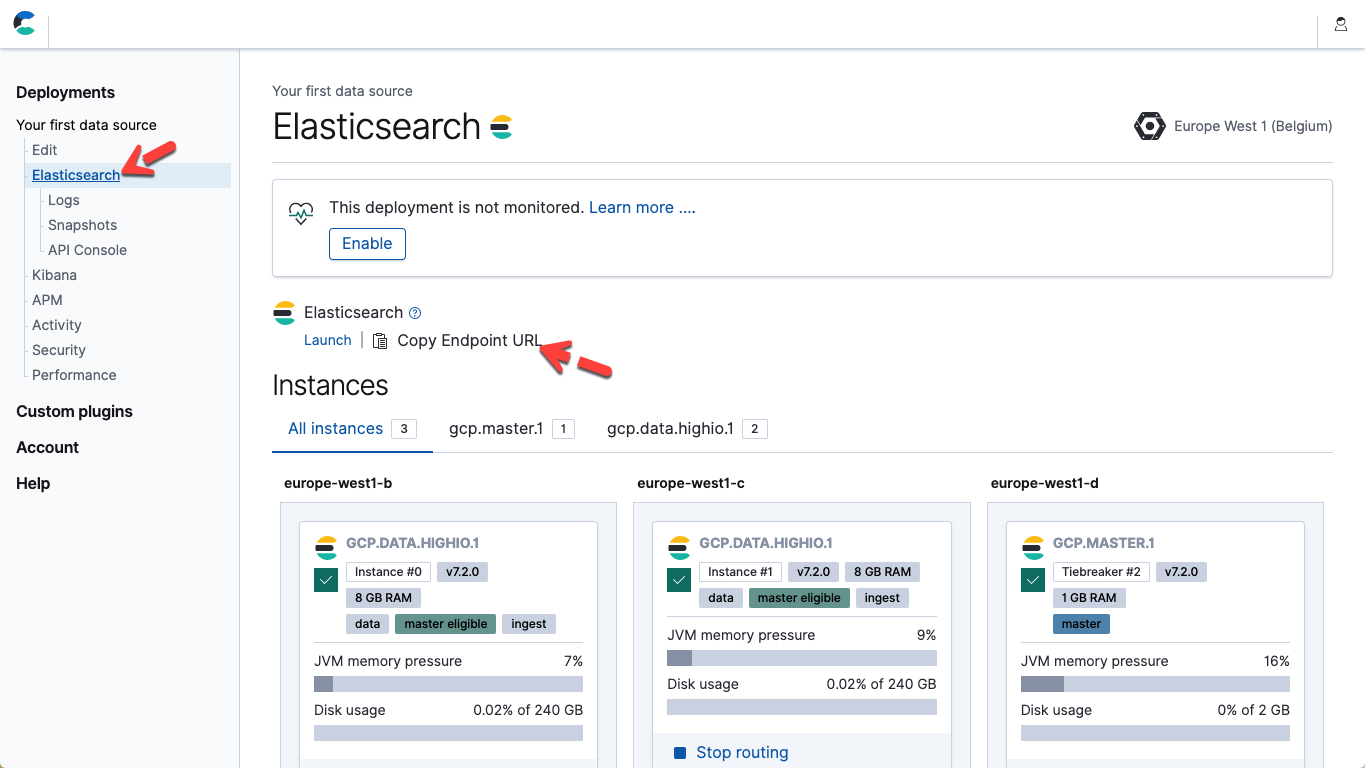
- No arquivo anterior, modifique os hosts e a senha dos parâmetros para que correspondam ao endpoint do Elasticsearch Service e à sua senha para o usuário da Elastic. No Elastic Cloud, você pode obter a URL de endpoint do Elasticsearch nos detalhes da sua página de implantação (Copy Endpoint URL).
- Execute o pipeline iniciando o Logstash: ./bin/logstash -f ~/elastic-rss.conf
A inicialização do Logstash levará quase um minuto. Você começará a ver pontos (.....) sendo impressos no console. Cada ponto representa um documento que foi ingerido no Elasticsearch.
- Abra o Kibana. No Kibana Dev Tools Console, execute este comando para confirmar que 20 documentos foram ingeridos:POST elastic_blog/_search
Clientes de linguagem
Em algumas situações, é preferível integrar a ingestão de dados ao próprio código da aplicação personalizado. Para isso, recomendamos usar um dos clientes do Elasticsearch com suporte oficial. Esses clientes são bibliotecas que abstraem detalhes de baixo nível da ingestão de dados e permitem a concentração no trabalho real que é específico à sua aplicação. Existem clientes oficiais para Java, JavaScript, Go, .NET, PHP, Perl, Python e Ruby. Consulte a documentação referente à sua linguagem preferida para obter todos os detalhes e exemplos de código. Se sua aplicação está escrita em uma linguagem não listada anteriormente, existem chances de que haja um cliente colaborado pela comunidade.Kibana Dev Tools
Nossa ferramenta preferida recomendada para desenvolvimento e debug das solicitações do Elasticsearch é o Kibana Dev Tools Console. O Dev Tools expõe a capacidade e flexibilidade da API REST genérica do Elasticsearch, ao mesmo tempo abstraindo os aspectos técnicos das solicitações HTTP subjacentes. Não é nenhuma surpresa que você possa usar o Dev Tools Console para aplicar PUT em documentos JSON brutos no Elasticsearch:PUT my_first_index/_doc/1
{
"title" : "How to Ingest Into Elasticsearch Service",
"date" : "2019-08-15T14:12:12",
"description" : "This is an overview article about the various ways to ingest into Elasticsearch Service"
}
Clientes REST variados
Com o Elasticsearch fornecendo uma interface REST genérica, realmente fica a seu critério localizar seu cliente REST favorito para se comunicar com o Elasticsearch e fazer a ingestão de documentos. É recomendável primeiro analisar as ferramentas mencionadas anteriormente, mas existem muitos motivos para você avaliar alternativas. Por exemplo, curl é uma ferramenta muito usada como último recurso, seja para desenvolvimento, debug ou integração com scripts personalizados.Conclusões
Existem inúmeras maneiras de fazer a ingestão de dados no Elasticsearch Service. Não existem dois cenários iguais; a escolha de métodos ou ferramentas específicos para fazer a ingestão de dados depende de caso de uso, de requisitos e de ambientes específicos. Os Beats fornecem uma solução pronta, conveniente e leve para fazer a coleta e a ingestão de dados de muitas fontes diferentes. Empacotados com os Beats estão módulos que fornecem a configuração para ingestão, análise, indexação e visualização de dados para muitos bancos de dados, sistemas operacionais, ambientes de container, servidores web e caches comuns, dentre outros. Esses módulos proporcionam uma experiência dos dados ao dashboard que demoram não mais que cinco minutos. Como os Beats são leves, são ideais para dispositivos incorporados com restrição de recursos, como dispositivos IoT ou firewalls. O Logstash, em contrapartida, é uma ferramenta flexível para ler, transformar e ingerir dados, fornecendo inúmeros filtros, entradas e saídas. Se a funcionalidade dos Beats não for suficiente para determinados casos de uso, um padrão de arquitetura comum será usar os Beats para coletar dados e passá-los pelo Logstash para processamento adicional antes da ingestão no Elasticsearch.É recomendável usar bibliotecas clientes com suporte oficial ao fazer a ingestão de dados diretamente de sua aplicação. O Kibana Dev Tools Console é a solução perfeita para desenvolvimento e debug. Por fim, a API REST do Elasticsearch oferece a flexibilidade de usar seu cliente REST favorito. Está pronto para se aprofundar ainda mais? É recomendável ler os seguintes artigos:
- Should I use Logstash or Elasticsearch ingest nodes? (Devo usar os nós de ingestão do Logstash ou do Elasticsearch?)
- Get System Logs and Metrics into Elasticsearch with Beats System Modules (Coloque os logs e metrics de sistema no Elasticsearch com os módulos de sistema dos Beats)