Acelerando as experiências de IA generativa
Ferramentas de desenvolvimento e IA com tecnologia de busca desenvolvidas para oferecer velocidade e escala


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Avanços diários nos grandes modelos de linguagem (LLMs) e na IA generativa colocaram os desenvolvedores na vanguarda do movimento, influenciando sua direção e as possibilidades. Neste post do blog, compartilharei como os clientes de busca da Elastic estão usando o banco de dados vetorial e a plataforma aberta da Elastic para IA com tecnologia de busca e ferramentas de desenvolvedor para acelerar e redimensionar experiências de IA generativa, proporcionando novos caminhos para crescimento.
Os resultados de uma pesquisa recente com desenvolvedores conduzida pela Dimensional Research e apoiada pela Elastic indicam que 87% dos desenvolvedores já têm um caso de uso para IA generativa, seja análise de dados, suporte ao cliente, busca no local de trabalho ou chatbots. No entanto, apenas 11% implementaram com sucesso esses casos de uso em ambientes de produção.
Existem vários fatores que se colocam como obstáculos:
Implantação e gerenciamento de modelos. A escolha do modelo certo requer experimentação e iteração rápida. A implantação de LLMs para aplicações de IA generativa é demorada e complexa, com uma curva de aprendizado acentuada para muitas organizações.
Preocupações legais e de conformidade. Essas preocupações são especialmente importantes ao lidar com dados sensíveis e podem ser uma barreira para a adoção do modelo.
- Redimensionamento. Dados específicos do domínio são cruciais para que os LLMs entendam o contexto e gerem resultados precisos. A recuperação desses dados enquanto eles se expandem exige um suporte igualmente escalável para as cargas de trabalho que geram embeddings vetoriais, aumentando rapidamente a demanda por memória e recursos computacionais. Com vastos conjuntos de dados, as janelas de contexto são grandes e caras para passar para um LLM, e mais contexto não significa necessariamente mais relevância. Somente uma plataforma robusta de ferramentas pode moldar o contexto e equilibrar as compensações entre relevância e escala para alcançar uma arquitetura de inovação viável e preparada para o futuro.
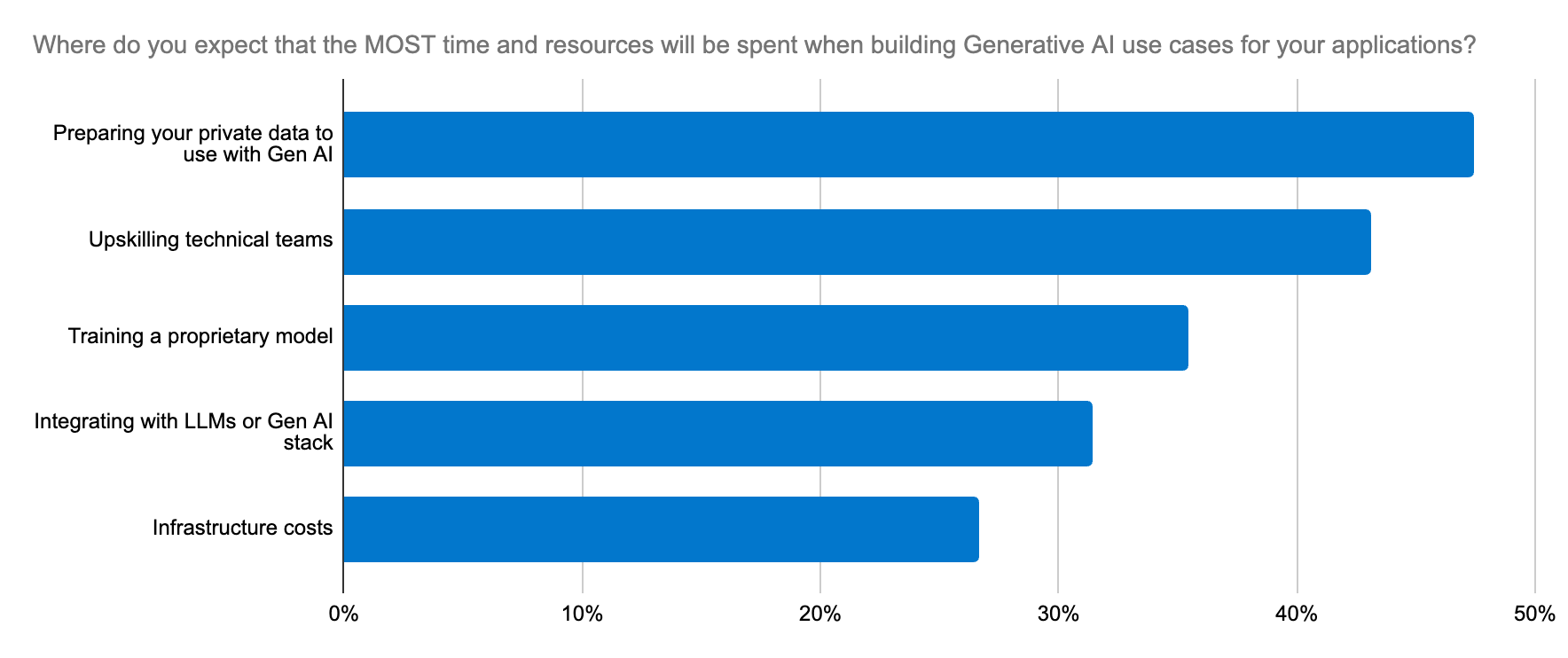
Os desenvolvedores buscam uma maneira confiável, escalável e econômica de criar aplicações de IA generativos e uma plataforma que simplifique a implementação e o processo de seleção do LLM.
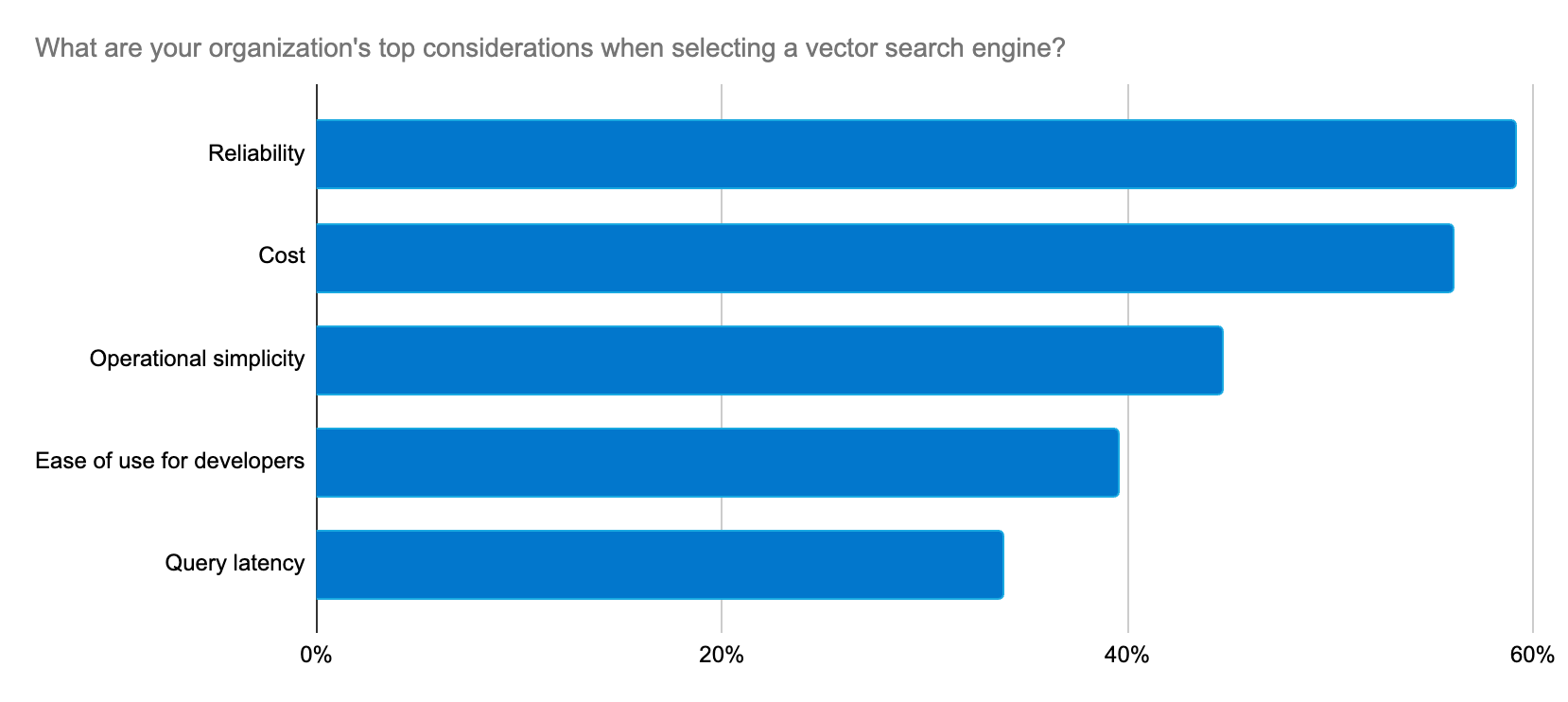
A Elastic fornece consistentemente soluções para essas preocupações dos desenvolvedores com um ritmo rápido de inovação para oferecer suporte a casos de uso de IA generativa.
Implemente experiências de IA generativa com rapidez e escala
O Elasticsearch é o banco de dados vetorial mais baixado do mercado, e a profunda associação da Elastic com a comunidade Lucene nos permitiu projetar e entregar aos nossos clientes inovações na busca com mais rapidez. O Elasticsearch agora tem a tecnologia do Lucene 9.10, ajudando os clientes a alcançar velocidade e escala com IA generativa. Com a versão 9.10, entre outros aumentos de velocidade, os usuários estão observando melhorias significativas na latência das consultas em índices multissegmentados. E isso é apenas o começo: mais velocidade está por vir.
Estamos usando o Elastic como banco de dados vetorial devido à sua flexibilidade, escalabilidade e confiabilidade inerentes. A Elastic eleva continuamente o jogo, fornecendo rapidamente novos recursos que oferecem suporte para machine learning e IA generativa.
Peter O'Connor, gerente de engenharia de plataforma, Stack Overflow
Para implementar e redimensionar rapidamente as cargas de trabalho de RAG, o Elastic Learned Sparse EncodeR (ELSER) (com disponibilidade geral) é um modelo de machine learning (ML) otimizado, de interação tardia e fácil de implantar para busca semântica. O ELSER fornece resultados de busca contextualmente relevantes sem exigir ajustes finos e oferece aos desenvolvedores uma solução confiável e integrada, economizando tempo e reduzindo a complexidade da seleção, implantação e gerenciamento de modelos.
O ELSER eleva a relevância da busca sem prejudicar a velocidade. Quando a Consensus atualizou sua plataforma de pesquisa acadêmica desenvolvida pela Elastic, usando o ELSER, ela obteve uma redução de 75% na latência da busca e um aumento na precisão.
Ao combinar o ELSER com o modelo de embedding E5, você pode aplicar facilmente a busca vetorial multilíngue. Nosso artefato otimizado do E5 é adaptado especificamente para implantações do Elasticsearch. A busca multilíngue também está disponível por meio do upload de modelos multilíngues ou da integração com a API de inferência da Elastic (por exemplo, os embeddings de modelos multilíngues da Cohere). Esses avanços aceleram ainda mais a geração aumentada de recuperação (RAG), fazendo do Elastic uma infraestrutura crítica para redimensionar as experiências inovadoras de IA generativa que você cria.
A Elastic também está com o foco voltado para o redimensionamento dessas experiências com eficiência. A quantização escalar, que veio com nossa versão 8.12, é um divisor de águas para o armazenamento vetorial. Grandes expansões vetoriais podem provocar lentidão nas buscas. No entanto, essa técnica de compactação reduz os requisitos de memória em quatro vezes, ajuda a compactar mais vetores e, em escalas mais altas, tem um impacto insignificante no recall. Ela duplica a velocidade da busca vetorial usada no RAG sem sacrificar a precisão. O resultado? Um sistema mais simples e rápido que reduz os custos de infraestrutura em escala.
Ao combinar a precisão e a velocidade da Elastic com o poder do Google Cloud, você pode criar uma plataforma de busca muito estável e econômica que também oferece uma experiência agradável para o usuário.
Sujith Joseph, arquiteto principal de busca empresarial e nuvem, Cisco Systems
O mecanismo de busca mais relevante para RAG
A relevância é a chave para as melhores experiências de IA generativa. Usar o ELSER para busca semântica e o BM25 para busca textual são excelentes primeiros passos para recuperar documentos relevantes como contexto para LLMs. Grandes janelas de contexto podem ser ainda mais refinadas usando ferramentas de reclassificação que agora fazem parte do Elastic Stack. Os reclassificadores aplicam poderosos modelos de ML para ajustar os resultados da busca e trazer os resultados mais relevantes para o topo com base nas preferências do usuário e nos sinais. O Learning to Rank (LTR) agora também é nativo da Elasticsearch Platform. Isso é excelente para casos de uso de RAG, que dependem de alimentar um LLM com os resultados mais relevantes como contexto.
A implementação é ainda mais simplificada por meio da API de inferência e de provedores terceirizados, como a Cohere. Atualize para nossa versão mais recente para testar o impacto que os reclassificadores podem ter na relevância.
Essas abordagens não só melhoram a precisão da busca (em 30%, no caso da Consensus), mas também ajudam você a alcançar resultados rápidos, refinando a relevância para o RAG e gerenciando fluxos de trabalho de ML com eficiência.
Simplificando a seleção e troca de modelos
A seleção de modelo pode ser como procurar uma agulha em um palheiro. Na verdade, nossa pesquisa com desenvolvedores destacou que um dos cinco maiores esforços com a IA generativa nas organizações é a integração com LLMs. Esse dilema vai além da escolha de LLMs de código aberto ou fechado para um caso de uso — ele se estende à precisão, segurança de dados, especificidade de domínio e rápida adaptação ao ecossistema de LLM em constante mudança. Os desenvolvedores precisam de um fluxo de trabalho simples para experimentar novos modelos e trocá-los.
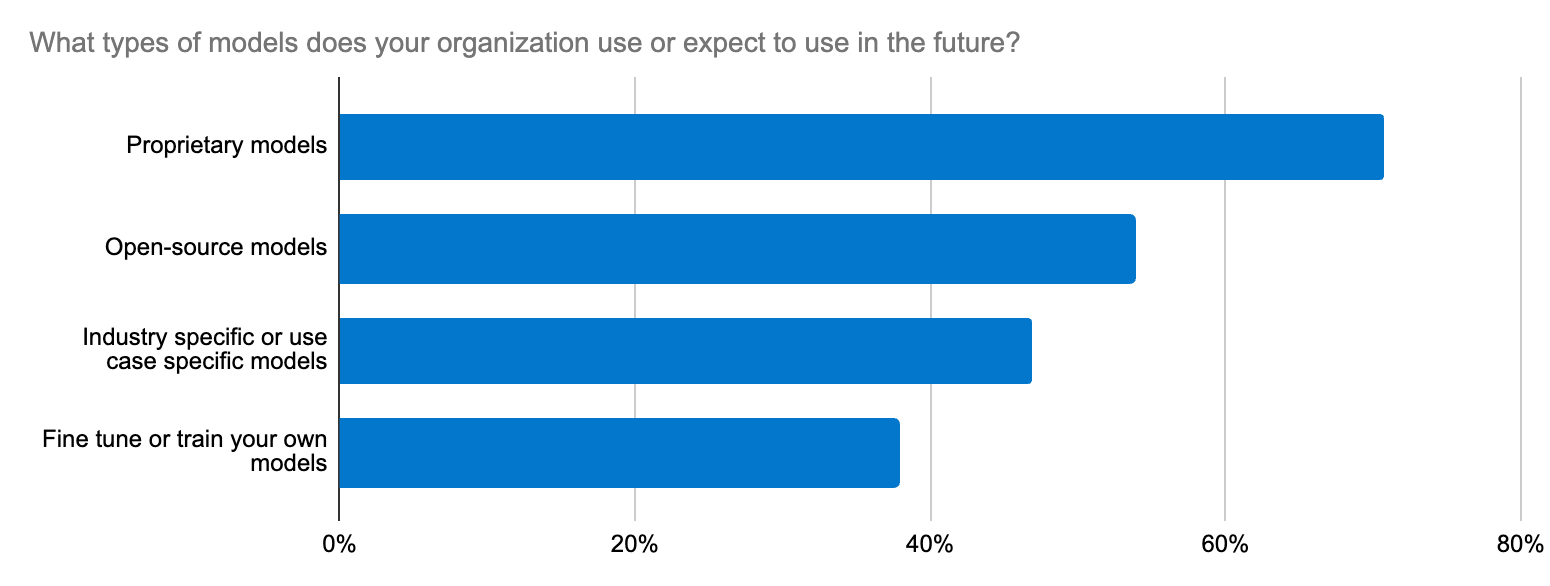
A Elastic oferece suporte para modelos transformadores e fundamentais por meio de sua plataforma aberta, seu banco de dados vetorial e seu mecanismo de busca. O Elastic Learned Sparse EncodeR (ELSER) é um ponto de partida confiável para acelerar as implementações de RAG.
Além disso, a API de inferência da Elastic simplifica o código e o gerenciamento de inferência em várias nuvens para os desenvolvedores. Quer você use o ELSER ou embeddings da OpenAI (o modelo mais avaliado e usado entre os desenvolvedores), Hugging Face, Cohere ou outros para cargas de trabalho de RAG, uma única chamada de API garante um código limpo para gerenciar a implantação de inferência híbrida. Com a API de inferência, uma ampla variedade de modelos torna-se facilmente acessível, para que você possa encontrar a opção ideal. A fácil integração com o processamento de linguagem natural (PLN) específico do domínio e os modelos de IA generativa simplifica o gerenciamento de modelos, liberando seu tempo para você se dedicar à inovação com IA.
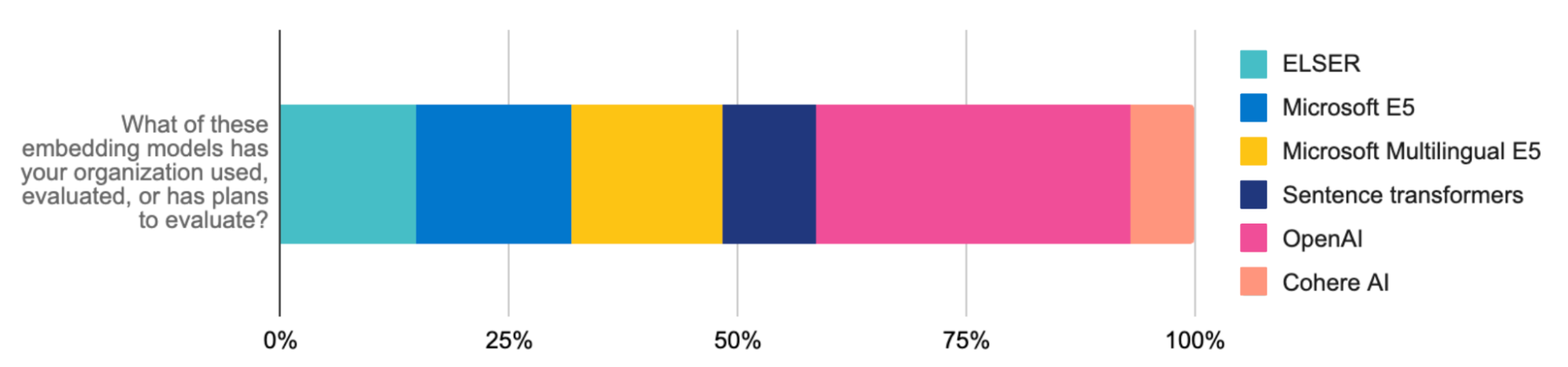
Mais fortes juntos: uma ótima experiência com integrações
Os desenvolvedores também podem hospedar diversos modelos transformadores, incluindo modelos da Hugging Face públicos e privados. Embora o Elasticsearch sirva como um banco de dados vetorial versátil para todo o ecossistema, os desenvolvedores que preferem ferramentas como LangChain e LlamaIndex podem usar nossas integrações para ativar rapidamente apps de IA generativa prontos para produção usando modelos LangChain. A plataforma aberta da Elastic permite que você adapte, experimente e acelere projetos de IA generativa rapidamente. O Elastic também foi adicionado recentemente como um banco de dados vetorial de terceiros para o On Your Data, um novo serviço para criar copilotos de conversação. Outro bom exemplo é a colaboração da Elastic com a equipe da Cohere nos bastidores para tornar o Elastic um excelente banco de dados vetorial para os embeddings da Cohere.
A IA generativa está remodelando todas as organizações, e a Elastic está aqui para apoiar essa transformação. Para os desenvolvedores, as chaves para implementações de IA generativa bem-sucedidas são o aprendizado contínuo (você já conhece o Elastic Search Labs?) e a rápida adaptação ao dinâmico cenário da IA.
Experimente!
- Leia sobre esses recursos e muito mais nas notas de lançamento do Elastic Search.
- Quem já trabalha com o Elastic Cloud pode acessar muitos desses recursos diretamente no console Elastic Cloud. Ainda não está usando o Elastic Cloud? Inicie uma avaliação gratuita.
- Experimente o Elasticsearch Relevance Engine, nosso conjunto de ferramentas de desenvolvedor para criar apps de busca com IA.
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste post permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis atualmente poderão não ser entregues dentro do prazo previsto ou nem chegar a ser entregues.
Neste post do blog, podemos ter usado ou nos referido a ferramentas de IA generativa de terceiros, que pertencem a seus respectivos proprietários e são operadas por eles. A Elastic não tem nenhum controle sobre as ferramentas de terceiros e não temos nenhuma responsabilidade por seu conteúdo, operação ou uso nem por qualquer perda ou dano que possa surgir do uso de tais ferramentas. Tenha cuidado ao usar ferramentas de IA com informações pessoais, sensíveis ou confidenciais. Os dados que você enviar poderão ser usados para treinamento de IA ou outros fins. Não há garantia de que as informações fornecidas serão mantidas em segurança ou em confidencialidade. Você deve se familiarizar com as práticas de privacidade e os termos de uso de qualquer ferramenta de IA generativa antes de usá-la.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine e marcas associadas são marcas comerciais, logotipos ou marcas registradas da Elasticsearch N.V. nos Estados Unidos e em outros países. Todos os outros nomes de empresas e produtos são marcas comerciais, logotipos ou marcas registradas de seus respectivos proprietários.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir